Spire.PDF 10.9.0 enhances the conversion from PDF to images, OFD, PDFA1B and SVG to PDF
We are excited to announce the release of Spire.PDF 10.9.0. This version enhances the conversion from PDF to images, OFD, PDFA1B as well as SVG to PDF. Moreover, some known issues are fixed successfully in the update, such as the issue that results are incorrect when extracting text multiple times. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREPDF-4562 SPIREPDF-5019 |
Improves the speed of printing PDF documents. |
| Bug | SPIREPDF-4445 | Fixes the issue that content is blank when converting PDF documents to images. |
| Bug | SPIREPDF-6938 | Fixes the issue that the program throws a System.FormatException: "Header checksum illegal" when compressing PDF documents. |
| Bug | SPIREPDF-6969 | Fixes the issue that the program throws a System.NullReferenceException: "Object reference not set to an instance of an object." when converting PDF documents to OFD documents. |
| Bug | SPIREPDF-6970 | Fixes the issue that the program throws a System.Exception: "Header of the stream cannot be read." when extracting images. |
| Bug | SPIREPDF-6971 | Fixes the issue that the content is incorrect when converting SVG files to PDF documents. |
| Bug | SPIREPDF-6974 | Fixes the issue with font errors when converting SVG files to PDF documents. |
| Bug | SPIREPDF-6979 | Fixes the issue that the program throws a System.IndexOutOfRangeException: "Index is outside the bounds of the array." when converting PDF documents to images. |
| Bug | SPIREPDF-6981 | Fixes the issue that the program throws a System.NullReferenceException: "Object reference not set to an instance of an object." when retrieving fonts. |
| Bug | SPIREPDF-6995 | Fixes the issue that results are incorrect when extracting text multiple times. |
| Bug | SPIREPDF-6997 | Fixes the issue that the program throws a System.NullReferenceException: "Object reference not set to an instance of an object." when converting PDF documents to PDFA1B documents. |
Python: Set the Transparency of PDF Images
Setting the transparency of images in PDF documents is crucial for achieving professional-grade output, which allows for layering images without hard edges and creating a seamless integration with the background or underlying content. This not only enhances the visual appeal but also creates a polished and cohesive look, especially in graphics-intensive documents. This article will demonstrate how to effectively set the transparency of PDF images using Spire.PDF for Python in Python programs.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Add Images with Specified Transparency to PDF
Developers can utilize the PdfPageBase.Canvas.DrawImage() method in Spire.PDF for Python to draw an image at a specified location on a PDF page. Before drawing, developers can set the transparency of the canvas using PdfPageBase.Canvas.SetTransparency() method, which in turn sets the transparency level of the image being drawn. Below are the detailed steps:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page in the document using PdfDocument.Pages.get_Item() method.
- Load an image using PdfImage.FromFile() method.
- Set the transparency of the canvas using PdfPageBase.Canvas.SetTransparency() method.
- Draw the image on the page using PdfPageBase.Canvas.DrawImage() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Load an image
image = PdfImage.FromFile("Screen.jpg")
# Set the transparency of the canvas
page.Canvas.SetTransparency(0.2)
# Draw the image at the specified location
page.Canvas.DrawImage(image, PointF(80.0, 80.0))
# Save the document
pdf.SaveToFile("output/AddTranslucentPicture.pdf")
pdf.Close()

Adjust the Transparency of Existing Images in PDF
To adjust the transparency of an existing image on a PDF page, developers can retrieve the image along with its bounds, delete the image, and finally redraw the image in the same location with the specified transparency. This process allows for the adjustment of the image's opacity while maintaining its original placement. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page in the document using PdfDocument.Pages.get_Item() method.
- Get an image on the page as a stream through PdfPageBase.ImagesInfo[].Image property and get the bounds of the image through PdfPageBase.ImagesInfo[].Bounds property.
- Remove the image from the page using PdfPageBase.DeleteImage() method.
- Create a PdfImage instance with the stream using PdfImage.FromStream() method.
- Set the transparency of the canvas using PdfPageBase.Canvas.SetTransparency() method.
- Redraw the image in the same location with the specified transparency using PdfPageBase.Canvas.DrawImage() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample1.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Get the first image on the page as a stream and the bounds of the image
imageStream = page.ImagesInfo[0].Image
bounds = page.ImagesInfo[0].Bounds
# Delete the original image
page.DeleteImage(0)
# Create a PdfImage instance using the image stream
image = PdfImage.FromStream(imageStream)
# Set the transparency of the canvas
page.Canvas.SetTransparency(0.3)
# Draw the new image at the same location using the canvas
page.Canvas.DrawImage(image, bounds)
# Save the document
pdf.SaveToFile("output/SetExistingImageTransparency.pdf")
pdf.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
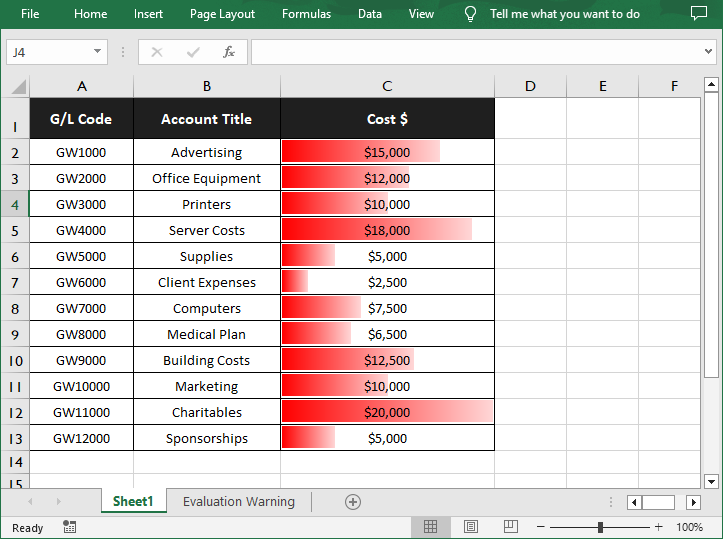
Python: Add Data Bars in Excel
Data Bars in Excel is a feature within the Conditional Formatting tool that allows you to visually represent numerical data through a series of bars. This feature is particularly useful for comparing values at a glance, as the length of the bar corresponds to the magnitude of the value it represents. In this article, you will learn how to add data bars in an Excel cell range in Python using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Add Data Bars in Excel in Python
With Spire.XLS for Python, you are allowed to add a data bar to a specified data range and also set its format. The following are the detailed steps.
- Create a Workbook instance.
- Load a sample Excel document using Workbook.LoadFromFile() method.
- Get a specified worksheet using Workbook.Worsheets[index] property.
- Add a conditional formatting to the worksheet using Worksheet.ConditionalFormats.Add() method and return an object of XlsConditionalFormats class.
- Set the cell range where the conditional formatting will be applied using XlsConditionalFormats.AddRange() method.
- Add a condition using XlsConditionalFormats.AddCondition() method, and then set its format type to DataBar using IConditionalFormat.FormatType property.
- Set the fill effect and color of the data bars using IConditionalFormat.DataBar.BarFillType and IConditionalFormat.DataBar.BarColor properties.
- Save the result document using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook instance
workbook = Workbook()
# Load a sample Excel document
workbook.LoadFromFile("sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Add a conditional format to the worksheet
xcfs = sheet.ConditionalFormats.Add()
# Set the range where the conditional format will be applied
xcfs.AddRange(sheet.Range["C2:C13"])
# Add a condition and set its format type to DataBar
format = xcfs.AddCondition()
format.FormatType = ConditionalFormatType.DataBar
# Set the fill effect and color of the data bars
format.DataBar.BarFillType = DataBarFillType.DataBarFillGradient
format.DataBar.BarColor = Color.get_Red()
# Save the result document
workbook.SaveToFile("ApplyDataBarsToCellRange.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.PDF for Java 10.9.0 supports extracting text from specified areas
We're pleased to announce the release of Spire.PDF for Java 10.9.0. This version supports extracting text from specified areas, and preserving XMP data when converting PDF to PDF/A. Furthermore, some known issues that occurred when replacing, extracting text, and compressing images have been successfully fixed. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-6920 | Adds the PreserveAllowedMetadata property to support preserving XMP data when converting PDF to PDF/A format documents.
PdfStandardsConverter convert= new PdfStandardsConverter(outputFile_pdf); convert.getOptions().setPreserveAllowedMetadata(true); convert.toPdfA2A(outputFile_pdfA2A); |
| New feature | SPIREPDF-6977 | Add a new interface 'PdfTextReplaceOptions.setReplacementArea(Rectangle2D rect)' to support extracting text from specified areas.
PdfPageBase page = pdf.getPages().get(0);
PdfTextReplacer replacer= new PdfTextReplacer (page);
replacer.getOptions().setReplacementArea(new Rectangle2D.Float(10, 0, 841, 150));
replacer.getOptions().setReplaceType(EnumSet.of(ReplaceActionType.WholeWord));
replacer.replaceAllText("SQL","Now SQL");
|
| New feature | SPIREPDF-6962 | Adds a deprecation status indicator to the 'PdfDocument.isPasswordProtected(filename)' method. |
| Bug | SPIREPDF-6959 | Fixes the issue that the program threw a 'java.lang.NullPointerException' when replacing text. |
| Bug | SPIREPDF-6973 | Fixes the issue that the program threw a 'java.lang.NullPointerException' when extracting text. |
| Bug | SPIREPDF-6976 | Fixes the issue that the program threw a 'java.lang.ArrayIndexOutOfBoundsException' when extracting text. |
| Bug | SPIREPDF-6992 | Fixes the issue that the program threw a 'java.lang.OutOfMemoryError' when determining if a PDF document was password protected. |
| Bug | SPIREPDF-6994 | Fixes the issue that the program threw a 'java.lang.NoClassDefFoundError' when compressing images. |
| Bug | SPIREPDF-7001 | Fixes the issue that the program threw a 'java.lang.OutOfMemoryError' when merging documents after replacing text. |
Spire.XLS 14.9.1 supports identify OLE objects in Msg format
We are happy to announce the release of Spire.XLS 14.9.1. This version supports identify OLE objects in Msg format and disabling DTD processing. It also implements the support for the BAHTTEXT formula. Moreover, some known issues are fixed successfully in this version, such as the issue that the result of data summing using MarkerDesigner function was incorrect. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREXLS-5307 | Adds the 'OleObjectType.Msg' type to identify OLE objects in Msg format.
Workbook wb = new Workbook();
wb.LoadFromFile(inputFile);
Worksheet sheet =wb.Worksheets[0];
OleObjectType type;
if (sheet.HasOleObjects)
{
for (int i = 0; i < sheet.OleObjects.Count; i++)
{
var Object = sheet.OleObjects[i];
type = sheet.OleObjects[i].ObjectType;
switch (type)
{
case OleObjectType.Msg:
File.WriteAllBytes(outputFile_1, Object.OleData);
break;
......
}
}
}
|
| New feature | SPIREXLS-5359 | Adds the 'workbook.ProhibitDtd = true' property to disable DTD processing.
Workbook workbook = new Workbook(); workbook.ProhibitDtd = true; workbook.LoadFromFile(inputFile); workbook.SaveToFile(outputFile, ExcelVersion.Version2013); workbook.Dispose(); |
| New feature | SPIREXLS-5395 | Implements the support for the BAHTTEXT formula.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A3"].Value2 = 1234; workbook.Worksheets[0].Range["C3"].Formula = "=BAHTTEXT(A3)"; workbook.Worksheets[0].Range["A9"].Value = "1234"; workbook.Worksheets[0].Range["C9"].Formula = "=BAHTTEXT(A9)"; workbook.SaveToFile(outputFile, ExcelVersion.Version2013); workbook.Dispose(); |
| Bug | SPIREXLS-5108 | Fixed the issue that the table borders were inconsistent in color after converting an Excel document to a picture. |
| Bug | SPIREXLS-5280 | Fix the issue that the content was incorrect after converting an Excel document to a CSV document. |
| Bug | SPIREXLS-5315 | Fix the issue that the order of setting different font styles for the contents of a cell affected the inconsistency of the results. |
| Bug | SPIREXLS-5321 | Fix the issue that icons were lost after converting an Excel document to an HTML document. |
| Bug | SPIREXLS-5332 | Fix the issue that the data in the pivot table was lost when converting an Excel document to a picture. |
| Bug | SPIREXLS-5346 | Fix the issue that the result of data summing using MarkerDesigner function was incorrect. |
| Bug | SPIREXLS-5360 | Fixed the issue that the program threw System.OutOfMemoryException when converting charts to pictures. |
| Bug | SPIREXLS-5361 | Fixed the issue that the formatting was changed after saving as an XLSX document. |
| Bug | SPIREXLS-5363 | Fixed the issue that the spacing between words became larger after converting an Excel document to a PDF document. |
| Bug | SPIREXLS-5400 | Fix the issue that the text line breaks were incorrect after converting an Excel document to a PDF document. |
C#: Set Page Setup Options in Excel
When printing Excel spreadsheets, particularly those containing complex datasets or detailed reports, configuring the page setup properly is crucial. Excel’s page setup options enable you to adjust key factors such as page margins, orientation, paper size, and scaling, ensuring your documents are tailored to fit various printing needs. By customizing these settings, you can control how your content is displayed on the page, making sure it appears polished and professional. In this article, we will demonstrate how to set page setup options in Excel in C# using Spire.XLS for .NET.
- Set Page Margins in Excel in C#
- Set Page Orientation in Excel in C#
- Set Paper Size in Excel in C#
- Set Print Area in Excel in C#
- Set Scaling Factor in Excel in C#
- Set Fit-to-Pages Options in Excel in C#
- Set Headers and Footers in Excel in C#
Install Spire.XLS for .NET
To begin with, you need to add the DLL files included in the Spire.XLS for .NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.XLS
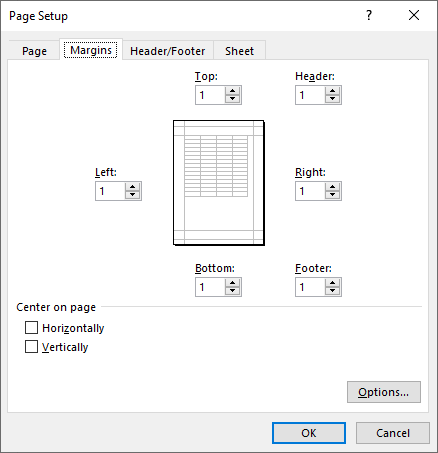
Set Page Margins in Excel in C#
The PageSetup class in Spire.XLS for .NET is used to configure page setup options for Excel worksheets. You can access the PageSetup object of a worksheet through the Worksheet.PageSetup property. Then, use properties like PageSetup.TopMargin, PageSetup.BottomMargin, PageSetup.LeftMargin, PageSetup.RightMargin, PageSetup.HeaderMarginInch, and PageSetup.FooterMarginInch to set the corresponding margins for the worksheet. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the top, bottom, left, right, header, and footer margins using PageSetup.TopMargin, PageSetup.BottomMargin, PageSetup.LeftMargin, PageSetup.RightMargin, PageSetup.HeaderMarginInch, and PageSetup.FooterMarginInch properties.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
namespace SetPageMargins
{
internal class Program
{
static void Main(string[] args)
{
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the PageSetup object of the worksheet
PageSetup pageSetup = sheet.PageSetup;
// Set top, bottom, left, and right page margins for the worksheet
// The measure of the unit is Inch (1 inch = 2.54 cm)
pageSetup.TopMargin = 1;
pageSetup.BottomMargin = 1;
pageSetup.LeftMargin = 1;
pageSetup.RightMargin = 1;
pageSetup.HeaderMarginInch = 1;
pageSetup.FooterMarginInch = 1;
// Save the modified workbook to a new file
workbook.SaveToFile("SetPageMargins.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
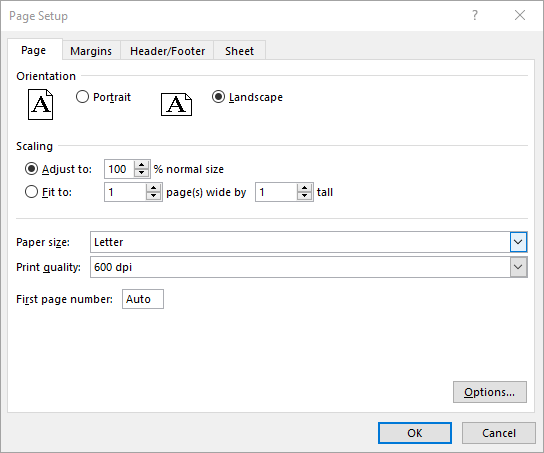
Set Page Orientation in Excel in C#
The PageSetup.Orientation property lets you determine how the page should be oriented when printed. You can choose between two options: portrait mode or landscape mode. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the page orientation using PageSetup.Orientation property.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
namespace SetPageOrientation
{
internal class Program
{
static void Main(string[] args)
{
//Page Orientation
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the PageSetup object of the worksheet
PageSetup pageSetup = sheet.PageSetup;
// Set the page orientation for printing the worksheet to landscape mode
pageSetup.Orientation = PageOrientationType.Landscape;
// Save the modified workbook to a new file
workbook.SaveToFile("SetPageOrientation.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
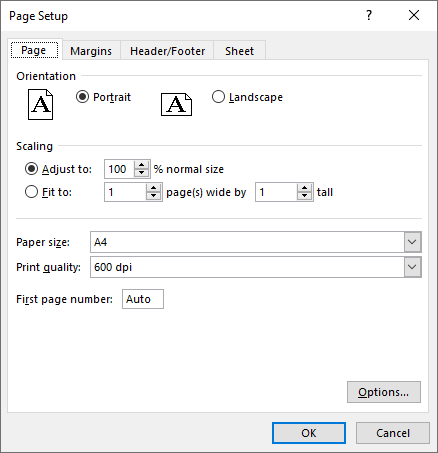
Set Paper Size in Excel in C#
The PageSetup.PaperSize property enables you to select from a variety of paper sizes for printing your worksheet. These options include A3, A4, A5, B4, B5, letter, legal, tabloid, and more. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the paper size using PageSetup.PaperSize property.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
namespace SetPaperSize
{
internal class Program
{
static void Main(string[] args)
{
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the PageSetup object of the worksheet
PageSetup pageSetup = sheet.PageSetup;
// Set the paper size to A4
pageSetup.PaperSize = PaperSizeType.PaperA4;
// Save the modified workbook to a new file
workbook.SaveToFile("SetPaperSize.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
Set Print Area in Excel in C#
You can specify the exact area that you want to print using the PageSetup.PringArea property. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the print area using PageSetup.PringArea property.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
namespace SetPrintArea
{
internal class Program
{
static void Main(string[] args)
{
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the PageSetup object of the worksheet
PageSetup pageSetup = sheet.PageSetup;
// Set the print area of the worksheet to "A1:E5"
pageSetup.PrintArea = "A1:E5";
// Save the modified workbook to a new file
workbook.SaveToFile("SetPrintArea.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
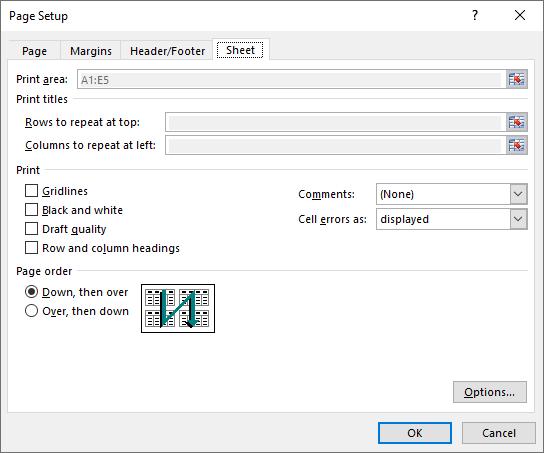
Set Scaling Factor in Excel in C#
If you want to scale the content of your worksheet to a specific percentage of its original size, use the PageSetup.Zoom property. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the scaling factor using PageSetup.Zoom property.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
namespace SetScalingFactor
{
internal class Program
{
static void Main(string[] args)
{
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the PageSetup object of the worksheet
PageSetup pageSetup = sheet.PageSetup;
// Set the scaling factor of the worksheet to 90%
pageSetup.Zoom = 90;
// Save the modified workbook to a new file
workbook.SaveToFile("SetScalingFactor.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
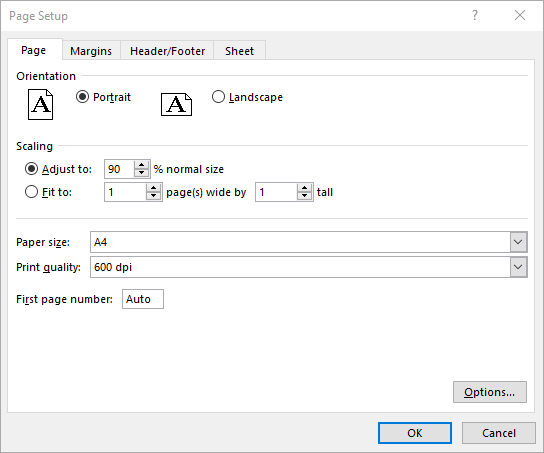
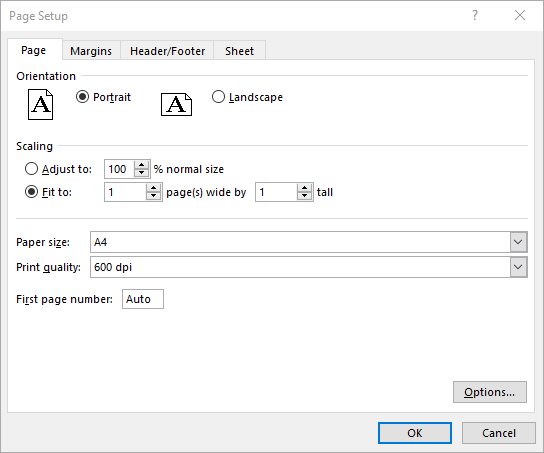
Set Fit-to-Pages Options in Excel in C#
Spire.XLS also enables you to fit your worksheet content to a specific number of pages by using the PageSetup.FitToPagesTall and PageSetup.FitToPagesWide properties. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Fit the content of the worksheet to one page using PageSetup.FitToPagesTall and PageSetup.FitToPagesWide properties.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- C#
using Spire.Xls;
namespace SetFitToPages
{
internal class Program
{
static void Main(string[] args)
{
// Create a Workbook object
Workbook workbook = new Workbook();
// Load an Excel file
workbook.LoadFromFile("Sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Get the PageSetup object of the worksheet
PageSetup pageSetup = sheet.PageSetup;
// Fit the content of the worksheet within one page vertically (i.e., all rows will fit on a single page)
pageSetup.FitToPagesTall = 1;
// Fit the content of the worksheet within one page horizontally (i.e., all columns will fit on a single page)
pageSetup.FitToPagesWide = 1;
// Save the modified workbook to a new file
workbook.SaveToFile("FitToPages.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}
}
Set Headers and Footers in Excel in C#
For setting headers and footers in Excel, please check this article: C#/VB.NET: Add Headers and Footers to Excel.
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Doc for Java 12.9.0 supports determining if a bookmark is hidden
We are excited to announce the release of Spire.Doc for Java 12.9.0. This version supports determining if a bookmark is hidden with a new method. Moreover, some known bugs are fixed successfully in this update, such as the issue that line spacing became inconsistent after replacing bookmark content. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREDOC-7237 | Supports determining if a bookmark is hidden with the new method, "bookmark.isHidden()". |
| New feature | SPIREDOC-10287 | Supports updating the character count with the new method, "document.updateWordCount()". |
| New feature | SPIREDOC-10771 | Supports embedding font files into the document when converting Word documents to HTML documents with the new method, "document.getHtmlExportOptions().setFontEmbedded(true)". |
| Bug | SPIREDOC-10641 | Fixes the issue that line spacing became inconsistent after replacing bookmark content. |
| Bug | SPIREDOC-10671 | Fixes the issue that regular format Latex formula code added to the document was converted into italic style. |
| Bug | SPIREDOC-10676 | Fixes the issue that removing the italic style from Latex formulas did not take effect. |
| Bug | SPIREDOC-10739 | Fixes the issue that the set edit restriction password did not work in MS Word or WPS tools. |
| Bug | SPIREDOC-10757 | Fixes the issue that garbled content appeared when converting Word documents to PDF documents. |
| Bug | SPIREDOC-10769 | Fixes the issue that the program hung when converting Markdown documents to Word documents. |
| Bug | SPIREDOC-10771 | Fixes the issue that an occasional exception occurred during stress testing of the merge mail function. |
Python: Load and Save PDFs with Byte Streams
Handling PDF documents using bytes and bytearray provides an efficient and flexible approach within applications. By processing PDFs directly as byte streams, developers can manage documents in memory or transfer them over networks without the need for temporary file storage, optimizing space and improving overall application performance. This method also facilitates seamless integration with web services and APIs. Additionally, using bytearray allows developers to make precise byte-level modifications to PDF documents.
This article will demonstrate how to save PDFs as bytes and bytearray and load PDFs from bytes and bytearray using Spire.PDF for Python, offering practical examples for Python developers.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Create a PDF Document and Save It to Bytes and Bytearray
Developers can create PDF documents using the classes and methods provided by Spire.PDF for Python, save them to a Stream object, and then convert it to an immutable bytes object or a mutable bytearray object. The Stream object can also be used to perform byte-level operations.
The detailed steps are as follows:
- Create an object of PdfDocument class to create a PDF document.
- Add a page to the document and draw text on the page.
- Save the document to a Stream object using PdfDocument.SaveToStream() method.
- Convert the Stream object to a bytes object using Stream.ToArray() method.
- The bytes object can be directly converted to a bytearray object.
- Afterward, the byte streams can be used for further operations, such as writing them to a file using the BinaryIO.write() method.
- Python
from spire.pdf import *
# Create an instance of PdfDocument class
pdf = PdfDocument()
# Set the page size and margins of the document
pageSettings = pdf.PageSettings
pageSettings.Size = PdfPageSize.A4()
pageSettings.Margins.Top = 50
pageSettings.Margins.Bottom = 50
pageSettings.Margins.Left = 40
pageSettings.Margins.Right = 40
# Add a new page to the document
page = pdf.Pages.Add()
# Create fonts and brushes for the document content
titleFont = PdfTrueTypeFont("HarmonyOS Sans SC", 16.0, PdfFontStyle.Bold, True)
titleBrush = PdfBrushes.get_Brown()
contentFont = PdfTrueTypeFont("HarmonyOS Sans SC", 13.0, PdfFontStyle.Regular, True)
contentBrush = PdfBrushes.get_Black()
# Draw the title on the page
titleText = "Brief Introduction to Cloud Services"
titleSize = titleFont.MeasureString(titleText)
page.Canvas.DrawString(titleText, titleFont, titleBrush, PointF(0.0, 30.0))
# Draw the body text on the page
contentText = ("Cloud computing is a service model where computing resources are provided over the internet on a pay-as-you-go basis. "
"It is a type of infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS), and software-as-a-service (SaaS) model. "
"Cloud computing is typically offered througha subscription-based model, where users pay for access to the cloud resources on a monthly, yearly, or other basis.")
# Set the string format of the body text
contentFormat = PdfStringFormat()
contentFormat.Alignment = PdfTextAlignment.Justify
contentFormat.LineSpacing = 20.0
# Create a TextWidget object with the body text and apply the string format
textWidget = PdfTextWidget(contentText, contentFont, contentBrush)
textWidget.StringFormat = contentFormat
# Create a TextLayout object and set the layout options
textLayout = PdfTextLayout()
textLayout.Layout = PdfLayoutType.Paginate
textLayout.Break = PdfLayoutBreakType.FitPage
# Draw the TextWidget on the page
rect = RectangleF(PointF(0.0, titleSize.Height + 50.0), page.Canvas.ClientSize)
textWidget.Draw(page, rect, textLayout)
# Save the PDF document to a Stream object
pdfStream = Stream()
pdf.SaveToStream(pdfStream)
# Convert the Stream object to a bytes object
pdfBytes = pdfStream.ToArray()
# Convert the Stream object to a bytearray object
pdfBytearray = bytearray(pdfStream.ToArray())
# Write the byte stream to a file
with open("output/PDFBytearray.pdf", "wb") as f:
f.write(pdfBytearray)

Load a PDF Document from Byte Streams
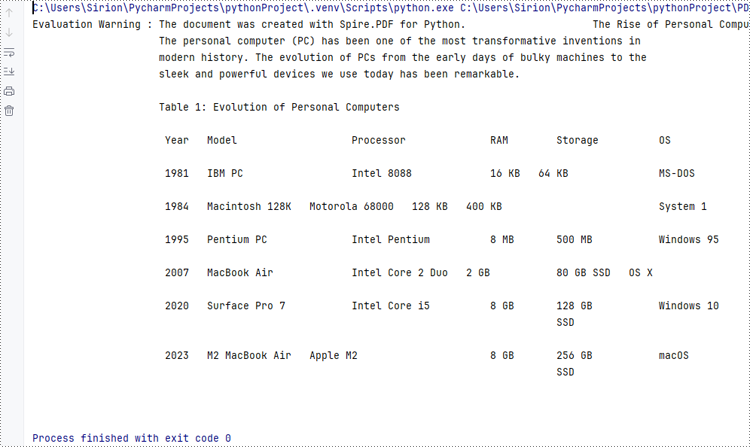
Developers can use a bytes object of a PDF file to create a stream and load it using the PdfDocument.LoadFromStream() method. Once the PDF document is loaded, various operations such as reading, modifying, and converting the PDF can be performed. The following is an example of the steps:
- Create a bytes object with a PDF file.
- Create a Stream object using the bytes object.
- Load the Stream object as a PDF document using PdfDocument.LoadFromStream() method.
- Extract the text from the first page of the document and print the text.
- Python
from spire.pdf import *
# Create a byte array from a PDF file
with open("Sample.pdf", "rb") as f:
byteData = f.read()
# Create a Stream object from the byte array
stream = Stream(byteData)
# Load the Stream object as a PDF document
pdf = PdfDocument(stream)
# Get the text from the first page
page = pdf.Pages.get_Item(0)
textExtractor = PdfTextExtractor(page)
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
text = textExtractor.ExtractText(extractOptions)
# Print the text
print(text)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add Page Numbers to a PDF Document
Adding page numbers to a PDF enhances its organization and readability, making it easier for readers to navigate the document. Whether for reports, manuals, or e-books, page numbers provide a professional touch and help maintain the flow of information. This process involves determining the placement, alignment, and style of the numbers within the footer or header.
In this article, you will learn how to add page numbers to the PDF footer using Spire.PDF for Python.
- Add Left-Aligned Page Numbers to PDF Footer
- Add Center-Aligned Page Numbers to PDF Footer
- Add Right-Aligned Page Numbers to PDF Footer
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
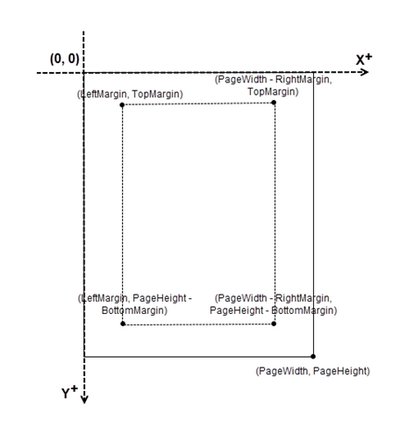
Coordinate System in PDF
When using Spire.PDF for Python to modify a PDF document, the coordinate system's origin is at the top-left corner of the page. The x-axis extends to the right, while the y-axis extends downward.
Page numbers are usually positioned in the header or footer. Thus, it's important to consider the page size and margins when determining the placement of the page numbers.
Classes and Methods for Creating Page Numbers
Spire.PDF for Python provides the PdfPageNumberField and PdfPageCountField classes to retrieve the current page number and total page count. These can be merged into a single PdfCompositeField that formats the output as "Page X of Y", where X represents the current page number and Y indicates the total number of pages.
To position the PdfCompositeField on the page, use the Location property, and render it with the Draw() method.
Add Left-Aligned Page Numbers to PDF Footer
To add left-aligned page numbers in the footer, you need to consider the left and bottom page margins as well as the page height. For example, you can use coordinates such as (LeftMargin, PageHeight – BottomMargin + SmallNumber). This ensures that the page numbers align with the left side of the text while keeping a comfortable distance from both the content and the edges of the page.
The steps to add left-aligned page numbers to PDF footer are as follows:
- Create a PdfDocument object.
- Load a PDF file from a specified path.
- Create a PdfPageNumberField object and a PdfPageCountField object.
- Create a PdfCompositeField object to combine page count field and page number field in a single string.
- Set the position of the composite field through PdfCompositeField.Location property to ensure the page number aligns with the left side of the text.
- Iterate through the pages in the document, and draw the composite field on each page at the specified location.
- Save the document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Create font, brush and pen
font = PdfTrueTypeFont("Times New Roman", 12.0, PdfFontStyle.Regular, True)
brush = PdfBrushes.get_Black()
pen = PdfPen(brush, 1.0)
# Create a PdfPageNumberField object and a PdfPageCountField object
pageNumberField = PdfPageNumberField()
pageCountField = PdfPageCountField()
# Create a PdfCompositeField object to combine page count field and page number field in a single string
compositeField = PdfCompositeField(font, brush, "Page {0} of {1}", [pageNumberField, pageCountField])
# Get the page size
pageSize = doc.Pages[0].Size
# Specify the blank areas around the page
leftMargin = 54.0
rightMargin = 54.0
bottomMargin = 72.0
# Set the location of the composite field
compositeField.Location = PointF(leftMargin, pageSize.Height - bottomMargin + 18.0)
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Draw a line at the specified position
page.Canvas.DrawLine(pen, leftMargin, pageSize.Height - bottomMargin + 15.0, pageSize.Width - rightMargin, pageSize.Height - bottomMargin + 15.0)
# Draw the composite field on the page
compositeField.Draw(page.Canvas, 0.0, 0.0)
# Save to a different PDF file
doc.SaveToFile("Output/LeftAlignedPageNumbers.pdf")
# Dispose resources
doc.Dispose()
Add Center-Aligned Page Numbers to PDF Footer
To position the page number in the center of the footer, you first need to measure the width of the page number itself. Once you have this measurement, you can calculate the appropriate X coordinate by using the formula (PageWidth - PageNumberWidth) / 2. This ensures the page number is horizontally centered within the footer.
The steps to add center-aligned page numbers to PDF footer are as follows:
- Create a PdfDocument object.
- Load a PDF file from a specified path.
- Create a PdfPageNumberField object and a PdfPageCountField object.
- Create a PdfCompositeField object to combine page count field and page number field in a single string.
- Set the position of the composite field through PdfCompositeField.Location property to ensure the page number is perfectly centered in the footer.
- Iterate through the pages in the document, and draw the composite field on each page at the specified location.
- Save the document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Create font, brush and pen
font = PdfTrueTypeFont("Times New Roman", 12.0, PdfFontStyle.Regular, True)
brush = PdfBrushes.get_Black()
pen = PdfPen(brush, 1.0)
# Specify the blank margins around the page
leftMargin = 54.0
rightMargin = 54.0
bottomMargin = 72.0
# Create a PdfPageNumberField object and a PdfPageCountField object
pageNumberField = PdfPageNumberField()
pageCountField = PdfPageCountField()
# Create a PdfCompositeField object to combine page count field and page number field in a single field
compositeField = PdfCompositeField(font, brush, "Page {0} of {1}", [pageNumberField, pageCountField])
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Get the page size
pageSize = doc.Pages[i].Size
# Draw a line at the specified position
page.Canvas.DrawLine(pen, leftMargin, pageSize.Height - bottomMargin + 15.0, pageSize.Width - rightMargin, pageSize.Height - bottomMargin + 15.0)
# Measure the size the "Page X of Y"
pageNumberSize = font.MeasureString("Page {} of {}".format(i + 1, doc.Pages.Count))
# Set the location of the composite field
compositeField.Location = PointF((pageSize.Width - pageNumberSize.Width)/2, pageSize.Height - bottomMargin + 18.0)
# Draw the composite field on the page
compositeField.Draw(page.Canvas, 0.0, 0.0)
# Save to a different PDF file
doc.SaveToFile("Output/CenterAlignedPageNumbers.pdf")
# Dispose resources
doc.Dispose()
Add Right-Aligned Page Numbers to PDF Footer
To add a right-aligned page number in the footer, measure the width of the page number. Then, calculate the X coordinate using the formula PageWidth - PageNumberWidth - RightMargin. This ensures that the page number aligns with the right side of the text.
The following are the steps to add right-aligned page numbers to PDF footer:
- Create a PdfDocument object.
- Load a PDF file from a specified path.
- Create a PdfPageNumberField object and a PdfPageCountField object.
- Create a PdfCompositeField object to combine page count field and page number field in a single string.
- Set the position of the composite field through PdfCompositeField.Location property to ensure the page number aligns with the right side of the text.
- Iterate through the pages in the document, and draw the composite field on each page at the specified location.
- Save the document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Create font, brush and pen
font = PdfTrueTypeFont("Times New Roman", 12.0, PdfFontStyle.Regular, True)
brush = PdfBrushes.get_Black()
pen = PdfPen(brush, 1.0)
# Specify the blank margins around the page
leftMargin = 54.0
rightMargin = 54.0
bottomMargin = 72.0
# Create a PdfPageNumberField object and a PdfPageCountField object
pageNumberField = PdfPageNumberField()
pageCountField = PdfPageCountField()
# Create a PdfCompositeField object to combine page count field and page number field in a single string
compositeField = PdfCompositeField(font, brush, "Page {0} of {1}", [pageNumberField, pageCountField])
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Get the page size
pageSize = doc.Pages[i].Size
# Draw a line at the specified position
page.Canvas.DrawLine(pen, leftMargin, pageSize.Height - bottomMargin + 15.0, pageSize.Width - rightMargin, pageSize.Height - bottomMargin + 15.0)
# Measure the size the "Page X of Y"
pageNumberSize = font.MeasureString("Page {} of {}".format(i + 1, doc.Pages.Count))
# Set the location of the composite field
compositeField.Location = PointF(pageSize.Width - pageNumberSize.Width - rightMargin, pageSize.Height - bottomMargin + 18.0)
# Draw the composite field on the page
compositeField.Draw(page.Canvas, 0.0, 0.0)
# Save to a different PDF file
doc.SaveToFile("Output/RightAlignedPageNumbers.pdf")
# Dispose resources
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Apply Shadow, Transparent, and 3D Effects to Text in PowerPoint
Enhancing the visual appeal of your PowerPoint presentations is crucial for capturing your audience's attention. One effective way to achieve this is by applying advanced text effects such as shadows, transparency, and 3D effects. These techniques can add depth, dimension, and a modern look to your text, making your slides more engaging and professional. In this article, we'll demonstrate how to apply shadow, transparent and 3D effects to text in PowerPoint in Python using Spire.Presentation for Python.
- Apply Shadow Effect to Text in PowerPoint in Python
- Apply Transparent Effect to Text in PowerPoint in Python
- Apply 3D Effect to Text in PowerPoint in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Apply Shadow Effect to Text in PowerPoint in Python
Spire.Presentation for Python offers the InnerShadowEffect and OuterShadowEffect classes for creating inner and outer shadow effects. These shadow effects can then be applied to the text within shapes by using the IAutoShape.TextFrame.TextRange.EffectDag.InnerShadowEffect and IAutoShape.TextFrame.TextRange.EffectDag.OuterShadowEffect properties. The detailed steps are as follows.
- Create an object of the Presentation class.
- Get a specific slide in the presentation using the Presentation.Slides[index] property.
- Add a shape to the slide using the ISilde.Shapes.AppendShape() method.
- Add text to the shape using the IAutoShape.AppendTextFrame() method.
- Create an inner or outer shadow effect using the InnerShadowEffect or OuterShadowEffect class.
- Set the blur radius, direction, distance and color, for the inner or outer shadow effect using the properties offered by the InnerShadowEffect or OuterShadowEffect class.
- Apply the inner or outer shadow effect to the text within the shape using the IAutoShape.TextFrame.TextRange.EffectDag.InnerShadowEffect or IAutoShape.TextFrame.TextRange.EffectDag.OuterShadowEffect property.
- Save the resulting presentation using the Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an object of the Presentation class
ppt = Presentation()
# Get the first slide
slide = ppt.Slides[0]
# Add the first rectangular shape to the slide
shape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF.FromLTRB(120, 60, 500, 200))
shape.Fill.FillType = FillFormatType.none
# Add text to the shape
shape.AppendTextFrame("Text With Outer Shadow Effect")
shape.TextFrame.Paragraphs[0].TextRanges[0].LatinFont = TextFont("Arial")
shape.TextFrame.Paragraphs[0].TextRanges[0].FontHeight = 21
shape.TextFrame.Paragraphs[0].TextRanges[0].Fill.FillType = FillFormatType.Solid
shape.TextFrame.Paragraphs[0].TextRanges[0].Fill.SolidColor.Color = Color.get_Black()
# Create an outer shadow effect
outerShadow = OuterShadowEffect()
# Set the blur radius, direction, distance and color for the outer shadow effect
outerShadow.BlurRadius = 0
outerShadow.Direction = 50
outerShadow.Distance = 10
outerShadow.ColorFormat.Color = Color.get_LightBlue()
# Apply the outer shadow effect to the text in the first rectangular shape
shape.TextFrame.TextRange.EffectDag.OuterShadowEffect = outerShadow
# Add the second rectangular shape to the slide
shape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF.FromLTRB(120, 300, 500, 440))
shape.Fill.FillType = FillFormatType.none
# Add text to the shape
shape.AppendTextFrame("Text With Inner Shadow Effect")
shape.TextFrame.Paragraphs[0].TextRanges[0].LatinFont = TextFont("Arial")
shape.TextFrame.Paragraphs[0].TextRanges[0].FontHeight = 21
shape.TextFrame.Paragraphs[0].TextRanges[0].Fill.FillType = FillFormatType.Solid
shape.TextFrame.Paragraphs[0].TextRanges[0].Fill.SolidColor.Color = Color.get_Black()
# Create an inner shadow effect
innerShadow = InnerShadowEffect()
# Set the blur radius, direction, distance and color for the inner shadow effect
innerShadow.BlurRadius = 0
innerShadow.Direction = 50
innerShadow.Distance = 10
innerShadow.ColorFormat.Color = Color.get_LightBlue()
# Apply the inner shadow effect to the text in the second rectangular shape
shape.TextFrame.TextRange.EffectDag.InnerShadowEffect = innerShadow
# Save the resulting presentation
ppt.SaveToFile("SetShadowEffect.pptx", FileFormat.Pptx2013)
ppt.Dispose()

Apply Transparent Effect to Text in PowerPoint in Python
Spire.Presentation for Python does not offer a direct method to apply transparency effect to text, but you can control the transparency by adjusting the alpha value of the text color. The detailed steps are as follows.
- Create an object of the Presentation class.
- Get a specific slide in the presentation using the Presentation.Slides[index] property.
- Add a shape to the slide using the ISilde.Shapes.AppendShape() method.
- Retrieve the paragraph collection from the text frame within the shape using the IAutoShape.TextFrame.Paragraphs property, then remove any default paragraphs from the collection using the ParagraphList.Clear() method.
- Add new paragraphs to the collection using the ParagraphList.Append() method, and insert text into each paragraph using the TextParagraph.TextRanges.Append() method.
- Set the fill type of the text to solid using the TextRange.Fill.FillType property.
- Adjust the transparency of the text by setting the color with varying alpha values using the Color.FromArgb(alpha:int, red:int, green:int, blue:int) method, where the alpha value controls the transparency level—the lower the alpha, the more transparent the text.
- Save the resulting presentation using the Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an object of the Presentation class
ppt = Presentation()
# Get the first slide
slide = ppt.Slides[0]
# Add a rectangular shape to the slide
textboxShape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF.FromLTRB(100, 100, 400, 220))
# Make the border of the shape transparent
textboxShape.ShapeStyle.LineColor.Color = Color.get_Transparent()
# Set the shape's fill to none
textboxShape.Fill.FillType = FillFormatType.none
# Retrieve the paragraph collection from the text frame within the shape
paras = textboxShape.TextFrame.Paragraphs
# Remove any default paragraphs
paras.Clear()
# Add three new paragraphs to the text frame, each with a different transparency level for the text
alpha = 55 # Initial alpha value for text transparency
for i in range(3):
# Create and add a new paragraph
paras.Append(TextParagraph())
# Add text to the paragraph
paras[i].TextRanges.Append(TextRange("Text with Different Transparency"))
# Set the text fill type to solid
paras[i].TextRanges[0].Fill.FillType = FillFormatType.Solid
# Set the text color with varying transparency, controlled by the alpha value
paras[i].TextRanges[0].Fill.SolidColor.Color = Color.FromArgb(
alpha,
Color.get_Blue().R,
Color.get_Blue().G,
Color.get_Blue().B
)
# Increase alpha value to reduce transparency for the next paragraph
alpha += 100
# Save the resulting presentation
ppt.SaveToFile("SetTransparency.pptx", FileFormat.Pptx2013)
ppt.Dispose()

Apply 3D Effect to Text in PowerPoint in Python
The FormatThreeD class in Spire.Presentation for Python is used for creating a 3D effect. You can access the FormatThreeD object using the IAutoShape.TextFrame.TextThreeD property, then use the properties of the FormatThreeD class to configure the settings for the 3D effect. The detailed steps are as follows.
- Create an object of the Presentation class.
- Get a specific slide in the presentation using the Presentation.Slides[index] property.
- Add a shape to the slide using the ISilde.Shapes.AppendShape() method.
- Add text to the shape using the IAutoshape.AppendTextFrame() method.
- Access the FormatThreeD object using the IAutoShape.TextFrame.TextThreeD property.
- Set the material type, top bevel type, contour color and width, and lighting type for the 3D effect through the properties of the FormatThreeD class.
- Save the resulting presentation using the Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an object of the Presentation class
ppt = Presentation()
# Get the first slide
slide = ppt.Slides[0]
# Add a rectangular shape to the slide
shape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF.FromLTRB(30, 40, 680, 240))
# Make the border of the shape transparent
shape.ShapeStyle.LineColor.Color = Color.get_Transparent()
# Set the shape's fill to none
shape.Fill.FillType = FillFormatType.none
# Add text to the shape
shape.AppendTextFrame("Text with 3D Effect")
# Set text color
textRange = shape.TextFrame.TextRange
textRange.Fill.FillType = FillFormatType.Solid
textRange.Fill.SolidColor.Color = Color.get_LightBlue()
# Set font
textRange.FontHeight = 40
textRange.LatinFont = TextFont("Arial")
# Access the FormatThreeD object
threeD = shape.TextFrame.TextThreeD
# Set the material type for the 3D effect
threeD.ShapeThreeD.PresetMaterial = PresetMaterialType.Metal
# Set the top bevel type for the 3D effect
threeD.ShapeThreeD.TopBevel.PresetType = BevelPresetType.Circle
# Set the contour color and width for the 3D effect
threeD.ShapeThreeD.ContourColor.Color = Color.get_Green()
threeD.ShapeThreeD.ContourWidth = 3
# Set the lighting type for the 3D effect
threeD.LightRig.PresetType = PresetLightRigType.Sunrise
# Save the resulting presentation
ppt.SaveToFile("Set3DEffect.pptx", FileFormat.Pptx2013)
ppt.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.