C#: Convert HTML to PDF using ChromeHtmlConverter
HTML is widely used to present content in web browsers, but preserving its exact layout when sharing or printing can be challenging. PDF, by contrast, is a universally accepted format that reliably maintains document layout across various devices and operating systems. Converting HTML to PDF is particularly useful in web development, especially when creating printable versions of web pages or generating reports from web data.
Spire.PDF for .NET now supports a streamlined method to convert HTML to PDF in C# using the ChromeHtmlConverter class. This tutorial provides step-by-step guidance on performing this conversion effectively.
- Convert HTML to PDF with ChromeHtmlConverter in C#
- Generate Output Logs During HTML to PDF Conversion in C#
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLLs files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Install Google Chrome
This method requires Google Chrome to perform the conversion. If Chrome is not already installed, you can download it from this link and install it.
Convert HTML to PDF using ChromeHtmlConverter in C#
You can utilize the ChromeHtmlConverter.ConvertToPdf() method to convert an HTML file to a PDF using the Chrome plugin. This method accepts 3 parameters, including the input HTML file path, output PDF file path, and ConvertOptions which allows customization of conversion settings like conversion timeout, PDF paper size and page margins. The detailed steps are as follows.
- Create an instance of the ChromeHtmlConverter class and provide the path to the Chrome plugin (chrome.exe) as a parameter in the class constructor.
- Create an instance of the ConvertOptions class.
- Customize the conversion settings, such as the conversion timeout, the paper size and page margins of the converted PDF through the properties of the ConvertOptions class.
- Convert an HTML file to PDF using the ChromeHtmlConverter.ConvertToPdf() method.
- C#
using Spire.Additions.Chrome;
namespace ConvertHtmlToPdfUsingChrome
{
internal class Program
{
static void Main(string[] args)
{
//Specify the input URL and output PDF file path
string inputUrl = @"https://www.e-iceblue.com/Tutorials/Spire.PDF/Spire.PDF-Program-Guide/C-/VB.NET-Convert-Image-to-PDF.html";
string outputFile = @"HtmlToPDF.pdf";
//Specify the path to the Chrome plugin
string chromeLocation = @"C:\Program Files\Google\Chrome\Application\chrome.exe";
//Create an instance of the ChromeHtmlConverter class
ChromeHtmlConverter converter = new ChromeHtmlConverter(chromeLocation);
// Create an instance of the ConvertOptions class
ConvertOptions options = new ConvertOptions();
//Set conversion timeout
options.Timeout = 10 * 3000;
//Set paper size and page margins of the converted PDF
options.PageSettings = new PageSettings()
{
PaperWidth = 8.27,
PaperHeight = 11.69,
MarginTop = 0,
MarginLeft = 0,
MarginRight = 0,
MarginBottom = 0
};
//Convert the URL to PDF
converter.ConvertToPdf(inputUrl, outputFile, options);
}
}
}
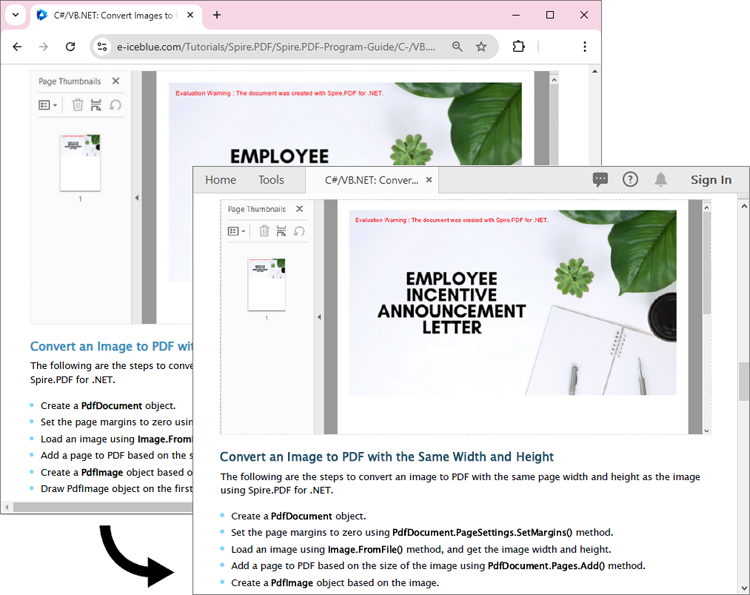
The converted PDF file maintains the same appearance as if the HTML file were printed to PDF directly through the Chrome browser:
Generate Output Logs During HTML to PDF Conversion in C#
Spire.PDF for .NET enables you to generate output logs during HTML to PDF conversion using the Logger class. The detailed steps are as follows.
- Create an instance of the ChromeHtmlConverter class and provide the path to the Chrome plugin (chrome.exe) as a parameter in the class constructor.
- Enable Logging by creating a Logger object and assigning it to the ChromeHtmlConverter.Logger property.
- Create an instance of the ConvertOptions class.
- Customize the conversion settings, such as the conversion timeout, the paper size and page margins of the converted PDF through the properties of the ConvertOptions class.
- Convert an HTML file to PDF using the ChromeHtmlConverter.ConvertToPdf() method.
- C#
using Spire.Additions.Chrome;
namespace ConvertHtmlToPdfUsingChrome
{
internal class Program
{
static void Main(string[] args)
{
//Specify the input URL and output PDF file path
string inputUrl = @"https://www.e-iceblue.com/Tutorials/Spire.PDF/Spire.PDF-Program-Guide/C-/VB.NET-Convert-Image-to-PDF.html";
string outputFile = @"HtmlToPDF.pdf";
// Specify the log file path
string logFilePath = @"Logs.txt";
//Specify the path to the Chrome plugin
string chromeLocation = @"C:\Program Files\Google\Chrome\Application\chrome.exe";
//Create an instance of the ChromeHtmlConverter class
ChromeHtmlConverter converter = new ChromeHtmlConverter(chromeLocation);
//Enable logging
converter.Logger = new Logger(logFilePath);
//Create an instance of the ConvertOptions class
ConvertOptions options = new ConvertOptions();
//Set conversion timeout
options.Timeout = 10 * 3000;
//Set paper size and page margins of the converted PDF
options.PageSettings = new PageSettings()
{
PaperWidth = 8.27,
PaperHeight = 11.69,
MarginTop = 0,
MarginLeft = 0,
MarginRight = 0,
MarginBottom = 0
};
//Convert the URL to PDF
converter.ConvertToPdf(inputUrl, outputFile, options);
}
}
}
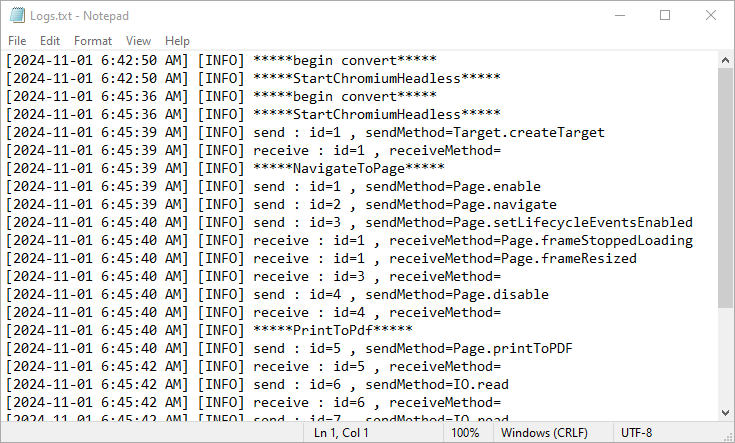
Here is the screenshot of the output log file:
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Import and Export PDF Form Data
PDF forms are essential tools for collecting information across various industries. Understanding how to import and export this data in different formats like FDF, XFDF, and XML can greatly enhance your data management processes. For instance, importing form data allows you to update or pre-fill PDF forms with existing information, saving time and increasing accuracy. Conversely, exporting form data enables you to share collected information effortlessly with other applications, facilitating seamless integration and minimizing manual entry errors. In this article, we will introduce how to import and export PDF form data in Python using Spire.PDF for Python.
- Import PDF Form Data from FDF, XFDF or XML Files in Python
- Export PDF Form Data to FDF, XFDF or XML Files in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
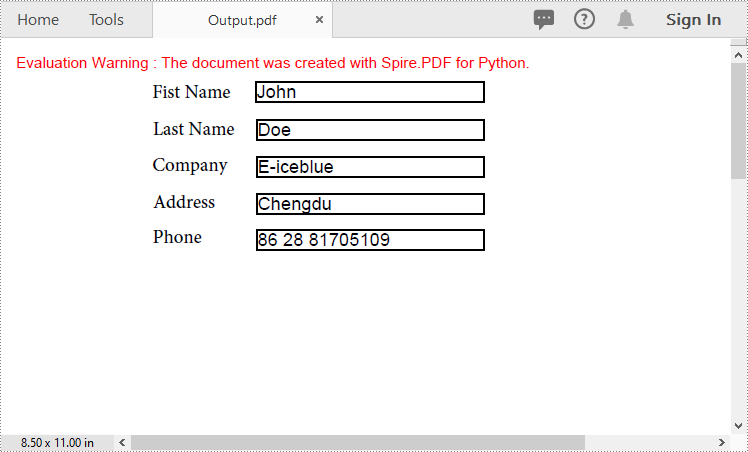
Import PDF Form Data from FDF, XFDF or XML Files in Python
Spire.PDF for Python offers the PdfFormWidget.ImportData() method for importing PDF form data from FDF, XFDF, or XML files. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using PdfDocument.Form property.
- Import form data from an FDF, XFDF or XML file using PdfFormWidget.ImportData() method.
- Save the resulting document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Forms.pdf")
# Get the form of the document
pdfForm = pdf.Form
formWidget = PdfFormWidget(pdfForm)
# Import PDF form data from an XML file
formWidget.ImportData("Data.xml", DataFormat.Xml)
# Import PDF form data from an FDF file
# formWidget.ImportData("Data.fdf", DataFormat.Fdf)
# Import PDF form data from an XFDF file
# formWidget.ImportData("Data.xfdf", DataFormat.XFdf)
# Save the resulting document
pdf.SaveToFile("Output.pdf")
# Close the PdfDocument object
pdf.Close()
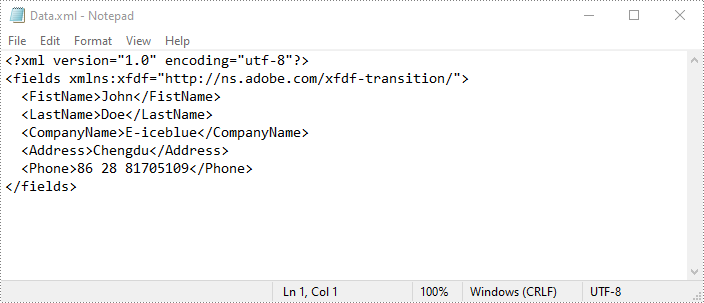
Export PDF Form Data to FDF, XFDF or XML Files in Python
Spire.PDF for Python also enables developers to export PDF form data to FDF, XFDF, or XML files by using the PdfFormWidget.ExportData() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using PdfDocument.Form property.
- Export form data to an FDF, XFDF or XML file using PdfFormWidget.ExportData() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Forms.pdf")
# Get the form of the document
pdfForm = pdf.Form
formWidget = PdfFormWidget(pdfForm)
# Export PDF form data to an XML file
formWidget.ExportData("Data.xml", DataFormat.Xml, "Form")
# Export PDF form data to an FDF file
# formWidget.ExportData("Data.fdf", DataFormat.Fdf, "Form")
# Export PDF form data to an XFDF file
# formWidget.ExportData("Data.xfdf", DataFormat.XFdf, "Form")
# Close the PdfDocument object
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Office 9.10.0 is released
We are excited to announce the release of Spire.Office 9.10.0. In this version, Spire.PDF supports ignoring images when converting PDF to Markdown; Spire.Doc adds new methods to track the addition, deletion, and modification of document elements; Spire.XLS supports ARRAYTOTEXT, ARABIC, BASE, COMBINA, XOR formulas. Moreover, a lot of known issues are fixed successfully in this version. More details are listed below.
In this version, the most recent versions of Spire.Doc, Spire.PDF, Spire.XLS, Spire.Presentation, Spire.Email, Spire.DocViewer, Spire.PDFViewer, Spire.Spreadsheet, Spire.OfficeViewer, Spire.DataExport, and Spire.Barcode are included.
DLL Versions:
- Spire.Doc.dll v12.10.13
- Spire.Pdf.dll v10.10.5
- Spire.XLS.dll v14.10.2
- Spire.Presentation.dll v9.10.2
- Spire.Barcode.dll v7.3.3
- Spire.Email.dll v6.6.0
- Spire.DocViewer.Forms.dll v8.8.2
- Spire.PdfViewer.Asp.dll v7.12.23
- Spire.PdfViewer.Forms.dll v7.12.23
- Spire.Spreadsheet.dll v7.5.2
- Spire.OfficeViewer.Forms.dll v8.7.15
- Spire.DataExport.dll 4.9.0
- Spire.DataExport.ResourceMgr.dll v2.1.0
Here is a list of changes made in this release
Spire.PDF
| Category | ID | Description |
| New feature | SPIREPDF-7003 | Supports ignoring images when converting PDF to Markdown.
PdfToMarkdownConverter converter = new PdfToMarkdownConverter(inputFile); converter.MarkdownOptions.IgnoreImage = true; converter.ConvertToMarkdown(outputFile); |
| New feature | SPIREPDF-7030 | Extends the PdfMDPSignatureMaker class to support passing an IPdfSignatureFormatter object.
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile(inputFile);
X509Certificate2 cert = new X509Certificate2(inputFile_pfx, "e-iceblue");
IPdfSignatureFormatter formatter = new PdfPKCS7Formatter(cert, false);
PdfMDPSignatureMaker pdfMDPSignatureMaker = new PdfMDPSignatureMaker(pdf, formatter);
PdfSignature signature = pdfMDPSignatureMaker.Signature;
signature.Name = "e-iceblue";
signature.ContactInfo = "028-81705109";
signature.Location = "chengdu";
signature.Reason = " this document";
PdfSignatureAppearance appearance = new PdfSignatureAppearance(signature);
appearance.NameLabel = "Signer: ";
appearance.ContactInfoLabel = "ContactInfo: ";
appearance.LocationLabel = "Loaction: ";
appearance.ReasonLabel = "Reason: ";
pdfMDPSignatureMaker.MakeSignature("signName", pdf.Pages[0], 100, 100, 250, 200, appearance);
pdf.SaveToFile(outputFile, FileFormat.PDF);
pdf.Dispose();
|
| New feature | SPIREPDF-7030 | Supports signing existing signature fields using either the PdfOrdinarySignatureMaker class or the PdfMDPSignatureMaker class.
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile(inputFile);
PdfFormWidget widgets = pdf.Form as PdfFormWidget;
for (int i = 0; i < widgets.FieldsWidget.List.Count; i++)
{
PdfFieldWidget widget = widgets.FieldsWidget.List[i] as PdfFieldWidget;
if (widget is PdfSignatureFieldWidget)
{
string originalName = widget.Name;
X509Certificate2 cert = new X509Certificate2(inputFile_pfx, "e-iceblue");
IPdfSignatureFormatter formatter = new PdfPKCS7Formatter(cert, false);
// PdfMDPSignatureMaker signatureMaker = new PdfMDPSignatureMaker(pdf, formatter);
PdfOrdinarySignatureMaker signatureMaker = new PdfOrdinarySignatureMaker(pdf, formatter);
PdfSignature signature = signatureMaker.Signature;
signature.Name = "E-iceblue";
signature.ContactInfo = "028-81705109";
signature.Location = "chengdu";
signature.Reason = "document";
PdfSignatureAppearance appearance = new PdfSignatureAppearance(signature);
appearance.NameLabel = "Signer: ";
appearance.ContactInfoLabel = "ContactInfo: ";
appearance.LocationLabel = "Loaction: ";
appearance.ReasonLabel = "Reason: ";
appearance.SignatureImage = PdfImage.FromFile(inputFile_Img);
appearance.GraphicMode = GraphicMode.SignImageAndSignDetail;
signatureMaker.MakeSignature(originalName, appearance);
}
}
pdf.SaveToFile(outputFile);
pdf.Dispose();
|
| New feature | SPIREPDF-7014 | Adds the Logger class that supports logging output when converting HTML to PDF using Chrome plugin.
ChromeHtmlConverter converter = new ChromeHtmlConverter(TestUtil.ChromiumPath); converter.Logger = new Logger(logFilePath); //Enable IsEnabled to output logs to the console //Logger.IsEnabled = true; ConvertOptions options = new ConvertOptions(); |
| New feature | SPIREPDF-7104 | Supports creating PdfAttachmentAnnotation and adding an author.
annotation.Title = "test"; |
| Bug | SPIREPDF-5473 | Fixes the issue that the bold fonts were not correctly applied when converting PDF document to PdfX1A2001 document. |
| Bug | SPIREPDF-7044 | Fixes the issue that the Bounds for vertical text were not obtained correctly. |
| Bug | SPIREPDF-7066 | Fixes the issue that the application threw "NullReferenceException" when converting PDF document to LinearizedPdf document. |
| Bug | SPIREPDF-7079 | Fixes the issue that the application threw "An item with the same key has already been added" exception during multi-threaded extraction of text from PDF pages. |
| Bug | SPIREPDF-7110 | Fixes the issue that the application threw a "DivideByZeroException" when calling the SetPdfToHtmlOptions method in multi-threaded scenarios. |
| Bug | SPIREPDF-7111 | Fixes the issue that the output result was incorrect when converting OFD document to PDF document and then saving them as XPS. |
| Bug | SPIREPDF-7119 | Fixes the issue that the program would hang while reading fonts from PDF document. |
| Bug | SPIREPDF-6736 | Fixes the issue that opening the resulting document after converting a PDF document to a PDFA document caused an error. |
| Bug | SPIREPDF-6946 | Fixes the issue that the application threw the System.IndexOutOfRangeException: "Index was outside the bounds of the array." exception when converting a PDF document to a PPTX document. |
| Bug | SPIREPDF-6948 | Fixes the issue that converting a PDF document to images experienced a decrease in speed. |
| Bug | SPIREPDF-7006 | Fixes the issue that validating the validity of signatures always returned false for the first signature. |
| Bug | SPIREPDF-7012 | Fixes the issue that the application threw the "Object reference not set to an instance of an object" exception when converting an OFD document to a PDF document. |
| Bug | SPIREPDF-7013 | Fixes the issue that the application threw the "Invalid font weight value: 681" exception when converting an OFD document to a PDF document. |
| Bug | SPIREPDF-7027 | Fixes the issue that converting an OFD document to a PDF document resulted in content loss. |
| Bug | SPIREPDF-7032 | Fixes the issue that the application threw the "Object reference not set to an instance of an object" exception when compressing a PDF document. |
| Bug | SPIREPDF-7046 | Fixes the issue that the application threw the "NullReferenceException" exception when converting a PDF document to a ToPdfA3B document without applying license. |
Spire.Doc
| Category | ID | Description |
| New feature | - | Adds new methods to track the addition, deletion, and modification of document elements.
public void StartTrackRevisions(string author); public void StartTrackRevisions(string author, DateTime dateTime); public void StopTrackRevisions(); |
| New feature | SPIREDOC-10831 | Supports modification of the revision author.
range.InsertRevision.Author = "e-iceblue"; |
| Bug | SPIREDOC-9646 | Fixes the issue that the table content was missing when converting Word to PDF. |
| Bug | SPIREDOC-10588 | Fixes the issue that the program threw an "ArgumentException" when converting Word to HTML. |
| Bug | SPIREDOC-10727 | Fixes the issue of blank content when converting Word to PDF. |
| Bug | SPIREDOC-10766 | Fixes the issue that the program threw a "Cannot insert an object of type Paragraph into the Document" exception when loading Word document. |
| Bug | SPIREDOC-10753 | Fixes the issue that paragraph indentation was lost after replacing paragraph text in bookmarks. |
| Bug | SPIREDOC-10764 | Fixes the issue that the program was hanging when converting Word to PDF. |
| Bug | SPIREDOC-10816 | Fixes the issue that some parts of the page content were lost after converting Word to PDF. |
Spire.XLS
| Category | ID | Description |
| New feature | SPIREXLS-5350 | MarkerDesigner now supports applying filter value parameters. |
| New feature | SPIREXLS-5396 | ARRAYTOTEXT formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Text = "True"; workbook.Worksheets[0].Range["A2"].Text = "1234.01234"; workbook.Worksheets[0].Range["A3"].Text = "Hello"; workbook.Worksheets[0].Range["B1"].Text = "#VALUE!"; workbook.Worksheets[0].Range["B2"].Text = "Seattle"; workbook.Worksheets[0].Range["B3"].Text = "$1,123.00"; workbook.Worksheets[0].Range["D1"].FormulaArray = "=ARRAYTOTEXT(A1:B4,0)"; workbook.Worksheets[0].Range["D3"].FormulaArray = "=ARRAYTOTEXT(A1:B4,1)"; workbook.SaveToFile(outputFile, ExcelVersion.Version2013); |
| New feature | SPIREXLS-5471 | ARABIC formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Value2 = "mcmxii"; workbook.Worksheets[0].Range["C1"].Formula = "=ARABIC(A1)"; workbook.Worksheets[0].Range["C2"].Formula = "=ARABIC(\"LVII\")"; workbook.Worksheets[0].Range["C3"].Formula = "=ARABIC(\"mcmxii\")"; workbook.Worksheets[0].Range["C4"].Formula = "=ARABIC(\"\")"; workbook.Worksheets[0].Range["C5"].Formula = "=ARABIC(\"-LVII\")"; workbook.Worksheets[0].Range["C6"].Formula = "=ARABIC(\"57\")"; workbook.Worksheets[0].Range["C7"].Formula = "=ARABIC(\"2024/10/15\")"; workbook.Worksheets[0].Range["C8"].Formula = "=ARABIC(\"Text\")"; |
| New feature | SPIREXLS-5478 | BASE formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Value2 = 7; workbook.Worksheets[0].Range["C1"].Formula = "=BASE(A1,2)"; workbook.Worksheets[0].Range["C2"].Formula = "=BASE(7,2)"; workbook.Worksheets[0].Range["C3"].Formula = "=BASE(100,16))"; workbook.Worksheets[0].Range["C4"].Formula = "=BASE(15,2,10)"; workbook.Worksheets[0].Range["C5"].Formula = "=BASE(Text,16))"; workbook.Worksheets[0].Range["C6"].Formula = "=BASE(-7,2)"; |
| New feature | SPIREXLS-5479 | COMBINA formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Value2 = 4; workbook.Worksheets[0].Range["C1"].Formula = "=COMBINA(A1,3)"; workbook.Worksheets[0].Range["C2"].Formula = "=COMBINA(4,3)"; workbook.Worksheets[0].Range["C3"].Formula = "=COMBINA(10,3)"; workbook.Worksheets[0].Range["C4"].Formula = "=COMBINA(3,10)"; workbook.Worksheets[0].Range["C5"].Formula = "=COMBINA(Text,16))"; |
| New feature | SPIREXLS-5480 | XOR formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Value2 = 3; workbook.Worksheets[0].Range["A2"].Value2 = 0; workbook.Worksheets[0].Range["C1"].Formula = "=XOR(A1>A2)"; workbook.Worksheets[0].Range["C2"].Formula = "=XOR(2>9)"; workbook.Worksheets[0].Range["C3"].Formula = "=XOR(3>0,2<9)"; workbook.Worksheets[0].Range["C4"].Formula = "=XOR(3>12,2<9)"; workbook.Worksheets[0].Range["C5"].Formula = "=XOR(3>12,2<9,4>6)"; workbook.Worksheets[0].Range["A6"].Value2 = 3>0; workbook.Worksheets[0].Range["C6"].Formula = "=XOR(A6)"; |
| New feature | SPIREXLS-5482 | Supports embedding images into cells.
worksheet.Range["B1"].InsertOrUpdateCellImage("D:\\vs1.png",true);
|
| New feature | SPIREXLS-5521 | Supports getting a cell's NamedRange.
Workbook workbook = new Workbook();
workbook.LoadFromFile(inputFile);
var result = workbook.Worksheets[0].Range["A1"].GetNamedRange();
System.Console.WriteLine(result);
var result1 = workbook.Worksheets[0].Range["A2"].GetNamedRange();
System.Console.WriteLine(result1);
File.WriteAllText(outputFile_T, result.ToString()+ "\r\n");
File.AppendAllText(outputFile_T, result1.ToString()+ "\r\n");
var result2 = workbook.Worksheets[0].Range["A3"].GetNamedRange();
if (result2 == null)
{
System.Console.WriteLine("null");
File.AppendAllText(outputFile_T, "null");
}
|
| Bug | SPIREXLS-2333 | Fixed an issue where the number of pages retrieved was incorrect. |
| Bug | SPIREXLS-5287 | Fixed an issue with decimal points not being correct when exporting data under the .NET 6 framework. |
| Bug | SPIREXLS-5347 | Fixed an issue where embedded images in cells were lost after converting Excel to PDF. |
| Bug | SPIREXLS-5465 | Fixed an exception "Index was out of range. Must be non-negative and less than the size of the collection. (Parameter 'index')" when converting Excel to PDF. |
| Bug | SPIREXLS-5481 | Fixed an issue where the calculation result of a formula was incorrect. |
| Bug | SPIREXLS-5486 | Fixed an exception when converting Excel to PDF. |
| Bug | SPIREXLS-5489 | Fixed an issue where an additional "@" character was inserted when adding formulas to cells, and the formula value was incorrect. |
| Bug | SPIREXLS-5491 | Fixed an issue where deleting Sparklines failed. |
| Bug | SPIREXLS-5532 | Fixed an issue where adding filters to pivot tables failed. |
C#: Convert Word to Markdown
Markdown, with its lightweight syntax, offers a streamlined approach to web content creation, collaboration, and document sharing, particularly in environments where tools like Git or Markdown-friendly editors are prevalent. By converting Word documents to Markdown files, users can enhance their productivity, facilitate easier version control, and ensure compatibility across different systems and platforms. In this article, we will explore the process of converting Word documents to Markdown files using Spire.Doc for .NET, providing simple C# code examples.
Install Spire.Doc for .NET
To begin with, you need to add the DLL files included in the Spire.Doc for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Doc
Convert Word to Markdown with C#
Using Spire.Doc for .NET, we can convert a Word document to a Markdown file by loading the document using Document.LoadFromFile() method and then convert it to a Markdown file using Document.SaveToFile(filename: String, FileFormat.Markdown) method. The detailed steps are as follows:
- Create an instance of Document class.
- Load a Word document using Document.LoadFromFile() method.
- Convert the document to a Markdown file using Document.SaveToFile(filename: String, FileFormat.Markdown) method.
- Release resources.
- C#
using Spire.Doc;
namespace WordToMarkdown
{
class Program
{
static void Main(string[] args)
{
// Create an instance of Document class
Document doc = new Document();
// Load a Word document
doc.LoadFromFile("Sample.docx");
// Convert the document to a Markdown file
doc.SaveToFile("output/WordToMarkdown.md", FileFormat.Markdown);
doc.Dispose();
}
}
}
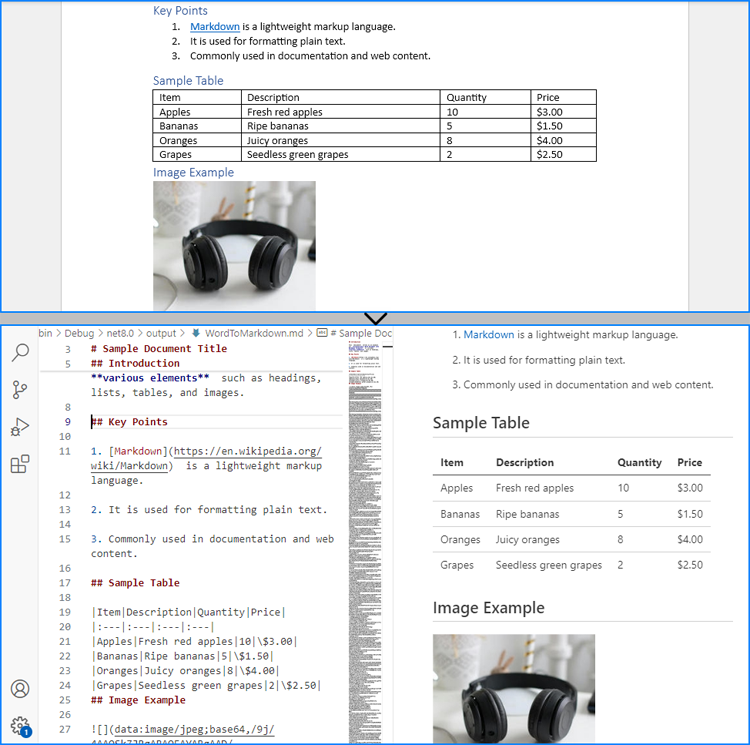
Convert Word to Markdown Without Images
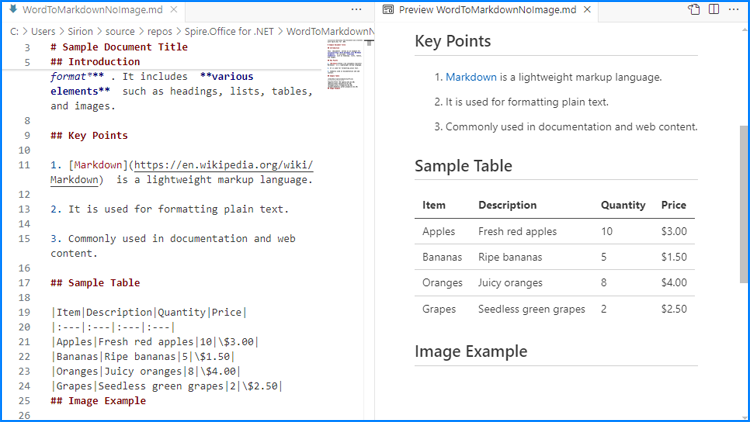
When using Spire.Doc for .NET to convert Word documents to Markdown files, images are stored in Base64 encoding by default, which can increase the file size and affect compatibility. To address this, we can remove the images during conversion, thereby reducing the file size and enhancing compatibility.
The following steps outline how to convert Word documents to Markdown files without images:
- Create an instance of Document class.
- Load a Word document using Document.LoadFromFile() method.
- Iterate through the sections and then the paragraphs in the document.
- Iterate through the document objects in the paragraphs:
- Get a document object through Paragraph.ChildObjects[] property.
- Check if it’s an instance of DocPicture class. If it is, remove it using Paragraph.ChildObjects.Remove(DocumentObject) method.
- Convert the document to a Markdown file using Document.SaveToFile(filename: String, FileFormat.Markdown) method.
- Release resources.
- C#
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
namespace WordToMarkdownNoImage
{
class Program
{
static void Main(string[] args)
{
// Create an instance of Document class
Document doc = new Document();
// Load a Word document
doc.LoadFromFile("Sample.docx");
// Iterate through the sections in the document
foreach (Section section in doc.Sections)
{
// Iterate through the paragraphs in the sections
foreach (Paragraph paragraph in section.Paragraphs)
{
// Iterate through the document objects in the paragraphs
for (int i = 0; i < paragraph.ChildObjects.Count; i++)
{
// Get a document object
DocumentObject docObj = paragraph.ChildObjects[i];
// Check if it is an instance of DocPicture class
if (docObj is DocPicture)
{
// Remove the DocPicture instance
paragraph.ChildObjects.Remove(docObj);
}
}
}
}
// Convert the document to a Markdown file
doc.SaveToFile("output/WordToMarkdownNoImage.md", FileFormat.Markdown);
doc.Dispose();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.XLS 14.10.2 supports ARRAYTOTEXT, ARABIC, BASE, COMBINA, XOR formulas
We're pleased to announce the release of Spire.XLS 14.10.2. This version supports ARRAYTOTEXT, ARABIC, BASE, COMBINA, XOR formulas, and also supports embedding images into cells as well as getting a cell's NamedRange. What’s more, the issues that occurred when converting Excel to PDF, retrieving number of pages, and exporting data has been successfully resolved. More details are shown below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREXLS-5350 | MarkerDesigner now supports applying filter value parameters. |
| New feature | SPIREXLS-5396 | ARRAYTOTEXT formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Text = "True"; workbook.Worksheets[0].Range["A2"].Text = "1234.01234"; workbook.Worksheets[0].Range["A3"].Text = "Hello"; workbook.Worksheets[0].Range["B1"].Text = "#VALUE!"; workbook.Worksheets[0].Range["B2"].Text = "Seattle"; workbook.Worksheets[0].Range["B3"].Text = "$1,123.00"; workbook.Worksheets[0].Range["D1"].FormulaArray = "=ARRAYTOTEXT(A1:B4,0)"; workbook.Worksheets[0].Range["D3"].FormulaArray = "=ARRAYTOTEXT(A1:B4,1)"; workbook.SaveToFile(outputFile, ExcelVersion.Version2013); |
| New feature | SPIREXLS-5471 | ARABIC formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Value2 = "mcmxii"; workbook.Worksheets[0].Range["C1"].Formula = "=ARABIC(A1)"; workbook.Worksheets[0].Range["C2"].Formula = "=ARABIC(\"LVII\")"; workbook.Worksheets[0].Range["C3"].Formula = "=ARABIC(\"mcmxii\")"; workbook.Worksheets[0].Range["C4"].Formula = "=ARABIC(\"\")"; workbook.Worksheets[0].Range["C5"].Formula = "=ARABIC(\"-LVII\")"; workbook.Worksheets[0].Range["C6"].Formula = "=ARABIC(\"57\")"; workbook.Worksheets[0].Range["C7"].Formula = "=ARABIC(\"2024/10/15\")"; workbook.Worksheets[0].Range["C8"].Formula = "=ARABIC(\"Text\")"; |
| New feature | SPIREXLS-5478 | BASE formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Value2 = 7; workbook.Worksheets[0].Range["C1"].Formula = "=BASE(A1,2)"; workbook.Worksheets[0].Range["C2"].Formula = "=BASE(7,2)"; workbook.Worksheets[0].Range["C3"].Formula = "=BASE(100,16))"; workbook.Worksheets[0].Range["C4"].Formula = "=BASE(15,2,10)"; workbook.Worksheets[0].Range["C5"].Formula = "=BASE(Text,16))"; workbook.Worksheets[0].Range["C6"].Formula = "=BASE(-7,2)"; |
| New feature | SPIREXLS-5479 | COMBINA formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Value2 = 4; workbook.Worksheets[0].Range["C1"].Formula = "=COMBINA(A1,3)"; workbook.Worksheets[0].Range["C2"].Formula = "=COMBINA(4,3)"; workbook.Worksheets[0].Range["C3"].Formula = "=COMBINA(10,3)"; workbook.Worksheets[0].Range["C4"].Formula = "=COMBINA(3,10)"; workbook.Worksheets[0].Range["C5"].Formula = "=COMBINA(Text,16))"; |
| New feature | SPIREXLS-5480 | XOR formula has been supported.
Workbook workbook = new Workbook(); workbook.Worksheets[0].Range["A1"].Value2 = 3; workbook.Worksheets[0].Range["A2"].Value2 = 0; workbook.Worksheets[0].Range["C1"].Formula = "=XOR(A1>A2)"; workbook.Worksheets[0].Range["C2"].Formula = "=XOR(2>9)"; workbook.Worksheets[0].Range["C3"].Formula = "=XOR(3>0,2<9)"; workbook.Worksheets[0].Range["C4"].Formula = "=XOR(3>12,2<9)"; workbook.Worksheets[0].Range["C5"].Formula = "=XOR(3>12,2<9,4>6)"; workbook.Worksheets[0].Range["A6"].Value2 = 3>0; workbook.Worksheets[0].Range["C6"].Formula = "=XOR(A6)"; |
| New feature | SPIREXLS-5482 | Supports embedding images into cells.
worksheet.Range["B1"].InsertOrUpdateCellImage("D:\\vs1.png",true);
|
| New feature | SPIREXLS-5521 | Supports getting a cell's NamedRange.
Workbook workbook = new Workbook();
workbook.LoadFromFile(inputFile);
var result = workbook.Worksheets[0].Range["A1"].GetNamedRange();
System.Console.WriteLine(result);
var result1 = workbook.Worksheets[0].Range["A2"].GetNamedRange();
System.Console.WriteLine(result1);
File.WriteAllText(outputFile_T, result.ToString()+ "\r\n");
File.AppendAllText(outputFile_T, result1.ToString()+ "\r\n");
var result2 = workbook.Worksheets[0].Range["A3"].GetNamedRange();
if (result2 == null)
{
System.Console.WriteLine("null");
File.AppendAllText(outputFile_T, "null");
}
|
| Bug | SPIREXLS-2333 | Fixed an issue where the number of pages retrieved was incorrect. |
| Bug | SPIREXLS-5287 | Fixed an issue with decimal points not being correct when exporting data under the .NET 6 framework. |
| Bug | SPIREXLS-5347 | Fixed an issue where embedded images in cells were lost after converting Excel to PDF. |
| Bug | SPIREXLS-5465 | Fixed an exception "Index was out of range. Must be non-negative and less than the size of the collection. (Parameter 'index')" when converting Excel to PDF. |
| Bug | SPIREXLS-5481 | Fixed an issue where the calculation result of a formula was incorrect. |
| Bug | SPIREXLS-5486 | Fixed an exception when converting Excel to PDF. |
| Bug | SPIREXLS-5489 | Fixed an issue where an additional "@" character was inserted when adding formulas to cells, and the formula value was incorrect. |
| Bug | SPIREXLS-5491 | Fixed an issue where deleting Sparklines failed. |
| Bug | SPIREXLS-5532 | Fixed an issue where adding filters to pivot tables failed. |
Spire.Office for Java 9.10.0 is released
We are excited to announce the release of Spire.Office for Java 9.10.0. In this version, Spire.Doc for Java enhances the conversion from Markdown to Word; Spire.Presentation for Java supports finding the first occurrence of text; Spire.PDF for Java supports converting HTML to PDF using the Chrome plugin; Spire.OCR for Java supports scanning image streams. Moreover, many known bugs are fixed in this update successfully. More details are listed below.
Here is a list of changes made in this release
Spire.Doc for Java
| Category | ID | Description |
| Bug | SPIREDOC-10795 | Fixes issue that the TOC field was updated incorrectly. |
| Bug | SPIREDOC-10800 | Fixes the issue that the Chinese characters were garbled after converting Markdown to Word. |
| Bug | SPIREDOC-10801 | Fixes the issue that the list numbers were lost after converting Markdown to Word. |
Spire.Presentation for Java
| Category | ID | Description |
| New feature | SPIREPPT-2573 | Supports the FindFirstTextAsRange method for finding the first occurrence of text.
Presentation ppt = new Presentation();
ppt.loadFromFile(inputFile);
String text = "create, read";
PortionEx textRange=ppt.getSlides().get(0).FindFirstTextAsRange(text);
textRange.getFill().setFillType(FillFormatType.SOLID);
textRange.getFill().getSolidColor().setColor(Color.red);
textRange.setFontHeight(28);
textRange.setLatinFont(new TextFont("Arial"));
textRange.isBold(TriState.TRUE);
textRange.isItalic(TriState.TRUE);
textRange.setTextUnderlineType(TextUnderlineType.DOUBLE);
textRange.setTextStrikethroughType(TextStrikethroughType.SINGLE);
ppt.saveToFile(outputFile, FileFormat.PPTX_2016);
ppt.dispose();
|
| Bug | SPIREPPT-2614 | Fixes the issue that the program threw the NullPointerException exception when loading PPTX documents. |
| Bug | SPIREPPT-2616 SPIREPPT-2617 |
Fixes the issue that incorrect content occurred when converting PPTX documents to images. |
Spire.PDF for Java
| Category | ID | Description |
| New feature | SPIREPDF-7017 | Supports returning error document information when merging documents reports errors. |
| New feature | SPIREPDF-7120 | Synchronizes the ToPdfX1A2001() method under the PdfStandardsConverter class to Java. |
| New feature | SPIREPDF-6972 | Supports converting HTML to PDF using the Chrome plugin. Supported systems: Windows & Linux.
ChromeHtmlConverter converter = new ChromeHtmlConverter(TestUtil.ChromiumPath); URI uri = new URI(converter.getUrl()); IWebSocketService webSocketService = (IWebSocketService) WebSocketServiceImpl.create(uri); converter.setWebSocketService(webSocketService); ConvertOptions options = new ConvertOptions(); options.setTimeout(10 * 1000); PageSettings pageSettings = new PageSettings(); pageSettings.setPaperFormat(8);//A4 pageSettings.setMarginBottom(0); pageSettings.setMarginTop(0); pageSettings.setMarginLeft(0); pageSettings.setMarginRight(0); options.setPageSettings(pageSettings); converter.convertToPdf(inputPath, OutputPath, options); |
| New feature | SPIREPDF-7094 | Supports output of logs through the Logger class when using the Chrome plugin to convert HTML to PDF.
ChromeHtmlConverter converter = new ChromeHtmlConverter(TestUtil.ChromiumPath); converter.setLogger(new Logger(OutputPath_TXT)); // Save logs to a txt file converter.getLogger().setEnabled(true); // Print logs to the console |
| Bug | SPIREPDF-7029 | Fixes the issue that the red seal became black after encrypting PDF documents. |
| Bug | SPIREPDF-7033 | Fixes the issue that the program threw "Unknown Target Area Type: Fit_H" exception when converting PDF to OFD. |
| Bug | SPIREPDF-6958 | Fixes the issue that the effect of converting HTML to PDF was incorrect. |
| Bug | SPIREPDF-7064 | Fixes the issue that the program threw "Value cannot be null" exception when merging documents. |
| Bug | SPIREPDF-7087 | Fixes the issue that it failed to convert HTML to PDF over 1.2MB in size. |
| Bug | SPIREPDF-7089 | Fixes the issue that the text of tables was messed up after converting PDF to images. |
| Bug | SPIREPDF-7090 | Fixes the issue that the contents were cut off from the page breaks when converting HTML to PDF. |
| Bug | SPIREPDF-7091 | Fixes the issue that the program hung when converting HTML to PDF. |
| Bug | SPIREPDF-7113 | Fixes the issue that the tool alerted that there were errors in the document content after drawing SVG on PDF layers and opening the resulting document in Adobe tools. |
| Bug | SPIREPDF-7127 | Fixes the issue that the program threw an exception of "Unknown Color Space Type" when converting OFD to PDF. |
| Bug | SPIREPDF-7128 | Fixes the issue that setting the customized properties of attachments did not take effect. |
| Bug | SPIREPDF-7130 | Fixes the issue that the program threw "For input string: 'CM'" exception when converting OFD to PDF. |
Spire.OCR for Java
| Category | ID | Description |
| New feature | - | Supports a new module for OCR usage.
OcrScanner scanner = new OcrScanner();
//ConfigureOptions configureOptions = new ConfigureOptions("D:\\Models\\java\\Java\\win-x64\\","English");
ConfigureOptions configureOptions = new ConfigureOptions();
configureOptions.setLanguage("English");
configureOptions.setModelPath("D:\\Models\\java\\Java\\win-x64\\");
scanner.ConfigureDependencies(configureOptions);
scanner.scan(imageFile);
String scannedText=scanner.getText().toString();
System.out.println(scannedText);
|
| New feature | SPIREOCR-57 SPIREOCR-63 |
Supports scanning image streams.
InputStream stream = new FileInputStream(sourceFolder); scanner.Scan(stream, OCRImageFormat.Gif); |
| Bug | SPIREOCR-59 | Fixes the issue that image recognition threw an exception on Ubuntu system. |
| Bug | SPIREOCR-76 | Fixes the issue that image data recognition was incorrect. |
Spire.PDF for Java 10.10.7 supports converting HTML to PDF using the Chrome plugin
We are excited to announce the release of Spire.PDF for Java 10.10.7. This version supports converting HTML to PDF using the Chrome plugin. It also enhances the conversion from PDF to images as well as HTML, SVG, and OFD to PDF. Moreover, a lot of known issues are fixed successfully in this version, such as the issue that setting custom properties for attachments did not take effect. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-7120 | Synchronizes the ToPdfX1A2001() method under the PdfStandardsConverter class to Java. |
| New feature | SPIREPDF-6972 | Supports converting HTML to PDF using the Chrome plugin. Supported systems: Windows & Linux.
ChromeHtmlConverter converter = new ChromeHtmlConverter(TestUtil.ChromiumPath); URI uri = new URI(converter.getUrl()); IWebSocketService webSocketService = (IWebSocketService) WebSocketServiceImpl.create(uri); converter.setWebSocketService(webSocketService); ConvertOptions options = new ConvertOptions(); options.setTimeout(10 * 1000); PageSettings pageSettings = new PageSettings(); pageSettings.setPaperFormat(8);//A4 pageSettings.setMarginBottom(0); pageSettings.setMarginTop(0); pageSettings.setMarginLeft(0); pageSettings.setMarginRight(0); options.setPageSettings(pageSettings); converter.convertToPdf(inputPath, OutputPath, options); |
| New feature | SPIREPDF-7094 | Supports output of logs through the Logger class when using the Chrome plugin to convert HTML to PDF.
ChromeHtmlConverter converter = new ChromeHtmlConverter(TestUtil.ChromiumPath); converter.setLogger(new Logger(OutputPath_TXT)); // Save logs to a txt file converter.getLogger().setEnabled(true); // Print logs to the console |
| Bug | SPIREPDF-6958 | Fixes the issue that the effect of converting HTML to PDF was incorrect. |
| Bug | SPIREPDF-7064 | Fixes the issue that the program threw "Value cannot be null" exception when merging documents. |
| Bug | SPIREPDF-7087 | Fixes the issue that it failed to convert HTML to PDF over 1.2MB in size. |
| Bug | SPIREPDF-7089 | Fixes the issue that the text of tables was messed up after converting PDF to images. |
| Bug | SPIREPDF-7090 | Fixes the issue that the contents were cut off from the page breaks when converting HTML to PDF. |
| Bug | SPIREPDF-7091 | Fixes the issue that the program hung when converting HTML to PDF. |
| Bug | SPIREPDF-7113 | Fixes the issue that the tool alerted that there were errors in the document content after drawing SVG on PDF layers and opening the resulting document in Adobe tools. |
| Bug | SPIREPDF-7127 | Fixes the issue that the program threw an exception of "Unknown Color Space Type" when converting OFD to PDF. |
| Bug | SPIREPDF-7128 | Fixes the issue that setting the customized properties of attachments did not take effect. |
| Bug | SPIREPDF-7130 | Fixes the issue that the program threw "For input string: 'CM'" exception when converting OFD to PDF. |
Python: Set, Update, and Get Cell Values in Excel Worksheets
The Excel workbook, as a widely used data management tool, can be combined with Python to enable the automation of large-scale data processing. Using Python to set, update, and read cell values in Excel can significantly improve work efficiency, reduce repetitive tasks, and enhance the flexibility and scalability of data processing workflows, thus creating added value. This approach is applicable across a range of fields, from automating financial reports to generating data analysis reports, and can greatly boost productivity in various work contexts.
This article will demonstrate how to set, update, and retrieve cell values in Excel files using Spire.XLS for Python.
- Set cell values in Excel Files with Python
- Update cell values in Excel Files with Python
- Retrieve cell values in Excel Files with Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.XLS
If you are unsure how to install, please refer to: How to Install Spire.XLS for Python on Windows
Set cell values in Excel Files with Python
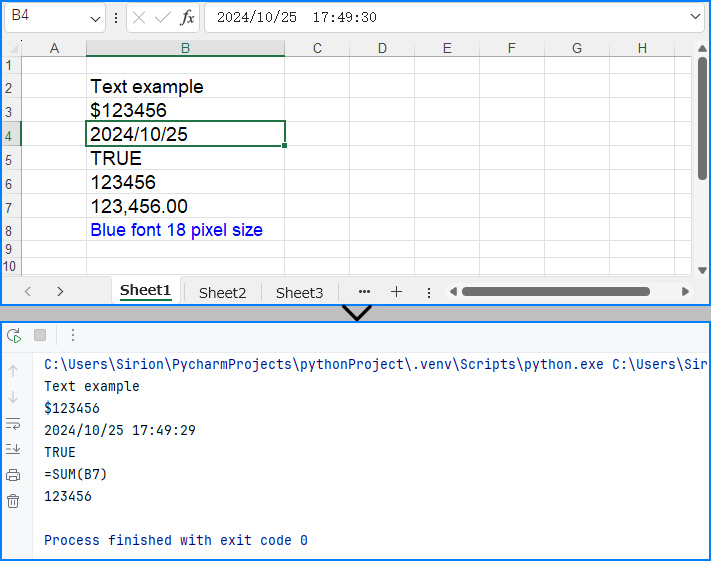
We can use the Worksheet.Range.get_Item() method from Spire.XLS for Python to obtain a specified cell in an Excel worksheet as a CellRange object, such as Range.get_Item(2, 1) or Range.get_Item("A2") (row 2, column 1). Then, we can use the CellRange.Value property to set the cell value, or other properties within this class to set text, numbers, boolean values, and other types of data. The following is an example of the procedure:
- Create a Workbook object.
- Get the first default worksheet using Workbook.Worksheets.get_Item() method.
- Obtain the specified cell as a CellRange object using Worksheet.Range.get_Item() method.
- Use properties within the CellRange class, such as Text, Value, DateTimeValue, Formula, and NumberValue, to set cell values.
- Format the cells.
- Save the workbook using Workbook.SaveToFile().
- Python
from spire.xls import Workbook, FileFormat, DateTime, HorizontalAlignType
import datetime
# Create an instance of Workbook to create an Excel workbook
workbook = Workbook()
# Get the first default worksheet
sheet = workbook.Worksheets.get_Item(0)
# Get cell and set text
cell = sheet.Range.get_Item(2, 2)
cell.Text = "Text example"
# Get cell and set a regular value
cell1 = sheet.Range.get_Item(3, 2)
cell1.Value = "$123456"
# Get cell and set a date value
cell2 = sheet.Range.get_Item(4, 2)
cell2.DateTimeValue = DateTime.get_Now()
# Get cell and set a boolean value
cell3 = sheet.Range.get_Item(5, 2)
cell3.BooleanValue = True
# Get cell and set a formula
cell4 = sheet.Range.get_Item(6, 2)
cell4.Formula = "=SUM(B7)"
# Get cell, set a number value, and set number format
cell5 = sheet.Range.get_Item(7, 2)
cell5.NumberValue = 123456
cell5.NumberFormat = "#,##0.00"
# Get cell and set a formula array
cell6 = sheet.Range.get_Item(8, 2)
cell6.HtmlString = "<p><span style='color: blue; font-size: 18px;'>Blue font 18 pixel size</span></p>"
# Set formatting
cellRange = sheet.Range.get_Item(2, 2, 7, 2)
cellRange.Style.Font.FontName = "Arial"
cellRange.Style.Font.Size = 14
cellRange.Style.HorizontalAlignment = HorizontalAlignType.Left
# Auto-fit the column width
sheet.AutoFitColumn(2)
# Save the file
workbook.SaveToFile("output/SetExcelCellValue.xlsx", FileFormat.Version2016)
workbook.Dispose()
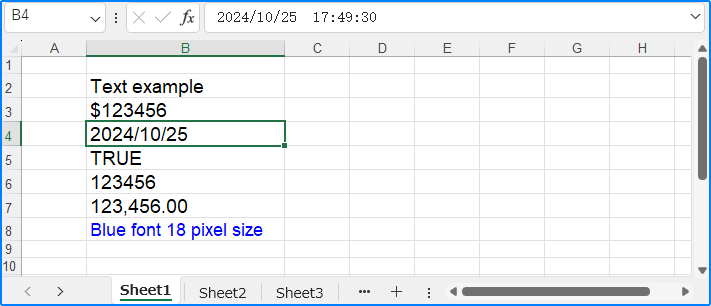
Update cell values in Excel Files with Python
To update a cell value in Excel, we can retrieve the cell to update and use the same approach as above to reset its value, thus updating the cell value. Below is an example of the procedure:
- Create a Workbook object.
- Load the Excel file using Workbook.LoadFromFile() method.
- Get a worksheet using Workbook.Worksheets.get_Item() method.
- Obtain the cell to update using Worksheet.Range.get_Item() method.
- Use properties under the CellRange class to reset the cell value.
- Save the workbook with Workbook.SaveToFile() method.
- Python
from spire.xls import Workbook
# Create an instance of Workbook
workbook = Workbook()
# Load the Excel file
workbook.LoadFromFile("output/SetExcelCellValue.xlsx")
# Get the worksheet
sheet = workbook.Worksheets.get_Item(0)
# Get the cell
cell = sheet.Range.get_Item(2, 2)
# Change the cell value to a number
cell.NumberValue = 45150
# Set the cell number format
cell.NumberFormat = "[Green]#,##0;[RED]-#,##0"
# Save the workbook
workbook.SaveToFile("output/UpdateExcelCellValue.xlsx")
workbook.Dispose()
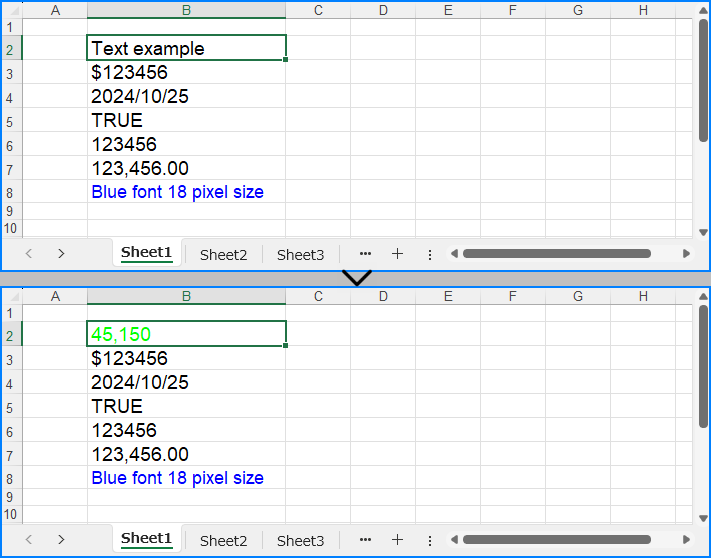
Retrieve cell values in Excel Files with Python
The CellRange.Value property can also be used to directly read cell values. Below is an example of the procedure to read cell values in Excel files:
- Create a Workbook object.
- Load the Excel file with Workbook.LoadFromFile() method.
- Get a worksheet using Workbook.Worksheets.get_Item() method.
- Loop through the specified cell range and use the CellRange.Value property to get the cell value.
- Print the results.
- Python
from spire.xls import Workbook
# Create an instance of Workbook
workbook = Workbook()
# Load the Excel file
workbook.LoadFromFile("output/SetExcelCellValue.xlsx")
# Get the worksheet
sheet = workbook.Worksheets.get_Item(0)
# Loop through cells from row 2 to 8 in column 2
for i in range(2, 8):
# Get the cell
cell = sheet.Range.get_Item(i, 2)
# Get the cell value
value = cell.Value
# Output the value
print(value)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Get or Replace Used Fonts in PDF
PDFs often use a variety of fonts and there are situations where you may need to get or replace these fonts. For instance, getting fonts allows you to inspect details such as font name, size, type, and style, which is especially useful for maintaining design consistency or adhering to specific standards. On the other hand, replacing fonts can help address compatibility issues, particularly when the original fonts are not supported on certain devices or software. In this article, we will explain how to get and replace the used fonts in PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Get Used Fonts in PDF in Python
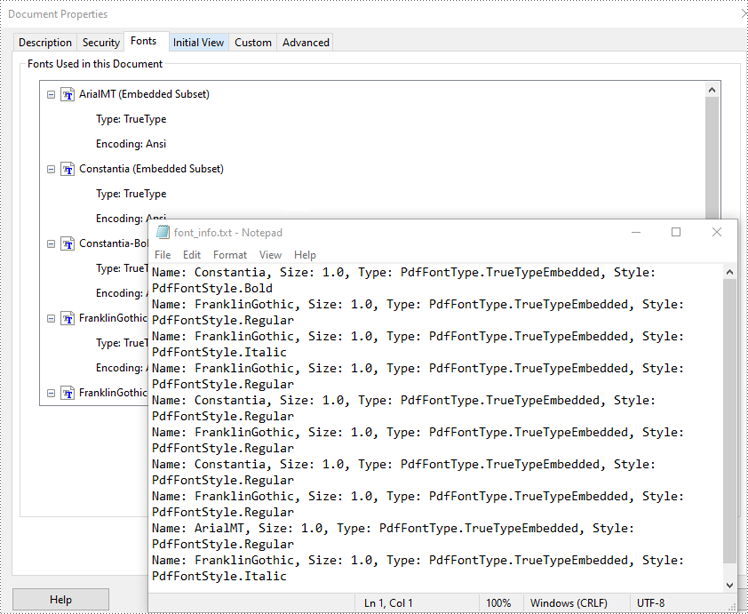
Spire.PDF for Python provides the PdfDocument.UsedFonts property to retrieve a list of all fonts used in a PDF. By iterating through this list, you can easily access detailed font information such as the font name, size, type and style using the PdfUsedFont.Name, PdfUsedFont.Size, PdfUsedFont.Type and PdfUsedFont.Style properties. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the list of fonts used in this document using the PdfDocument.UsedFonts property.
- Create a text file to save the extracted font information.
- Iterate through the font list.
- Get the information of each font, such as font name, size, type and style using the PdfUsedFont.Name, PdfUsedFont.Size, PdfUsedFont.Type and PdfUsedFont.Style properties, and save it to the text file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Input1.pdf")
# Get the list of fonts used in this document
usedFonts = pdf.UsedFonts
# Create a text file to save the extracted font information
with open("font_info.txt", "w") as file:
# Iterate through the font list
for font in usedFonts:
# Get the information of each font, such as font name, size, type and style
font_info = f"Name: {font.Name}, Size: {font.Size}, Type: {font.Type}, Style: {font.Style}\n"
file.write(font_info)
pdf.Close()
Replace Used Fonts in PDF in Python
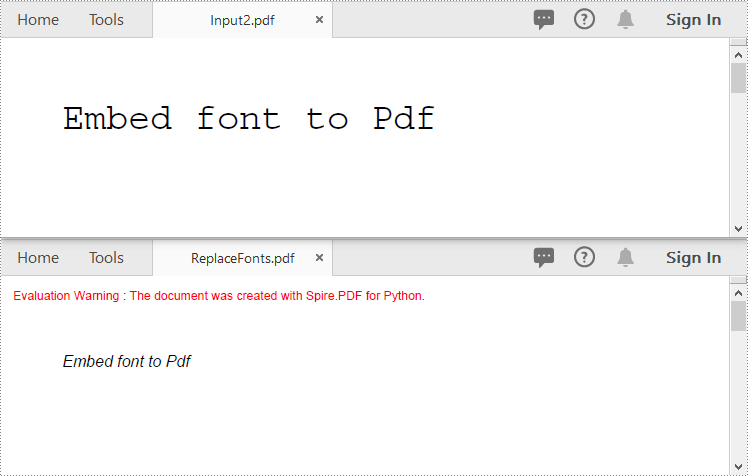
You can replace the fonts used in a PDF with the desired font using the PdfUsedFont.Replace() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the list of fonts used in this document using the PdfDocument.UsedFonts property.
- Create a new font using the PdfTrueTypeFont class.
- Iterate through the font list.
- Replace each used font with the new font using the PdfUsedFont.Replace() method.
- Save the resulting document to a new PDF using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Input2.pdf")
# Get the list of fonts used in this document
usedFonts = pdf.UsedFonts
# Create a new font
newFont = PdfTrueTypeFont("Arial", 13.0, PdfFontStyle.Italic ,True)
# Iterate through the font list
for font in usedFonts:
# Replace each font with the new font
font.Replace(newFont)
# Save the resulting document to a new PDF
pdf.SaveToFile("ReplaceFonts.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.OCR for Java 1.9.19 supports scanning image stream
We are excited to announce the release of the Spire.OCR for Java 1.9.19. The latest version supports scanning image streams and adds a new module for OCR usage. Besides, some known bugs are successfully fixed in this update, such as the issue that image recognition threw an exception on Ubuntu system. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Supports a new module for OCR usage.
OcrScanner scanner = new OcrScanner();
//ConfigureOptions configureOptions = new ConfigureOptions("D:\\Models\\java\\Java\\win-x64\\","English");
ConfigureOptions configureOptions = new ConfigureOptions();
configureOptions.setLanguage("English");
configureOptions.setModelPath("D:\\Models\\java\\Java\\win-x64\\");
scanner.ConfigureDependencies(configureOptions);
scanner.scan(imageFile);
String scannedText=scanner.getText().toString();
System.out.println(scannedText);
|
| New feature | SPIREOCR-57 SPIREOCR-63 |
Supports scanning image streams.
InputStream stream = new FileInputStream(sourceFolder); scanner.Scan(stream, OCRImageFormat.Gif); |
| Bug | SPIREOCR-59 | Fixes the issue that image recognition threw an exception on Ubuntu system. |
| Bug | SPIREOCR-76 | Fixes the issue that image data recognition was incorrect. |