Python: Edit or Modify a Word Document
Programmatic editing of Word documents involves using code to alter or modify the contents of these documents. This approach enables automation and customization, making it particularly advantageous for handling large document collections. Through the use of Spire.Doc library, developers can perform a wide range of operations, including text manipulation, formatting changes, and the addition of images or tables.
The following sections will demonstrate how to edit or modify a Word document in Python using Spire.Doc for Python.
- Modify Text in a Word Document
- Change Formatting of Text in a Word Document
- Add New Elements to a Word Document
- Remove Paragraphs from a Word Document
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
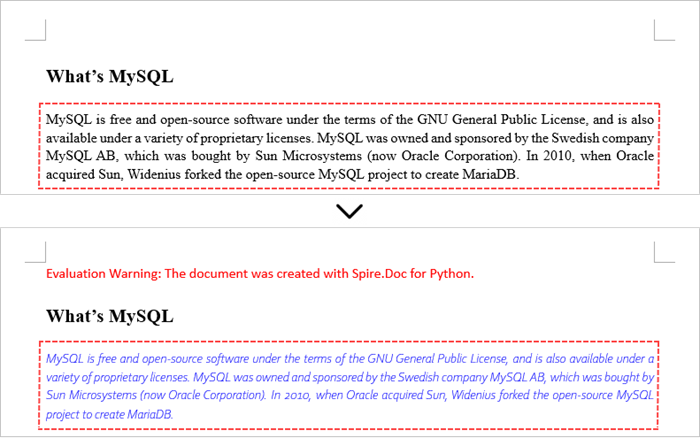
Modify Text in a Word Document in Python
In order to alter the content of a paragraph, the initial step is to obtain the desired paragraph from a specific section through the use of the Section.Paragraphs[index] property. Following this, you can replace the existing text with the new content by assigning it to the Paragraph.Text property of the chosen paragraph.
Here are the steps to edit text in a Word document with Python:
- Create a Document object.
- Load a Word file from the given file path.
- Get a specific section using Document.Sections[index] property.
- Get a specific paragraph using Section.Paragraphs[index] property.
- Reset the text of the paragraph using Paragraph.Text property.
- Save the updated document to a different Word file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load an existing Word file
document.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx");
# Get a specific section
section = document.Sections[0]
# Get a specific paragraph
paragraph = section.Paragraphs[0]
# Modify the text of the paragraph
paragraph.Text = "The text has been modified"
# Save the document to a different Word file
document.SaveToFile("output/ModifyText.docx", FileFormat.Docx)
# Dispose resource
document.Dispose()

Change Formatting of Text in a Word Document in Python
To alter the text appearance of a particular paragraph, you first need to obtain the specified paragraph. Next, go through its child objects to find the individual text ranges. The formatting of each text range can then be updated using the TextRange.CharacterFormat property.
The steps to change text formatting in a Word document are as follows:
- Create a Document object.
- Load a Word file from the given file path.
- Get a specific section using Document.Sections[index] property.
- Get a specific paragraph using Section.Paragraphs[index] property.
- Iterate through the child objects in the paragraph.
- Determine if a child object is a text range.
- Get a specific text range.
- Reset the text formatting using TextRange.CharacterFormat property.
- Save the updated document to a different Word file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get a specific section
section = doc.Sections[0]
# Get a specific paragraph
paragraph = section.Paragraphs[1];
# Iterate through the child objects in the paragraph
for i in range(paragraph.ChildObjects.Count):
# Determine if a child object is text range
if isinstance(paragraph.ChildObjects[i], TextRange):
# Get a specific text range
textRange = paragraph.ChildObjects[i]
# Reset font name
textRange.CharacterFormat.FontName = "Corbel Light"
# Reset font size
textRange.CharacterFormat.FontSize = 11.0
# Reset text color
textRange.CharacterFormat.TextColor = Color.get_Blue()
# Apply italic to the text range
textRange.CharacterFormat.Italic = True
# Save the document to a different Word file
doc.SaveToFile("output/ChangeFormatting.docx", FileFormat.Docx2019)
# Dispose resource
doc.Dispose()
Add New Elements to a Word Document in Python
In a Word document, most elements—such as text, images, lists, and charts—are fundamentally organized around the concept of a paragraph. To insert a new paragraph into a specific section, use the Section.AddParagraph() method.
After creating the new paragraph, you can add various elements to it by leveraging the methods and properties of the Paragraph object.
The steps to add new elements (text and images) to a Word document are as follows:
- Create a Document object.
- Load a Word file from the given file path.
- Get a specific section through Document.Sections[index] property.
- Add a paragraph to the section using Section.AddParagraph() method.
- Add text to the paragraph using Paragraph.AppendText() method.
- Add an image to the paragraph using Paragraph.AppendPicture() method.
- Save the updated document to a different Word file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.docx")
# Get the last section
lastSection = doc.LastSection
# Add a paragraph to the section
paragraph = lastSection.AddParagraph()
# Add an image to the paragraph
picture = paragraph.AppendPicture("C:\\Users\\Administrator\\Desktop\\logo.png");
# Set text wrap style
picture.TextWrappingStyle = TextWrappingStyle.TopAndBottom
# Add text to the paragraph
paragraph.AppendText("This text and the image above are added by Spire.Doc for Python.")
# Create a paragraph style
style = ParagraphStyle(doc)
style.Name = "FontStyle"
style.CharacterFormat.FontName = "Times New Roman"
style.CharacterFormat.FontSize = 12
doc.Styles.Add(style)
# Apply the style to the paragraph
paragraph.ApplyStyle(style.Name)
# Save the document to a different Word file
doc.SaveToFile("output/AddNewElements.docx", FileFormat.Docx2019)
# Dispose resource
doc.Dispose()

Remove Paragraphs from a Word Document in Python
To eliminate a specific paragraph from a document, simply invoke the ParagraphCollection.RemoveAt() method and supply the index of the paragraph you intend to delete.
The steps to remove paragraphs from a Word document are as follows:
- Create a Document object.
- Load a Word file from the given file path.
- Get a specific section through Document.Sections[index] property.
- Remove a specific paragraph from the section using Section.Paragraphs.RemoveAt() method.
- Save the updated document to a different Word file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get a specific section
section = doc.Sections[0]
# Remove a specific paragraph
section.Paragraphs.RemoveAt(0)
# Save the document to a different Word file
doc.SaveToFile("output/RemoveParagraph.docx", FileFormat.Docx);
# Dispose resource
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.XLS for JavaScript is Now Available
In a significant stride towards enhancing the capabilities of web developers, Spire.XLS for JavaScript, a powerful Excel development library, has been released. This cutting-edge solution empowers developers to seamlessly integrate Excel functionalities into their JavaScript applications, simplifying the way data is managed and manipulated within web environments.
Spire.XLS for JavaScript
Spire.XLS for JavaScript is designed to streamline Excel programming tasks, enabling developers to create, read, modify, and convert Excel files directly within their JavaScript environment. As a robust JavaScript Excel API, it allows seamless compatibility with popular frameworks such as Vue, React, Angular, and plain JavaScript.
Contact Us
- Sales: sales@e-iceblue.com
- Technical Support: support@e-iceblue.com
- Skype ID: iceblue.support
Python: Remove Forms from a PDF Document
Interactive forms in PDFs are valuable tools that allow users to fill in information, complete surveys, or sign documents electronically. However, these forms can also add layers of complexity to a PDF, impacting both file size and the overall user experience. When forms are no longer needed, or when a document needs to be simplified for distribution or archiving, removing these interactive elements can be beneficial. In this article, we will demonstrate how to remove forms from a PDF document in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
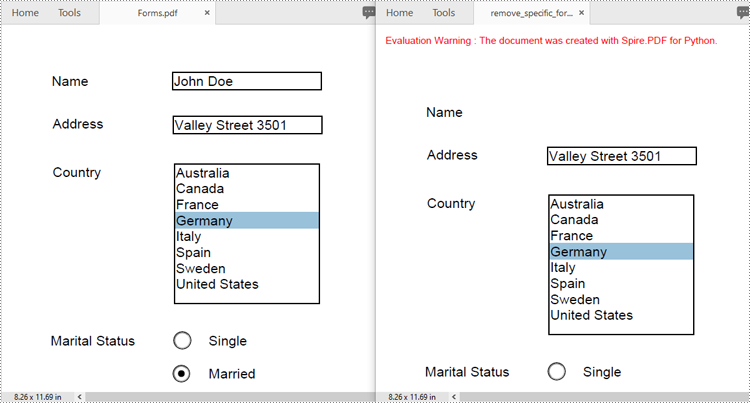
Remove a Specific Form from a PDF Document in Python
Spire.PDF for Python allows you to remove specific form fields from a PDF file by using either the indexes or the names of the form fields. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document containing form fields using the PdfDocument.LoadFromFile() method.
- Get the form of the document using the PdfDocument.Form property.
- Get the form field collection using the PdfFormWidget.FieldsWidget property.
- Remove a specific form field by its index using the PdfFormFieldWidgetCollection.RemoveAt(index) method. Or retrieve a form field by its name using the PdfFormFieldWidgetCollection[name] property, and then remove it using the PdfFormFieldWidgetCollection.Remove(field) method.
- Save the resulting document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an instance of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Forms.pdf")
# Get the form of the document
pdfForm = doc.Form
formWidget = PdfFormWidget(pdfForm)
# Get the form field collection
field_collection = formWidget.FieldsWidget
# Remove a specific form field by its index
field_collection.RemoveAt(0)
# Or remove a specific form field by its name
# text_box = field_collection["Name"]
# field_collection.Remove(text_box)
# Save the resulting document
doc.SaveToFile("remove_specific_form.pdf")
doc.Close()
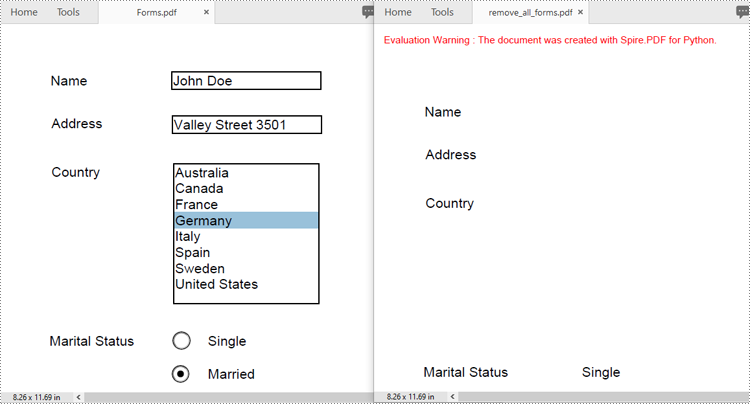
Remove All Forms from a PDF Document in Python
To remove all form fields from a PDF document, you need to iterate through the form field collection, and then remove each form field from the collection using the PdfFormFieldWidgetCollection.RemoveAt(index) method. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document containing form fields using the PdfDocument.LoadFromFile() method.
- Get the form of the document using the PdfDocument.Form property.
- Get the form field collection using the PdfFormWidget.FieldsWidget property.
- Iterate through all form fields in the collection.
- Remove each form field from the collection using the PdfFormFieldWidgetCollection.RemoveAt(index) method.
- Save the resulting document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an instance of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Forms.pdf")
# Get the form of the document
pdfForm = doc.Form
formWidget = PdfFormWidget(pdfForm)
# Get the form field collection
field_collection = formWidget.FieldsWidget
# Check if there are any form fields in the collection
if field_collection.Count > 0:
# Iterate through all form fields in the collection
for i in range(field_collection.Count - 1, -1, -1):
# Remove the current form field from the collection
field_collection.RemoveAt(i)
# Save the resulting document
doc.SaveToFile("remove_all_forms.pdf")
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Office 9.8.0 is released
We are excited to announce the release of Spire.Office 9.8.0. In this version, Spire.PDF supports converting HTML to PDF using the Chrome; Spire.XLS supports enabling revision mode and obtaining custom properties of worksheets; Spire.Presentation supports converting PowerPoint documents to Markdown files; Spire.OCR supports configuring OCR models, languages, and dependency libraries. Besides, a lot of known issues are fixed successfully in this version. More details are listed below.
In this version, the most recent versions of Spire.Doc, Spire.PDF, Spire.XLS, Spire.Presentation, Spire.Email, Spire.DocViewer, Spire.PDFViewer, Spire.Spreadsheet, Spire.OfficeViewer, Spire.DataExport, and Spire.Barcode are included.
DLL Versions:
- Spire.Doc.dll v12.8.12
- Spire.Pdf.dll v10.8.1
- Spire.XLS.dll v14.8.2
- Spire.Presentation.dll v9.8.3
- Spire.Barcode.dll v7.3.3
- Spire.Email.dll v6.6.0
- Spire.DocViewer.Forms.dll v8.8.1
- Spire.PdfViewer.Asp.dll v7.12.23
- Spire.PdfViewer.Forms.dll v7.12.23
- Spire.Spreadsheet.dll v7.5.2
- Spire.OfficeViewer.Forms.dll v8.7.15
- Spire.DataExport.dll 4.9.0
- Spire.DataExport.ResourceMgr.dll v2.1.0
Here is a list of changes made in this release
Spire.Doc
| Category | ID | Description |
| Bug | SPIREDOC-10644 | Fixes the issue that the image data was failed to be filled during mail merge. |
| Bug | SPIREDOC-10219 | Fixes the issue that extra blank pages are generated when converting Word to OFD. |
| Bug | SPIREDOC-10365 | Fixes the issue that the VBA was lost after saving Docm. |
| Bug | SPIREDOC-10389 | Fixes the issue that the application threw the exception "Wrong Word version" when loading Word documents encrypted using the WPS tool. |
| Bug | SPIREDOC-10425 | Fixes the issue that the application threw the exception 'System. ArgumentNullException' when converting Word to PDF. |
| Bug | SPIREDOC-10456 | Fixes the issue that the borderless text boxes added using the WPS tool were not successfully parsed. |
| Bug | SPIREDOC-10554 | Fixes the issue that the images didn't display when adding HTML that contains the image paths starting with https. |
| Bug | SPIREDOC-10587 | Fixes the issue that the application threw the exception "Unknown boolean value" when converting Word to PDF. |
| Bug | SPIREDOC-10738 | Fixes the issue that the customXml appeared after replacing text. |
| Bug | SPIREDOC-10743 | Optimizes the file size for converting Word to OFD. |
Spire.XLS
| Category | ID | Description |
| New feature | SPIREXLS-5274 | Supports obtaining custom properties of worksheets.
Workbook workbook = new Workbook ();
workbook.LoadFromFile("funds-test.xlsx");
ICustomPropertiesCollection customProperties = workbook.Worksheets[0].CustomProperties;
for (int i = 0; i < customProperties.Count; i++)
{
XlsCustomProperty xcp = customProperties[i];
string name = xcp.Name;
string value = xcp.Value;
}
|
| New feature | SPIREXLS-5306 | Supports obtaining the original document name of the embedded OLE object.
ole.OleOriginName |
| New feature | SPIREXLS-5254 | Supports enabling revision mode.
Workbook.TrackedChanges=true;//default value is false |
| New feature | SPIREXLS-5348 | Supports setting global custom font folders.
Workbook.SetGlobalCustomFontsFolders(string[] fontPath); |
| Bug | SPIREXLS-5271 | Fixes the issue that the cell data was inaccurate when converting Excel to images. |
| Bug | SPIREXLS-5298 | Fixes the issue that the cell contents were lost when converting Excel to PDF. |
| Bug | SPIREXLS-5304 | Fixes the issue that the row height was incorrect when converting Excel to PDF. |
| Bug | SPIREXLS-5309 | Fixes the issue that the pagination was incorrect when converting Excel to PDF. |
| Bug | SPIREXLS-5320 | Fixes the issue that the first 10 data entries were incorrect after adding a "FilterTop10" filter in a worksheet. |
| Bug | SPIREXLS-5196 | Fixes the issue that the checkbox was not converted to image format when converting Excel to PDF. |
| Bug | SPIREXLS-5305 | Fixes the issue that multiple calls to the ApplyStyleToRange method in pivot tables result in incorrect results. |
| Bug | SPIREXLS-5308 | Fixes the issue that setting the color transparency of rich text did not take effect. |
| Bug | SPIREXLS-5317 | Fixes the issue that the Filter formula is calculated incorrectly. |
| Bug | SPIREXLS-5330 | Fixes the issue that pivot table column names are incorrect when converting Excel to images. |
| Bug | SPIREXLS-5345 | Fixes the issue that the text location is incorrect when converting Excel to PDF. |
| Bug | SPIREXLS-5349 | Fixes the issue that ChartSheet retrieval is incorrect. |
| Bug | SPIREXLS-5352 | Fixes the issue that cell content is incorrect when converting Excel to HTML or images. |
Spire.PDF
| Category | ID | Description |
| New feature | SPIREPDF-5742 | Adds the PreserveAllowedMetadata property to support preserving XMP data when converting PDF to PDFA format documents.
PdfStandardsConverter converter = new PdfStandardsConverter(stream); converter.Options.PreserveAllowedMetadata = true; |
| New feature | - | Supports converting HTML to PDF using the Chrome plugin. Save the resulting PDF document to a file: string chromeLocation = baseDirectory + "chrome\\Chrome-bin\\chrome.exe";
ChromeHtmlConverter converter = new ChromeHtmlConverter(chromeLocation);
ConvertOptions options = new ConvertOptions();
options.Timeout = 10 * 1000;
options.PageSettings = new PageSettings()
{
PaperWidth = 8.77,
PaperHeight = 6.20,
MarginBottom = 0,
MarginTop = 0,
MarginLeft = 0,
MarginRight = 0
};
converter.ConvertToPdf("https://www.e-iceblue.com/", outputFile, options);
var pdfAsStream = new MemoryStream();
string chromeLocation = baseDirectory + "chrome\\Chrome-bin\\chrome.exe";
ChromeHtmlConverter converter = new ChromeHtmlConverter(chromeLocation);
ConvertOptions options = new ConvertOptions();
options.Timeout = 10 * 1000;
options.PageSettings = new PageSettings()
{
PaperWidth = 8.77,
PaperHeight = 6.2,
MarginBottom = 0,
MarginTop = 0,
MarginLeft = 0,
MarginRight = 0
};
converter.ConvertToPdf("https://www.e-iceblue.com/", pdfAsStream, options);
|
| New feature | SPIREPDF-6820 | Optimizes the layout of Excel documents converted from PDF documents. Use the new code: pdfDocument.ConvertOptions.SetPdfToXlsxOptions(new XlsxLineLayoutOptions(true, false, false)); //bool convertToMultipleSheet, bool rotatedText, bool splitCell |
| Optimization | SPIREPDF-5744 | Optimizes the time consumption of PDF to image conversion. |
| Bug | SPIREPDF-6789 | Fixes the issue that the program reported an error when printing PDF documents. |
| Bug | SPIREPDF-6806 | Fixes the issue that images in PDF documents converted from XPS documents were not displayed in the PDF.js viewer. |
| Bug | SPIREPDF-6848 | Fixes the issue that the border was lost after filling the text field with content and opening the document in Google Chrome or previewing it in Adobe when printing. |
| Bug | SPIREPDF-6896 | Fixes the issue that the program threw System.NullReferenceException when converting a PDF document to a PDFA1B document. |
| Bug | SPIREPDF-6898 SPIREPDF-6899 |
Fixes the issue that the program threw System.NullReferenceException when extracting text from PDF documents. |
| Bug | SPIREPDF-6906 | Fixes the issue that the program threw System.ArgumentNullException when converting PDF documents to images. |
| Bug | SPIREPDF-6832 | Fixes the issue that verification of signature validity was inaccurate. |
| Bug | SPIREPDF-6836 | Fixes the issue that removing the PdfWatermarkAnnotationWidget object failed. |
| Bug | SPIREPDF-6875 | Fixes the issue that printing PDF to B5 paper size was incorrect. |
| Bug | SPIREPDF-2659 SPIREPDF-4454 |
Fixes the issue that importing and exporting form data (in FDF, XFDF, and XML formats) was incorrect. |
| Bug | SPIREPDF-6797 | Fixes the issue that highlighting covered the text after converting PDF to images. |
| Bug | SPIREPDF-6896 | Fixes the issue that the program threw an exception System.NullReferenceException when converting an OFD document to a PDF document. |
| Bug | SPIREPDF-6908 | Fixes the issue that the contents were blank after converting a PDF document to images. |
| Bug | SPIREPDF-6910 | Fixes the issue that it failed to get the action script of annotations. |
| Bug | SPIREPDF-6922 | Fixes the issue that the program threw an exception System.ArgumentException when importing FDF file data to PDF. |
| Bug | SPIREPDF-6925 | Fixes the issue that spaces were lost when copying content to Notepad after adding content to a PDF document using the PdfTaggedContent interface. |
| Bug | SPIREPDF-6929 SPIREPDF-6940 |
Fixes the issue that the program threw an exception System.OutOfMemoryException when converting a PDF document to images. |
| Bug | SPIREPDF-6941 | Fixes the issue that signatures were reversed by mirroring after flattening form fields. |
| Bug | SPIREPDF-6949 | Fixes the issue that the program threw an exception System.NullReferenceException when converting a PDF document to an Excel document. |
| Bug | SPIREPDF-6968 | Fixes the issue that the program threw an exception System.NullReferenceException when loading a PDF document. |
Spire.Presentation
| Category | ID | Description |
| New feature | - | Supports converting PowerPoint documents to Markdown files.
Presentation ppt = new Presentation();
ppt.LoadFromFile("1.pptx");
ppt.SaveToFile("1.md", FileFormat.Markdown);
ppt.Dispose();
|
| Bug | SPIREPPT-2522 | Fixes the issue that the waterfall chart is displayed incorrectly after modifying its data. |
| Bug | SPIREPPT-2534 | Fixes the issue that the program threw System.ArgumentException when setting document property "_MarkAsFinal". |
| Bug | SPIREPPT-2535 | Fixes the issue that the tilt angle of text was lost after converting slides to pictures. |
| Bug | SPIREPPT-2547 | Fixes the issue that the application threw the exception "System.ArgumentOutOfRangeException" when copying slides to a new PowerPoint presentation. |
| Bug | SPIREPPT-2549 | Fixes the issue that the message "PowerPoint found a problem with content" prompted when opening the resulting file generated after copying slides to a new PowerPoint presentation. |
Spire.OCR
| Category | ID | Description |
| New feature | - | Adds the ConfigureOptions class and new method ConfigureDependencies(ConfigureOptions configureOptions), which supports configuring OCR models, languages, and dependency libraries.
OcrScanner scanner = new OcrScanner();
// Create a new instance of the ConfigureOptions class to set up the scanner configuration
ConfigureOptions configureOptions = new ConfigureOptions();
// Set the path to the model
configureOptions.ModelPath = @"D:\Model&Lib\Model\V4.Server";
// Set the path to the dependency libraries
configureOptions.LibPath = @"D:\Model&Lib\Lib\V2.7\Net\X64";
// Specify the language
configureOptions.Language = "Chinese";
// Apply the configuration options to the scanner using the ConfigureDependencies method
scanner.ConfigureDependencies(configureOptions);
scanner.Scan("test.tif");
|
Spire.OfficeViewer
| Category | ID | Description |
| Bug | SPIREPPT-2502 | Fixes the issue that the warning watermark of presentations cannot be removed after applying a valid license. |
Spire.Presentation for Java 9.8.3 support setting format when replacing text
We are pleased to announce the release of Spire.Presentation for Java 9.8.3. This version provides a new method to set format when replacing text, and also fixes some known issues occurred when loading PowerPoint files, adding formulas in table cells, and adding LatexMath. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPPT-2579 | Provides the ReplaceAndFormatText(String matchedString, String newValue, PortionFormatEx format) method to support setting format when replacing text.
Presentation ppt = new Presentation();
// Load a PowerPoint presentation from the specified file.
ppt.loadFromFile(inputFile);
// Create a new object to store the default text range formatting properties.
PortionFormatEx format = new PortionFormatEx();
// Set the IsBold property of the text range formatting to true, making the text bold.
format.isBold(TriState.TRUE);
// Set the FillType property of the text range fill to Solid, indicating a solid fill color.
format.getFill().setFillType(FillFormatType.SOLID);
// Set the Color property of the solid fill color to red.
format.getFill().getSolidColor().setColor(Color.red);
// Set the FontHeight property of the text range formatting to 25, indicating the font size.
format.setFontHeight(25);
format.isBold(TriState.TRUE);
// Replace all occurrences of the text "Spire.Presentation for .NET" with "Spire.PPT" and apply the specified formatting.
ppt.ReplaceAndFormatText("Spire.Presentation for .NET", "Spire.PPT", format);
// Save the modified presentation to the specified output file in the PPTX format compatible with PowerPoint 2016.
ppt.saveToFile(outputFile, FileFormat.PPTX_2016);
// Dispose of the Presentation object to free up resources
ppt.dispose();
|
| Bug | SPIREPPT-2544 | Fixes the issue that the content did not fit automatically after changing the page orientation. |
| Bug | SPIREPPT-2562 | Fixes the issue that the formulas were incorrect when adding LatexMath. |
| Bug | SPIREPPT-2577 | Fixes the issue where Chinese characters in formula were displayed as "x". |
| Bug | SPIREPPT-2589 | Fixes the issue that the application threw the exception "java.lang.ClassCastException" when adding formulas in table cells. |
| Bug | SPIREPPT-2593 | Fixes the issue that the application threw the exception "OutOfMemory" when loading PowerPoint files. |
Java: Convert HTML to Excel
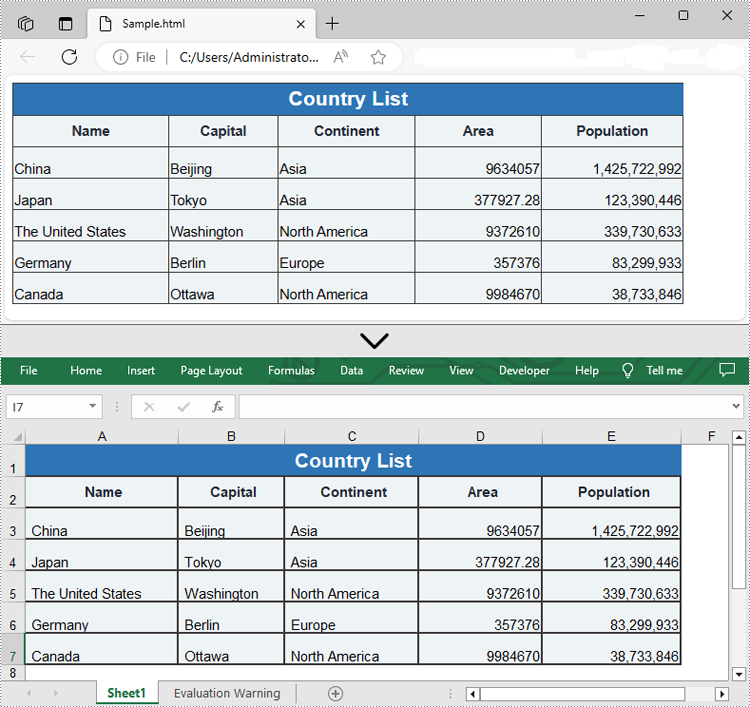
HTML files often contain valuable datasets embedded within tables. However, analyzing this data directly in HTML can be cumbersome and inefficient. Converting HTML tables to Excel format allows you to take advantage of Excel's powerful data manipulation and analysis tools, making it easier to sort, filter, and visualize the information. Whether you need to analyze data for a report, perform calculations, or simply organize it in a more user-friendly format, converting HTML to Excel streamlines the process. In this article, we will demonstrate how to convert HTML files to Excel format in Java using Spire.XLS for Java.
Install Spire.XLS for Java
First of all, you're required to add the Spire.Xls.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>14.11.0</version>
</dependency>
</dependencies>
Convert HTML to Excel in Java
Spire.XLS for Java provides the Workbook.loadFromHtml() method for loading an HTML file. Once the HTML file is loaded, you can convert it to Excel format using the Workbook.saveToFile() method. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an HTML file using the Workbook.loadFromHtml() method.
- Save the HTML file in Excel format using the Workbook.saveToFile() method.
- Java
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
public class ConvertHtmlToExcel {
public static void main(String[] args) {
// Specify the input HTML file path
String filePath = "C:\\Users\\Administrator\\Desktop\\Sample.html";
// Create an object of the workbook class
Workbook workbook = new Workbook();
// Load the HTML file
workbook.loadFromHtml(filePath);
// Save the HTML file in Excel XLSX format
String result = "C:\\Users\\Administrator\\Desktop\\ToExcel.xlsx";
workbook.saveToFile(result, ExcelVersion.Version2013);
workbook.dispose();
}
}
Insert HTML String into Excel in Java
In addition to converting HTML files to Excel, Spire.XLS for Java allows you to insert HTML strings directly into Excel cells using the CellRange.setHtmlString() method. The detailed steps are as follows.
- Create an object of the Workbook class.
- Get a specific worksheet by its index (0-based) using the Workbook.getWorksheets().get(index) method.
- Get the cell that you want to add an HTML string to using the Worksheet.getCellRange() method.
- Add an HTML sting to the cell using the CellRange.setHtmlString() method.
- Save the resulting workbook to a new file using the Workbook.saveToFile() method.
- Java
import com.spire.xls.CellRange;
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class InsertHtmlStringInExcelCell {
public static void main(String[] args) {
// Create an object of the workbook class
Workbook workbook = new Workbook();
// Get the first sheet
Worksheet sheet = workbook.getWorksheets().get(0);
// Specify the HTML string
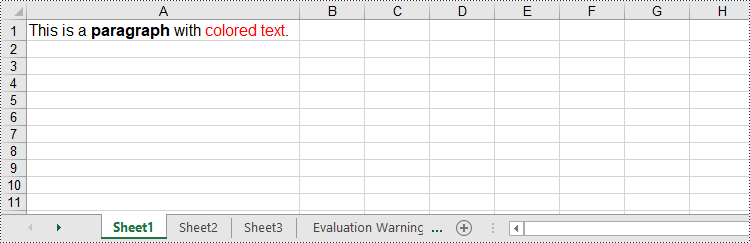
String htmlCode = "<p><font size='12'>This is a <b>paragraph</b> with <span style='color: red;'>colored text</span>.</font></p>";
// Get the cell that you want to add the HTML string to
CellRange range = sheet.getCellRange("A1");
// Add the HTML string to the cell
range.setHtmlString(htmlCode);
// Auto-adjust the width of the first column based on its content
sheet.autoFitColumn(1);
// Save the resulting workbook to a new file
String result = "C:\\Users\\Administrator\\Desktop\\InsertHtmlStringIntoCell.xlsx";
workbook.saveToFile(result, ExcelVersion.Version2013);
workbook.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create Actions in PDF Documents
One powerful feature that enhances the interactivity and utility of PDF documents is the actions in these documents. By embedding actions such as document jumping, navigation controls, or even media playing, users can transform static documents into dynamic tools that streamline workflows, improve user engagement, and automate routine tasks, making the use of PDFs more efficient and versatile than ever before. This article will show how to use Spire.PDF for Python to create actions in PDF documents with Python code effortlessly.
- Create a Navigation Action in PDF with Python
- Create a Sound Action in PDF with Python
- Create a File Open Action in PDF with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Create a Navigation Action in PDF with Python
A navigation button is an action that allows users to jump to a specified position on a designated page within a document. Developers can create a PdfDestination object, use it to create a PdfGoToAction, and then create an annotation based on this object and add it to the page to complete the creation of the navigation button. The following are the detailed steps:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Create a PdfDestination object and set its property.
- Create a PdfGoToAction object based on the destination.
- Draw a rectangle on a page using PdfPageBase.Canvas.DrawRectangle() method.
- Create a PdfActionAnnotation object based on the action and add it to the page using PdfPageBase.Annotations.Add() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create an instance of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a PdfDestination instance and set its properties
destination = PdfDestination(pdf.Pages[0])
destination.Location = PointF(0.0, 0.0)
destination.Mode = PdfDestinationMode.Location
destination.Zoom = 0.8
# Create a rectangle
rect = RectangleF.FromLTRB(70, pdf.PageSettings.Size.Height - 120, 140, pdf.PageSettings.Size.Height - 100)
# Create a PdfGoToAction instance
action = PdfGoToAction(destination)
# Draw a rectangle on the second page
pdf.Pages.get_Item(1).Canvas.DrawRectangle(PdfBrushes.get_LightGray(), rect)
# Draw text of the button
font = PdfFont(PdfFontFamily.TimesRoman, 14.0)
stringFormat = PdfStringFormat(PdfTextAlignment.Center)
pdf.Pages.get_Item(1).Canvas.DrawString("To Page 1", font, PdfBrushes.get_Green(), rect, stringFormat)
# Create a PdfActionAnnotation instance
annotation = PdfActionAnnotation(rect, action)
# Add the annotation to the second page
pdf.Pages.get_Item(1).Annotations.Add(annotation)
# Save the document
pdf.SaveToFile("output/AddPDFNavigationButton.pdf")
pdf.Close()

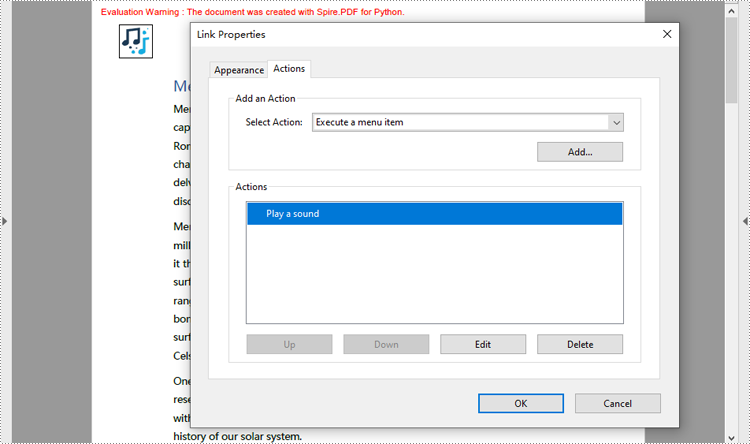
Create a Sound Action in PDF with Python
Developers can embed audio as actions in PDF documents, which allows the audio to play when the user performs a specified action, such as playing when the file opens or when a button is clicked. The following are the steps for creating a sound action:
- Create an instance of PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Create an instance of PdfSoundAction class with an audio file.
- Set the audio parameters through properties under PdfSound class.
- Set the playing parameters through properties under PdfSoundAction class.
- Get a page using PdfDocument.Pgaes.get_Item(() method.
- Draw an image on the page using PdfPageBase.Canvas.Draw() method.
- Create a PdfActionAnnotation object with the sound action at the location of the image.
- Add the annotation to the page
- Or you can only set the sound action as the action performed after the document is opened through PdfDocument.AfterOpenAction property. This doesn’t need to add it as an annotation on a PDF page.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument instance and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get the first page of the document
page = pdf.Pages.get_Item(0)
# Create an instance of PdfSoundAction with the sound file path
soundAction = PdfSoundAction("Wave.wav")
# Set the audio parameters
soundAction.Sound.Bits = 16
soundAction.Sound.Channels = PdfSoundChannels.Stereo
soundAction.Sound.Encoding = PdfSoundEncoding.Signed
soundAction.Sound.Rate = 44100
# Set the playing parameters
soundAction.Volume = 0.5
soundAction.Repeat = True
soundAction.Mix = True
soundAction.Synchronous = False
# Draw an image on the page
image = PdfImage.FromFile("Sound.png")
page.Canvas.DrawImage(image, PointF(30.0, 30.0))
# Create an instance of PdfActionAnnotation with the sound action
rect = RectangleF.FromLTRB(30.0, 30.0, image.GetBounds().Width + 30.0, image.GetBounds().Height + 30.0)
annotation = PdfActionAnnotation(rect, soundAction)
# Add the annotation to the page
page.Annotations.Add(annotation)
# Set the sound action to play after the document is opened
# pdf.AfterOpenAction = soundAction
# Save the document
pdf.SaveToFile("output/AddMusicPDF.pdf")
pdf.Close()
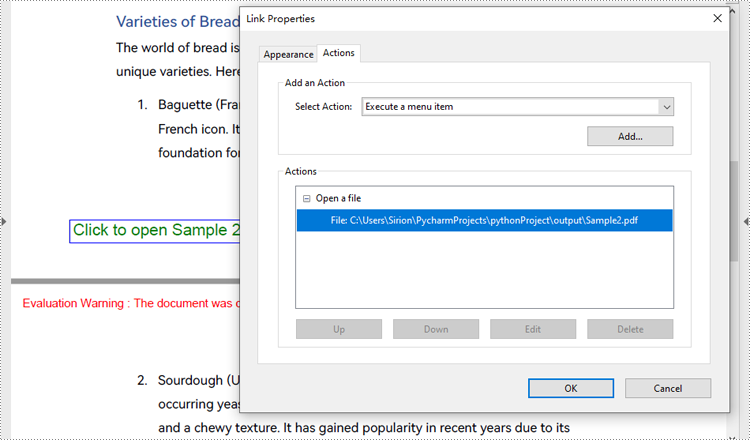
Create a File Open Action in PDF with Python
The PdfLaunchAction class represents a file open action in PDF that allows users to open the corresponding file by clicking on a button on a PDF page. Developers can specify the absolute or relative path of the file to be opened and whether to open in a new window when creating a file open action. The detailed steps for creating a file open action in a PDF document are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page of the document using PdfDocument.Pages.get_Item() method.
- Draw a rectangle on the page using PdfPageBase.Canvas.DrawRectangle() method.
- Create an object of PdfLaunchAction class and specify the file path and path type.
- Set the opening mode to new window through PdfLaunchAction.IsNewWindow property.
- Create an object of PdfActionAnnotation class based on the action and set its color through PdfActionAnnotation.Color property.
- Add the annotation to the page using PdfPageBase.Annotations.Add() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create an instance of PdfDocument class
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the first page of the document
page = pdf.Pages.get_Item(0)
# Draw a rectangle on the page
rect = RectangleF.FromLTRB(50, pdf.PageSettings.Size.Height - 100, 200, pdf.PageSettings.Size.Height - 80)
page.Canvas.DrawRectangle(PdfPens.get_LightGray(), rect)
# Draw text in the rectangle
page.Canvas.DrawString("Click to open Sample 2", PdfFont(PdfFontFamily.Helvetica, 14.0), PdfBrushes.get_Green(), rect, PdfStringFormat(PdfTextAlignment.Center))
# Create a PdfLaunchAction object
action = PdfLaunchAction("Sample2.pdf", PdfFilePathType.Relative)
action.IsNewWindow = True
# Create a PdfActionAnnotation object based on the action
annotation = PdfActionAnnotation(rect, action)
annotation.Color = PdfRGBColor(Color.get_Blue())
# Add the annotation to the page
page.Annotations.Add(annotation)
# Save the document
pdf.SaveToFile("output/CreatePDFLaunchAction.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Copy Content from One Word Document to Another
Transferring content between Microsoft Word documents is a frequent task for many users. Whether you need to consolidate information spread across multiple files or quickly reuse existing text and other elements, the ability to effectively copy and paste between documents can save you time and effort.
In this article, you will learn how to copy content from one Word document to another using Java and Spire.Doc for Java.
- Copy Specified Paragraphs from One Word Document to Another
- Copy a Section from One Word Document to Another
- Copy the Entire Document and Append it to Another
- Create a Copy of a Word Document
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
Copy Specified Paragraphs from One Word Document to Another in Java
Spire.Doc for Java provides a flexible way to copy content between Microsoft Word documents. This is achieved by cloning individual paragraphs and then adding those cloned paragraphs to a different document.
To copy specific paragraphs from one Word document to another, you can follow these steps:
- Load the source document into a Document object.
- Load the target document into a separate Document object.
- Identify the paragraphs you want to copy from the source document.
- Create copies of those selected paragraphs using Paragraph.deepClone() method
- Add the cloned paragraphs to the target document using ParagraphCollection.add() method.
- Save the updated target document to a new Word file.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
public class CopyParagraphs {
public static void main(String[] args) {
// Create a Document object
Document sourceDoc = new Document();
// Load the source file
sourceDoc.loadFromFile("C:\\Users\\Administrator\\Desktop\\source.docx");
// Get a specific section
Section section = sourceDoc.getSections().get(0);
// Get the specified paragraphs from the source file
Paragraph p1 = section.getParagraphs().get(2);
Paragraph p2 = section.getParagraphs().get(3);
// Create another Document object
Document targetDoc = new Document();
// Load the target file
targetDoc.loadFromFile("C:\\Users\\Administrator\\Desktop\\target.docx");
// Get the last section
Section lastSection = targetDoc.getLastSection();
// Add the paragraphs from the source file to the target file
lastSection.getParagraphs().add((Paragraph)p1.deepClone());
lastSection.getParagraphs().add((Paragraph)p2.deepClone());
// Save the target file to a different Word file
targetDoc.saveToFile("CopyParagraphs.docx", FileFormat.Docx_2019);
// Dispose resources
sourceDoc.dispose();
targetDoc.dispose();
}
}
Copy a Section from One Word Document to Another in Java
When copying content between Microsoft Word documents, it's important to consider that a section can contain not only paragraphs, but also other elements like tables. To successfully transfer an entire section from one document to another, you need to iterate through all the child objects within the section and add them individually to a specific section in the target document.
The steps to copy a section between different Word documents are as follows:
- Create Document objects to load the source file and the target file, respectively.
- Get the specified section from the source document.
- Iterate through the child objects within the section.
- Clone a specific child object using DocumentObject.deepClone() method.
- Add the cloned child objects to a designated section in the target document using DocumentObjectCollection.add() method.
- Save the updated target document to a new file.
- Java
import com.spire.doc.Document;
import com.spire.doc.DocumentObject;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
public class CopySection {
public static void main(String[] args) {
// Create a Document object
Document sourceDoc = new Document();
// Load the source file
sourceDoc.loadFromFile("C:\\Users\\Administrator\\Desktop\\source.docx");
// Get the specified section from the source file
Section section = sourceDoc.getSections().get(0);
// Create another Document object
Document targetDoc = new Document();
// Load the target file
targetDoc.loadFromFile("C:\\Users\\Administrator\\Desktop\\target.docx");
// Get the last section of the target file
Section lastSection = targetDoc.getLastSection();
// Iterate through the child objects in the selected section
for (int i = 0; i < section.getBody().getChildObjects().getCount(); i++) {
// Get a specific child object
DocumentObject childObject = section.getBody().getChildObjects().get(i);
// Add the child object to the last section of the target file
lastSection.getBody().getChildObjects().add(childObject.deepClone());
}
// Save the target file to a different Word file
targetDoc.saveToFile("CopySection.docx", FileFormat.Docx_2019);
// Dispose resources
sourceDoc.dispose();
targetDoc.dispose();
}
}

Copy the Entire Document and Append it to Another in Java
Copying the full contents from one Microsoft Word document into another can be achieved using the Document.insertTextFromFile() method. This method enables you to seamlessly append the contents of a source document to a target document.
The steps to copy an entire document and append it to another are as follows:
- Create a Document object to represent the target file.
- Load the target file from the given file path.
- Insert the content of a different Word document into the target file using Document.insertTextFromFile() method.
- Save the updated target file to a new Word document.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class CopyEntireDocument {
public static void main(String[] args) {
// Specify the path of the source document
String sourceFile = "C:\\Users\\Administrator\\Desktop\\source.docx";
// Create a Document object
Document targetDoc = new Document();
// Load the target file
targetDoc.loadFromFile("C:\\Users\\Administrator\\Desktop\\target.docx");
// Insert content of the source file to the target file
targetDoc.insertTextFromFile(sourceFile, FileFormat.Docx);
// Save the target file to a different Word file
targetDoc.saveToFile("CopyEntireDocument.docx", FileFormat.Docx_2019);
// Dispose resources
targetDoc.dispose();
}
}
Create a Copy of a Word Document in Java
Spire.Doc for Java provides a straightforward way to create a duplicate of a Microsoft Word document by using the Document.deepClone() method.
To make a copy of a Word document, follow these steps:
- Create a Document object to relisent the source document.
- Load a Word file from the given file path.
- Create a copy of the document using Document.deepClone() method.
- Save the cloned document to a new Word file.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class DuplicateDocument {
public static void main(String[] args) {
// Create a new document object
Document sourceDoc = new Document();
// Load a Word file
sourceDoc.loadFromFile("C:\\Users\\Administrator\\Desktop\\target.docx");
// Clone the document
Document newDoc = sourceDoc.deepClone();
// Save the cloned document as a docx file
newDoc.saveToFile("Copy.docx", FileFormat.Docx);
// Dispose resources
sourceDoc.dispose();
newDoc.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Office for Java 9.8.0 is released
We are pleased to announce the release of Spire.Office for Java 9.8.0. In this new version, Spire.XLS for Java supports embedding images in cells; Spire.Doc for Java optimizes the clarity of images when converting Word documents to HTML. Besides, some known issues are fixed successfully in this update. More details are listed below.
Here is a list of changes made in this release
Spire.XLS for Java
| Category | ID | Description |
| New feature | SPIREXLS-5147 | Provides the hideCategoriTags method to support hiding category labels.
Chart chart = sheet.getCharts().get(0);
String[] labels = chart.getCategoryLabels();
chart.hideCategoryLabels(new String[]
{ labels [0], labels [1], ...}
);
|
| New feature | SPIREXLS-5338 | Supports embedding images in cells.
worksheet.getCellRange("B1").insertOrUpdateCellImage("D:\\vs1.png",true);
|
| Bug | SPIREXLS-5331 | Fixes the issue that caused incorrect content when saving an Excel document and opening it in Microsoft Excel 2016. |
| Bug | SPIREXLS-5337 | Fixes the issue that resulted in incorrect pivot table data calculation. |
Spire.PDF for Java
| Category | ID | Description |
| Bug | SPIREPDF-6851 | Fixes the issue that the program threw "NullPointerException" when converting PDF to SVG. |
| Bug | SPIREPDF-6881 | Fixes the issue that some punctuation marks were missing when extracting table text. |
| Bug | SPIREPDF-6895 | Fixes the issue that the content was lost when converting OFD to PDF. |
| Bug | SPIREPDF-6923 | Fixes the issue that the program threw "doc-0/res/doc-0/res/res7651308984730378845.png cannot be found!" when converting OFD to PDF. |
| Bug | SPIREPDF-6924 | Fixes the issue that the program threw "ArrangStoreException" while reading Tiff files. |
| Bug | SPIREPDF-6939 | Fixes the issue that the program threw "NullPointerException" when converting PDF to Word. |
| Bug | SPIREPDF-6947 | Fixes the issue that the font styles were incorrect when converting PDF to PPTX. |
Spire.Doc for Java
| Category | ID | Description |
| Optimization | SPIREDOC-10600 | Improves clarity of images when converting Word documents to HTML. |
| Bug | SPIREDOC-10546 SPIREDOC-10601 |
Fixes the issue that the images were lost when converting HTML to Word. |
| Bug | SPIREDOC-10562 | Fixes the problem that the program threw "Unknown boolex value" exception when converting Word to PDF. |
| Bug | SPIREDOC-10688 | Fixes the issue that the table borders were lost when the saved Doc document was opened in WPS tool. |
Python: Detect Page Orientation or Rotation Angle in PDF
Proper presentation of a PDF document is critical for maintaining its accuracy and professionalism. By checking the orientation and rotation of each PDF page, you can confirm that all elements, including diagrams and images, are displayed correctly as intended on the viewing device or platform, thus avoiding confusion or misinterpretation of content. In this article, you will learn how to detect the orientation and rotation angle of a PDF page in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
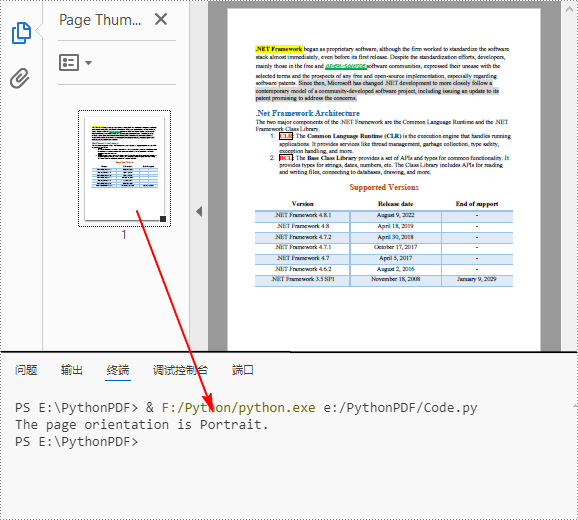
Detect PDF Page Orientation in Python
Page orientation is determined by the relationship between page width and height. Using Spire.PDF for Python, you can compare these two values to detect whether a page is landscape (width greater than height) or portrait (width less than height). The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Get the width and height of the PDF page using PdfPageBase.Size.Width and PdfPageBase.Size.Height properties.
- Compare the values of page width and height to detect the page orientation.
- Print out the result.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from disk
pdf.LoadFromFile("SamplePDF.pdf")
# Get the first page
page = pdf.Pages[0]
# Get the width and height of the page
Width = page.Size.Width
Height = page.Size.Height
# Compare the values of page width and height
if Width > Height:
print("The page orientation is Landscape.")
else:
print("The page orientation is Portrait.")
Detect PDF Page Rotation Angle in Python
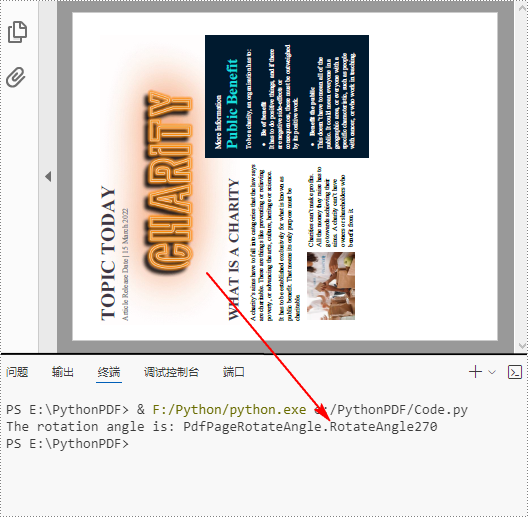
PDF pages can be rotated by a certain angle. To detect the rotation angle of a PDF page, you can use the PdfPageBase.Rotation property. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Get the rotation angle of the page using PdfPageBase.Rotation property, and then convert it to text string.
- Print out the result.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from disk
pdf.LoadFromFile("Sample.pdf")
# Get the first page
page = pdf.Pages[0]
# Get the rotation angle of the current page
rotationAngle = page.Rotation
rotation = str(rotationAngle)
# Print out the result
print("The rotation angle is: " + rotation)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.