
MS Word allows users to view hyperlinks but lacks a built-in feature for extracting hyperlinks with a single click. This limitation makes extracting multiple links from a document time-consuming. Thankfully, Python can streamline this process significantly. In this article, we'll show you how to use Spire.Doc for Python to easily extract hyperlinks from Word documents with Python, either individual or batch, saving you time and effort.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows.
Extract Hyperlinks from Word Documents: Specified Links
Whether you're looking to retrieve just one important link or filter out certain URLs, this section will guide you through the process step by step. Using the Filed.FiledText and the Filed.Code properties provided by Spire.Doc, you can efficiently target and extract specified hyperlinks, making it easier to access the information you need.
Steps to extract specified hyperlinks from Word documents:
- Create an instance of Document class.
- Read a Word document from files using Document.LoadFromFile() method.
- Iterate through elements to find all hyperlinks in this Word document.
- Get a certain hyperlink from the hyperlink collection.
- Retrieve the hyperlink text with Field.FieldText property.
- Extract URLs from the hyperlink in the Word document using Field.Code property.
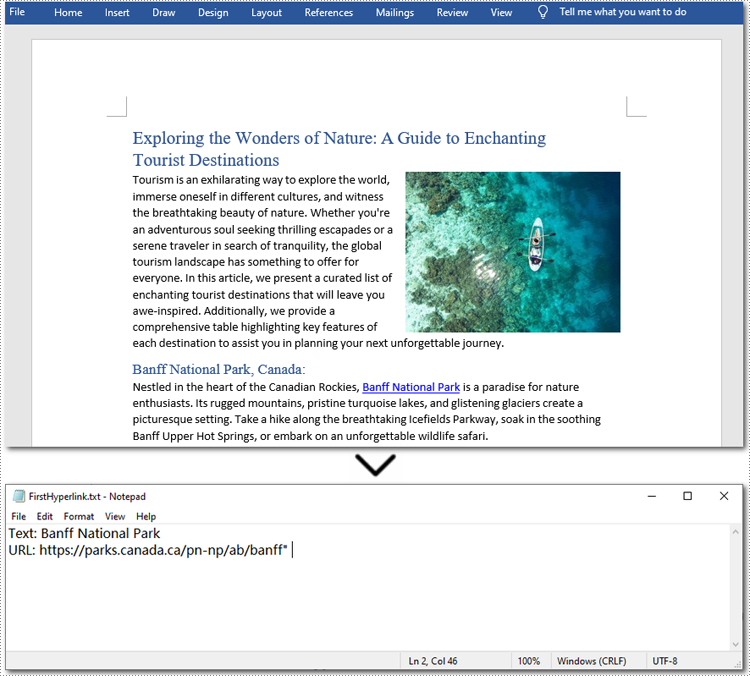
Here is the code example of extracting the first hyperlink in a Word document:
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("/sample.docx")
# Find all hyperlinks in the Word document
hyperlinks = []
for i in range(doc.Sections.Count):
section = doc.Sections.get_Item(i)
for j in range(section.Body.ChildObjects.Count):
sec = section.Body.ChildObjects.get_Item(j)
if sec.DocumentObjectType == DocumentObjectType.Paragraph:
for k in range((sec if isinstance(sec, Paragraph) else None).ChildObjects.Count):
para = (sec if isinstance(sec, Paragraph) else None).ChildObjects.get_Item(k)
if para.DocumentObjectType == DocumentObjectType.Field:
field = para if isinstance(para, Field) else None
if field.Type == FieldType.FieldHyperlink:
hyperlinks.append(field)
# Get the first hyperlink text and URL
if hyperlinks:
first_hyperlink = hyperlinks[0]
hyperlink_text = first_hyperlink.FieldText
hyperlink_url = first_hyperlink.Code.split('HYPERLINK ')[1].strip('"')
# Save to a text file
with open("/FirstHyperlink.txt", "w") as file:
file.write(f"Text: {hyperlink_text}\nURL: {hyperlink_url}\n")
# Close the document
doc.Close()
Extract All Hyperlinks from Word Documents
After checking out how to extract specified hyperlinks, let's move on to extracting all hyperlinks from your Word documents. This is especially helpful when you need a list of all links, whether to check for broken ones or for other purposes. By automating this process with Spire.Doc(short for Spire Doc for Python), you can save time and ensure accuracy. Let's take a closer look at the steps and code example. Steps to extract all hyperlinks from Word documents:
- Create a Document object.
- Load a Word document from the local storage with Document.LoadFromFile() method.
- Loop through elements to find all hyperlinks in the Word document.
- Iterate through all hyperlinks in the collection.
- Use Field.FieldText property to extract the hyperlink text from each link.
- Use Field.Code property to get URLs from hyperlinks.
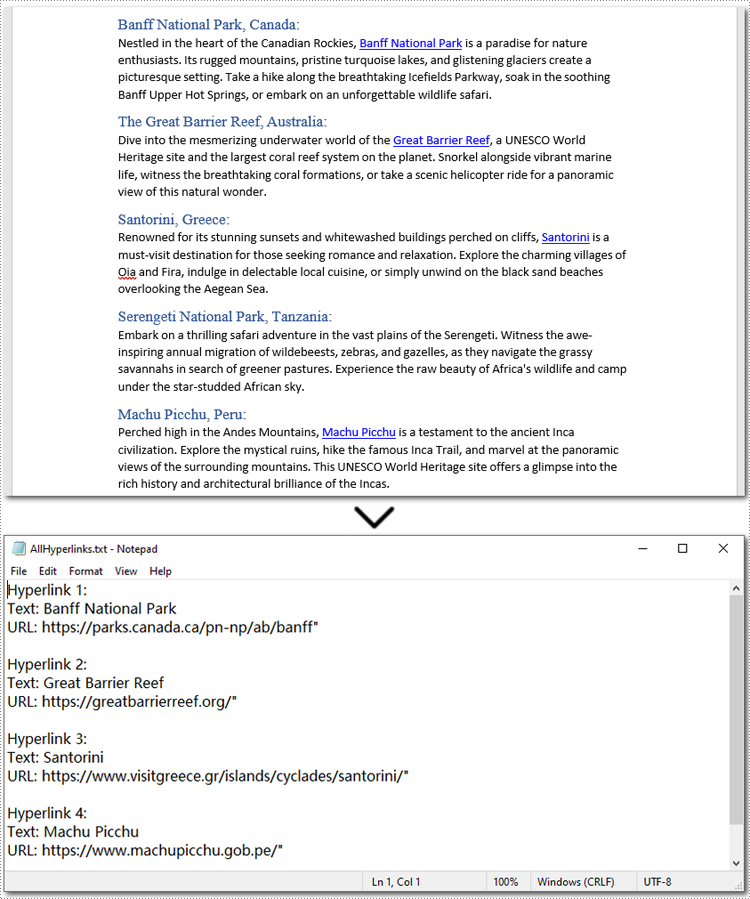
Below is a code example of extracting all hyperlinks from a Word document:
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("/sample.docx")
# Find all hyperlinks in the Word document
hyperlinks = []
for i in range(doc.Sections.Count):
section = doc.Sections.get_Item(i)
for j in range(section.Body.ChildObjects.Count):
sec = section.Body.ChildObjects.get_Item(j)
if sec.DocumentObjectType == DocumentObjectType.Paragraph:
for k in range((sec if isinstance(sec, Paragraph) else None).ChildObjects.Count):
para = (sec if isinstance(sec, Paragraph) else None).ChildObjects.get_Item(k)
if para.DocumentObjectType == DocumentObjectType.Field:
field = para if isinstance(para, Field) else None
if field.Type == FieldType.FieldHyperlink:
hyperlinks.append(field)
# Save all hyperlinks text and URL to a text file
with open("/AllHyperlinks.txt", "w") as file:
for i, hyperlink in enumerate(hyperlinks):
hyperlink_text = hyperlink.FieldText
hyperlink_url = hyperlink.Code.split('HYPERLINK ')[1].strip('"')
file.write(f"Hyperlink {i+1}:\nText: {hyperlink_text}\nURL: {hyperlink_url}\n\n")
# Close the document
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

