
Converting a PDF to grayscale reduces file size by removing unnecessary color data, turning the content into shades of gray. This is especially useful for documents where color isn’t critical, such as text-heavy reports or forms, resulting in more efficient storage and faster transmission. On the other hand, linearization optimizes the PDF’s internal structure for web use. It enables users to start viewing the first page while the rest of the file is still loading, providing a faster and smoother experience, particularly for online viewing. In this article, we will demonstrate how to convert PDF files to grayscale or linearized PDFs in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to Grayscale in Python
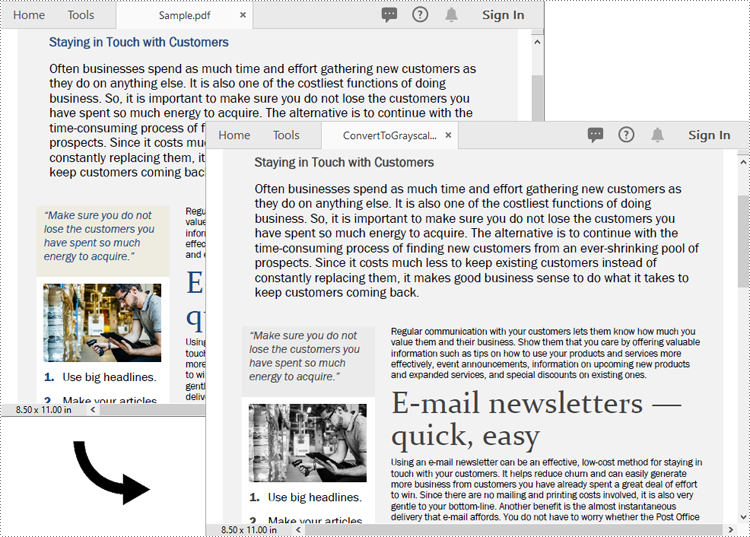
Converting a PDF document to grayscale can be achieved by using the PdfGrayConverter.ToGrayPdf() method. The detailed steps are as follows.
- Load a PDF document using the PdfGrayConverter class.
- Convert the PDF document to grayscale using the PdfGrayConverter.ToGrayPdf() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output PDF file paths inputFile = "Sample.pdf" outputFile = "Output/ConvertToGrayscale.pdf" # Load a PDF document using the PdfGrayConverter class converter = PdfGrayConverter(inputFile) # Convert the PDF document to grayscale converter.ToGrayPdf(outputFile)
Convert PDF to Linearized in Python
To convert a PDF to linearized, you can use the PdfToLinearizedPdfConverter.ToLinearizedPdf() method. The detailed steps are as follows.
- Load a PDF document using the PdfToLinearizedPdfConverter class.
- Convert the PDF document to linearized using the PdfToLinearizedPdfConverter.ToLinearizedPdf() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output PDF file paths inputFile = "Sample.pdf" outputFile = "Output/ConvertToLinearizedPdf.pdf" # Load a PDF document using the PdfToLinearizedPdfConverter class converter = PdfToLinearizedPdfConverter(inputFile) # Convert the PDF document to a linearized PDF converter.ToLinearizedPdf(outputFile)
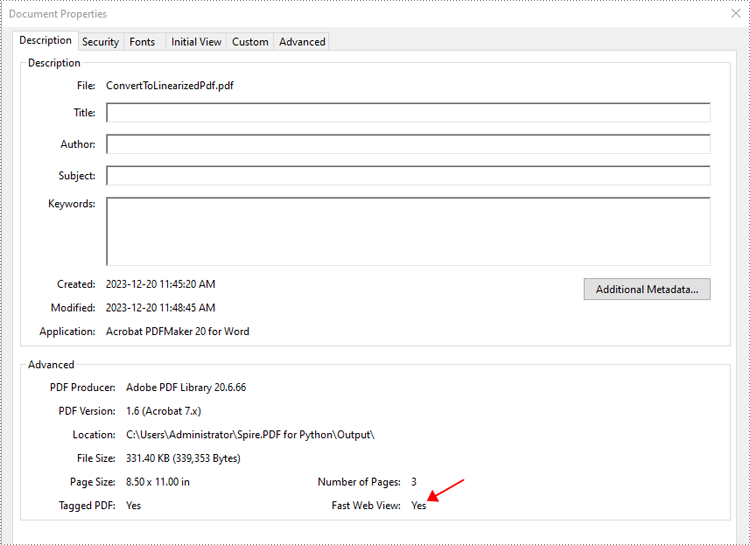
Open the result file in Adobe Acrobat and check the document properties. You will see that the value for "Fast Web View" is set to "Yes", indicating that the file has been linearized.
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

