C#: Add Filters to Pivot Tables in Excel
Filters in pivot tables enable users to narrow down the displayed data based on specific criteria. By adding filters, users can focus on subsets of data that are most relevant to their analysis, allowing for a more targeted and efficient data exploration. In this article, we will demonstrate how to add filters to pivot tables in Excel in C# using Spire.XLS for .NET.
- Add Report Filter to Pivot Table in Excel in C#
- Add Filter to a Row Field of Pivot Table in Excel in C#
- Add Filter to a Column Field of Pivot Table in Excel in C#
Install Spire.XLS for .NET
To begin with, you need to add the DLL files included in the Spire.XLS for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.XLS
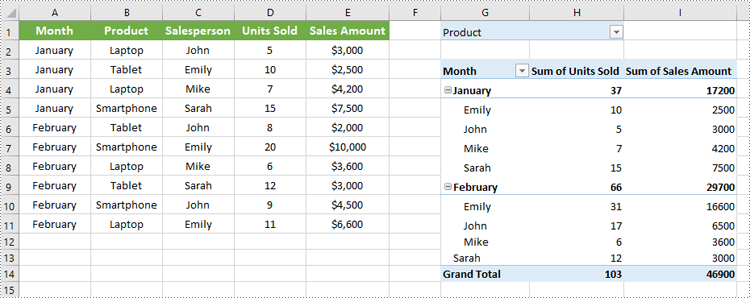
Add Report Filter to Pivot Table in Excel in C#
Spire.XLS for .NET offers the XlsPivotTable.ReportFilters.Add() method to add report filters to a pivot table. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet in the file using Workbook.Worksheets[index] property.
- Get a specific pivot table in the worksheet using Worksheet.PivotTables[index] property.
- Create a report filter using PovotReportFilter class.
- Add the report filter to the pivot table using XlsPivotTable.ReportFilters.Add() method.
- Save the resulting file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
using Spire.Xls.Core.Spreadsheet.PivotTables;
namespace AddReportFilter
{
internal class Program
{
static void Main(string[] args)
{
// Create an object of the Workbook class
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the first pivot table
XlsPivotTable pt = sheet.PivotTables[0] as XlsPivotTable;
// Create a report filter
PivotReportFilter reportFilter = new PivotReportFilter("Product", true);
// Add the report filter to the pivot table
pt.ReportFilters.Add(reportFilter);
// Save the resulting file
workbook.SaveToFile("AddReportFilter.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
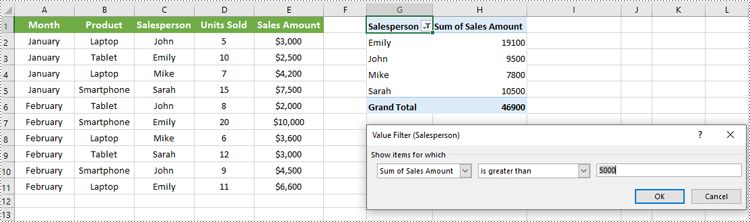
Add Filter to a Row Field of Pivot Table in Excel in C#
You can add a value filter or label filter to a specific row field in a pivot table using the XlsPivotTable.RowFields[index].AddValueFilter() or XlsPivotTable.RowFields[index].AddLabelFilter() method. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet in the file using Workbook.Worksheets[index] property.
- Get a specific pivot table in the worksheet using Worksheet.PivotTables[index] property.
- Add a value filter or label filter to a specific row field in the pivot table using XlsPivotTable.RowFields[index].AddValueFilter() or XlsPivotTable.RowFields[index].AddLabelFilter() method.
- Calculate the data in the pivot table using XlsPivotTable.CalculateData() method.
- Save the resulting file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
using Spire.Xls.Core.Spreadsheet.PivotTables;
namespace AddRowFilter
{
internal class Program
{
static void Main(string[] args)
{
// Create an object of the Workbook class
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the first pivot table
XlsPivotTable pt = sheet.PivotTables[0] as XlsPivotTable;
// Add a value filter to the first row field in the pivot table
pt.RowFields[0].AddValueFilter(PivotValueFilterType.GreaterThan, pt.DataFields[0], 5000, null);
// Or add a label filter to the first row field in the pivot table
//pt.RowFields[0].AddLabelFilter(PivotLabelFilterType.Equal, "Mike", null);
// Calculate the pivot table data
pt.CalculateData();
// Save the resulting file
workbook.SaveToFile("AddRowFilter.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
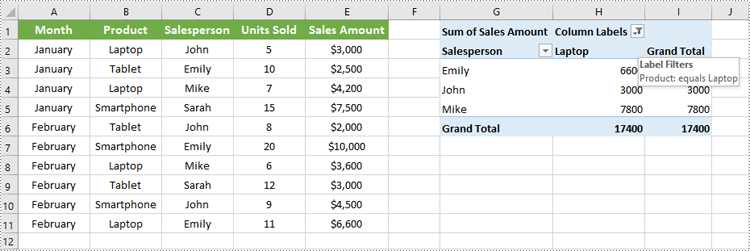
Add Filter to a Column Field of Pivot Table in Excel in C#
To add a value filter or label filter to a specific column field in a pivot table, you can use the XlsPivotTable.ColumnFields[index].AddValueFilter() or XlsPivotTable.ColumnFields[index].AddLabelFilter() method. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet in the file using Workbook.Worksheets[index] property.
- Get a specific pivot table in the worksheet using Worksheet.PivotTables[index] property.
- Add a value filter or label filter to a specific column field in the pivot table using XlsPivotTable.ColumnFields[index].AddValueFilter() or XlsPivotTable.ColumnFields[index].AddLabelFilter() method.
- Calculate the data in the pivot table using XlsPivotTable.CalculateData() method.
- Save the resulting file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
using Spire.Xls.Core.Spreadsheet.PivotTables;
namespace AddColumnFilter
{
internal class Program
{
static void Main(string[] args)
{
// Create an object of the Workbook class
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the first pivot table
XlsPivotTable pt = sheet.PivotTables[0] as XlsPivotTable;
// Add a label filter to the first column field in the pivot table
pt.ColumnFields[0].AddLabelFilter(PivotLabelFilterType.Equal, "Laptop", null);
// Or add a value filter to the first column field in the pivot table
// pt.ColumnFields[0].AddValueFilter(PivotValueFilterType.Between, pt.DataFields[0], 5000, 10000);
// Calculate the pivot table data
pt.CalculateData();
// Save the resulting file
workbook.SaveToFile("AddColumnFilter.xlsx", FileFormat.Version2016);
workbook.Dispose();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Detect and Remove Digital Signatures in Excel Files
Digital signatures serve as a critical layer of security, ensuring that an Excel file has not been altered since it was signed and verifying the identity of its originator. However, there are scenarios where the detection and removal of these digital signatures become necessary, such as when consolidating multiple documents, updating content, or preparing files for systems that do not support digitally signed documents. This article shows how to detect and remove digital signatures in Excel files with Python code using Spire.XLS for Python, providing a simple way to batch process Excel file digital signatures.
- Detecting the Presence of Digital Signatures in Excel Files
- Removing Digital Signatures from Excel Files
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.XLS
If you are unsure how to install, please refer to: How to Install Spire.XLS for Python on Windows
Detecting the Presence of Digital Signatures in Excel Files
Spire.XLS for Python provides the Workbook class to deal with Excel files and the Workbook.IsDigitallySigned property to check if an Excel file has digital signatures. Developers can use the Boolean value returned by this property to determine whether the Excel file contains a digital signature.
The detailed steps for detecting if an Excel file has digital signatures are as follows:
- Create an instance of Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Check whether the workbook is digitally signed by the value of the Workbook.IsDigitallySigned property.
- Python
from spire.xls import *
# Create an instance of Workbook
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Check whether the workbook is digitally signed
if workbook.IsDigitallySigned is False:
print("The workbook is not digitally signed.")
else:
print("The workbook is digitally signed.")
Removing Digital Signatures from Excel Files
Developers can use the Workbook.RemoveAllDigitalSignatures() method to effortlessly delete all digital signatures in an Excel workbook. The detailed steps are as follows:
- Create an instance of Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Remove all digital signatures from the workbook using Workbook.RemoveAllDigitalSignatures() method.
- Save the workbook using Workbook.SaveToFile() method.
- Python
from spire.xls import *
# Create an instance of Workbook
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Remove digital signatures
workbook.RemoveAllDigitalSignatures()
# Save the document
workbook.SaveToFile("output/RemoveExcelDigitalSignature.xlsx", FileFormat.Version2016)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#: Import and Export PDF Form Data
Importing and exporting PDF form data allows users to seamlessly exchange form information with external files in formats such as FDF (Forms Data Format), XFDF (XML Forms Data Format), or XML. The import function enables quick population of PDF forms using data from external sources, while the export function extracts data from PDF forms and saves it to external files. This capability simplifies data management, making it especially valuable for processing large volumes of form data or integrating with other systems. In this article, we will demonstrate how to import PDF form data from FDF, XFDF, or XML files, or export PDF form data to FDF, XFDF, or XML files in C# using Spire.PDF for .NET.
- Import PDF Form Data from FDF, XFDF or XML Files in C#
- Export PDF Form Data to FDF, XFDF or XML Files in C#
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLLs files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
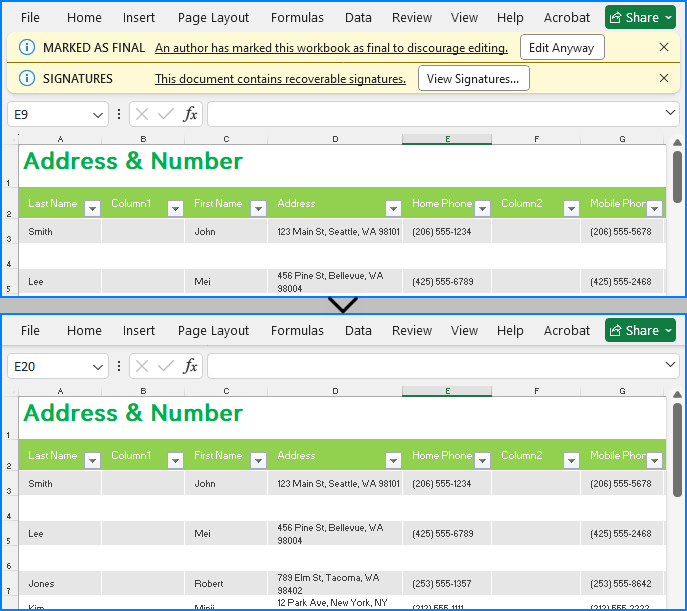
Import PDF Form Data from FDF, XFDF or XML Files in C#
Spire.PDF for .NET offers the PdfFormWidget.ImportData() method for importing PDF form data from FDF, XFDF, or XML files. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using PdfDocument.Form property.
- Import form data from an FDF, XFDF or XML file using PdfFormWidget.ImportData() method.
- Save the resulting document using PdfDocument.SaveToFile() method.
- C#
using Spire.Pdf;
using Spire.Pdf.Widget;
namespace ImportPdfFormData
{
internal class Program
{
static void Main(string[] args)
{
//Create an object of the PdfDocument class
PdfDocument document = new PdfDocument();
//Load a PDF document
document.LoadFromFile("Forms.pdf");
//Get the form of the PDF document
PdfFormWidget loadedForm = document.Form as PdfFormWidget;
//Import PDF form data from an XML file
loadedForm.ImportData("Data.xml", DataFormat.Xml);
//Import PDF form data from an FDF file
//loadedForm.ImportData("Data.fdf", DataFormat.Fdf);
//Import PDF form data from an XFDF file
//loadedForm.ImportData("Data.xfdf", DataFormat.XFdf);
//Save the resulting document
document.SaveToFile("Output.pdf");
//Close the PdfDocument object
document.Close();
}
}
}
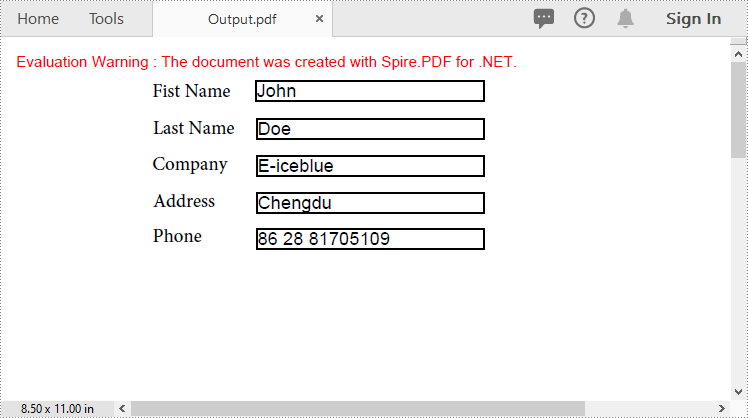
Export PDF Form Data to FDF, XFDF or XML Files in C#
Spire.PDF for .NET also enables you to export PDF form data to FDF, XFDF, or XML files by using the PdfFormWidget.ExportData() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using PdfDocument.Form property.
- Export form data to an FDF, XFDF or XML file using PdfFormWidget.ExportData() method.
- C#
using Spire.Pdf;
using Spire.Pdf.Fields;
using Spire.Pdf.Widget;
namespace ExportPdfFormData
{
internal class Program
{
static void Main(string[] args)
{
//Create an object of the PdfDocument class
PdfDocument document = new PdfDocument();
//Load a PDF document
document.LoadFromFile("Forms.pdf");
//Get the form of the PDF document
PdfFormWidget loadedForm = document.Form as PdfFormWidget;
//Export PDF form data to an XML file
loadedForm.ExportData("Data.xml", DataFormat.Xml, "Form");
//Export PDF form data to an FDF file
//loadedForm.ExportData("Data.fdf", DataFormat.Fdf, "Form");
//Export PDF form data to an XFDF file
//loadedForm.ExportData("Data.xfdf", DataFormat.XFdf, "Form");
//Close the PdfDocument object
document.Close();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Doc 12.10.5 adds new methods to track the addition, deletion, and modification of document elements
We're pleased to announce the release of Spire.Doc 12.10.5. This version adds new methods to track the addition, deletion, and modification of document elements, and also supports modifying the revision author. Furthermore, the issues that occurred when converting Word to PDF/HTML and loading Word files have been successfully fixed. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Adds new methods to track the addition, deletion, and modification of document elements.
public void StartTrackRevisions(string author); public void StartTrackRevisions(string author, DateTime dateTime); public void StopTrackRevisions(); |
| New feature | SPIREDOC-10831 | Supports modification of the revision author.
range.InsertRevision.Author = "e-iceblue"; |
| Bug | SPIREDOC-9646 | Fixes the issue that the table content was missing when converting Word to PDF. |
| Bug | SPIREDOC-10588 | Fixes the issue that the program threw an "ArgumentException" when converting Word to HTML. |
| Bug | SPIREDOC-10727 | Fixes the issue of blank content when converting Word to PDF. |
| Bug | SPIREDOC-10766 | Fixes the issue that the program threw a "Cannot insert an object of type Paragraph into the Document" exception when loading Word document. |
Spire.PDF 10.10.0 supports ignoring images when converting PDF to Markdown
We are excited to announce the release of Spire.PDF 10.10.0. The latest version supports ignoring images when converting PDF to Markdown. Besides, some known bugs are fixed successfully, such as the issue that opening the resulting document after converting a PDF document to a PDF/A document caused an error. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-7003 | Supports ignoring images when converting PDF to Markdown.
PdfToMarkdownConverter converter = new PdfToMarkdownConverter(inputFile); converter.MarkdownOptions.IgnoreImage = true; converter.ConvertToMarkdown(outputFile); |
| New feature | SPIREPDF-7030 | Extends the PdfMDPSignatureMaker class to support passing an IPdfSignatureFormatter object.
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile(inputFile);
X509Certificate2 cert = new X509Certificate2(inputFile_pfx, "e-iceblue");
IPdfSignatureFormatter formatter = new PdfPKCS7Formatter(cert, false);
PdfMDPSignatureMaker pdfMDPSignatureMaker = new PdfMDPSignatureMaker(pdf, formatter);
PdfSignature signature = pdfMDPSignatureMaker.Signature;
signature.Name = "e-iceblue";
signature.ContactInfo = "028-81705109";
signature.Location = "chengdu";
signature.Reason = " this document";
PdfSignatureAppearance appearance = new PdfSignatureAppearance(signature);
appearance.NameLabel = "Signer: ";
appearance.ContactInfoLabel = "ContactInfo: ";
appearance.LocationLabel = "Loaction: ";
appearance.ReasonLabel = "Reason: ";
pdfMDPSignatureMaker.MakeSignature("signName", pdf.Pages[0], 100, 100, 250, 200, appearance);
pdf.SaveToFile(outputFile, FileFormat.PDF);
pdf.Dispose();
|
| New feature | SPIREPDF-7030 | Supports signing existing signature fields using either the PdfOrdinarySignatureMaker class or the PdfMDPSignatureMaker class.
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile(inputFile);
PdfFormWidget widgets = pdf.Form as PdfFormWidget;
for (int i = 0; i < widgets.FieldsWidget.List.Count; i++)
{
PdfFieldWidget widget = widgets.FieldsWidget.List[i] as PdfFieldWidget;
if (widget is PdfSignatureFieldWidget)
{
string originalName = widget.Name;
X509Certificate2 cert = new X509Certificate2(inputFile_pfx, "e-iceblue");
IPdfSignatureFormatter formatter = new PdfPKCS7Formatter(cert, false);
// PdfMDPSignatureMaker signatureMaker = new PdfMDPSignatureMaker(pdf, formatter);
PdfOrdinarySignatureMaker signatureMaker = new PdfOrdinarySignatureMaker(pdf, formatter);
PdfSignature signature = signatureMaker.Signature;
signature.Name = "E-iceblue";
signature.ContactInfo = "028-81705109";
signature.Location = "chengdu";
signature.Reason = "document";
PdfSignatureAppearance appearance = new PdfSignatureAppearance(signature);
appearance.NameLabel = "Signer: ";
appearance.ContactInfoLabel = "ContactInfo: ";
appearance.LocationLabel = "Loaction: ";
appearance.ReasonLabel = "Reason: ";
appearance.SignatureImage = PdfImage.FromFile(inputFile_Img);
appearance.GraphicMode = GraphicMode.SignImageAndSignDetail;
signatureMaker.MakeSignature(originalName, appearance);
}
}
pdf.SaveToFile(outputFile);
pdf.Dispose();
|
| Bug | SPIREPDF-6736 | Fixes the issue that opening the resulting document after converting a PDF document to a PDFA document caused an error. |
| Bug | SPIREPDF-6946 | Fixes the issue that the application threw the System.IndexOutOfRangeException: "Index was outside the bounds of the array." exception when converting a PDF document to a PPTX document. |
| Bug | SPIREPDF-6948 | Fixes the issue that converting a PDF document to images experienced a decrease in speed. |
| Bug | SPIREPDF-7006 | Fixes the issue that validating the validity of signatures always returned false for the first signature. |
| Bug | SPIREPDF-7012 | Fixes the issue that the application threw the "Object reference not set to an instance of an object" exception when converting an OFD document to a PDF document. |
| Bug | SPIREPDF-7013 | Fixes the issue that the application threw the "Invalid font weight value: 681" exception when converting an OFD document to a PDF document. |
| Bug | SPIREPDF-7027 | Fixes the issue that converting an OFD document to a PDF document resulted in content loss. |
| Bug | SPIREPDF-7032 | Fixes the issue that the application threw the "Object reference not set to an instance of an object" exception when compressing a PDF document. |
| Bug | SPIREPDF-7046 | Fixes the issue that the application threw the "NullReferenceException" exception when converting a PDF document to a ToPdfA3B document without applying license. |
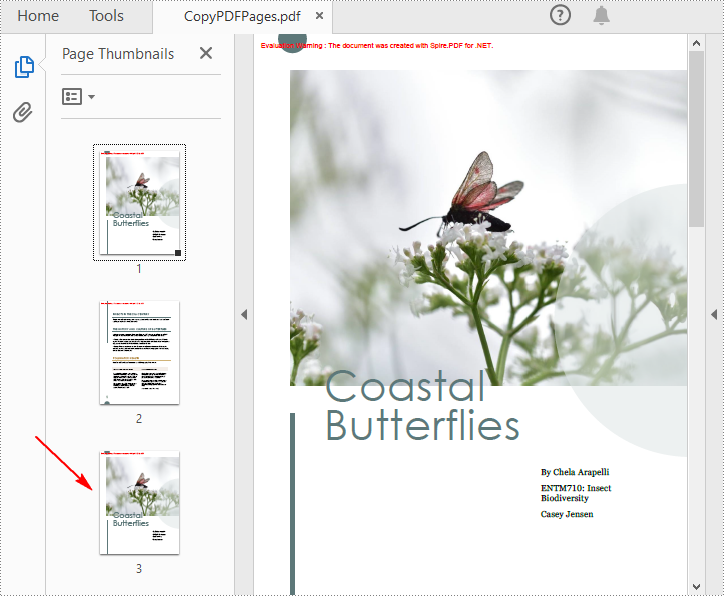
C#: Copy Pages in PDF
Copying PDF pages facilitates better organization of information. By copying pages that contain important sections and then compiling them into a new document, you can bring together relevant content from different sources to create a cohesive resource that is easy to navigate. In this article, you will learn how to copy pages in PDF in C# using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Copy Pages within the Same PDF in C#
To duplicate PDF pages, you can first create template based on a specified page in PDF, and then draw the template on a newly added page through the PdfPageBase.Canvas.DrawTemplate() method. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Get the size of the page using PdfPageBase.Size property.
- Create a template based on the page using PdfPageBase.CreateTemplate() method.
- Add a new page of the same size at the end using PdfDocument.Pages.Add(SizeF size, PdfMargins margins) method. Or you can insert a new page of the same size at a specified location using PdfDocument.Pages.Insert(int index, SizeF size, PdfMargins margins) method.
- Draw template on the newly added page using PdfPageBase.Canvas.DrawTemplate(PdfTemplate template, PointF location) method.
- Save the result file using PdfDocument.SaveToFile() method.
- C#
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace DuplicatePage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF file
pdf.LoadFromFile("Butterflies.pdf");
//Get the first page
PdfPageBase page = pdf.Pages[0];
//Get the size of the page
SizeF size = page.Size;
//Create a template based on the page
PdfTemplate template = page.CreateTemplate();
//Add a new page the same size as the first page
page = pdf.Pages.Add(size, new PdfMargins(0));
//Insert a new page at the specified location
//page = pdf.Pages.Insert(1, size, new PdfMargins(0));
//Draw the template on the newly added page
page.Canvas.DrawTemplate(template, new PointF(0, 0));
//Save the PDF file
pdf.SaveToFile("CopyPDFPages.pdf");
}
}
}
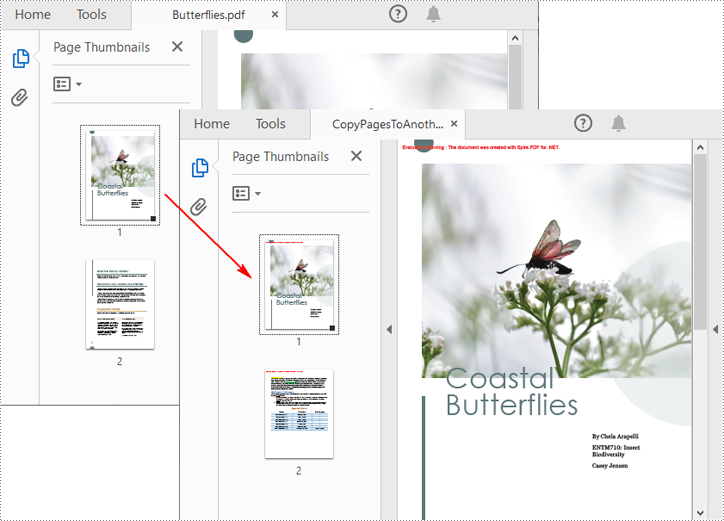
Copy Pages from One PDF to Another in C#
Spire.PDF for .NET also allows you to load two PDF files, create templates based on the pages in one PDF file, and then draw them onto the pages in another PDF file. The following are the detailed steps.
- Create a PdfDocument instance.
- Load two PDF files using PdfDocument.LoadFromFile() method.
- Get a specified page in the first PDF using PdfDocument.Pages[] property.
- Get the size of the page using PdfPageBase.Size property.
- Create a template based on the page using PdfPageBase.CreateTemplate() method.
- Insert a new page of the same size at a specified location in the second PDF using PdfDocument.Pages.Insert(int index, SizeF size, PdfMargins margins) method. Or you can add a new page of the same size at the end of the second PDF using PdfDocument.Pages.Add(SizeF size, PdfMargins margins) method.
- Draw template on the newly added page using PdfPageBase.Canvas.DrawTemplate(PdfTemplate template, PointF location) method.
- Save the result file using PdfDocument.SaveToFile() method.
- C#
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace CopyPageToAnother
{
class Program
{
static void Main(string[] args)
{
//Load the first PDF file
PdfDocument pdf1 = new PdfDocument();
pdf1.LoadFromFile("Butterflies.pdf");
//Load the second PDF file
PdfDocument pdf2 = new PdfDocument();
pdf2.LoadFromFile("SamplePDF.pdf");
//Get the first page in the first PDF file
PdfPageBase page = pdf1.Pages[0];
//Get the size of the page
SizeF size = page.Size;
//Create a template based on the page
PdfTemplate template = page.CreateTemplate();
//Insert a new page at a specified location in the second PDF file
PdfPageBase newPage = pdf2.Pages.Insert(0, size, new PdfMargins(0));
//Add a new page at the end of the second PDF file
//PdfPageBase newPage = pdf2.Pages.Add(size, new PdfMargins(0));
//Draw the template on the newly added page
newPage.Canvas.DrawTemplate(template, new PointF(0, 0));
//Save the result file
pdf2.SaveToFile("CopyPagesToAnotherPDF.pdf");
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.PDF for Java 10.10.0 supports returning error document information when merging documents reports errors
We are delighted to announce the release of Spire.PDF for Java 10.10.0. This version supports returning error document information when merging documents reports errors. Besides, some known issues are fixed in this version, such as the issue that the red seal became black after encrypting PDF documents. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-7017 | Supports returning error document information when merging documents reports errors. |
| Bug | SPIREPDF-7029 | Fixes the issue that the red seal became black after encrypting PDF documents. |
| Bug | SPIREPDF-7033 | Fixes the issue that the program threw "Unknown Target Area Type: Fit_H" exception when converting PDF to OFD. |
Python: Copy Pages in PDF
PDF format has now become a standard for sharing and preserving documents. When working with PDF files, you may sometimes need to copy specific pages in the PDF to extract valuable content, create summaries, or simply share relevant sections without distributing the entire document. In this article, you will learn how to copy pages in PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
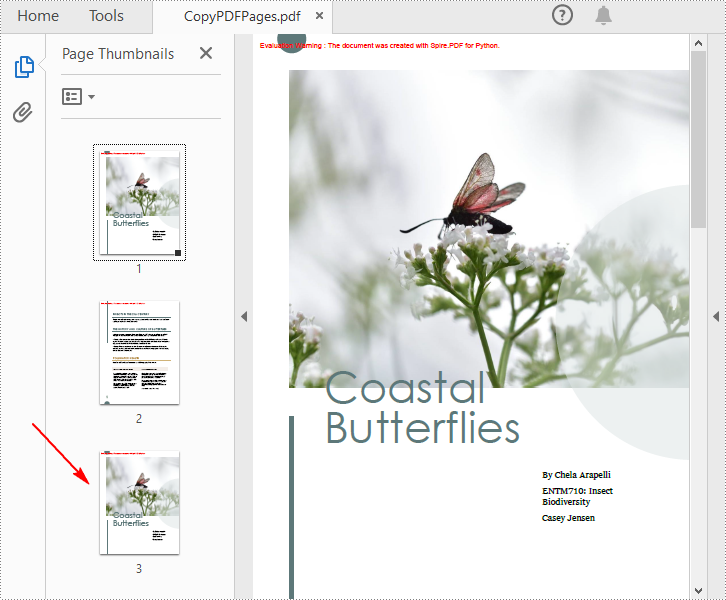
Copy Pages within the Same PDF in Python
To duplicate PDF pages, you can first create template based on a specified page in PDF, and then draw the template on a newly added page through the PdfPageBase.Canvas.DrawTemplate() method. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Get the size of the page using PdfPageBase.Size property.
- Create a template based on the page using PdfPageBase.CreateTemplate() method.
- Add a new page of the same size at the end using PdfDocument.Pages.Add(size: SizeF, margins: PdfMargins) method. Or you can insert a new page of the same size at a specified location using PdfDocument.Pages.Insert(index: int, size: SizeF, margins: PdfMargins) method.
- Draw template on the newly added page using PdfPageBase.Canvas.DrawTemplate(template: PdfTemplate, location: PointF) method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from disk
pdf.LoadFromFile("Butterflies.pdf")
# Get the first page
page = pdf.Pages[0]
# Get the size of the page
size = page.Size
# Create a template based on the page
template = page.CreateTemplate()
# Add a new page of the same size at the end
page = pdf.Pages.Add(size, PdfMargins(0.0))
# Insert a new page at the specified location
# page = pdf.Pages.Insert(1, size, PdfMargins(0.0))
# Draw the template on the newly added page
page.Canvas.DrawTemplate(template, PointF(0.0, 0.0))
# Save the PDF file
pdf.SaveToFile("CopyPDFPages.pdf");
pdf.Close()
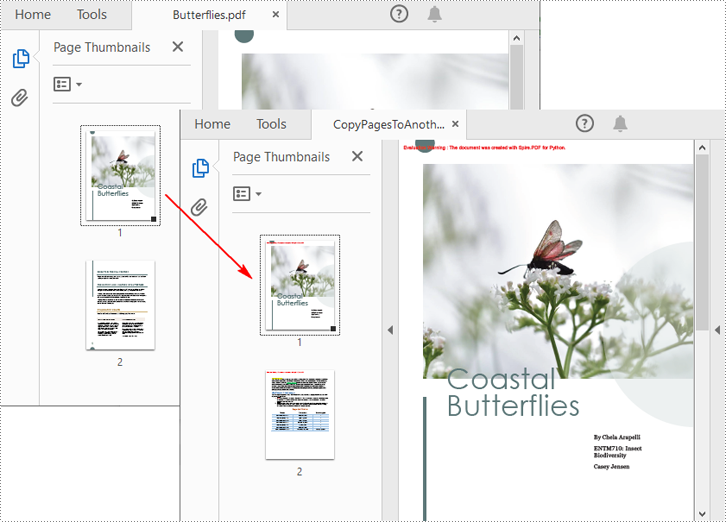
Copy Pages from One PDF to Another in Python
Spire.PDF for Python also allows you to load two PDF files, create templates based on the pages in one PDF file, and then draw them onto the pages in another PDF file. The following are the detailed steps.
- Create a PdfDocument instance.
- Load two PDF files using PdfDocument.LoadFromFile() method.
- Get a specified page in the first PDF using PdfDocument.Pages[] property.
- Get the size of the page using PdfPageBase.Size property.
- Create a template based on the page using PdfPageBase.CreateTemplate() method.
- Insert a new page of the same size at a specified location in the second PDF using PdfDocument.Pages.Insert(index: int, size: SizeF, margins: PdfMargins) method. Or you can add a new page of the same size at the end of the second PDF using PdfDocument.Pages.Add(size: SizeF, margins: PdfMargins) method.
- Draw template on the newly added page using PdfPageBase.Canvas.DrawTemplate(template: PdfTemplate, location: PointF) method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Load the first PDF file
pdf1 = PdfDocument()
pdf1.LoadFromFile("Butterflies.pdf")
# Load the second PDF file
pdf2 = PdfDocument()
pdf2.LoadFromFile("SamplePDF.pdf")
# Get the first page in the first PDF file
page = pdf1.Pages[0]
# Get the size of the page
size = page.Size
# Create a template based on the page
template = page.CreateTemplate()
# Insert a new page at a specified location in the second PDF file
newPage = pdf2.Pages.Insert(0, size, PdfMargins(0.0))
# Add a new page at the end of the second PDF file
# newPage = pdf2.Pages.Add(size, PdfMargins(0.0))
# Draw the template on the newly added page
newPage.Canvas.DrawTemplate(template, PointF(0.0, 0.0))
# Save the result file
pdf2.SaveToFile("CopyPagesToAnotherPDF.pdf")
pdf2.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create Pie Charts in Excel
A pie chart is a circular statistical graphic that is divided into slices to illustrate numerical proportions. Each slice represents a category's contribution to the whole, making it an effective way to visualize relative sizes. In this article, you will learn how to create a standard pip chart, an exploded pip chart, and a pie of pie chart in Excel using Spire.XLS for Python.
- Create a Pie Chart in Excel
- Create an Exploded Pie Chart in Excel
- Create a Pie of Pie Chart in Excel
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
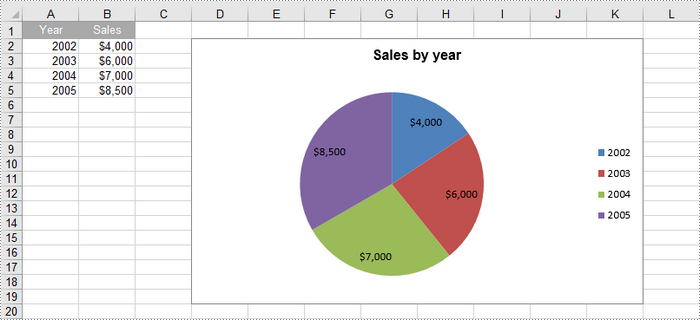
Create a Pie Chart in Excel in Python
To add a pie chart to a worksheet, use the Worksheet.Charts.Add(ExcelChartType.Pie) method, which returns a Chart object. You can then set various properties, such as DataRange, ChartTitle, LeftColumn, TopRow, and Series to define the chart's data, title, position, and series formatting.
Here are the steps to create a pie chart in Excel:
- Create a Workbook object.
- Retrieve a specific worksheet from the workbook.
- Insert values into the worksheet cells that will be used as chart data.
- Add a pie chart to the worksheet using Worksheet.Charts.Add(ExcelChartType.Pie) method.
- Set the chart data using Chart.DataRange property.
- Define the chart's position and size using Chart.LeftColumn, Chart.TopRow, Chart.RightColumn, and Chart.BottomRow properties.
- Set the chart title using Chart.ChartTitle property.
- Access and format the series through Chart.Series property.
- Save the workbook as an Excel file.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a workbook
workbook = Workbook()
# Get the first sheet
sheet = workbook.Worksheets[0]
# Set values of the specified cells
sheet.Range["A1"].Value = "Year"
sheet.Range["A2"].Value = "2002"
sheet.Range["A3"].Value = "2003"
sheet.Range["A4"].Value = "2004"
sheet.Range["A5"].Value = "2005"
sheet.Range["B1"].Value = "Sales"
sheet.Range["B2"].NumberValue = 4000
sheet.Range["B3"].NumberValue = 6000
sheet.Range["B4"].NumberValue = 7000
sheet.Range["B5"].NumberValue = 8500
# Format the cells
sheet.Range["A1:B1"].RowHeight = 15
sheet.Range["A1:B1"].Style.Color = Color.get_DarkGray()
sheet.Range["A1:B1"].Style.Font.Color = Color.get_White()
sheet.Range["A1:B1"].Style.VerticalAlignment = VerticalAlignType.Center
sheet.Range["A1:B1"].Style.HorizontalAlignment = HorizontalAlignType.Center
sheet.Range["B2:B5"].Style.NumberFormat = "\"$\"#,##0"
# Add a pie chart
chart = sheet.Charts.Add(ExcelChartType.Pie)
# Set region of chart data
chart.DataRange = sheet.Range["B2:B5"]
chart.SeriesDataFromRange = False
# Set position of chart
chart.LeftColumn = 4
chart.TopRow = 2
chart.RightColumn = 12
chart.BottomRow = 20
# Set chart title
chart.ChartTitle = "Sales by year"
chart.ChartTitleArea.IsBold = True
chart.ChartTitleArea.Size = 12
# Get the first series
cs = chart.Series[0]
# Set category labels for the series
cs.CategoryLabels = sheet.Range["A2:A5"]
# Set values for the series
cs.Values = sheet.Range["B2:B5"]
# Show vales in data labels
cs.DataPoints.DefaultDataPoint.DataLabels.HasValue = True
# Save the workbook to an Excel file
workbook.SaveToFile("output/PieChart.xlsx", ExcelVersion.Version2016)
# Dispose resources
workbook.Dispose()
Create an Exploded Pie Chart in Excel in Python
An exploded pie chart is a variation of the standard pie chart where one or more slices are separated or "exploded" from the main chart. To create an exploded pie chart, you can use the Worksheet.Charts.Add(ExcelChartType.PieExploded) method.
The steps to create an exploded pip chart in Excel are as follows:
- Create a Workbook object.
- Retrieve a specific worksheet from the workbook.
- Insert values into the worksheet cells that will be used as chart data.
- Add an exploded pie chart to the worksheet using Worksheet.Charts.Add(ExcelChartType. PieExploded) method.
- Set the chart data using Chart.DataRange property.
- Define the chart's position and size using Chart.LeftColumn, Chart.TopRow, Chart.RightColumn, and Chart.BottomRow properties.
- Set the chart title using Chart.ChartTitle property.
- Access and format the series through Chart.Series property.
- Save the workbook as an Excel file.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a workbook
workbook = Workbook()
# Get the first sheet
sheet = workbook.Worksheets[0]
# Set values of the specified cells
sheet.Range["A1"].Value = "Year"
sheet.Range["A2"].Value = "2002"
sheet.Range["A3"].Value = "2003"
sheet.Range["A4"].Value = "2004"
sheet.Range["A5"].Value = "2005"
sheet.Range["B1"].Value = "Sales"
sheet.Range["B2"].NumberValue = 4000
sheet.Range["B3"].NumberValue = 6000
sheet.Range["B4"].NumberValue = 7000
sheet.Range["B5"].NumberValue = 8500
# Format the cells
sheet.Range["A1:B1"].RowHeight = 15
sheet.Range["A1:B1"].Style.Color = Color.get_DarkGray()
sheet.Range["A1:B1"].Style.Font.Color = Color.get_White()
sheet.Range["A1:B1"].Style.VerticalAlignment = VerticalAlignType.Center
sheet.Range["A1:B1"].Style.HorizontalAlignment = HorizontalAlignType.Center
sheet.Range["B2:B5"].Style.NumberFormat = "\"$\"#,##0"
# Add an exploded pie chart
chart = sheet.Charts.Add(ExcelChartType.PieExploded)
# Set region of chart data
chart.DataRange = sheet.Range["B2:B5"]
chart.SeriesDataFromRange = False
# Set position of chart
chart.LeftColumn = 4
chart.TopRow = 2
chart.RightColumn = 12
chart.BottomRow = 20
# Set chart title
chart.ChartTitle = "Sales by year"
chart.ChartTitleArea.IsBold = True
chart.ChartTitleArea.Size = 12
# Get the first series
cs = chart.Series[0]
# Set category labels for the series
cs.CategoryLabels = sheet.Range["A2:A5"]
# Set values for the series
cs.Values = sheet.Range["B2:B5"]
# Show vales in data labels
cs.DataPoints.DefaultDataPoint.DataLabels.HasValue = True
# Save the workbook to an Excel file
workbook.SaveToFile("output/ExplodedPieChart.xlsx", ExcelVersion.Version2016)
# Dispose resources
workbook.Dispose()
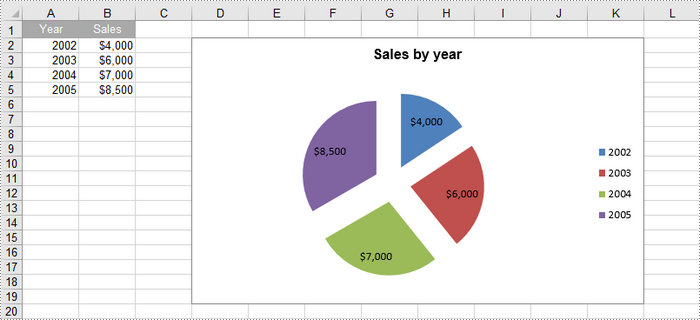
Create a Pie of Pie Chart in Excel in Python
A pie of pie chart is a specialized type of pie chart that allows for more detailed representation of data by providing a secondary pie chart for specific categories. To add a pip of pie chart to a worksheet, use the Worksheet.Charts.Add(ExcelChartType.PieOfPie) method.
The detailed steps to create a pie of pie chart in Excel are as follows:
- Create a Workbook object.
- Retrieve a specific worksheet from the workbook.
- Insert values into the worksheet cells that will be used as chart data.
- Add a pie of pie chart to the worksheet using Worksheet.Charts.Add(ExcelChartType.PieOfPie) method.
- Set the chart data, position, size, title using the properties under the Chart object.
- Access the first series using Chart.Series[0] property.
- Set the split value that determines what displays in the secondary pie using Series.Format.Options.SplitValue property.
- Save the workbook as an Excel file.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a workbook
workbook = Workbook()
# Get the first sheet
sheet = workbook.Worksheets[0]
# Set values of the specified cells
sheet.Range["A1"].Value = "Product"
sheet.Range["A2"].Value = "Coffee"
sheet.Range["A3"].Value = "Biscuits"
sheet.Range["A4"].Value = "Tea"
sheet.Range["A5"].Value = "Vegetables"
sheet.Range["A6"].Value = "Fruits"
sheet.Range["A7"].Value = "Chips"
sheet.Range["A8"].Value = "Drinks"
sheet.Range["B1"].Value = "Sales Percentage"
sheet.Range["B2"].NumberValue = 0.27
sheet.Range["B3"].NumberValue = 0.13
sheet.Range["B4"].NumberValue = 0.26
sheet.Range["B5"].NumberValue = 0.25
sheet.Range["B6"].NumberValue = 0.03
sheet.Range["B7"].NumberValue = 0.05
sheet.Range["B8"].NumberValue = 0.01
# Autofit column width
sheet.AutoFitColumn(2)
# Format the cells
sheet.Range["A1:B1"].RowHeight = 15
sheet.Range["A1:B1"].Style.Color = Color.get_DarkGray()
sheet.Range["A1:B1"].Style.Font.Color = Color.get_White()
sheet.Range["A1:B1"].Style.VerticalAlignment = VerticalAlignType.Center
sheet.Range["A1:B1"].Style.HorizontalAlignment = HorizontalAlignType.Center
sheet.Range["B2:B8"].Style.NumberFormat = "0%"
# Add a pie of pie chart
chart = sheet.Charts.Add(ExcelChartType.PieOfPie)
# Set region of chart data
chart.DataRange = sheet.Range["B2:B58"]
chart.SeriesDataFromRange = False
# Set position of chart
chart.LeftColumn = 4
chart.TopRow = 2
chart.RightColumn = 12
chart.BottomRow = 20
# Chart title
chart.ChartTitle = "Sales Percentage"
chart.ChartTitleArea.IsBold = True
chart.ChartTitleArea.Size = 12
# Get the first series
cs = chart.Series[0]
# Set category labels for the series
cs.CategoryLabels = sheet.Range["A2:A8"]
# Set values for the series
cs.Values = sheet.Range["B2:B8"]
# Show vales in data labels
cs.DataPoints.DefaultDataPoint.DataLabels.HasValue = True
# Set the size of the secondary pie
cs.Format.Options.PieSecondSize = 50
# Set the split value, which determines what displays in the secondary pie
cs.Format.Options.SplitType = SplitType.Percent
cs.Format.Options.SplitValue = 10
# Save the workbook to an Excel file
workbook.SaveToFile("output/PieOfPieChart.xlsx", ExcelVersion.Version2016)
# Dispose resources
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#: Convert PDF to Markdown
The need to convert PDF documents into more flexible and editable formats, such as Markdown, has become a common task for developers and content creators. Converting PDFs to Markdown files facilitates easier editing and version control, and enhances content portability across different platforms and applications, making it particularly suitable for modern web publishing workflows. By utilizing Spire.PDF for .NET, developers can automate the conversion process, ensuring that the rich formatting and structure of the original PDFs are preserved in the resulting Markdown files.
This article will demonstrate how to use Spire.PDF for .NET to convert PDF documents to Markdown format with C# code.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Convert PDF Documents to Markdown Files
With the Spire.PDF for .NET library, developers can easily load any PDF file using the PdfDocument.LoadFromFile(string filename) method and then save the document in the desired format by calling the PdfDocument.SaveToFile(string filename, FileFormat fileFormat) method. To convert a PDF to Markdown format, simply specify the FileFormat.Markdown enumeration as a parameter when invoking the method.
The detailed steps for converting PDF documents to Markdown files are as follows:
- Create an instance of PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile(string filename) method.
- Convert the document to a Markdown file using PdfDocument.SaveToFile(string filename, FileFormat.Markdown) method.
- C#
using Spire.Pdf;
namespace PDFToMarkdown
{
class Program
{
static void Main(string[] args)
{
// Create an instance of PdfDocument class
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.LoadFromFile("Sample.pdf");
// Convert the document to Markdown file
pdf.SaveToFile("output/PDFToMarkdown.md", FileFormat.Markdown);
// Release resources
pdf.Close();
}
}
}
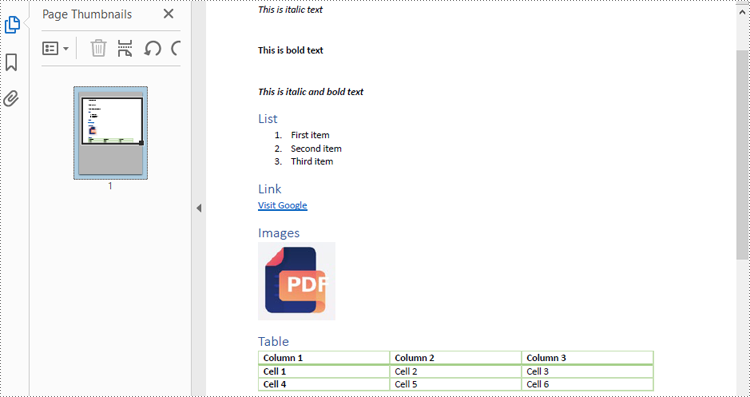
The PDF Document:
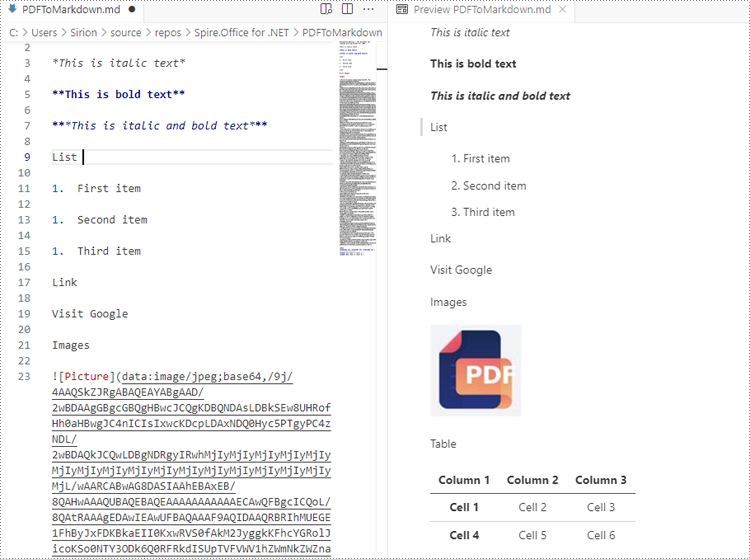
The Result Markdown File:
Convert PDF to Markdown by Streams
In addition to directly reading files for manipulation, Spire.PDF for .NET also supports loading a PDF document from a stream using PdfDocument.LoadFromStream() method and converting it to a Markdown file stream using PdfDocument.SaveToStream() method. Using streams reduces memory usage, supports large files, enables real-time data transfer, and simplifies data exchange with other systems.
The detailed steps for converting PDF documents to Markdown files by streams are as follows:
- Create a Stream object of PDF documents by downloading from the web or reading from a file.
- Load the PDF document from the stream using PdfDocument.LoadFromStream(Stream stream) method.
- Create another Stream object to store the converted Markdown file.
- Convert the PDF document to a Markdown file stream using PdfDocument.SaveToStream(Stream stream, FileFormat.Markdown) method.
- C#
using Spire.Pdf;
using System.IO;
using System.Net.Http;
namespace PDFToMarkdownByStream
{
class Program
{
static async Task Main(string[] args)
{
// Create an instance of PdfDocument class
PdfDocument pdf = new PdfDocument();
// Download a PDF document from a url as bytes
using (HttpClient client = new HttpClient())
{
byte[] pdfBytes = await client.GetByteArrayAsync("http://example.com/Sample.pdf");
// Create a MemoryStream using the bytes
using (MemoryStream inputStream = new MemoryStream(pdfBytes))
{
// Load the PDF document from the stream
pdf.LoadFromStream(inputStream);
// Create another MemoryStream object to store the Markdown file
using (MemoryStream outputStream = new MemoryStream())
{
// Convert the PDF document to a Markdown file stream
pdf.SaveToStream(outputStream, FileFormat.Markdown);
outputStream.Position = 0; // Reset the position of the stream for subsequent reads
// Upload the result stream or write it to a file
await client.PostAsync("http://example.com/upload", new StreamContent(outputStream));
File.WriteAllBytes("output.md", outputStream.ToArray());
}
}
}
// Release resources
pdf.Close();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.