Spire.OCR 1.9.12 supports a new model for OCR usage
We are pleased to announce the release of Spire.OCR 1.9.12. This version adds a new model for OCR usage. Furthermore, some known bugs are fixed in this update, such as the issue that errors occurred in character recognition. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | A new model for OCR usage has been added.
OcrScanner scanner = new OcrScanner();
ConfigureOptions configureOptions = new ConfigureOptions();
configureOptions.ModelPath = "ocr_model\\win-x64\\";
// The default is English(for exmple English, Chinese, Chinesetraditional, French, German, Japan, or Korean)
configureOptions.Language = "Chinese";
scanner.ConfigureDependencies(configureOptions);
scanner.Scan("1.png");
string text = scanner.Text.ToString();
File.WriteAllText("result.txt", text);
|
| Bug | SPIREOCR-67 | Improves the Recognition speed. |
| Bug | SPIREOCR-3 | Fixes the issue that character recognition errors occurred. |
| Bug | SPIREOCR-27 | Fixes the issue that inconsistent character recognition occurred during multiple reads. |
| Bug | SPIREOCR-43 | Fixes the issue that image data was not fully extracted. |
| Bug | SPIREOCR-68 | Fixes the issue that image recognition failed on the Linux system. |
| Bug | SPIREOCR-74 | Fixes the issue that incorrect line breaks occurred in recognized characters. |
| Bug | SPIREOCR-75 | Fixes the issue that intermittent recognition failures happen when cyclically recognizing text in images. |
Spire.Office 9.9.0 is released
We're pleased to announce the release of Spire.Office 9.9.0. This version adds many new features, for example, Spire.XLS supports identify OLE objects in Msg format and disabling DTD processing; Spire.Presentation supports setting the global font directory when execute conversion feature, and also adds two properties to obtain the last row and last column of the chart's data source. What’s more, a series of issues occurred when processing Excel, PDF and PowerPoint files have been successfully fixed. More details are given below.
In this version, the most recent versions of Spire.Doc, Spire.PDF, Spire.XLS, Spire.Presentation, Spire.Email, Spire.DocViewer, Spire.PDFViewer, Spire.Spreadsheet, Spire.OfficeViewer, Spire.DataExport, Spire.Barcode are included.
DLL Versions:
- Spire.Doc.dll v12.8.12
- Spire.Pdf.dll v10.9.0
- Spire.XLS.dll v14.9.5
- Spire.Presentation.dll v9.9.2
- Spire.Barcode.dll v7.3.3
- Spire.Email.dll v6.6.0
- Spire.DocViewer.Forms.dll v8.8.1
- Spire.PdfViewer.Asp.dll v7.12.23
- Spire.PdfViewer.Forms.dll v7.12.23
- Spire.Spreadsheet v7.5.2
- Spire.OfficeViewer.Forms.dll v8.7.15
- Spire.DataExport.dll v4.9.0
- Spire.DataExport.ResourceMgr.dll v2.1.0
Here is a list of changes made in this release
Spire.XLS
| Category | ID | Description |
| New feature | SPIREXLS-5307 | Adds the 'OleObjectType.Msg' type to identify OLE objects in Msg format.
Workbook wb = new Workbook();
wb.LoadFromFile(inputFile);
Worksheet sheet =wb.Worksheets[0];
OleObjectType type;
if (sheet.HasOleObjects)
{
for (int i = 0; i < sheet.OleObjects.Count; i++)
{
var Object = sheet.OleObjects[i];
type = sheet.OleObjects[i].ObjectType;
switch (type)
{
case OleObjectType.Msg:
File.WriteAllBytes(outputFile_1, Object.OleData);
break;
......
}
}
}
|
| New feature | SPIREXLS-5359 | Adds the 'workbook.ProhibitDtd = true' property to disable DTD processing.
Workbook workbook = new Workbook(); workbook.ProhibitDtd = true; workbook.LoadFromFile(inputFile); workbook.SaveToFile(outputFile, ExcelVersion.Version2013); workbook.Dispose(); |
| New feature | SPIREXLS-5395 | Implements the support for the BAHTTEXT formula.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A3"].Value2 = 1234; workbook.Worksheets[0].Range["C3"].Formula = "=BAHTTEXT(A3)"; workbook.Worksheets[0].Range["A9"].Value = "1234"; workbook.Worksheets[0].Range["C9"].Formula = "=BAHTTEXT(A9)"; workbook.SaveToFile(outputFile, ExcelVersion.Version2013); workbook.Dispose(); |
| New feature | SPIREXLS-5255 | Supports adding filters to row fields/column fields of pivot tables.
XlsPivotTable pt1 = workbook.Worksheets["PivotTable_1"].PivotTables[0] as XlsPivotTable; pt1.RowFields[0].AddValueFilter(PivotValueFilterType.Between, pt1.DataFields[0], 100000, 1000000); pt1.ColumnFields[0].AddValueFilter(PivotValueFilterType.Between, pt1.DataFields[0], 100000, 1000000); pt1.CalculateData(); |
| New feature | SPIREXLS-5393 | Supports the issue that the TEXTBEFORE formula is now available.
workbook.Worksheets[0].Range["A1"].Formula = "=TEXTBEFORE(\"Red riding hood's, red hood\", \"hood\")"; |
| New feature | SPIREXLS-5394 | Supports the issue that the TEXTSPLIT formula is now available.
Supports the issue that the TEXTSPLIT formula is now available. workbook.Worksheets[0].Range["B2:D2"].FormulaArray = "=TEXTSPLIT(A2, \" \")"; |
| New feature | SPIREXLS-5397 | Supports the issue that the TEXTAFTER formula is now available.
workbook.Worksheets[0].Range["A3"].Formula = "=TEXTAFTER(\"Red riding hood’s, red hood\", \"\")"; |
| Bug | SPIREXLS-5108 | Fixed the issue that the table borders were inconsistent in color after converting an Excel document to a picture. |
| Bug | SPIREXLS-5280 | Fix the issue that the content was incorrect after converting an Excel document to a CSV document. |
| Bug | SPIREXLS-5315 | Fix the issue that the order of setting different font styles for the contents of a cell affected the inconsistency of the results. |
| Bug | SPIREXLS-5321 | Fix the issue that icons were lost after converting an Excel document to an HTML document. |
| Bug | SPIREXLS-5332 | Fix the issue that the data in the pivot table was lost when converting an Excel document to a picture. |
| Bug | SPIREXLS-5346 | Fix the issue that the result of data summing using MarkerDesigner function was incorrect. |
| Bug | SPIREXLS-5360 | Fixed the issue that the program threw System.OutOfMemoryException when converting charts to pictures. |
| Bug | SPIREXLS-5361 | Fixed the issue that the formatting was changed after saving as an XLSX document. |
| Bug | SPIREXLS-5363 | Fixed the issue that the spacing between words became larger after converting an Excel document to a PDF document. |
| Bug | SPIREXLS-5400 | Fix the issue that the text line breaks were incorrect after converting an Excel document to a PDF document. |
| Bug | SPIREXLS-5355 | Fixes the issue that the content is incorrect when converting Excel documents to images. |
| Bug | SPIREXLS-5467 | Fixes the issue that an exception "System.InvalidCastException" is thrown when copying worksheets containing charts. |
| Bug | SPIREXLS-5468 | Fixes the issue that there is a discrepancy in data after the decimal point when converting Excel documents to PDF. |
Spire.PDF
| Category | ID | Description |
| Bug | SPIREPDF-4562 SPIREPDF-5019 |
Improves the speed of printing PDF documents. |
| Bug | SPIREPDF-4445 | Fixes the issue that content is blank when converting PDF documents to images. |
| Bug | SPIREPDF-6938 | Fixes the issue that the program throws a System.FormatException: "Header checksum illegal" when compressing PDF documents. |
| Bug | SPIREPDF-6969 | Fixes the issue that the program throws a System.NullReferenceException: "Object reference not set to an instance of an object." when converting PDF documents to OFD documents. |
| Bug | SPIREPDF-6970 | Fixes the issue that the program throws a System.Exception: "Header of the stream cannot be read." when extracting images. |
| Bug | SPIREPDF-6971 | Fixes the issue that the content is incorrect when converting SVG files to PDF documents. |
| Bug | SPIREPDF-6974 | Fixes the issue with font errors when converting SVG files to PDF documents. |
| Bug | SPIREPDF-6979 | Fixes the issue that the program throws a System.IndexOutOfRangeException: "Index is outside the bounds of the array." when converting PDF documents to images. |
| Bug | SPIREPDF-6981 | Fixes the issue that the program throws a System.NullReferenceException: "Object reference not set to an instance of an object." when retrieving fonts. |
| Bug | SPIREPDF-6995 | Fixes the issue that results are incorrect when extracting text multiple times. |
| Bug | SPIREPDF-6997 | Fixes the issue that the program throws a System.NullReferenceException: "Object reference not set to an instance of an object." when converting PDF documents to PDFA1B documents. |
Spire.Presentation
| Category | ID | Description |
| New feature | SPIREPPT-2567 | Supports setting the global font directory when execute the conversion function.
Presentation.SetCustomFontsDirctory("myfonts");
|
| New feature | SPIREPPT-2594 | Adds the "IChart.ChartData.LastRowIndex" and "IChart.ChartData.LastColIndex" properties to obtain the last row and last column of the chart's data source.
Presentation ppt = new Presentation();
ppt.LoadFromFile(inputFile);
StringBuilder stringBuilder= new StringBuilder();
IChart chart = ppt.Slides[0].Shapes[0] as IChart;
if (chart != null)
{
int lastRow = chart.ChartData.LastRowIndex;
int lastCol = chart.ChartData.LastColIndex;
sb.AppendLine("lastRow" + lastRow + "\r\n" + "lastColumn" + lastCol);
int dataRow = chart.Series[2].Values[chart.Series[2].Values.Count - 1].Row;
int dataColumn = chart.Series[2].Values[chart.Series[2].Values.Count - 1].Column;
sb.AppendLine("dataRow" + datarow + "\r\n" + "dataColumn" + dataColumn);
chart.ChartData.Clear(dataRow + 1, 0, lastRow + 1, lastCol + 1);
chart.ChartData.Clear(0, dataColumn + 1, lastRow + 1, lastCol + 1);
}
File.WriteAllText(outputFile_T,stringBuilder.ToString());
ppt.SaveToFile(outputFile, FileFormat.Pptx2013);
ppt.Dispose();
|
| Bug | SPIREPPT-2582 | Fixes the issue that the type changed from "graphic" to "image" when copying shapes. |
| Bug | SPIREPPT-2590 | Fixes the issue that the content was incorrect when converting PPTX documents to SVG documents. |
Spire.Office for Java 9.9.0 is released
We are excited to announce the release of Spire.Office for Java 9.9.0. In this version, Spire.Doc for Java supports determining if a bookmark is hidden; Spire.PDF for Java supports extracting text from specified areas; Spire.XLS for Java supports the revision function; Spire.Presentation for Java supports getting the names of all embedded fonts in a PowerPoint file. Moreover, a lot of known issues are fixed successfully in this version. More details are listed below.
Here is a list of changes made in this release
Spire.Doc for Java
| Category | ID | Description |
| New feature | SPIREDOC-7237 | Supports determining if a bookmark is hidden with the new method, "bookmark.isHidden()". |
| New feature | SPIREDOC-10287 | Supports updating the character count with the new method, "document.updateWordCount()". |
| New feature | SPIREDOC-10771 | Supports embedding font files into the document when converting Word documents to HTML documents with the new method, "document.getHtmlExportOptions().setFontEmbedded(true)". |
| Bug | SPIREDOC-10641 | Fixes the issue that line spacing became inconsistent after replacing bookmark content. |
| Bug | SPIREDOC-10671 | Fixes the issue that regular format Latex formula code added to the document was converted into italic style. |
| Bug | SPIREDOC-10676 | Fixes the issue that removing the italic style from Latex formulas did not take effect. |
| Bug | SPIREDOC-10739 | Fixes the issue that the set edit restriction password did not work in MS Word or WPS tools. |
| Bug | SPIREDOC-10757 | Fixes the issue that garbled content appeared when converting Word documents to PDF documents. |
| Bug | SPIREDOC-10769 | Fixes the issue that the program hung when converting Markdown documents to Word documents. |
| Bug | SPIREDOC-10771 | Fixes the issue that an occasional exception occurred during stress testing of the merge mail function. |
| Bug | SPIREDOC-10740 | Optimizes the speed of converting Word documents to PDF documents. |
| Bug | SPIREDOC-10457 | Fixes the issue that the text layout was incorrect after converting Word documents to PDF documents. |
| Bug | SPIREDOC-10791 | Fixes the issue that the created table of contents field was not updated correctly. |
| Bug | SPIREDOC-10813 | Fixes the issue that SimSun font was replaced with Times New Roman font after converting Word documents to PDF documents. |
| Bug | SPIREDOC-10821 | Fixes the issue that the program threw "Cannot find any fonts in specified font sources" exception when converting Word documents to PDF documents under the system environment where fonts were not installed. |
| Bug | SPIREDOC-10825 | Fixes the issue that the program threw java.lang.NullPointerException when using Map type parameters in MailMergeDataTable class. |
Spire.PDF for Java
| Category | ID | Description |
| New feature | SPIREPDF-6920 | Adds the PreserveAllowedMetadata property to support preserving XMP data when converting PDF to PDF/A format documents.
PdfStandardsConverter convert= new PdfStandardsConverter(outputFile_pdf); convert.getOptions().setPreserveAllowedMetadata(true); convert.toPdfA2A(outputFile_pdfA2A); |
| New feature | SPIREPDF-6977 | Add a new interface 'PdfTextReplaceOptions.setReplacementArea(Rectangle2D rect)' to support extracting text from specified areas.
PdfPageBase page = pdf.getPages().get(0);
PdfTextReplacer replacer= new PdfTextReplacer (page);
replacer.getOptions().setReplacementArea(new Rectangle2D.Float(10, 0, 841, 150));
replacer.getOptions().setReplaceType(EnumSet.of(ReplaceActionType.WholeWord));
replacer.replaceAllText("SQL","Now SQL");
|
| New feature | SPIREPDF-6962 | Adds a deprecation status indicator to the 'PdfDocument.isPasswordProtected(filename)' method. |
| Bug | SPIREPDF-6959 | Fixes the issue that the program threw a 'java.lang.NullPointerException' when replacing text. |
| Bug | SPIREPDF-6973 | Fixes the issue that the program threw a 'java.lang.NullPointerException' when extracting text. |
| Bug | SPIREPDF-6976 | Fixes the issue that the program threw a 'java.lang.ArrayIndexOutOfBoundsException' when extracting text. |
| Bug | SPIREPDF-6992 | Fixes the issue that the program threw a 'java.lang.OutOfMemoryError' when determining if a PDF document was password protected. |
| Bug | SPIREPDF-6994 | Fixes the issue that the program threw a 'java.lang.NoClassDefFoundError' when compressing images. |
| Bug | SPIREPDF-7001 | Fixes the issue that the program threw a 'java.lang.OutOfMemoryError' when merging documents after replacing text. |
Spire.XLS for Java
| Category | ID | Description |
| New feature | SPIREXLS-5371 | Supports the revision function.
Workbook workbook = new Workbook();
workbook.loadFromFile("input.xlsx");
workbook.setTrackedChanges(true);
workbook.acceptAllTrackedChanges();
workbook.saveToFile("output.xlsx", ExcelVersion.Version2013);
workbook.dispose();
|
| New feature | SPIREXLS-5362 | Optimizes the speed of converting Excel documents to HTML documents. |
| Bug | SPIREXLS-5149 | Fixes the issue that print area settings are not fully copied when duplicating worksheets. |
| Bug | SPIREXLS-5295 | Fixes the issue that some data is incorrect when converting Excel documents to PDF documents. |
| Bug | SPIREXLS-5368 | Fixes the issue that chart contents are lost when converting worksheets to images. |
| Bug | SPIREXLS-5368 | Fixes the issue that the program throws an exception "Input string was not in the correct format." when converting charts to images. |
| Bug | SPIREXLS-5432 | Fixes the issue that the program throws a java.lang.IllegalArgumentException exception when loading Excel documents. |
| Bug | SPIREXLS-5435 | Fixes the issue that conditional formatting is lost when converting Excel documents to XML documents and then back to Excel documents. |
| Bug | SPIREXLS-5441 | Fixes the issue that the program throws a java.lang.OutOfMemoryError exception when converting Excel documents to PDF documents. |
| Bug | SPIREXLS-5442 | Fixes the issue that fonts are incorrect when converting Excel documents to PDF documents. |
Spire.Presentation for Java
| Category | ID | Description |
| New feature | SPIREPPT-2602 | Supports getting the names of all embedded fonts in a PowerPoint file.
ArrayList<String> embedFonts = ppt.getEmbedFonts(); |
| Bug | SPIREPPT-2597 | Fixes the issue that the program threw java.lang.ClassCastException when converting a PPTX document to a PPT document. |
| Bug | SPIREPPT-2599 | Fixes the issue that the program threw java.lang.ClassCastException when calling table.distributeRows(0,1) method after adding a formula to a table cell. |
| Bug | SPIREPPT-2601 | Fixes the issue that the program suspended when loading a PPTX document. |
E-iceblue will take a 7-day National Holiday from October 1 to 7, 2024
We would like to inform you that E-iceblue will be on holiday from October 1st to October 7th, 2024 (GMT+8:00), in observance of China’s National Day.
During the holiday, your email will be received as usual and the urgent problems will be solved as soon as possible by the staff on duty.
Note: The purchase system will remain available 24 hours a day and 7 days a week. Once you process the order online and finish the payment, the license file will be sent to you automatically by our system.
If you want to obtain a temporary license file to have a better evaluation on our products, please Request a Temporary License for yourself. If you could not request it successfully, please send an email to sales team.
Regular business hours will resume on October 8th, 2024. We apologize for any inconvenience this may cause and sincerely appreciate your understanding and continued support.
Please feel free to contact us via the following emails:
- Support Team: support@e-iceblue.com
- Sales Team: sales@e-iceblue.com
Useful Links Related to Purchase
Python: Convert PDF to Grayscale or Linearized
Converting a PDF to grayscale reduces file size by removing unnecessary color data, turning the content into shades of gray. This is especially useful for documents where color isn’t critical, such as text-heavy reports or forms, resulting in more efficient storage and faster transmission. On the other hand, linearization optimizes the PDF’s internal structure for web use. It enables users to start viewing the first page while the rest of the file is still loading, providing a faster and smoother experience, particularly for online viewing. In this article, we will demonstrate how to convert PDF files to grayscale or linearized PDFs in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to Grayscale in Python
Converting a PDF document to grayscale can be achieved by using the PdfGrayConverter.ToGrayPdf() method. The detailed steps are as follows.
- Load a PDF document using the PdfGrayConverter class.
- Convert the PDF document to grayscale using the PdfGrayConverter.ToGrayPdf() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output PDF file paths inputFile = "Sample.pdf" outputFile = "Output/ConvertToGrayscale.pdf" # Load a PDF document using the PdfGrayConverter class converter = PdfGrayConverter(inputFile) # Convert the PDF document to grayscale converter.ToGrayPdf(outputFile)
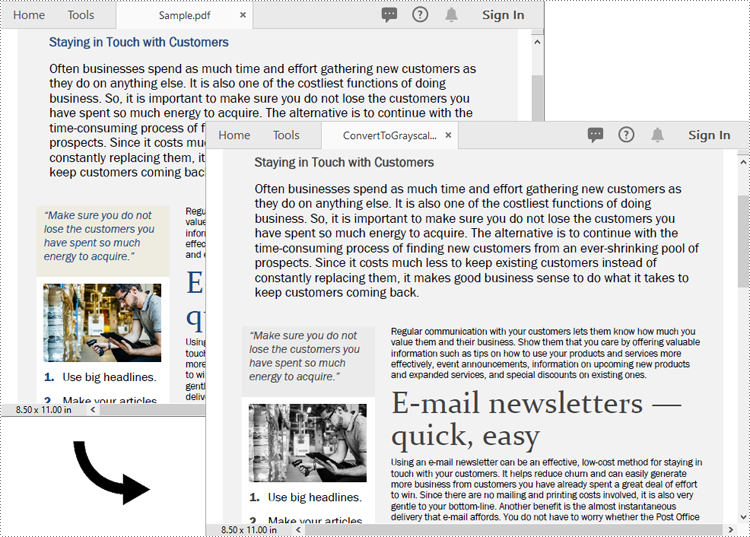
Convert PDF to Linearized in Python
To convert a PDF to linearized, you can use the PdfToLinearizedPdfConverter.ToLinearizedPdf() method. The detailed steps are as follows.
- Load a PDF document using the PdfToLinearizedPdfConverter class.
- Convert the PDF document to linearized using the PdfToLinearizedPdfConverter.ToLinearizedPdf() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output PDF file paths inputFile = "Sample.pdf" outputFile = "Output/ConvertToLinearizedPdf.pdf" # Load a PDF document using the PdfToLinearizedPdfConverter class converter = PdfToLinearizedPdfConverter(inputFile) # Convert the PDF document to a linearized PDF converter.ToLinearizedPdf(outputFile)
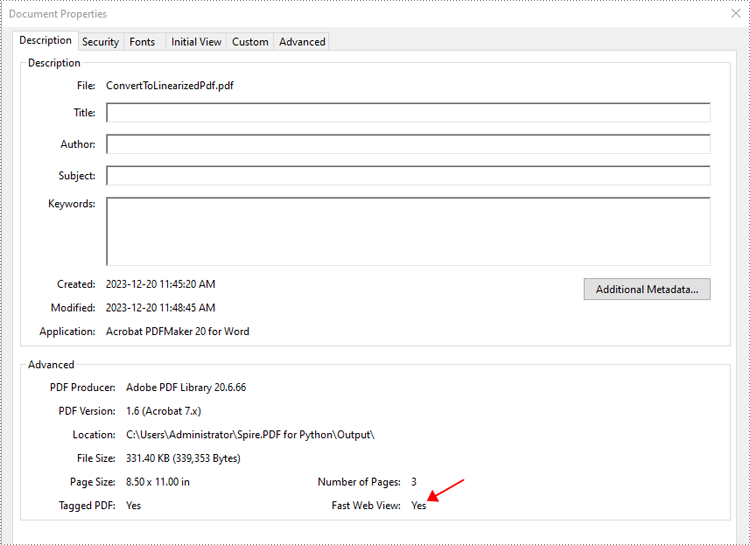
Open the result file in Adobe Acrobat and check the document properties. You will see that the value for "Fast Web View" is set to "Yes", indicating that the file has been linearized.
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.XLS 14.9.5 supports adding filters to row fields/column fields of pivot tables
We are excited to announce the release of Spire.XLS 14.9.5. The latest version supports adding filters to row fields/column fields of pivot tables. Furthermore, some known bugs are successfully fixed in this update, such as the issue that the content is incorrect when converting Excel documents to images. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREXLS-5255 | Supports adding filters to row fields/column fields of pivot tables.
XlsPivotTable pt1 = workbook.Worksheets["PivotTable_1"].PivotTables[0] as XlsPivotTable; pt1.RowFields[0].AddValueFilter(PivotValueFilterType.Between, pt1.DataFields[0], 100000, 1000000); pt1.ColumnFields[0].AddValueFilter(PivotValueFilterType.Between, pt1.DataFields[0], 100000, 1000000); pt1.CalculateData(); |
| New feature | SPIREXLS-5393 | Supports the TEXTBEFORE formula.
workbook.Worksheets[0].Range["A1"].Formula = "=TEXTBEFORE(\"Red riding hood's, red hood\", \"hood\")"; |
| New feature | SPIREXLS-5394 | Supports the TEXTSPLIT formula.
Supports the issue that the TEXTSPLIT formula is now available. workbook.Worksheets[0].Range["B2:D2"].FormulaArray = "=TEXTSPLIT(A2, \" \")"; |
| New feature | SPIREXLS-5397 | Supports the TEXTAFTER formula.
workbook.Worksheets[0].Range["A3"].Formula = "=TEXTAFTER(\"Red riding hood’s, red hood\", \"\")"; |
| Bug | SPIREXLS-5355 | Fixes the issue that the content is incorrect when converting Excel documents to images. |
| Bug | SPIREXLS-5467 | Fixes the issue that an exception "System.InvalidCastException" is thrown when copying worksheets containing charts. |
| Bug | SPIREXLS-5468 | Fixes the issue that there is a discrepancy in data after the decimal point when converting Excel documents to PDF. |
Python: Insert, Modify and Delete Sparklines in Excel
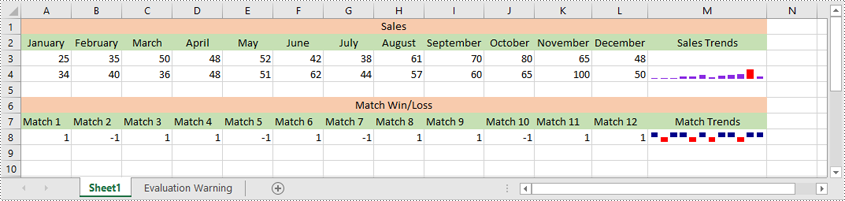
Sparklines in Excel are small, lightweight charts that fit inside individual cells of a worksheet. They are particularly useful for showing variations in data across rows or columns, allowing users to quickly identify trends without taking up much space. In this article, we'll demonstrate how to insert, modify, and delete sparklines in Excel in Python using Spire.XLS for Python.
- Insert a Sparkline in Excel in Python
- Modify a Sparkline in Excel in Python
- Delete Sparklines from Excel in Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
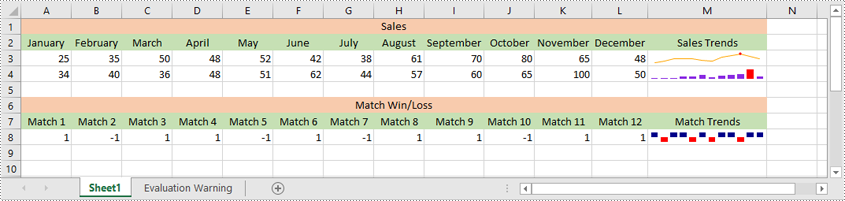
Insert a Sparkline in Excel in Python
Excel offers 3 main types of sparklines:
- Line Sparkline: Shows data trends as a line, similar to a miniature line graph.
- Column Sparkline: Displays data as vertical bars, emphasizing individual data points.
- Win/Loss Sparkline: Illustrates positive and negative values, useful for tracking binary outcomes like wins or losses.
Spire.XLS for Python supports inserting all of the above types of sparklines. Below are the detailed steps for inserting a sparkline in Excel using Spire.XLS for Python:
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Add a sparkline group to the worksheet using Worksheet.SparklineGroups.AddGroup() method.
- Specify the sparkline type, color, and data point color for the sparkline group.
- Add a sparkline collection to the group using SparklineGroup.Add() method, and then add a sparkline to the collection using SparklineCollection.Add() method.
- Save the resulting file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet in the workbook
sheet = workbook.Worksheets[0]
# Add a sparkline group to the worksheet
sparkline_group1 = sheet.SparklineGroups.AddGroup()
# Set the sparkline type to line
sparkline_group1.SparklineType = SparklineType.Line
# Set the sparkline color
sparkline_group1.SparklineColor = Color.get_Orange()
# Set the highest data point color
sparkline_group1.HighPointColor = Color.get_Red()
# Add a sparkline collection
sparklines1 = sparkline_group1.Add()
# Add a sparkline to the collection, define the data range for the sparkline and the target cell for displaying the sparkline
sparklines1.Add(sheet.Range["A3:L3"], sheet.Range["M3"])
# Add a sparkline group to the worksheet
sparkline_group2 = sheet.SparklineGroups.AddGroup()
# Set the sparkline type to column
sparkline_group2.SparklineType = SparklineType.Column
# Set the sparkline color
sparkline_group2.SparklineColor = Color.get_BlueViolet()
# Set the highest data point color
sparkline_group2.HighPointColor = Color.get_Red()
# Add a sparkline collection
sparklines2 = sparkline_group2.Add()
# Add a sparkline to the collection, define the data range for the sparkline and the target cell for displaying the sparkline
sparklines2.Add(sheet.Range["A4:L4"], sheet.Range["M4"])
# Add a sparkline group to the worksheet
sparkline_group3 = sheet.SparklineGroups.AddGroup()
# Set the sparkline type to stacked (win/loss)
sparkline_group3.SparklineType = SparklineType.Stacked
# Set the sparkline color
sparkline_group3.SparklineColor = Color.get_DarkBlue()
# Set the negative data point color
sparkline_group3.NegativePointColor = Color.get_Red()
# Add a sparkline collection
sparklines3 = sparkline_group3.Add()
# Add a sparkline to the collection, define the data range for the sparkline and the target cell for displaying the sparkline
sparklines3.Add(sheet.Range["A8:L8"], sheet.Range["M8"])
# Save the resulting workbook to file
workbook.SaveToFile("AddSparklines.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Modify a Sparkline in Excel in Python
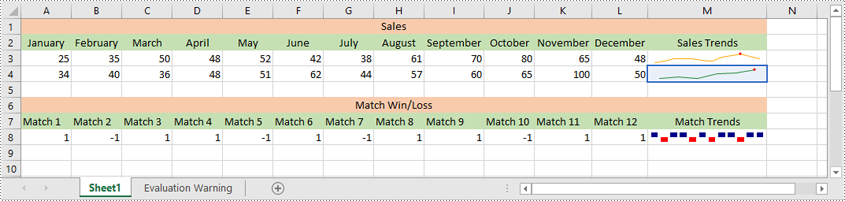
After inserting a sparkline, you can modify its type, color, and data source to make it more effective at displaying the information you need.
The following steps explain how to modify a sparkline in Excel using Spire.XLS for Python:
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Get a specific sparkline group in the worksheet using Worksheet.SparklineGroups[index] property.
- Change the sparkline type and color for the sparkline group using SparklineGroup.SparklineType and SparklineGroup.SparklineColor properties.
- Get a specific sparkline in the group and change its data source using ISparklines.RefreshRanges() method.
- Save the resulting file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file that contains sparklines
workbook.LoadFromFile("AddSparklines.xlsx")
# Get the first worksheet in the workbook
sheet = workbook.Worksheets[0]
# Get the second sparkline group
sparklineGroup = sheet.SparklineGroups[1]
# Change the sparkline type
sparklineGroup.SparklineType = SparklineType.Line
# Change the sparkline color
sparklineGroup.SparklineColor = Color.get_ForestGreen()
# Change the data range of the sparkline
sparklines = sparklineGroup[0]
sparklines.RefreshRanges(sheet.Range["A4:F4"], sheet.Range["M4"])
# Save the resulting workbook to file
workbook.SaveToFile("ModifySparklines.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Delete Sparklines from Excel in Python
Spire.XLS for Python allows you to remove specific sparklines from a sparkline group and to remove the entire sparkline group from an Excel worksheet.
The following steps explain how to remove an entire sparkline group or specific sparklines from a sparkline group using Spire.XLS for Python:
- Create an object of the Workbook class
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Get a specific sparkline group in the worksheet using Worksheet.SparklineGroups[index] property.
- Delete the entire sparkline group using Worksheet.SparklineGroups.Clear() method. Or delete a specific sparkline using ISparklines.Remove() method.
- Save the resulting file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file that contains sparklines
workbook.LoadFromFile("AddSparklines.xlsx")
# Get the first worksheet in the workbook
sheet = workbook.Worksheets[0]
# Get the first sparkline group in the worksheet
sparklineGroup = sheet.SparklineGroups[0]
# Remove the first sparkline group from the worksheet
sheet.SparklineGroups.Clear(sparklineGroup)
# # Remove the first sparkline
# sparklines = sparklineGroup[0]
# sparklines.Remove(sparklines[0])
# Save the resulting workbook to file
workbook.SaveToFile("RemoveSparklines.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#: Convert Text to Numbers and Numbers to Text
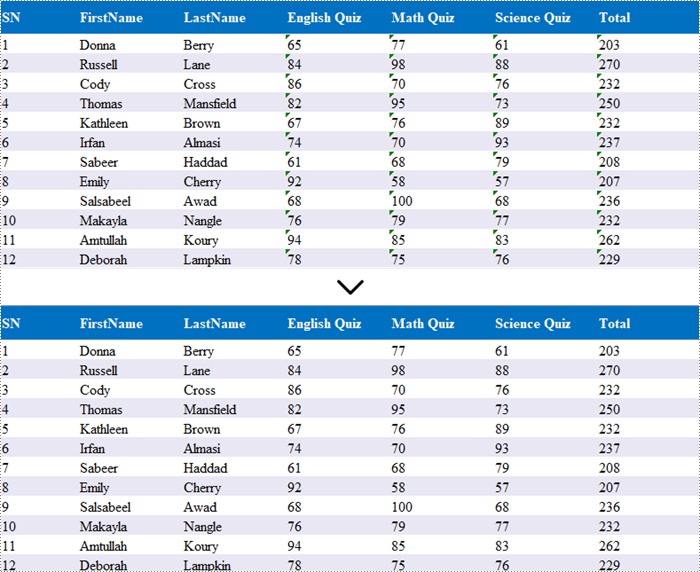
Transforming text to numbers and vice versa in Excel is essential for effective data management. By converting text to numbers, you enhance the accuracy of calculations and data processing, which is vital for activities such as financial reporting and statistical analysis. Conversely, changing numbers to text can improve formatting, making outputs clearer and more readable, ultimately presenting data in a more user-friendly way.
In this article, you will learn how to convert text to numbers and numbers to text in Excel using Spire.XLS for .NET.
Install Spire.XLS for .NET
To begin with, you need to add the DLL files included in the Spire.XLS for .NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.XLS
Convert Text to Numbers in C#
When you import data from an external source into Excel, you might notice a small green triangle in the upper-left corner of certain cells. This triangle serves as an error indicator, signaling that the number is formatted as text. When numbers are stored as text, it can lead to unexpected outcomes, such as formulas not calculating correctly and displaying as text instead of yielding results.
To convert text-formatted numbers back to numeric format, you can use the CellRange.ConvertToNumber() method. The CellRange object can refer to either a single cell or a range of cells.
Here are the steps to convert text to numbers in Excel:
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Access a specific worksheet with Workbook.Worksheets[index] property.
- Retrieve a cell or range of cells using Worksheet.Range property.
- Convert the text in the cell(s) to numbers using CellRange.ConvertToNumber() method.
- Save the document as a new Excel file.
- C#
using Spire.Xls;
namespace ConvertTextToNumbers
{
class Program
{
static void Main(string[] args)
{
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel document
workbook.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.xlsx");
// Get a specific worksheet
Worksheet worksheet = workbook.Worksheets[0];
// Get a cell range
CellRange range = worksheet.Range["D2:G13"];
// Convert text to number
range.ConvertToNumber();
// Save the workbook to a different Excel file
workbook.SaveToFile("TextToNumbers.xlsx", ExcelVersion.Version2013);
// Dispose resources
workbook.Dispose();
}
}
}
Convert Numbers to Text in C#
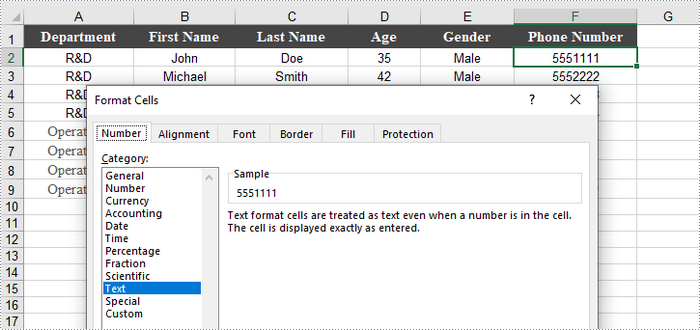
When working with numerical data in Excel, you may find occasions where converting numbers to text is necessary. This is especially crucial for data that requires specific formatting, such as IDs or phone numbers, where leading zeros must be preserved.
To convert a number in a cell to text, you can set the CellRange.NumberFormat property to @. The CellRange object can represent either a single cell or a range of cells.
Here are the steps to convert numbers to text in Excel:
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Access a specific worksheet through Workbook.Worksheets[index] property.
- Retrieve a specific cell or range of cells using Worksheet.Range property.
- Convert the numbers in the cell(s) to text by setting CellRange.NumberFormat to @.
- Save the document as a new Excel file.
- C#
using Spire.Xls;
namespace ConvertNumbersToText
{
class Program
{
static void Main(string[] args)
{
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel document
workbook.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Employee.xlsx");
// Get a specific worksheet
Worksheet worksheet = workbook.Worksheets[0];
// Get a cell range
CellRange cellRange = worksheet.Range["F2:F9"];
// Convert numbers in the cell range to text
cellRange.NumberFormat = "@";
// Save the workbook to a different Excel file
workbook.SaveToFile("NumbersToText.xlsx", ExcelVersion.Version2013);
// Dispose resources
workbook.Dispose();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Set Viewer Preferences of PDF Documents
Setting view preferences in PDF documents is a crucial feature that can significantly enhance user experience. By configuring options like page layout, display mode, and zoom level, you ensure recipients view the document as intended, without manual adjustments. This is especially useful for business reports, design plans, or educational materials, where consistent presentation is crucial for effectively delivering information and leaving a professional impression. This article will show how to set view preferences of PDF documents with Python code using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Set PDF Viewer Preferences with Python
Viewer preferences allow document creators to define how a PDF document is displayed when opened, including page layout, window layout, and display mode. Developers can use the properties under ViewerPreferences class to set those display options. The detailed steps are as follows:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the ViewerPreferences through using PdfDocument.ViewerPreferences property.
- Set the viewer preferences using properties under ViewerPreferences class.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the viewer preferences
preferences = pdf.ViewerPreferences
# Set the viewer preferences
preferences.FitWindow = True
preferences.CenterWindow = True
preferences.HideMenubar = True
preferences.HideToolbar = True
preferences.DisplayTitle = True
preferences.HideWindowUI = True
preferences.PageLayout = PdfPageLayout.SinglePage
preferences.BookMarkExpandOrCollapse = True
preferences.PrintScaling = PrintScalingMode.AppDefault
preferences.PageMode = PdfPageMode.UseThumbs
# Save the document
pdf.SaveToFile("output/ViewerPreferences.pdf")
pdf.Close()
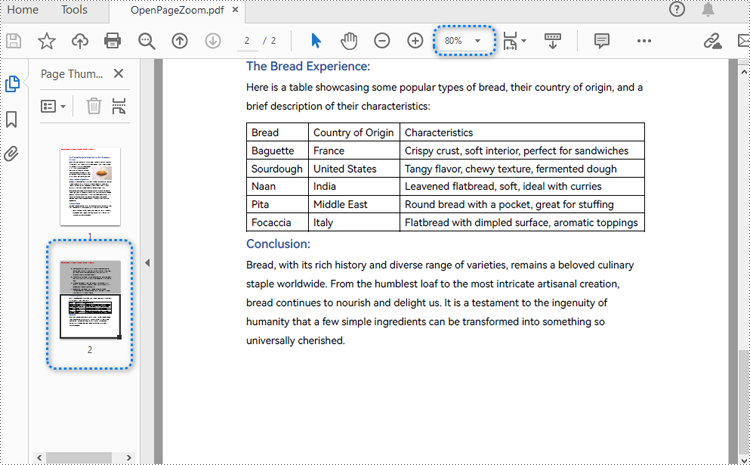
Set the Opening Page and Zoom Level with Python
By creating PDF actions and setting them to be executed when the document is opened, developers can configure additional viewer preferences, such as the initial page display and zoom level. Here are the steps to follow:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfDestination object and set the location and zoom factor of the destination.
- Create a PdfGoToAction object using the destination.
- Set the action as the document open action through PdfDocument.AfterOpenAction property.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample1.pdf")
# Get the second page
page = pdf.Pages.get_Item(1)
# Create a PdfDestination object
dest = PdfDestination(page)
# Set the location and zoom factor of the destination
dest.Mode = PdfDestinationMode.Location
dest.Location = PointF(0.0, page.Size.Height / 2)
dest.Zoom = 0.8
# Create a PdfGoToAction object
action = PdfGoToAction(dest)
# Set the action as the document open action
pdf.AfterOpenAction = action
# Save the document
pdf.SaveToFile("output/OpenPageZoom.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create Pivot Charts in Excel
Pivot charts are a powerful tool in Excel that allows you to visualize data from pivot tables in an easy-to-understand format. They enable users to summarize large datasets, highlight trends, and make data-driven decisions through interactive graphs. Whether you're analyzing sales figures, performance metrics, or any other form of data, pivot charts provide a dynamic way to represent complex data visually. In this article, we will demonstrate how to create pivot charts in Excel in Python using Spire.XLS for Python.
- Create Pivot Charts in Excel in Python
- Show or Hide Field Buttons in Pivot Charts in Excel in Python
- Format Pivot Chart Series in Excel in Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
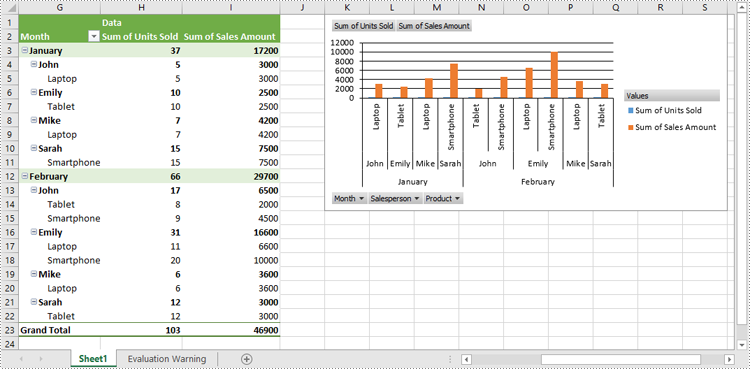
Create Pivot Charts in Excel in Python
Spire.XLS for Python provides the Worksheet.Charts.Add(pivotChartType:ExcelChartType, pivotTable:IPivotTable) method to create a pivot chart based on a specific pivot table in Excel. The detailed steps are as follows:
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet in the Excel file using Workbook.Worksheets[index] property.
- Get a specific pivot table in the worksheet using Worksheet.PivotTables[index] property.
- Add a pivot chart based on the pivot table to the worksheet using Worksheet.Charts.Add(pivotChartType:ExcelChartType, pivotTable:IPivotTable) method.
- Set the position and title of the pivot chart.
- Save the resulting file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("PivotTable.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the first pivot table in the worksheet
pivotTable = sheet.PivotTables[0]
# Create a clustered column chart based on the pivot table
pivotChart = sheet.Charts.Add(ExcelChartType.ColumnClustered, pivotTable)
# Set chart position
pivotChart.TopRow = 1
pivotChart.LeftColumn = 11
pivotChart.RightColumn = 20
pivotChart.BottomRow = 15
# Set chart title to null
pivotChart.ChartTitle = ""
# Save the resulting file
workbook.SaveToFile("CreatePivotChart.xlsx", ExcelVersion.Version2013)
workbook.Dispose()
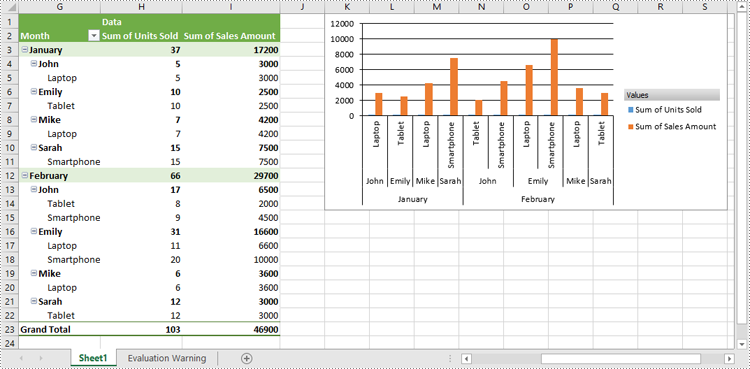
Show or Hide Field Buttons in Pivot Charts in Excel in Python
You can show or hide the following field buttons in a pivot chart with Spire.XLS for Python:
- Entire Field Buttons
- Report Filter Field Buttons
- Legend Field Buttons
- Axis Field Buttons
- Value Field Buttons
The detailed steps are as follows:
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet in the Excel file using Workbook.Worksheets[index] property.
- Get a specific pivot table in the worksheet using Worksheet.PivotTables[index] property.
- Add a pivot chart based on the pivot table to the worksheet using Worksheet.Charts.Add(pivotChartType:ExcelChartType, pivotTable:IPivotTable) method.
- Set the position and title of the pivot chart.
- Hide specific field buttons in the pivot chart, such as the axis field buttons and the value field buttons, using Chart.DisplayAxisFieldButtons and Chart.DisplayValueFieldButtons properties.
- Save the resulting file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("CreatePivotChart.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the first pivot table in the worksheet
pivotTable = sheet.PivotTables[0]
# Create a clustered column chart based on the pivot table
pivotChart = sheet.Charts.Add(ExcelChartType.ColumnClustered, pivotTable)
# Set chart position
pivotChart.TopRow = 1
pivotChart.LeftColumn = 11
pivotChart.RightColumn = 20
pivotChart.BottomRow = 15
# Set chart title to null
pivotChart.ChartTitle = ""
# Hide specific field buttons
pivotChart.DisplayAxisFieldButtons = False
pivotChart.DisplayValueFieldButtons = False
# pivotChart.DisplayLegendFieldButtons = False
# pivotChart.ShowReportFilterFieldButtons = False
# pivotChart.DisplayEntireFieldButtons = False
# Save the resulting file
workbook.SaveToFile("HideFieldButtons.xlsx", ExcelVersion.Version2013)
workbook.Dispose()
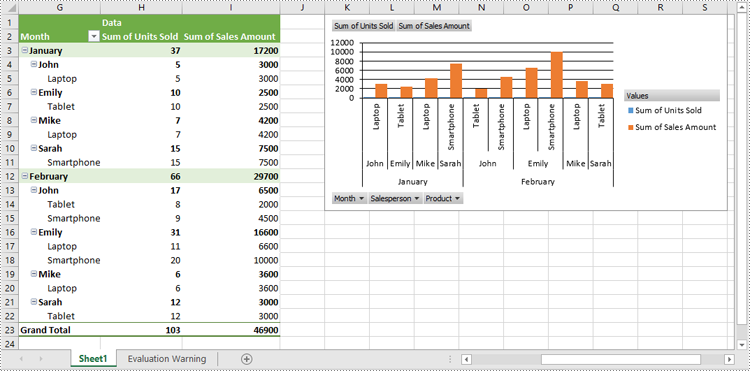
Format Pivot Chart Series in Excel in Python
When generating a pivot chart using a pivot table as the data source with Spire.XLS for Python, the chart series are not automatically created. You need to add the series to the pivot chart and then apply the desired formatting. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet in the Excel file using Workbook.Worksheets[index] property.
- Get a specific pivot table in the worksheet using Worksheet.PivotTables[index] property.
- Add a pivot chart based on the pivot table to the worksheet using Worksheet.Charts.Add(pivotChartType:ExcelChartType, pivotTable:IPivotTable) method.
- Set the position and title of the pivot chart.
- Add series to the chart using Chart.Series.Add() method and then apply the desired formatting to the series.
- Save the resulting file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("CreatePivotChart.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the first pivot table in the worksheet
pivotTable = sheet.PivotTables[0]
# Create a clustered column chart based on the pivot table
pivotChart = sheet.Charts.Add(ExcelChartType.ColumnClustered, pivotTable)
# Set chart position
pivotChart.TopRow = 1
pivotChart.LeftColumn = 11
pivotChart.RightColumn = 20
pivotChart.BottomRow = 15
# Set chart title to null
pivotChart.ChartTitle = ""
# Add chart series
series = pivotChart.Series.Add(ExcelChartType.ColumnClustered)
# Set bar width
series.GetCommonSerieFormat().GapWidth = 10
# Set overlap
# series.GetCommonSerieFormat().Overlap = 100
# Save the resulting file
workbook.SaveToFile("FormatChartSeries.xlsx", ExcelVersion.Version2013)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.