Spire.XLS for Java 14.9.8 supports the revision function
We are excited to announce the release of Spire.XLS for Java 14.9.8. This version supports the revision function. Moreover, it optimizes the speed of converting Excel documents to HTML documents. Besides, some known bugs are fixed successfully in this update, such as the issue that print area settings are not fully copied when duplicating worksheets. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREXLS-5371 | Supports the revision function.
Workbook workbook = new Workbook();
workbook.loadFromFile("input.xlsx");
workbook.setTrackedChanges(true);
workbook.acceptAllTrackedChanges();
workbook.saveToFile("output.xlsx", ExcelVersion.Version2013);
workbook.dispose();
|
| New feature | SPIREXLS-5362 | Optimizes the speed of converting Excel documents to HTML documents. |
| Bug | SPIREXLS-5149 | Fixes the issue that print area settings are not fully copied when duplicating worksheets. |
| Bug | SPIREXLS-5295 | Fixes the issue that some data is incorrect when converting Excel documents to PDF documents. |
| Bug | SPIREXLS-5368 | Fixes the issue that chart contents are lost when converting worksheets to images. |
| Bug | SPIREXLS-5368 | Fixes the issue that the program throws an exception "Input string was not in the correct format." when converting charts to images. |
| Bug | SPIREXLS-5432 | Fixes the issue that the program throws a java.lang.IllegalArgumentException exception when loading Excel documents. |
| Bug | SPIREXLS-5435 | Fixes the issue that conditional formatting is lost when converting Excel documents to XML documents and then back to Excel documents. |
| Bug | SPIREXLS-5441 | Fixes the issue that the program throws a java.lang.OutOfMemoryError exception when converting Excel documents to PDF documents. |
| Bug | SPIREXLS-5442 | Fixes the issue that fonts are incorrect when converting Excel documents to PDF documents. |
Spire.Presentation for Java 9.9.2 supports getting the names of all embedded fonts in a PowerPoint file
We are delighted to announce the release of Spire.Presentation for Java 9.9.2. This version supports getting the names of all embedded fonts in a PowerPoint file. It also enhances the conversion from PPTX files to PPT files. Moreover, some known issues are fixed in this version, such as the issue that the program suspended when loading a PPTX document. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPPT-2602 | Supports getting the names of all embedded fonts in a PowerPoint file.
ArrayList<String> embedFonts = ppt.getEmbedFonts(); |
| Bug | SPIREPPT-2597 | Fixes the issue that the program threw java.lang.ClassCastException when converting a PPTX document to a PPT document. |
| Bug | SPIREPPT-2599 | Fixes the issue that the program threw java.lang.ClassCastException when calling table.distributeRows(0,1) method after adding a formula to a table cell. |
| Bug | SPIREPPT-2601 | Fixes the issue that the program suspended when loading a PPTX document. |
Python: Convert Text to Numbers and Numbers to Text in Excel
Converting text to numbers and vice versa in Excel is crucial for efficient data management. When you convert text to numbers, you enable accurate calculations and data processing, which is essential for tasks like financial reporting and statistical analysis. On the other hand, converting numbers to text can be beneficial for formatting outputs, creating clear and readable labels, and presenting data in a more user-friendly manner.
In this article, you will learn how to convert text to numbers and numbers to text in Excel using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Convert Text to Numbers in Excel
If you import data from another source into Excel, a small green triangle may appear in the upper-left corner of the cell. This error indicator indicates that the number is stored as text. Numbers that are stored as text can cause unexpected results, like an uncalculated formula showing instead of a result.
To convert numbers stored as text to numbers, you can simply use the CellRange.ConvertToNumber() method. The CellRange object can represent a single cell or a range of cells.
The steps to convert text to numbers in Excel are as follows:
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Get a cell or a range of cells using Worksheet.Range property.
- Convert the text in the cell(s) into numbers using CellRange.ConvertToNumber() method.
- Save the document to a different Excel file.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel document
workbook.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.xlsx")
# Get a specific worksheet
worksheet = workbook.Worksheets[0]
# Get a cell range
range = worksheet.Range["D2:G13"]
# Convert text to number
range.ConvertToNumber()
# Save the workbook to a different Excel file
workbook.SaveToFile("output/TextToNumbers.xlsx", ExcelVersion.Version2013)
# Dispose resources
workbook.Dispose()
Convert Numbers to Text in Excel
When working with numerical data in Excel, you might encounter situations where you need to convert numbers to text. This is particularly important when dealing with data that requires specific formatting, such as IDs or phone numbers that must retain leading zeros.
To convert the number in a cell into text, you can set the CellRange.NumberFormat to @. The CellRange object represents a single cell or a range of cells.
The detailed steps to convert numbers to text in Excel are as follows:
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Get a specific cell or a range of cells using Worksheet.Range property.
- Convert the numbers in the cell(s) into text by setting CellRange.NumberFormat to @.
- Save the document to a different Excel file.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel document
workbook.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Employee.xlsx")
# Get a specific worksheet
worksheet = workbook.Worksheets[0]
# Get a cell range
cellRange = worksheet.Range["F2:F9"]
# Convert numbers in the cell range to text
cellRange.NumberFormat = "@"
# Save the workbook to a different Excel file
workbook.SaveToFile("output/NumbersToText.xlsx", ExcelVersion.Version2013)
# Dispose resources
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Presentation 9.9.2 support setting the global font directory when execute conversion feature
We're glad to announce the release of Spire.Presentation 9.9.2. This version supports setting the global font directory when execute conversion feature, and also adds two properties to obtain the last row and last column of the chart's data source. Moreover, two issues that occurred when converting PPTX to SVG, and copying shapes have been successfully fixed. Check below for more details.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPPT-2567 | Supports setting the global font directory when execute the conversion function.
Presentation.SetCustomFontsDirctory("myfonts");
|
| New feature | SPIREPPT-2594 | Adds the "IChart.ChartData.LastRowIndex" and "IChart.ChartData.LastColIndex" properties to obtain the last row and last column of the chart's data source.
Presentation ppt = new Presentation();
ppt.LoadFromFile(inputFile);
StringBuilder stringBuilder= new StringBuilder();
IChart chart = ppt.Slides[0].Shapes[0] as IChart;
if (chart != null)
{
int lastRow = chart.ChartData.LastRowIndex;
int lastCol = chart.ChartData.LastColIndex;
sb.AppendLine("lastRow" + lastRow + "\r\n" + "lastColumn" + lastCol);
int dataRow = chart.Series[2].Values[chart.Series[2].Values.Count - 1].Row;
int dataColumn = chart.Series[2].Values[chart.Series[2].Values.Count - 1].Column;
sb.AppendLine("dataRow" + datarow + "\r\n" + "dataColumn" + dataColumn);
chart.ChartData.Clear(dataRow + 1, 0, lastRow + 1, lastCol + 1);
chart.ChartData.Clear(0, dataColumn + 1, lastRow + 1, lastCol + 1);
}
File.WriteAllText(outputFile_T,stringBuilder.ToString());
ppt.SaveToFile(outputFile, FileFormat.Pptx2013);
ppt.Dispose();
|
| Bug | SPIREPPT-2582 | Fixes the issue that the type changed from "graphic" to "image" when copying shapes. |
| Bug | SPIREPPT-2590 | Fixes the issue that the content was incorrect when converting PPTX documents to SVG documents. |
Spire.Doc for Java 12.9.4 enhances the conversion from Word to PDF
We are delighted to announce the release of Spire.Doc for Java 12.9.4. This version enhances the conversion from Word to PDF. Besides, some known issues are fixed successfully in this version, such as the issue that the created table of contents field was not updated correctly. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREDOC-10740 | Optimizes the speed of converting Word documents to PDF documents. |
| Bug | SPIREDOC-10457 | Fixes the issue that the text layout was incorrect after converting Word documents to PDF documents. |
| Bug | SPIREDOC-10791 | Fixes the issue that the created table of contents field was not updated correctly. |
| Bug | SPIREDOC-10813 | Fixes the issue that SimSun font was replaced with Times New Roman font after converting Word documents to PDF documents. |
| Bug | SPIREDOC-10821 | Fixes the issue that the program threw "Cannot find any fonts in specified font sources" exception when converting Word documents to PDF documents under the system environment where fonts were not installed. |
| Bug | SPIREDOC-10825 | Fixes the issue that the program threw java.lang.NullPointerException when using Map type parameters in MailMergeDataTable class. |
Python: Crop Pages in PDF
When dealing with PDF files, you might sometimes need to crop pages in the PDF to remove unnecessary margins, borders, or unwanted content. By doing so, you can make the document conform to specific design requirements or page sizes, ensuring a more aesthetically pleasing or functionally optimized output. This article will introduce how to crop pages in PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Crop a PDF Page in Python
Spire.PDF for Python allows you specify a rectangular area, and then use the PdfPageBase.CropBox property to crop page to the specified area. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Crop the page to the specified area using PdfPageBase.CropBox property.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from disk
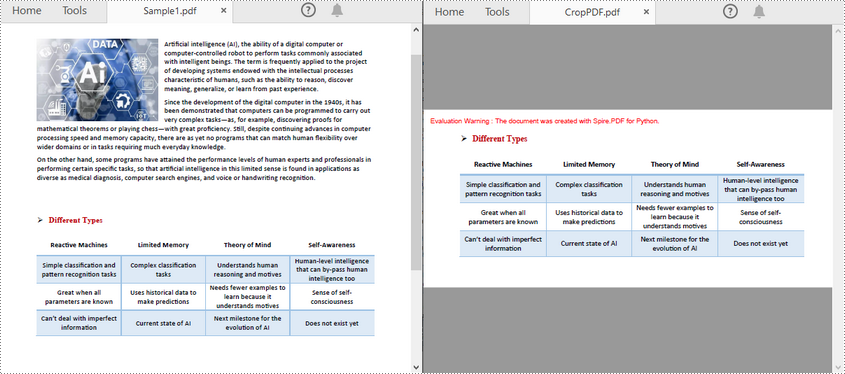
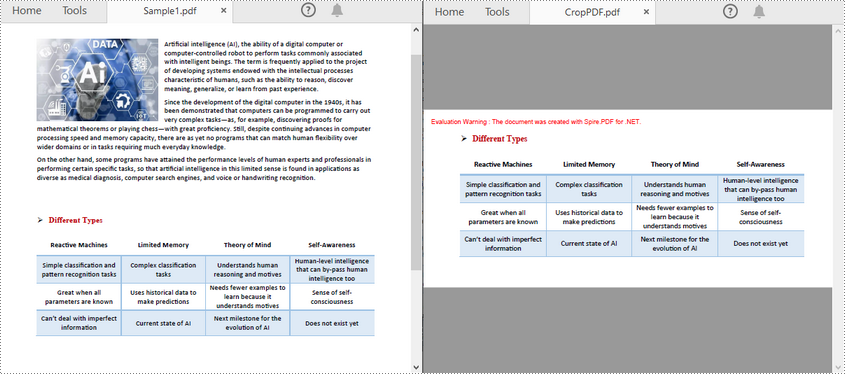
pdf.LoadFromFile("Sample1.pdf")
# Get the first page
page = pdf.Pages[0]
# Crop the page by the specified area
page.CropBox = RectangleF(0.0, 300.0, 600.0, 260.0)
# Save the result file
pdf.SaveToFile("CropPDF.pdf")
pdf.Close()
Crop a PDF Page and Export as an Image in Python
To accomplish this task, you can use the PdfDocument.SaveAsImage(pageIndex: int) method to convert a cropped PDF page to an image stream. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Crop the page to the specified area using PdfPageBase.CropBox property.
- Convert the cropped page to an image stream using PdfDocument.SaveAsImage() method.
- Save the image as a PNG, JPG or BMP file using Stream.Save() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from disk
pdf.LoadFromFile("Sample1.pdf")
# Get the first page
page = pdf.Pages[0]
# Crop the page by the specified area
page.CropBox = RectangleF(0.0, 300.0, 600.0, 260.0)
# Convert the page to an image
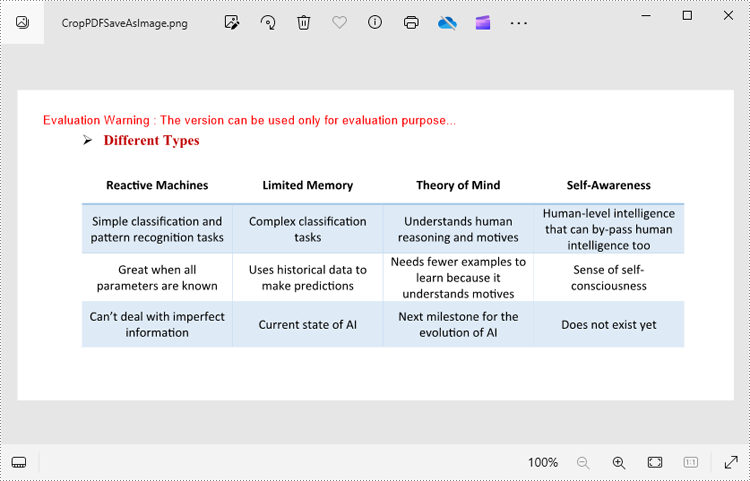
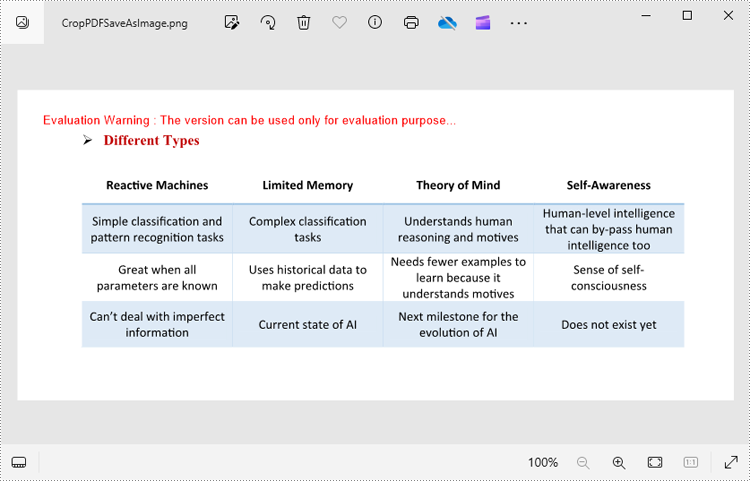
with pdf.SaveAsImage(0) as imageS:
# Save the image as a PNG file
imageS.Save("CropPDFSaveAsImage.png")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#: Crop Pages in PDF
PDF page cropping is particularly useful in scenarios where the original document has excessive margins or borders that are not necessary for the intended use. By cropping pages, you can preserve the designated area for specific use, making the document more efficient for sharing, printing, or digital presentations. In this article, you will learn how to crop pages in PDF in C# using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Crop a PDF Page in C#
Spire.PDF for .NET allows you specify a rectangular area, and then use the PdfPageBase.CropBox property to crop page to the specified area. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Crop the page to the specified area using PdfPageBase.CropBox property.
- Save the result file using PdfDocument.SaveToFile() method.
- C#
using System.Drawing;
using Spire.Pdf;
namespace CropPDFPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
//Load a PDF file from disk
pdf.LoadFromFile("Sample1.pdf");
//Get the first page
PdfPageBase page = pdf.Pages[0];
//Crop the page by the specified area
page.CropBox = new RectangleF(0, 300, 600, 260);
//Save the result file
pdf.SaveToFile("CropPDF.pdf");
pdf.Close();
}
}
}
Crop a PDF Page and Export as an Image in C#
To accomplish this task, you can use the PdfDocument.SaveAsImage(int pageIndex, PdfImageType type) method to convert a cropped PDF page to an image. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Crop the page to the specified area using PdfPageBase.CropBox property.
- Convert the copped page to an image using PdfDocument.SaveAsImage() method.
- Save the image as a PNG, JPG or BMP file using Image.Save(string filename, ImageFormat format) method.
- C#
using System.Drawing;
using System.Drawing.Imaging;
using Spire.Pdf;
using Spire.Pdf.Graphics;
namespace CropPDFPageToImage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
//Load a PDF file from disk
pdf.LoadFromFile("Sample1.pdf");
//Get the first page
PdfPageBase page = pdf.Pages[0];
//Crop the page by the specified area
page.CropBox = new RectangleF(0, 300, 600, 260);
//Convert the page to an image
Image image = pdf.SaveAsImage(0, PdfImageType.Bitmap);
//Save the image as a PNG file
image.Save("CropPDFSaveAsImage.png", ImageFormat.Png);
//Save the image as a JPG file
//image.Save("ToJPG.jpg", ImageFormat.Jpeg);
//Save the image as a BMP file
//image.Save("ToBMP.bmp", ImageFormat.Bmp);
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Verify or Extract Digital Signatures in PDF
Verifying digital signatures in PDFs is crucial for ensuring that a document remains unaltered and genuinely comes from the stated signer. This verification process is essential for maintaining the document’s integrity and trustworthiness. Additionally, extracting digital signatures allows you to retrieve signature details, such as the signature image and certificate information, which can be useful for further validation or archival purposes. In this article, we will demonstrate how to verify and extract digital signatures in PDFs in Java using Spire.PDF for Java.
- Verify Digital Signatures in PDF in Java
- Detect Whether a Signed PDF Has Been Modified in Java
- Extract Signature Images and Certificate Information from PDF in Java
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
Verify Digital Signatures in PDF in Java
Spire.PDF for Java provides the PdfSignature.verifySignature() method to check the validity of digital signatures in PDF documents. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using the PdfDocument.Form property.
- Iterate through all fields in the form and find the signature field.
- Get the signature using the PdfSignatureFieldWidget.getSignature() method.
- Verify the validity of the signature using the PdfSignature.verifySignature() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.fields.PdfField;
import com.spire.pdf.security.PdfSignature;
import com.spire.pdf.widget.PdfFormWidget;
import com.spire.pdf.widget.PdfSignatureFieldWidget;
public class VerifySignature {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.loadFromFile("Signature.pdf");
// Get the form of the PDF document
PdfFormWidget formWidget = (PdfFormWidget) pdf.getForm();
if(formWidget.getFieldsWidget().getCount() > 0)
{
// Iterate through all fields in the form
for(int i = 0; i < formWidget.getFieldsWidget().getCount(); i ++)
{
PdfField field = formWidget.getFieldsWidget().get(i);
// Find the signature field
if (field instanceof PdfSignatureFieldWidget)
{
PdfSignatureFieldWidget signatureField = (PdfSignatureFieldWidget) field;
// Get the signature
PdfSignature signature = signatureField.getSignature();
// Verify the signature
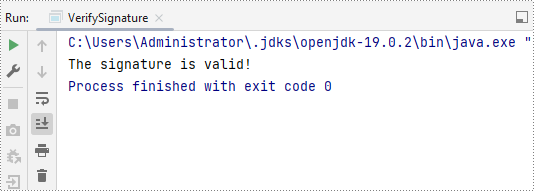
boolean valid = signature.verifySignature();
if(valid)
{
System.out.print("The signature is valid!");
}
else
{
System.out.print("The signature is invalid!");
}
}
}
}
}
}
Detect Whether a Signed PDF Has Been Modified in Java
To verify if a signed PDF document has been modified, you can use the PdfSignature.VerifyDocModified() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using the PdfDocument.Form property.
- Iterate through all fields in the form and find the signature field.
- Get the signature using the PdfSignatureFieldWidget.getSignature() method.
- Verify if the document has been modified since it was signed using the PdfSignature.VerifyDocModified() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.fields.PdfField;
import com.spire.pdf.security.PdfSignature;
import com.spire.pdf.widget.PdfFormWidget;
import com.spire.pdf.widget.PdfSignatureFieldWidget;
public class CheckIfSignedPdfIsModified {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.loadFromFile("Signature.pdf");
// Get the form of the PDF document
PdfFormWidget formWidget = (PdfFormWidget) pdf.getForm();
if(formWidget.getFieldsWidget().getCount() > 0) {
// Iterate through all fields in the form
for (int i = 0; i < formWidget.getFieldsWidget().getCount(); i++) {
PdfField field = formWidget.getFieldsWidget().get(i);
// Find the signature field
if (field instanceof PdfSignatureFieldWidget) {
PdfSignatureFieldWidget signatureField = (PdfSignatureFieldWidget) field;
// Get the signature
PdfSignature signature = signatureField.getSignature();
// Verify the signaure
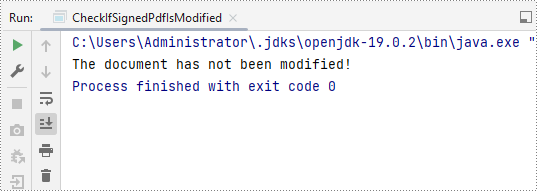
boolean modified = signature.verifyDocModified();
if(modified)
{
System.out.print("The document has been modified!");
}
else
{
System.out.print("The document has not been modified!");
}
}
}
}
}
}
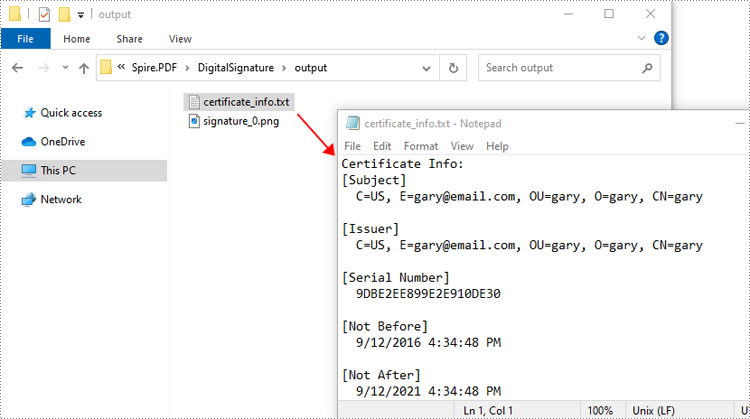
Extract Signature Images and Certificate Information from PDF in Java
To extract signature images and certificate information from PDF, you can use the PdfFormWidget.extractSignatureAsImages() and PdfSignture.getCertificate().toString() methods. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using the PdfDocument.Form property.
- Extract signature images using the PdfFormWidget.extractSignatureAsImages() method and then save each image to file.
- Iterate through all fields in the form and find the signature field.
- Get the signature using the PdfSignatureFieldWidget.getSignature() method.
- Get the certificate information of the signature using the PdfSignture.getCertificate().toString() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.fields.PdfField;
import com.spire.pdf.security.PdfCertificate;
import com.spire.pdf.security.PdfSignature;
import com.spire.pdf.widget.PdfFormWidget;
import com.spire.pdf.widget.PdfSignatureFieldWidget;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractSignatureImage {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a PDF document
pdf.loadFromFile("Signature.pdf");
// Get the form of the PDF document
PdfFormWidget formWidget = (PdfFormWidget) pdf.getForm();
// Extract signature images
Image[] images = formWidget.extractSignatureAsImages();
// Iterate through the images and save each image to file
for (int i = 0; i < images.length; i++) {
try {
// Convert the Image to BufferedImage
BufferedImage bufferedImage = (BufferedImage) images[i];
// Define the output file path
File outputFile = new File("output\\signature_" + i + ".png");
// Save the image as a PNG file
ImageIO.write(bufferedImage, "png", outputFile);
} catch (IOException e) {
e.printStackTrace();
}
}
// Create a text file to save the certificate information
try (BufferedWriter writer = new BufferedWriter(new FileWriter("output\\certificate_info.txt"))) {
if (formWidget.getFieldsWidget().getCount() > 0) {
// Iterate through all fields in the form
for (int i = 0; i < formWidget.getFieldsWidget().getCount(); i++) {
PdfField field = formWidget.getFieldsWidget().get(i);
// Find the signature field
if (field instanceof PdfSignatureFieldWidget) {
PdfSignatureFieldWidget signatureField = (PdfSignatureFieldWidget) field;
// Get the signature
PdfSignature signature = signatureField.getSignature();
// Get the certificate info of the signature
String certificateInfo = signature.getCertificate() != null ? signature.getCertificate().toString() : "No certificate";
// Write the certificate information to the text file
writer.write("Certificate Info: \n" + certificateInfo);
writer.write("-----------------------------------\n");
}
}
} else {
writer.write("No signature fields found.");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.OCR for Java Program Guide Content
Spire.OCR for Java is a professional OCR library to read text from Images in JPG, PNG, GIF, BMP and TIFF formats. Developers can easily add OCR functionalities on Java applications (J2SE and J2EE). It supports commonly used image formats and provides functionalities like reading multiple characters and fonts from images, bold and italic styles and much more.
Spire.OCR for Java provides a very easy way to extract text from images. With just three lines of code in Java, Spire.OCR supports read texts from variable common image formats, such as Bitmap, JPG, PNG, TIFF and GIF.
Java: Extract Text from Images Using the New Model of Spire.OCR for Java
Spire.OCR for Java offers developers a new model for extracting text from images. In this article, we will demonstrate how to extract text from images in Java using the new model of Spire.OCR for Java.
The detailed steps are as follows.
Step 1: Create a Java Project in IntelliJ IDEA.
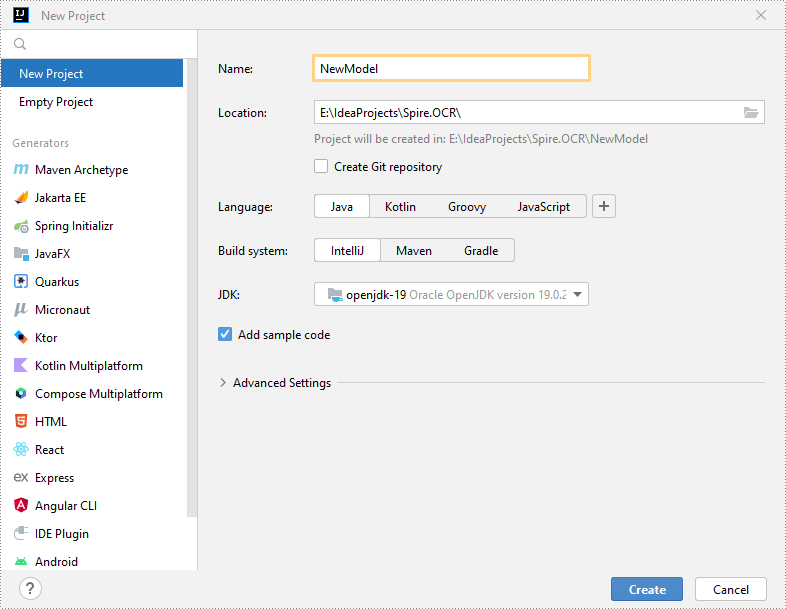
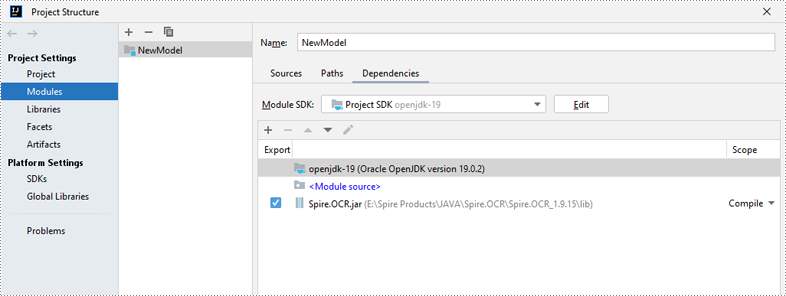
Step 2: Add Spire.OCR.jar to Your Project.
Option 1: Install Spire.OCR for Java via Maven.
If you're using Maven, you can install Spire.OCR for Java by adding the following code to your project's pom.xml file:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.ocr</artifactId>
<version>1.9.19</version>
</dependency>
</dependencies>
Option 2: Manually Import Spire.OCR.jar.
First, download Spire.OCR for Java from the following link and extract it to a specific directory:
https://www.e-iceblue.com/Download/ocr-for-java.html
Next, in IntelliJ IDEA, go to File > Project Structure > Modules > Dependencies. In the Dependencies pane, click the "+" button and select JARs or Directories. Navigate to the directory where Spire.OCR for Java is located, open the lib folder and select the Spire.OCR.jar file, then click OK to add it as the project’s dependency.
Step 3: Download the New Model of Spire.OCR for Java.
Download the model that fits in with your operating system from one of the following links.
Then extract the package and save it to a specific directory on your computer. In this example, we saved the package to "D:\".
Step 4: Implement Text Extraction from Images Using the New Model of Spire.OCR for Java.
Use the following code to extract text from images with the new OCR model of Spire.OCR for Java:
- Java
import com.spire.ocr.*;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
try {
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Create an instance of the ConfigureOptions class to set up the scanner configurations
ConfigureOptions configureOptions = new ConfigureOptions();
// Set the path to the new model
configureOptions.setModelPath("D:\\win-x64");
// Set the language for text recognition. The default is English.
// Supported languages include English, Chinese, Chinesetraditional, French, German, Japanese, and Korean.
configureOptions.setLanguage("English");
// Apply the configuration options to the scanner
scanner.ConfigureDependencies(configureOptions);
// Extract text from an image
scanner.scan("Sample.png");
// Save the extracted text to a text file
saveTextToFile(scanner, "output.txt");
} catch (OcrException e) {
e.printStackTrace();
}
}
private static void saveTextToFile(OcrScanner scanner, String filePath) {
try {
String text = scanner.getText().toString();
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath))) {
writer.write(text);
}
} catch (IOException | OcrException e) {
e.printStackTrace();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.