Python: Convert PDF to SVG
SVG (Scalable Vector Graphics) is an XML-based vector image format that describes two-dimensional graphics using geometric shapes, text, and other graphical elements. SVG files can be easily scaled without losing image quality, which makes them ideal for various purposes such as web design, illustrations, and animations. In certain situations, you may encounter the need to convert PDF files to SVG format. In this article, we will explain how to convert PDF to SVG in Python using Spire.PDF for Python.
- Convert a PDF File to SVG in Python
- Convert a PDF File to SVG with Custom Width and Height in Python
- Convert Specific Pages of a PDF File to SVG in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
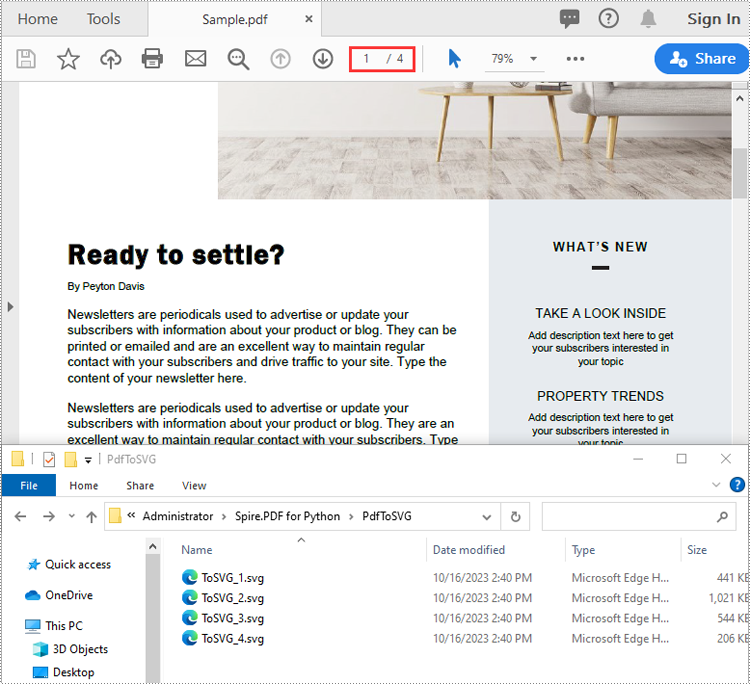
Convert a PDF File to SVG in Python
Spire.PDF for Python provides the PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method to convert each page of a PDF file to a separate SVG file. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF file using PdfDocument.LoadFromFile() method.
- Convert each page of the PDF file to SVG using PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Sample.pdf")
# Save each page of the file to a separate SVG file
doc.SaveToFile("PdfToSVG/ToSVG.svg", FileFormat.SVG)
# Close the PdfDocument object
doc.Close()
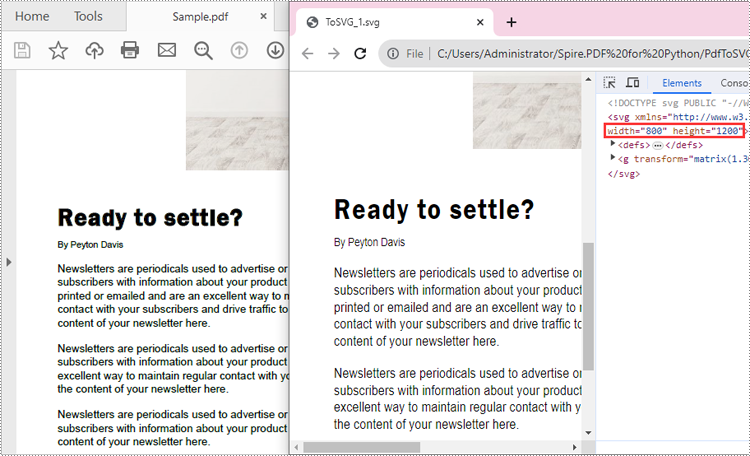
Convert a PDF File to SVG with Custom Width and Height in Python
The PdfDocument.PdfConvertOptions.SetPdfToSvgOptions(wPixel:float, hPixel:float) method provided by Spire.PDF for Python allows you to specify the width and height of the SVG files converted from PDF. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF file using PdfDocument.LoadFromFile() method.
- Specify the width and height of the output SVG files using PdfDocument.PdfConvertOptions.SetPdfToSvgOptions(wPixel:float, hPixel:float) method.
- Convert each page of the PDF file to SVG using PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Sample.pdf")
# Specify the width and height of output SVG files
doc.ConvertOptions.SetPdfToSvgOptions(800.0, 1200.0)
# Save each page of the file to a separate SVG file
doc.SaveToFile("PdfToSVGWithCustomWidthAndHeight/ToSVG.svg", FileFormat.SVG)
# Close the PdfDocument object
doc.Close()
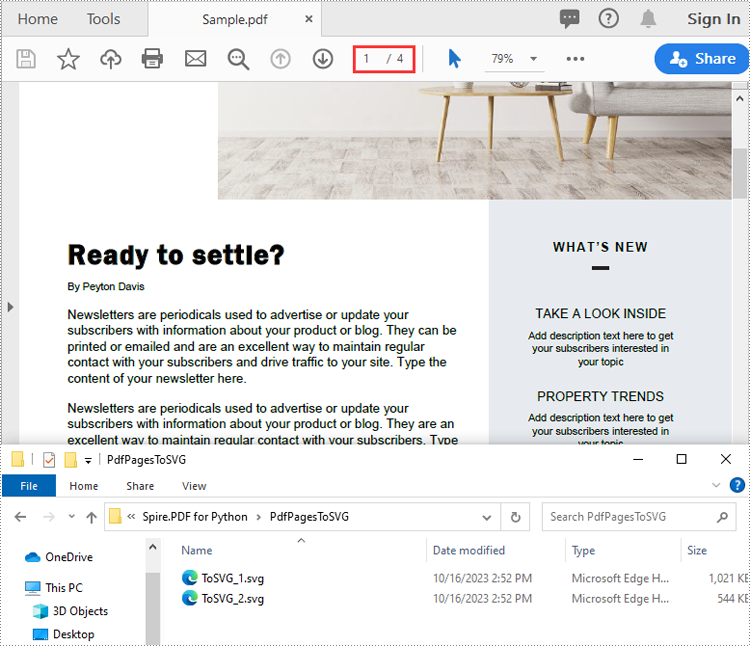
Convert Specific Pages of a PDF File to SVG in Python
The PdfDocument.SaveToFile(filename:str, startIndex:int, endIndex:int, fileFormat:FileFormat) method provided by Spire.PDF for Python allows you to convert specific pages of a PDF file to SVG files. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF file using PdfDocument.LoadFromFile() method.
- Convert specific pages of the PDF file to SVG using PdfDocument.SaveToFile(filename:str, startIndex:int, endIndex:int, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Sample.pdf")
# Save specific pages of the file to SVG files
doc.SaveToFile("PdfPagesToSVG/ToSVG.svg", 1, 2, FileFormat.SVG)
# Close the PdfDocument object
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert Images to PDF
Converting multiple images into a single PDF is a convenient and efficient way to organize and share visual content. Whether you have a collection of scanned documents, photographs, or digital images, consolidating them into a single PDF file simplifies the process of archiving, emailing, or distributing them. By merging images into a PDF format, you can preserve image quality, reduce file size, and maintain the sequence of the original images. In this article, you will learn how to convert images to PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert Multiple Images into a Single PDF Document in Python
In order to convert all the images in a folder to a PDF, we iterate through each image, add a new page to the PDF with the same size as the image, and then draw the image onto the new page. The following are the detailed steps.
- Create a PdfDocument object.
- Set the page margins to zero using PdfDocument.PageSettings.SetMargins() method.
- Get the folder where the images are stored.
- Iterate through each image file in the folder, and get the width and height of a specific image.
- Add a new page that has the same width and height as the image to the PDF document using PdfDocument.Pages.Add() method.
- Draw the image on the page using PdfPageBase.Canvas.DrawImage() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = 'C:/Users/Administrator/Desktop/Images/'
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ConvertImagesToPdf.pdf')
doc.Dispose();
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert PDF to Images (JPG, PNG, BMP)
Converting PDF to image can be beneficial in different scenarios. For example, it enables easy sharing of document content, especially on certain platforms that primarily support image formats. In addition, it helps to display previews or thumbnails of the content when publishing documents on the web. In this article, you will learn how to programmatically convert PDF to JPG/ PNG/ BMP images using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
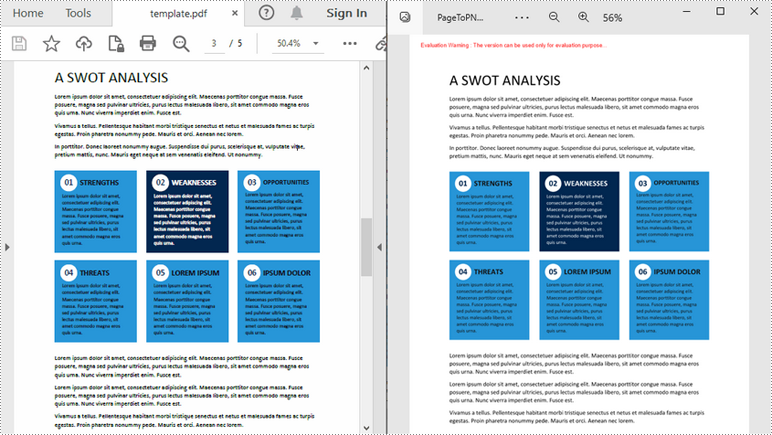
Convert a Specific PDF Page to an Image in Python
Spire.PDF for Python offers the PdfDocument.SaveAsImage(int pageIndex) method to convert a particular page into an image stream. The stream can be then saved as a JPEG, PNG, BMP or EMF image file. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Convert a specific page into an image stream using PdfDocument.SaveAsImage(int pageIndex) method.
- Save the image steam as a JPG file using Stream.Save() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("template.pdf")
# Convert a specific page to an image
with pdf.SaveAsImage(2) as imageS:
# Save the image as a JPG file
imageS.Save("PageToPNG.jpg")
pdf.Close()
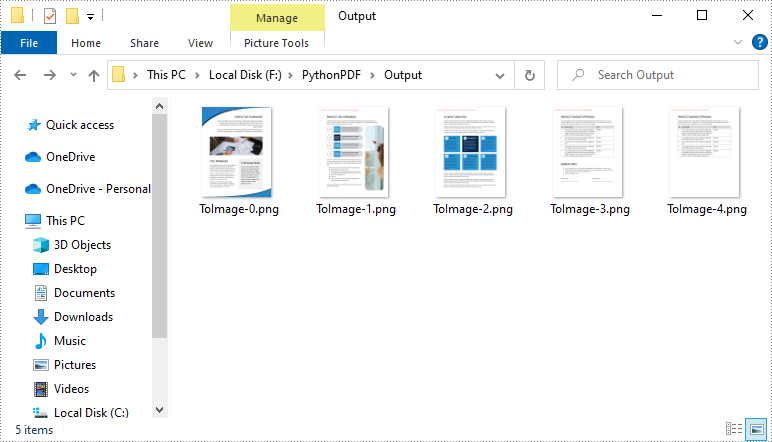
Convert an Entire PDF to Multiple Images in Python
To save each page in a PDF document as a separate image, you just need to put the conversion part inside a loop statement. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Loop through the pages in the document and convert each of them into an image stream using PdfDocument.SaveAsImage() method.
- Save the image steam as PNG files using Stream.Save() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("template.pdf")
# Iterate through all pages in the document
for i in range(pdf.Pages.Count):
# Save each page as an PNG image
fileName = "Output\\ToImage-{0:d}.png".format(i)
with pdf.SaveAsImage(i) as imageS:
imageS.Save(fileName)
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert PDF to Excel
PDF files present information in a fixed-layout format, which makes them ideal for maintaining document integrity. However, this fixed layout can pose challenges when you need to analyze or manipulate the data contained within them. By converting PDF to Excel, you can take advantage of Excel's extensive data manipulation capabilities, such as formulas, conditional formatting, pivot tables, and charts, to efficiently analyze, manipulate, visualize your data, and derive meaningful insights from it. In this article, you will learn how to convert PDF to Excel in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
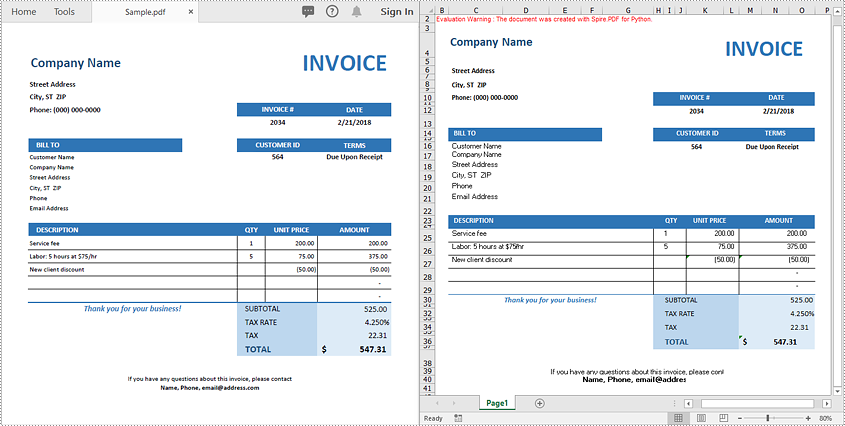
Convert PDF to Excel in Python
To convert PDF documents to Excel using Spire.PDF for Python, you can utilize the PdfDocument.SaveToFile() method. Before converting, you have the ability to specify the conversion options by creating an object of the XlsxLineLayoutOptions class and then applying the conversion options using the PdfDocument.ConvertOptions.SetPdfToXlsxOptions() method. The XlsxLineLayoutOptions class constructor accepts the following five parameters, which allow you to control how your PDF will be converted to Excel:
- convertToMultipleSheet (bool): Specifies whether to convert each page to a different worksheet in the same Excel. If set to False, only the first page will be converted.
- rotatedText (bool): Specifies whether to display rotated text.
- splitCell (bool): Specifies whether to convert text in a PDF cell (spanning more than two lines) to one Excel cell or to multiple cells.
- wrapText (bool): Specifies whether to wrap text in an Excel cell.
- overlapText (bool): Specifies whether to display overlapping text.
The following steps explain how to convert a PDF document to Excel XLSX format with specific conversion options using Spire.PDF for Python:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Create an XlsxLineLayoutOptions object and pass the corresponding parameters to the constructor of the XlsxLineLayoutOptions class to specify the conversion options.
- Apply the conversion options using PdfDocument.ConvertOptions.SetPdfToXlsxOptions() method.
- Save the PDF document to Excel XLSX format using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Sample.pdf")
# Create an XlsxLineLayoutOptions object to specify the conversion options
# Parameters: convertToMultipleSheet, rotatedText, splitCell, wrapText, overlapText
convertOptions = XlsxLineLayoutOptions(True, True, False, True, False)
# Set the conversion options
pdf.ConvertOptions.SetPdfToXlsxOptions(convertOptions)
# Save the PDF document to Excel XLSX format
pdf.SaveToFile("PdfToExcel.xlsx", FileFormat.XLSX)
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.