
Text (4)
PDFs often use a variety of fonts and there are situations where you may need to get or replace these fonts. For instance, getting fonts allows you to inspect details such as font name, size, type, and style, which is especially useful for maintaining design consistency or adhering to specific standards. On the other hand, replacing fonts can help address compatibility issues, particularly when the original fonts are not supported on certain devices or software. In this article, we will explain how to get and replace the used fonts in PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Get Used Fonts in PDF in Python
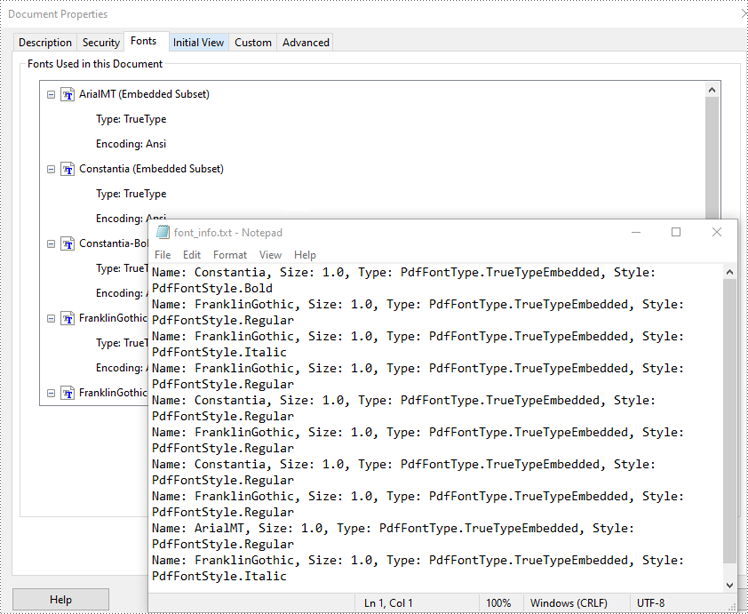
Spire.PDF for Python provides the PdfDocument.UsedFonts property to retrieve a list of all fonts used in a PDF. By iterating through this list, you can easily access detailed font information such as the font name, size, type and style using the PdfUsedFont.Name, PdfUsedFont.Size, PdfUsedFont.Type and PdfUsedFont.Style properties. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the list of fonts used in this document using the PdfDocument.UsedFonts property.
- Create a text file to save the extracted font information.
- Iterate through the font list.
- Get the information of each font, such as font name, size, type and style using the PdfUsedFont.Name, PdfUsedFont.Size, PdfUsedFont.Type and PdfUsedFont.Style properties, and save it to the text file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Input1.pdf")
# Get the list of fonts used in this document
usedFonts = pdf.UsedFonts
# Create a text file to save the extracted font information
with open("font_info.txt", "w") as file:
# Iterate through the font list
for font in usedFonts:
# Get the information of each font, such as font name, size, type and style
font_info = f"Name: {font.Name}, Size: {font.Size}, Type: {font.Type}, Style: {font.Style}\n"
file.write(font_info)
pdf.Close()
Replace Used Fonts in PDF in Python
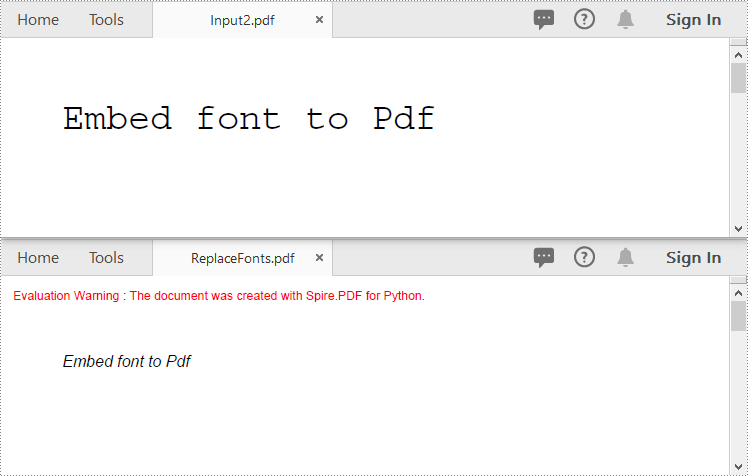
You can replace the fonts used in a PDF with the desired font using the PdfUsedFont.Replace() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the list of fonts used in this document using the PdfDocument.UsedFonts property.
- Create a new font using the PdfTrueTypeFont class.
- Iterate through the font list.
- Replace each used font with the new font using the PdfUsedFont.Replace() method.
- Save the resulting document to a new PDF using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Input2.pdf")
# Get the list of fonts used in this document
usedFonts = pdf.UsedFonts
# Create a new font
newFont = PdfTrueTypeFont("Arial", 13.0, PdfFontStyle.Italic ,True)
# Iterate through the font list
for font in usedFonts:
# Replace each font with the new font
font.Replace(newFont)
# Save the resulting document to a new PDF
pdf.SaveToFile("ReplaceFonts.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Using Python to manipulate text formatting in PDFs provides a powerful way to automate and customize documents. With the Spire.PDF for Python library, developers can efficiently find text with advanced search options to retrieve and modify text properties like font, size, color, and style, enabling users to find and update text formatting across large document sets, saving time and reducing manual work. This article will demonstrate how to use Spire.PDF for Python to retrieve and modify text formatting in PDF documents with Python code.
- Find Text and Retrieve the Font Information in PDFs
- Find and Modify Text Formatting in PDF Documents
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Find Text and Retrieve Formatting Information in PDFs
Developers can use the PdfTextFinder and PdfTextFindOptions classes provided by Spire.PDF for Python to precisely search for specific text in a PDF document and obtain a collection of PdfTextFragment objects representing the search results. Then, developers can access the format information of the specified search result text through properties such as FontName, FontSize, and FontFamily, under PdfTextFragment.TextStates[] property.
The detailed steps for finding text in PDF and retrieving its font information are as follows:
- Create an instance of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfTextFinder object using the page.
- Create a PdfTextFindOptions object, set the search options, and apply the search options through PdfTextFinder.Options property.
- Find specific text on the page using PdfTextFinder.Find() method and get a collection of PdfTextFragment objects.
- Get the formatting of the first finding result through PdfTextFragment.TextStates property.
- Get the font name, font size, and font family of the result through PdfTextStates[0].FontName, PdfTextStates[0].FontSize, and PdfTextStates[0].FontFamily properties.
- Print the result.
- Python
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Create a PdfTextFinder instance
finder = PdfTextFinder(page)
# Create a PdfTextFindOptions instance and set the search options
options = PdfTextFindOptions()
options.CaseSensitive = True
options.WholeWords = True
# Apply the options
finder.Options = options
# Find the specified text
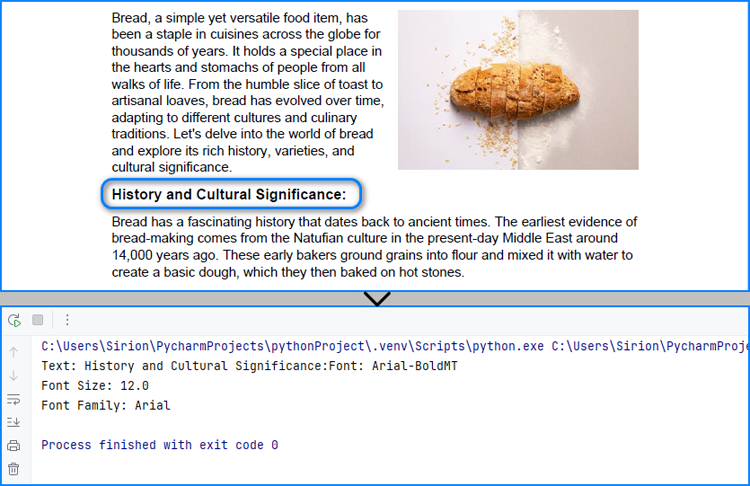
fragments = finder.Find("History and Cultural Significance:")
# Get the formatting of the first fragment
formatting = fragments[0].TextStates
# Get the formatting information
fontInfo = ""
fontInfo += "Text: " + fragments[0].Text
fontInfo += "Font: " + formatting[0].FontName
fontInfo += "\nFont Size: " + str(formatting[0].FontSize)
fontInfo += "\nFont Family: " + formatting[0].FontFamily
# Output font information
print(fontInfo)
# Release resources
pdf.Dispose()
Find and Modify Text Formatting in PDF Documents
After finding specific text, developers can overlay it with a rectangle in the same color as the background and then redraw the text in a new format at the same position, thus achieving text format modification of simple PDF text fragments on solid color pages. The detailed steps are as follows:
- Create an instance of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfTextFinder object using the page.
- Create a PdfTextFindOptions object, set the search options, and apply the search options through PdfTextFinder.Options property.
- Find specific text on the page using PdfTextFinder.Find() method and get the first result.
- Get the color of the page background through PdfPageBase.BackgroundColor property and change the color to white if the background is empty.
- Draw rectangles with the obtained color in the position of the found text using PdfPageBase.Canvas.DrawRectangle() method.
- Create a new font, brush, and string format and calculate the text frame.
- Draw the text in the new format in the same position using PdfPageBase.Canvas.DrawString() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Create a PdfTextFinder instance
finder = PdfTextFinder(page)
# Create a PdfTextFindOptions instance and set the search options
options = PdfTextFindOptions()
options.CaseSensitive = True
options.WholeWords = True
finder.Options = options
# Find the specified text
fragments = finder.Find("History and Cultural Significance:")
# Get the first result
fragment = fragments[0]
# Get the background color and change it to white if its empty
backColor = page.BackgroundColor
if backColor.ToArgb() == 0:
backColor = Color.get_White()
# Draw a rectangle with the background color to cover the text
for i in range(len(fragment.Bounds)):
page.Canvas.DrawRectangle(PdfSolidBrush(PdfRGBColor(backColor)), fragment.Bounds[i])
# Create a new font and a new brush
font = PdfTrueTypeFont("Times New Roman", 16.0, 3, True)
brush = PdfBrushes.get_Brown()
# Create a PdfStringFormat instance
stringFormat = PdfStringFormat()
stringFormat.Alignment = PdfTextAlignment.Left
# Calculate the rectangle that contains the text
point = fragment.Bounds[0].Location
size = SizeF(fragment.Bounds[-1].Right, fragment.Bounds[-1].Bottom)
rect = RectangleF(point, size)
# Draw the text with the specified format in the same rectangle
page.Canvas.DrawString("History and Cultural Significance", font, brush, rect, stringFormat)
# Save the document
pdf.SaveToFile("output/FindModifyTextFormat.pdf")
# Release resources
pdf.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Finding and replacing text is a common need in document editing, as it helps users correct minor errors or make adjustments to terms appearing in the document. Although PDF documents have a fixed layout and editing can be challenging, users can still perform small modifications such as replacing text with Python, and achieve a satisfactory editing result. In this article, we will explore how to utilize Spire.PDF for Python to find and replace text in PDF documents within a Python program.
- Find Text and Replace the First Match in PDF with Python
- Find Text and Replace All Matches in PDF with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Find Text and Replace the First Match in PDF with Python
Spire.PDF for Python enables users to find text and replace the first match in PDF documents with the PdfTextReplacer.ReplaceText(string originalText, string newText) method. This replacement method is great for making simple replacements for words or phrases that only appear once on a single page of a document.
The detailed steps for finding text and replacing the first match are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page of the document using PdfDocument.Pages.get_Item() method.
- Create an object of PdfTextReplacer class based on the page.
- Find specific text and replace the first match on the page using PdfTextReplacer.ReplaceText() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Sample.pdf")
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextReplacer class
replacer = PdfTextReplacer(page)
# Find and replace the first matched text
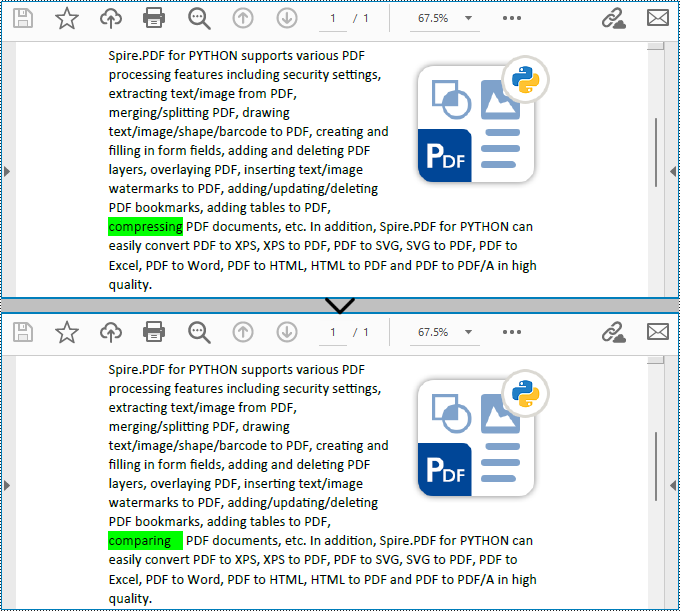
replacer.ReplaceText("compressing", "comparing")
# Save the document
pdf.SaveToFile("output/ReplaceFirstMatch.pdf")
pdf.Close()
Find Text and Replace All Matches in PDF with Python
Spire.PDF for Python also provides the PdfTextReplacer.ReplaceAllText(string originalText, string newText, Color textColor) method to find specific text and replace all matches with new text (optionally resetting the text color). The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Loop through the pages in the document.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create an object of PdfTextReplacer class based on the page.
- Find specific text and replace all the matches with new text in a new color using PdfTextReplacer.ReplaceAllText() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Sample.pdf")
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextReplacer class based on the page
replacer = PdfTextReplacer(page)
# Find and replace all matched text with a new color
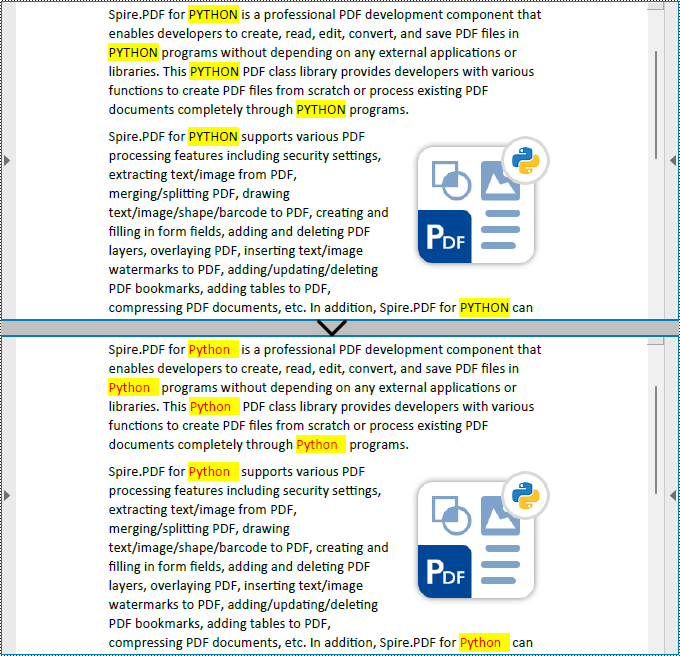
replacer.ReplaceAllText("PYTHON", "Python", Color.get_Red())
# Save the document
pdf.SaveToFile("output/ReplaceAllMatches.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Highlighting important text with vibrant colors is a commonly employed method for navigating and emphasizing content in PDF documents. Particularly in lengthy PDFs, emphasizing key information aids readers swiftly comprehending the document content, thereby enhancing reading efficiency. Utilizing Python programs enables document creators to effortlessly and expeditiously execute the highlighting process. This article will explain how to use Spire.PDF for Python to find and highlight text in PDF documents with Python programs.
- Find and Highlight Specific Text in PDF with Python
- Find and Highlight Text in a Specified PDF Page Area with Python
- Find and Highlight Text in PDF using Regular Expression with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Find and Highlight Specific Text in PDF with Python
Spire.PDF for Python enables developers to find all occurrences of specific text on a page with PdfPageBase.FindText() method and apply highlight color to an occurrence with ApplyHighLight() method. Below is an example of using Spire.PDF for Python to highlight all occurrence of specific text:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Loop through the pages in the document.
- Get a page using PdfDocument.Pages.get_Item() method.
- Find all occurrences of specific text on the page using PdfPageBase.FindText() method.
- Loop through the occurrences and apply a highlight color to each occurrence using ApplyHighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import*
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Loop through the pages in the PDF document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Find all occurrences of specific text on the page
result = page.FindText("cloud server", TextFindParameter.IgnoreCase).Finds
# Highlight all the occurrences
for text in result:
text.ApplyHighLight(Color.get_Cyan())
# Save the document
pdf.SaveToFile("output/FindHighlight.pdf")
pdf.Close()

Find and Highlight Text in a Specified PDF Page Area with Python
In addition to finding and highlighting specified text on the entire PDF page, Spire.PDF for Python also supports finding and highlighting specified text in specified areas on the page by passing a RectangleF instance as parameter to the PdfPageBase.FindText() method. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first page of the document using PdfDocument.Pages.get_Item() method.
- Define a rectangular area.
- Find all occurrences of specific text in the specified rectangular area on the first page using PdfPageBase.FindText() method.
- Loop through the occurrences and apply a highlight color to each occurrence using ApplyHighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an objetc of PdfDocument and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get a page
pdfPageBase = pdf.Pages.get_Item(0)
# Define a rectangular area
rctg = RectangleF(0.0, 0.0, pdfPageBase.ActualSize.Width, 300.0)
# Find all the occurrences of specified text in the rectangular area
findCollection = pdfPageBase.FindText(rctg,"cloud server",TextFindParameter.IgnoreCase)
# Find text in the rectangle
for find in findCollection.Finds:
#Highlight searched text
find.ApplyHighLight(Color.get_Green())
# Save the document
pdf.SaveToFile("output/FindHighlightArea.pdf")
pdf.Close()

Find and Highlight Text in PDF using Regular Expression with Python
Sometimes the text that needs to be highlighted is not exactly the same words. In this case, the use of regular expressions allows more flexibility in text search. By passing TextFindParameter.Regex as parameter to the PdfPageBase.FindText() method, we can find text using regular expression in PDF documents. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Specify the regular expression.
- Get a page using PdfDocument.Pages.get_Item() method.
- Find matched text with the regular expression on the page using PdfPageBase.FindText() method.
- Loop through the matched text and apply Highlight color to the text using ApplyHighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import*
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Specify the regular expression that matches two words after *
regex = "\\*(\\w+\\s+\\w+)"
# Get the second page
page = pdf.Pages.get_Item(1)
# Find matched text on the page using regular expression
result = page.FindText(regex, TextFindParameter.Regex)
# Highlight the matched text
for text in result.Finds:
text.ApplyHighLight(Color.get_DeepPink())
# Save the document
pdf.SaveToFile("output/FindHighlightRegex.pdf")

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
