Python: Convert PDF to Grayscale or Linearized
Converting a PDF to grayscale reduces file size by removing unnecessary color data, turning the content into shades of gray. This is especially useful for documents where color isn’t critical, such as text-heavy reports or forms, resulting in more efficient storage and faster transmission. On the other hand, linearization optimizes the PDF’s internal structure for web use. It enables users to start viewing the first page while the rest of the file is still loading, providing a faster and smoother experience, particularly for online viewing. In this article, we will demonstrate how to convert PDF files to grayscale or linearized PDFs in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to Grayscale in Python
Converting a PDF document to grayscale can be achieved by using the PdfGrayConverter.ToGrayPdf() method. The detailed steps are as follows.
- Load a PDF document using the PdfGrayConverter class.
- Convert the PDF document to grayscale using the PdfGrayConverter.ToGrayPdf() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output PDF file paths inputFile = "Sample.pdf" outputFile = "Output/ConvertToGrayscale.pdf" # Load a PDF document using the PdfGrayConverter class converter = PdfGrayConverter(inputFile) # Convert the PDF document to grayscale converter.ToGrayPdf(outputFile)
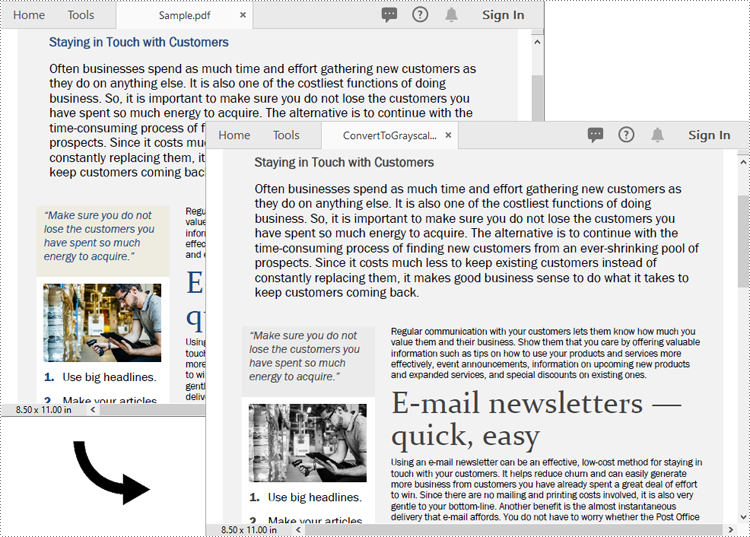
Convert PDF to Linearized in Python
To convert a PDF to linearized, you can use the PdfToLinearizedPdfConverter.ToLinearizedPdf() method. The detailed steps are as follows.
- Load a PDF document using the PdfToLinearizedPdfConverter class.
- Convert the PDF document to linearized using the PdfToLinearizedPdfConverter.ToLinearizedPdf() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output PDF file paths inputFile = "Sample.pdf" outputFile = "Output/ConvertToLinearizedPdf.pdf" # Load a PDF document using the PdfToLinearizedPdfConverter class converter = PdfToLinearizedPdfConverter(inputFile) # Convert the PDF document to a linearized PDF converter.ToLinearizedPdf(outputFile)
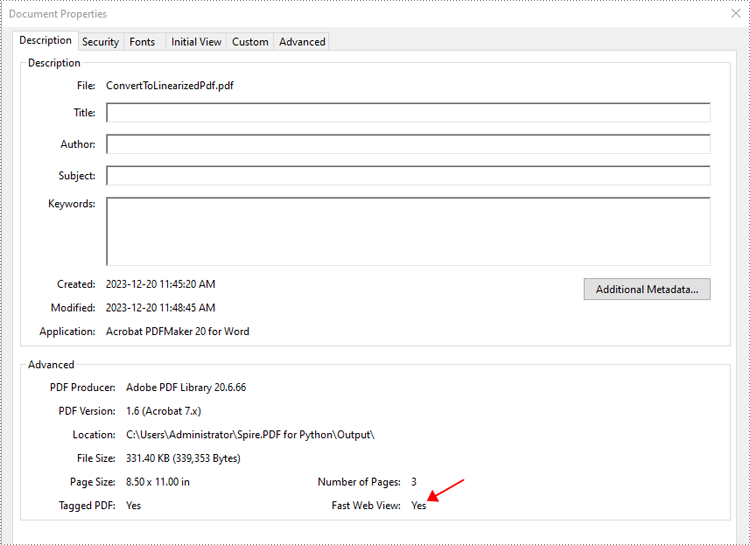
Open the result file in Adobe Acrobat and check the document properties. You will see that the value for "Fast Web View" is set to "Yes", indicating that the file has been linearized.
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Load and Save PDFs with Byte Streams
Handling PDF documents using bytes and bytearray provides an efficient and flexible approach within applications. By processing PDFs directly as byte streams, developers can manage documents in memory or transfer them over networks without the need for temporary file storage, optimizing space and improving overall application performance. This method also facilitates seamless integration with web services and APIs. Additionally, using bytearray allows developers to make precise byte-level modifications to PDF documents.
This article will demonstrate how to save PDFs as bytes and bytearray and load PDFs from bytes and bytearray using Spire.PDF for Python, offering practical examples for Python developers.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Create a PDF Document and Save It to Bytes and Bytearray
Developers can create PDF documents using the classes and methods provided by Spire.PDF for Python, save them to a Stream object, and then convert it to an immutable bytes object or a mutable bytearray object. The Stream object can also be used to perform byte-level operations.
The detailed steps are as follows:
- Create an object of PdfDocument class to create a PDF document.
- Add a page to the document and draw text on the page.
- Save the document to a Stream object using PdfDocument.SaveToStream() method.
- Convert the Stream object to a bytes object using Stream.ToArray() method.
- The bytes object can be directly converted to a bytearray object.
- Afterward, the byte streams can be used for further operations, such as writing them to a file using the BinaryIO.write() method.
- Python
from spire.pdf import *
# Create an instance of PdfDocument class
pdf = PdfDocument()
# Set the page size and margins of the document
pageSettings = pdf.PageSettings
pageSettings.Size = PdfPageSize.A4()
pageSettings.Margins.Top = 50
pageSettings.Margins.Bottom = 50
pageSettings.Margins.Left = 40
pageSettings.Margins.Right = 40
# Add a new page to the document
page = pdf.Pages.Add()
# Create fonts and brushes for the document content
titleFont = PdfTrueTypeFont("HarmonyOS Sans SC", 16.0, PdfFontStyle.Bold, True)
titleBrush = PdfBrushes.get_Brown()
contentFont = PdfTrueTypeFont("HarmonyOS Sans SC", 13.0, PdfFontStyle.Regular, True)
contentBrush = PdfBrushes.get_Black()
# Draw the title on the page
titleText = "Brief Introduction to Cloud Services"
titleSize = titleFont.MeasureString(titleText)
page.Canvas.DrawString(titleText, titleFont, titleBrush, PointF(0.0, 30.0))
# Draw the body text on the page
contentText = ("Cloud computing is a service model where computing resources are provided over the internet on a pay-as-you-go basis. "
"It is a type of infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS), and software-as-a-service (SaaS) model. "
"Cloud computing is typically offered througha subscription-based model, where users pay for access to the cloud resources on a monthly, yearly, or other basis.")
# Set the string format of the body text
contentFormat = PdfStringFormat()
contentFormat.Alignment = PdfTextAlignment.Justify
contentFormat.LineSpacing = 20.0
# Create a TextWidget object with the body text and apply the string format
textWidget = PdfTextWidget(contentText, contentFont, contentBrush)
textWidget.StringFormat = contentFormat
# Create a TextLayout object and set the layout options
textLayout = PdfTextLayout()
textLayout.Layout = PdfLayoutType.Paginate
textLayout.Break = PdfLayoutBreakType.FitPage
# Draw the TextWidget on the page
rect = RectangleF(PointF(0.0, titleSize.Height + 50.0), page.Canvas.ClientSize)
textWidget.Draw(page, rect, textLayout)
# Save the PDF document to a Stream object
pdfStream = Stream()
pdf.SaveToStream(pdfStream)
# Convert the Stream object to a bytes object
pdfBytes = pdfStream.ToArray()
# Convert the Stream object to a bytearray object
pdfBytearray = bytearray(pdfStream.ToArray())
# Write the byte stream to a file
with open("output/PDFBytearray.pdf", "wb") as f:
f.write(pdfBytearray)

Load a PDF Document from Byte Streams
Developers can use a bytes object of a PDF file to create a stream and load it using the PdfDocument.LoadFromStream() method. Once the PDF document is loaded, various operations such as reading, modifying, and converting the PDF can be performed. The following is an example of the steps:
- Create a bytes object with a PDF file.
- Create a Stream object using the bytes object.
- Load the Stream object as a PDF document using PdfDocument.LoadFromStream() method.
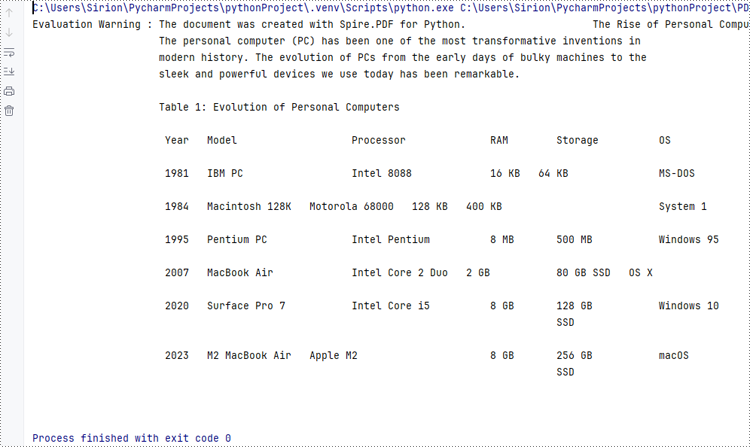
- Extract the text from the first page of the document and print the text.
- Python
from spire.pdf import *
# Create a byte array from a PDF file
with open("Sample.pdf", "rb") as f:
byteData = f.read()
# Create a Stream object from the byte array
stream = Stream(byteData)
# Load the Stream object as a PDF document
pdf = PdfDocument(stream)
# Get the text from the first page
page = pdf.Pages.get_Item(0)
textExtractor = PdfTextExtractor(page)
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
text = textExtractor.ExtractText(extractOptions)
# Print the text
print(text)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert PDF to PowerPoint
PDF (Portable Document Format) files are widely used for sharing and distributing documents due to their consistent formatting and broad compatibility. However, when it comes to presentations, PowerPoint remains the preferred format for many users. PowerPoint offers a wide range of features and tools that enable the creation of dynamic, interactive, and visually appealing slideshows. Unlike static PDF documents, PowerPoint presentations allow for the incorporation of animations, transitions, multimedia elements, and other interactive components, making them more engaging and effective for delivering information to the audience.
By converting PDF to PowerPoint, you can transform a static document into a captivating and impactful presentation that resonates with your audience and helps to achieve your communication goals. In this article, we will explain how to convert PDF files to PowerPoint format in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to PowerPoint in Python
Spire.PDF for Python provides the PdfDocument.SaveToFile(filename:str, FileFormat.PPTX) method to convert a PDF document into a PowerPoint presentation. With this method, each page of the original PDF document will be converted into a single slide in the output PPTX presentation.
The detailed steps to convert a PDF document to PowerPoint format are as follows:
- Create an object of the PdfDocument class.
- Load a sample PDF document using the PdfDocument.LoadFromFile() method.
- Save the PDF document as a PowerPoint PPTX file using the PdfDocument.SaveToFile(filename:str, FileFormat.PPTX) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a sample PDF document
pdf.LoadFromFile("Sample.pdf")
# Save the PDF document as a PowerPoint PPTX file
pdf.SaveToFile("PdfToPowerPoint.pptx", FileFormat.PPTX)
pdf.Close()
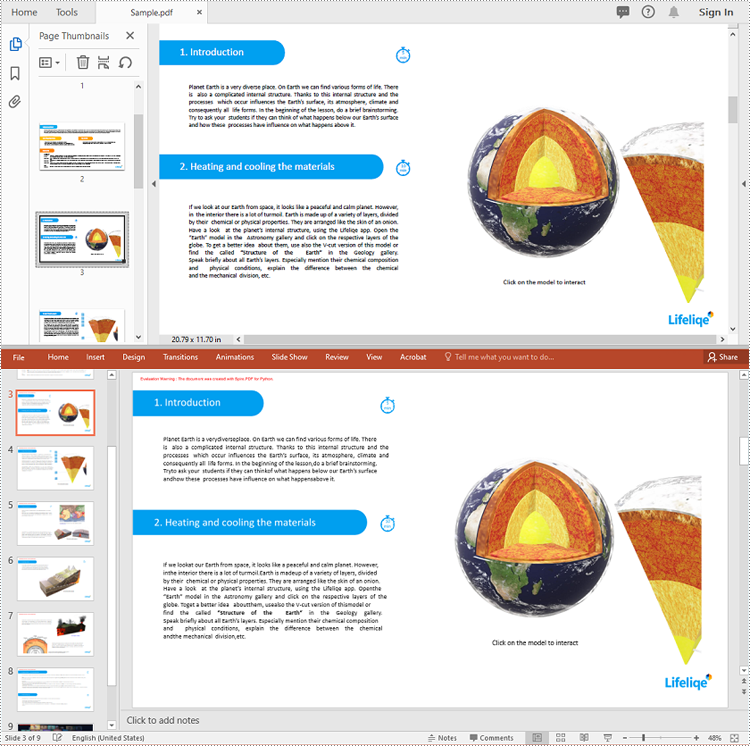
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert PDF to TIFF and TIFF to PDF
TIFF is a popular image format used in scanning and archiving due to its high quality and support for a wide range of color spaces. On the other hand, PDFs are widely used for document exchange because they preserve the layout and formatting of a document while compressing the file size. Conversion between these formats can be useful for various purposes such as archival, editing, or sharing documents.
In this article, you will learn how to convert PDF to TIFF and TIFF to PDF using the Spire.PDF for Python and Pillow libraries.
Install Spire.PDF for Python
This situation relies on the combination of Spire.PDF for Python and Pillow (PIL). Spire.PDF is used to read, create and convert PDF documents, while the PIL library is used for handling TIFF files and accessing their frames.
The libraries can be easily installed on your device through the following pip command.
pip install Spire.PDF pip install pillow
Convert PDF to TIFF in Python
To complete the PDF to TIFF conversion, you first need to load the PDF document and convert the individual pages into image streams using Spire.PDF. Subsequently, these image streams are then merged together using the functionality of the PIL library, resulting in a consolidated TIFF image.
The following are the steps to convert PDF to TIFF using Python.
- Create a PdfDocument object.
- Load a PDF document from a specified file path.
- Iterate through the pages in the document.
- Convert each page into an image stream using PdfDocument.SaveAsImage() method.
- Convert the image stream into a PIL image.
- Combine these PIL images into a single TIFF image.
- Python
from spire.pdf.common import *
from spire.pdf import *
from PIL import Image
from io import BytesIO
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Create an empty list to store PIL Images
images = []
# Iterate through all pages in the document
for i in range(doc.Pages.Count):
# Convert a specific page to an image stream
with doc.SaveAsImage(i) as imageData:
# Open the image stream as a PIL image
img = Image.open(BytesIO(imageData.ToArray()))
# Append the PIL image to list
images.append(img)
# Save the PIL Images as a multi-page TIFF file
images[0].save("Output/ToTIFF.tiff", save_all=True, append_images=images[1:])
# Dispose resources
doc.Dispose()
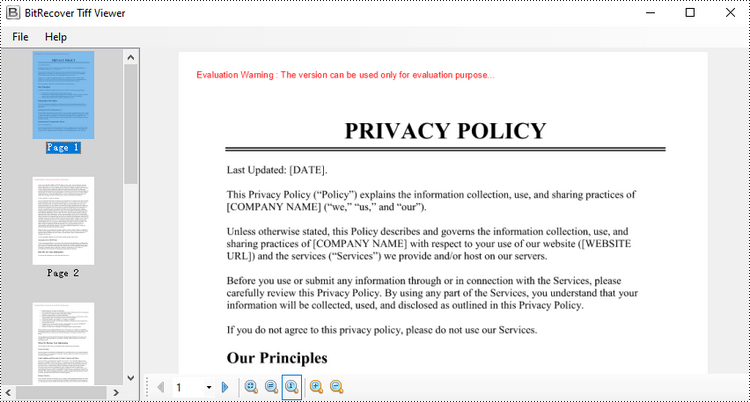
Convert TIFF to PDF in Python
With the assistance of the PIL library, you can load a TIFF file and transform each frame into distinct PNG files. Afterwards, you can utilize Spire.PDF to draw these PNG files onto pages within a PDF document.
To convert a TIFF image to a PDF document using Python, follow these steps.
- Create a PdfDocument object.
- Load a TIFF image.
- Iterate though the frames in the TIFF image.
- Get a specific frame, and save it as a PNG file.
- Add a page to the PDF document.
- Draw the image on the page at the specified location using PdfPageBase.Canvas.DrawImage() method.
- Save the document to a PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
from PIL import Image
import io
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a TIFF image
tiff_image = Image.open("C:\\Users\\Administrator\\Desktop\\TIFF.tiff")
# Iterate through the frames in it
for i in range(tiff_image.n_frames):
# Go to the current frame
tiff_image.seek(i)
# Extract the image of the current frame
frame_image = tiff_image.copy()
# Save the image to a PNG file
frame_image.save(f"temp/output_frame_{i}.png")
# Load the image file to PdfImage
image = PdfImage.FromFile(f"temp/output_frame_{i}.png")
# Get image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page to the document
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save the document to a PDF file
doc.SaveToFile("Output/TiffToPdf.pdf",FileFormat.PDF)
# Dispose resources
doc.Dispose()
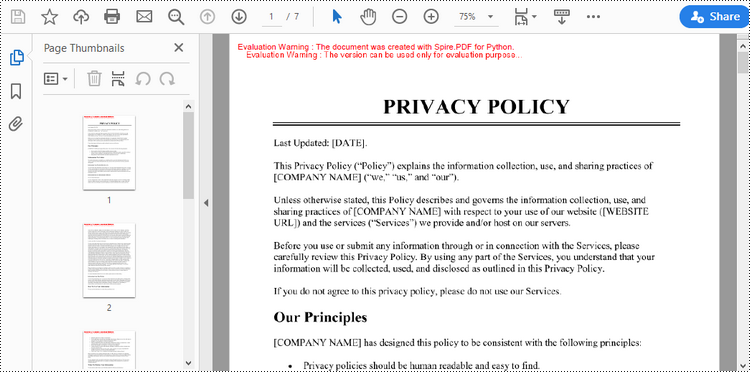
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
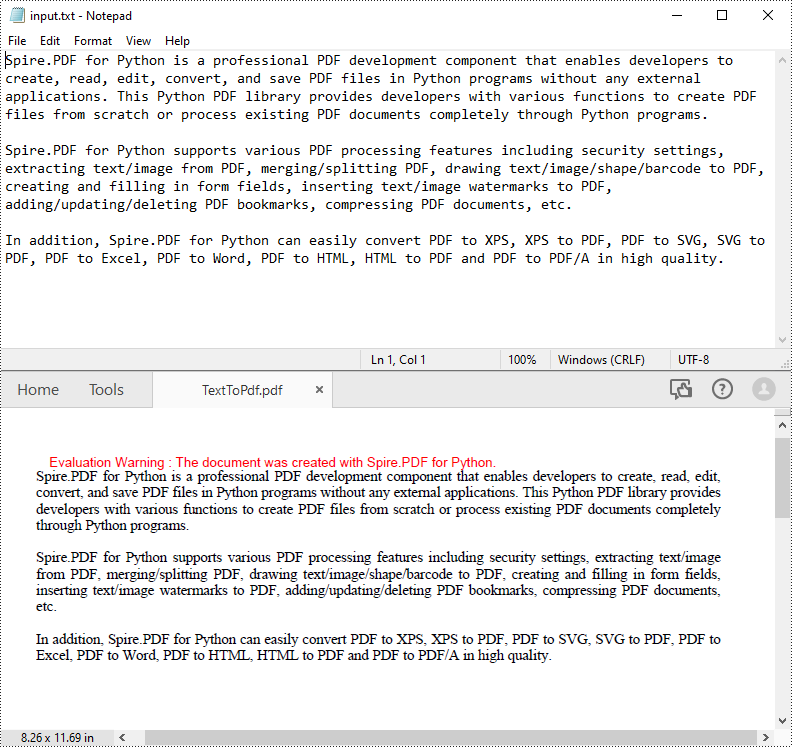
Python: Convert TXT to PDF
PDF is an ideal file format for sharing and archiving. If you are working with text files, you may find it beneficial to convert them to PDF files for enhanced portability, security and format preservation. In this article, you will learn how to convert TXT files to PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert TXT to PDF with Python
Spire.PDF for Python allows to convert text files to PDF by reading the text content from the input TXT file, and then drawing it onto the pages of a PDF document. Some of the core classes and methods used are listed below:
- PdfDocument class: Represents a PDF document model.
- PdfTextWidget class: Represents the text area with the ability to span several pages.
- File.ReadAllText() method: Reads the text in the text file into a string object.
- PdfDocument.Pages.Add() method: Adds a page to a PDF document.
- PdfTextWidget.Draw() method: Draws the text widget at a specified location on the page.
The following are the detailed steps to convert TXT to PDF in Python:
- Read text from the TXT file using File.ReadAllText() method.
- Create a PdfDocument instance and add a page to the PDF file.
- Create a PDF font and brush objects.
- Set the text format and layout.
- Create a PdfTextWidget object to hold the text content.
- Draw the text widget at a specified location on the PDF page using PdfTextWidget.Draw() method.
- Save the PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
def ReadFromTxt(fname: str) -> str:
with open(fname, 'r') as f:
text = f.read()
return text
inputFile = "input.txt"
outputFile = "TextToPdf.pdf"
# Get text from the txt file
text = ReadFromTxt(inputFile)
# Create a PdfDocument instance
pdf = PdfDocument()
# Add a page
page = pdf.Pages.Add()
# Create a PDF font and PDF brush
font = PdfFont(PdfFontFamily.TimesRoman, 11.0)
brush = PdfBrushes.get_Black()
# Set the text alignment and line spacing
strformat = PdfStringFormat()
strformat.LineSpacing = 10.0
strformat.Alignment = PdfTextAlignment.Justify
# Set the text layout
textLayout = PdfTextLayout()
textLayout.Break = PdfLayoutBreakType.FitPage
textLayout.Layout = PdfLayoutType.Paginate
# Create a PdfTextWidget instance to hold the text content
textWidget = PdfTextWidget(text, font, brush)
# Set the text format
textWidget.StringFormat = strformat
# Draw the text at the specified location on the page
bounds = RectangleF(PointF(0.0, 20.0), page.Canvas.ClientSize)
textWidget.Draw(page, bounds, textLayout)
# Save the result file
pdf.SaveToFile(outputFile, FileFormat.PDF)
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
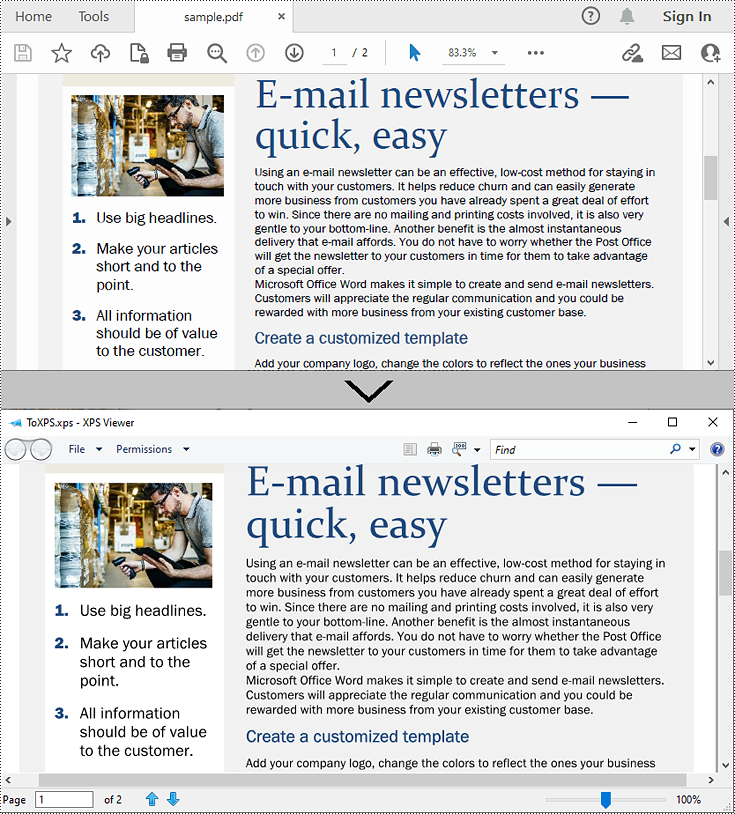
Python: Convert PDF to XPS
XPS, or XML Paper Specification, is a file format developed by Microsoft as an alternative to PDF (Portable Document Format). Similar to PDF, XPS is specifically designed to preserve the visual appearance and layout of documents across different platforms and devices, ensuring consistent viewing regardless of the software or hardware being used.
Converting PDF files to XPS format offers several notable benefits. Firstly, XPS files are fully supported within the Windows ecosystem. If you work in a Microsoft-centric environment that heavily relies on Windows operating systems and Microsoft applications, converting PDF files to XPS guarantees smooth compatibility and an optimized viewing experience tailored to the Windows platform.
Secondly, XPS files are optimized for printing, ensuring precise reproduction of the document on paper. This makes XPS the preferred format when high-quality printed copies of the document are required.
Lastly, XPS files are based on XML, a widely adopted standard for structured data representation. This XML foundation enables easy extraction and manipulation of content within the files, as well as seamless integration of file content with other XML-based workflows or systems.
In this article, we will demonstrate how to convert PDF files to XPS format in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to XPS in Python
Converting a PDF file to the XPS file format is very easy with Spire.PDF for Python. Simply load the PDF file using the PdfDocument.LoadFromFile() method, and then save the PDF file to the XPS file format using the PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method. The detailed steps are as follows:
- Create an object of the PdfDocument class.
- Load the sample PDF file using the PdfDocument.LoadFromFile() method.
- Save the PDF file to the XPS file format using the PdfDocument.SaveToFile (filename:str, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output file paths inputFile = "sample.pdf" outputFile = "ToXPS.xps" # Create an object of the PdfDocument class pdf = PdfDocument() # Load the sample PDF file pdf.LoadFromFile(inputFile) # Save the PDF file to the XPS file format pdf.SaveToFile(outputFile, FileFormat.XPS) # Close the PdfDocument object pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
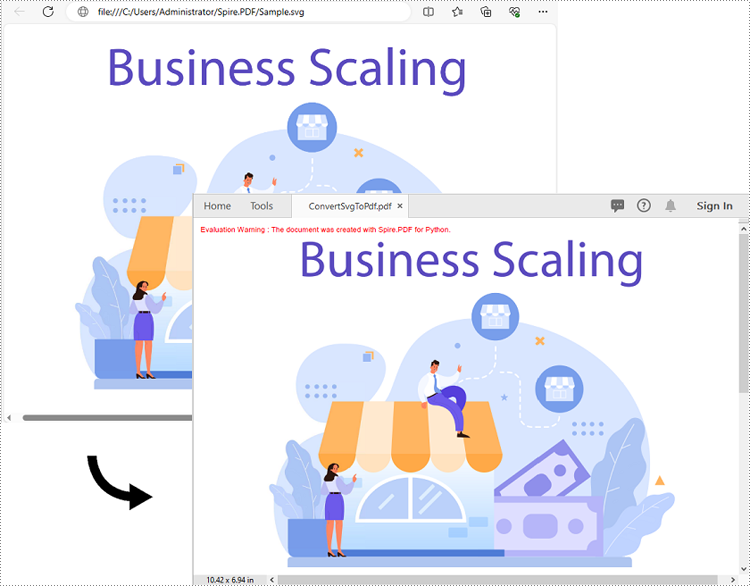
Python: Convert SVG to PDF
SVG files are commonly used for web graphics and vector-based illustrations because they can be scaled and adjusted easily. PDF, on the other hand, is a versatile format widely supported across different devices and operating systems. Converting SVG to PDF allows for easy sharing of graphics and illustrations, ensuring that recipients can open and view the files without requiring specialized software or worrying about browser compatibility issues. In this article, we will demonstrate how to convert SVG files to PDF format in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert SVG to PDF in Python
Spire.PDF for Python provides the PdfDocument.LoadFromSvg() method, which allows users to load an SVG file. Once loaded, users can use the PdfDocument.SaveToFile() method to save the SVG file as a PDF file. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load an SVG file using PdfDocument.LoadFromSvg() method.
- Save the SVG file to PDF format using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load an SVG file
doc.LoadFromSvg("Sample.svg")
# Save the SVG file to PDF format
doc.SaveToFile("ConvertSvgToPdf.pdf", FileFormat.PDF)
# Close the PdfDocument object
doc.Close()
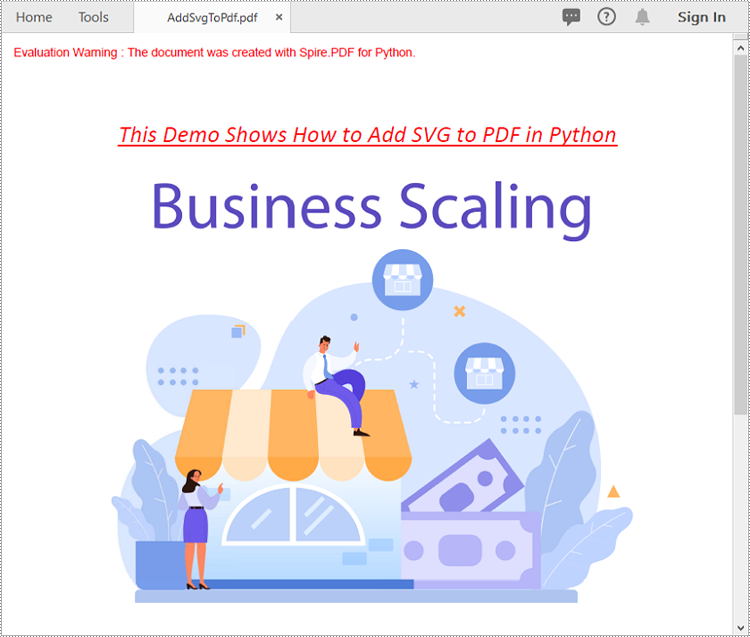
Add SVG to PDF in Python
In addition to converting SVG to PDF directly, Spire.PDF for Python also supports adding SVG files to specific locations in PDF. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load an SVG file using PdfDocument.LoadFromSvg() method.
- Create a template based on the content of the SVG file using PdfDocument. Pages[].CreateTemplate() method.
- Get the width and height of the template.
- Create another object of the PdfDocument class and load a PDF file using PdfDocument.LoadFromFile() method.
- Draw the template with a custom size at a specific location in the PDF file using PdfDocument.Pages[].Canvas.DrawTemplate() method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc1 = PdfDocument()
# Load an SVG file
doc1.LoadFromSvg("Sample.svg")
# Create a template based on the content of the SVG
template = doc1.Pages[0].CreateTemplate()
# Get the width and height of the template
width = template.Width
height = template.Height
# Create another PdfDocument object
doc2 = PdfDocument()
# Load a PDF file
doc2.LoadFromFile("Sample.pdf")
# Draw the template with a custom size at a specific location on the first page of the loaded PDF file
doc2.Pages[0].Canvas.DrawTemplate(template, PointF(10.0, 100.0), SizeF(width*0.8, height*0.8))
# Save the result file
doc2.SaveToFile("AddSvgToPdf.pdf", FileFormat.PDF)
# Close the PdfDocument objects
doc2.Close()
doc1.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert PDF to PDF/A and Vice Versa
PDF/A is a specialized format designed specifically for long-term archiving and preservation of electronic documents. It guarantees that the content, structure, and visual appearance of the documents remain unchanged over time. By converting PDF files to PDF/A format, you ensure the long-term accessibility of the documents, regardless of software, operating systems, or future technological advancements. Conversely, converting PDF/A files to standard PDF format makes it easier to edit, share, and collaborate on the documents, ensuring better compatibility across different applications, devices, and platforms. In this article, we will explain how to convert PDF to PDF/A and vice versa in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
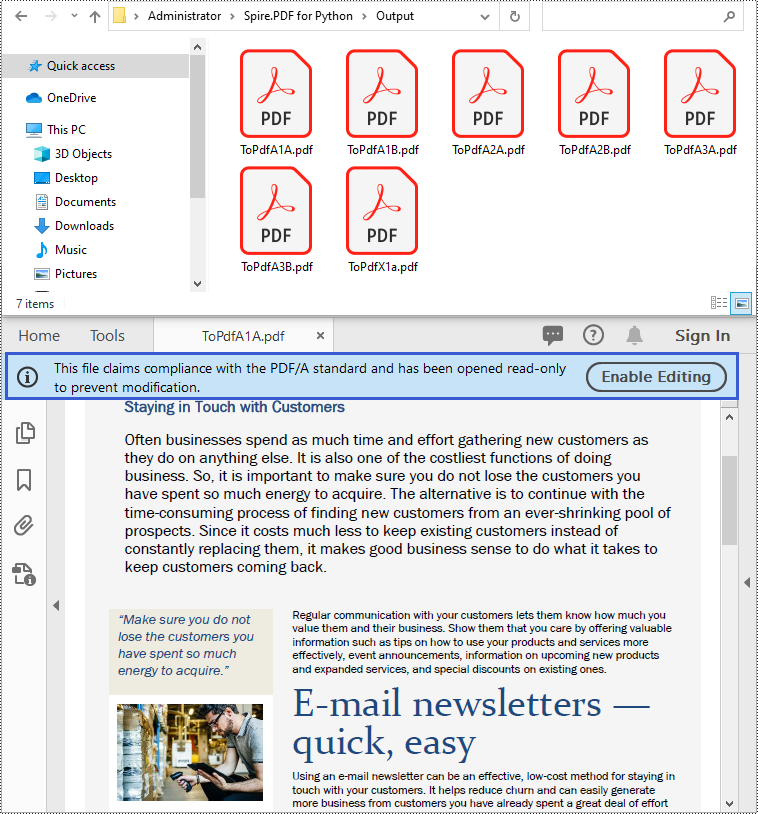
Convert PDF to PDF/A in Python
The PdfStandardsConverter class provided by Spire.PDF for Python supports converting PDF to various PDF/A formats, including PDF/A-1a, 2a, 3a, 1b, 2b and 3b. Moreover, it also supports converting PDF to PDF/X-1a:2001. The detailed steps are as follows.
- Specify the input file path and output folder.
- Create a PdfStandardsConverter object and pass the input file path to the constructor of the class as a parameter.
- Convert the input file to a Pdf/A-1a conformance file using PdfStandardsConverter.ToPdfA1A() method.
- Convert the input file to a Pdf/A-1b file using PdfStandardsConverter.ToPdfA1B() method.
- Convert the input file to a Pdf/A-2a file using PdfStandardsConverter.ToPdfA2A() method.
- Convert the input file to a Pdf/A-2b file using PdfStandardsConverter.ToPdfA2B() method.
- Convert the input file to a Pdf/A-3a file using PdfStandardsConverter.ToPdfA3A() method.
- Convert the input file to a Pdf/A-3b file using PdfStandardsConverter.ToPdfA3B() method.
- Convert the input file to a PDF/X-1a:2001 file using PdfStandardsConverter.ToPdfX1A2001() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input file path and output folder inputFile = "Sample.pdf" outputFolder = "Output/" # Create an object of the PdfStandardsConverter class converter = PdfStandardsConverter(inputFile) # Convert the input file to PdfA1A converter.ToPdfA1A(outputFolder + "ToPdfA1A.pdf") # Convert the input file to PdfA1B converter.ToPdfA1B(outputFolder + "ToPdfA1B.pdf") # Convert the input file to PdfA2A converter.ToPdfA2A(outputFolder + "ToPdfA2A.pdf") # Convert the input file to PdfA2B converter.ToPdfA2B(outputFolder + "ToPdfA2B.pdf") # Convert the input file to PdfA3A converter.ToPdfA3A(outputFolder + "ToPdfA3A.pdf") # Convert the input file to PdfA3B converter.ToPdfA3B(outputFolder + "ToPdfA3B.pdf") # Convert the input file to PDF/X-1a:2001 converter.ToPdfX1A2001(outputFolder + "ToPdfX1a.pdf")
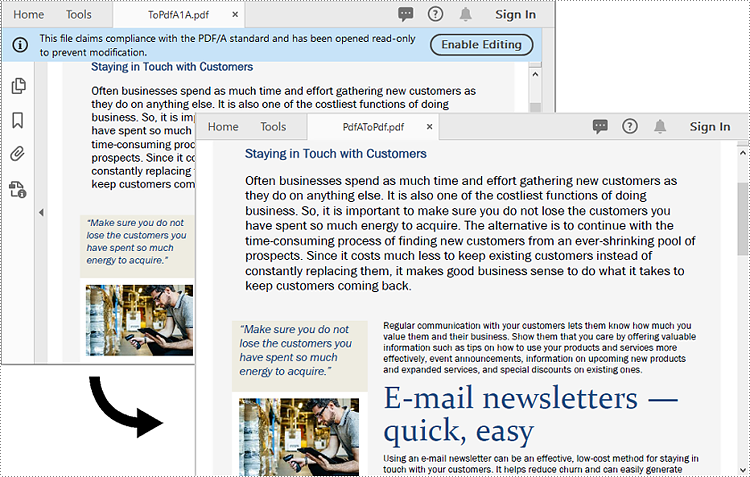
Convert PDF/A to PDF in Python
To convert a PDF/A file back to a standard PDF format, you need to create a new standard PDF file, and then draw the page content of the PDF/A file to the newly created PDF file. The detailed steps are as follows.
- Create a PdfDocument object.
- Load a PDF/A file using PdfDocument.LoadFromFile() method.
- Create a PdfNewDocument object and set its compression level as none.
- Loop through the pages in the original PDF/A file.
- Add pages to the newly created PDF using PdfDocumentBase.Pages.Add() method.
- Draw the page content of the original PDF/A file to the corresponding pages of the newly created PDF using PdfPageBase.CreateTemplate.Draw() method.
- Create a Stream object and then save the new PDF to the stream using PdfNewDocument.Save() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Specify the input and output file paths
inputFile = "Output/ToPdfA1A.pdf"
outputFile = "PdfAToPdf.pdf"
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile(inputFile)
# Create a new standard PDF file
newDoc = PdfNewDocument()
newDoc.CompressionLevel = PdfCompressionLevel.none
# Add pages to the newly created PDF and draw the page content of the loaded PDF onto the corresponding pages of the newly created PDF
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
size = page.Size
p = newDoc.Pages.Add(size, PdfMargins(0.0))
page.CreateTemplate().Draw(p, 0.0, 0.0)
# Save the new PDF to a PDF file
fileStream = Stream(outputFile)
newDoc.Save(fileStream)
fileStream.Close()
newDoc.Close(True)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert PDF to HTML
HTML is the standard markup language for web pages. Converting PDF documents to HTML format allows you to embed them directly into web pages, making them accessible and viewable in web browsers without requiring additional software or plugins. In this article, we will demonstrate how to convert PDF to HTML in Python using Spire.PDF for Python.
- Convert PDF to HTML in Python
- Set Conversion Options When Converting PDF to HTML in Python
- Convert PDF to HTML Stream in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to HTML in Python
The PdfDocument.SaveToFile() method provided by Spire.PDF for Python allows you to convert a PDF document to HTML format. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Save the PDF document to HTML format using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Sample.pdf")
# Save the PDF document to HTML format
doc.SaveToFile("PdfToHtml.html", FileFormat.HTML)
doc.Close()
Set Conversion Options When Converting PDF to HTML in Python
The SetPdfToHtmlOptions() method of the PdfConvertOptions class enables you to specify the conversion options when converting PDF files to HTML. This method accepts the following parameters:
- useEmbeddedSvg (bool): Indicates whether to embed SVG in the resulting HTML file.
- useEmbeddedImg (bool): Indicates whether to embed images in the resulting HTML file. This option is applicable only when useEmbeddedSvg is set to False.
- maxPageOneFile (bool): Specifies the maximum number of pages to be included per HTML file. This option is applicable only when useEmbeddedSvg is set to False.
- useHighQualityEmbeddedSvg (bool): Indicates whether to use high-quality embedded SVG in the resulting HTML file. This option is applicable when useEmbeddedSvg is set to True.
The following steps explain how to specify conversion options when converting PDF to HTML.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the PdfConvertOptions object using PdfDocument.ConvertOptions property.
- Specify the PDF to HTML conversion options using PdfConvertOptions.SetPdfToHtmlOptions() method.
- Save the PDF document to HTML format using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Sample.pdf")
# Set the conversion options to embed images in the resulting HTML and limit one page per HTML file
pdfToHtmlOptions = doc.ConvertOptions
pdfToHtmlOptions.SetPdfToHtmlOptions(False, True, 1, False)
# Save the PDF document to HTML format
doc.SaveToFile("PdfToHtmlWithCustomOptions.html", FileFormat.HTML)
doc.Close()
Convert PDF to HTML Stream in Python
In addition to converting a PDF document to an HTML file, you can save it to an HTML stream by using the PdfDocument.SaveToStream() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Create an object of the Stream class.
- Save the PDF document to an HTML stream using PdfDocument.SaveToStream() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Sample.pdf")
# Save the PDF document to HTML stream
fileStream = Stream("PdfToHtmlStream.html")
doc.SaveToStream(fileStream, FileFormat.HTML)
fileStream.Close()
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert PDF to Word DOC or DOCX
PDF files are designed to preserve the formatting and layout of the original document, making them ideal for sharing and printing. However, they are typically not editable without specialized software. Converting a PDF to a Word document allows you to make changes, add or delete text, modify formatting, and customize content as needed. This is particularly useful when you want to update or revise existing PDF files. In this article, we will explain how to convert PDF to Word DOC or DOCX formats in Python using Spire.PDF for Python.
- Convert PDF to Word DOC or DOCX in Python
- Setting Document Properties While Converting PDF to Word in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to Word DOC or DOCX in Python
Spire.PDF for Python provides the PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method to convert PDF documents to a wide range of file formats, including Word DOC, DOCX, and more. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Convert the PDF document to a Word DOCX or DOC file using PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Sample.pdf")
# Convert the PDF document to a Word DOCX file
doc.SaveToFile("ToDocx.docx", FileFormat.DOCX)
# Or convert the PDF document to a Word DOC file
doc.SaveToFile("ToDoc.doc", FileFormat.DOC)
# Close the PdfDocument object
doc.Close()
Setting Document Properties While Converting PDF to Word in Python
Document properties are attributes or information associated with a document that provide additional details about the file. These properties offer insights into various aspects of the document, such as its author, title, subject, version, keywords, category, and more.
Spire.PDF for Python provides the PdfToDocConverter class which allows developers to convert a PDF document to a Word DOCX file and set document properties for the file. The detailed steps are as follows.
- Create an object of the PdfToDocConverter class.
- Set document properties, such as title, subject, comment and author, for the converted Word DOCX file using the properties of the PdfToDocConverter class.
- Convert the PDF document to a Word DOCX file using PdfToDocConverter.SaveToDocx() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfToDocConverter class
converter = PdfToDocConverter("Sample.pdf")
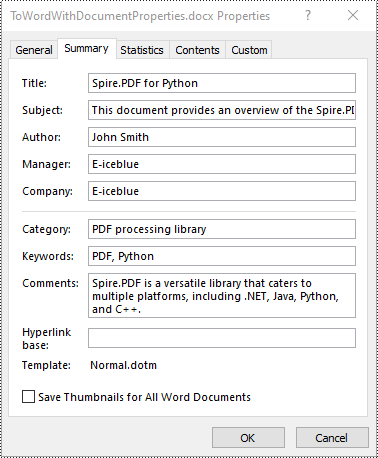
# Set document properties such as title, subject, author and keywords for the converted .DOCX file
converter.DocxOptions.Title = "Spire.PDF for Python"
converter.DocxOptions.Subject = "This document provides an overview of the Spire.PDF for Python product."
converter.DocxOptions.Tags = "PDF, Python"
converter.DocxOptions.Categories = "PDF processing library"
converter.DocxOptions.Commments = "Spire.PDF is a versatile library that caters to multiple platforms, including .NET, Java, Python, and C++."
converter.DocxOptions.Authors = "John Smith"
converter.DocxOptions.LastSavedBy = "Alexander Johnson"
converter.DocxOptions.Revision = 8
converter.DocxOptions.Version = "V4.0"
converter.DocxOptions.ProgramName = "Spire.PDF for Python"
converter.DocxOptions.Company = "E-iceblue"
converter.DocxOptions.Manager = "E-iceblue"
# Convert the PDF document to a Word DOCX file
converter.SaveToDocx("ToWordWithDocumentProperties.docx")
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.