

Finding and replacing text is a common need in document editing, as it helps users correct minor errors or make adjustments to terms appearing in the document. Although PDF documents have a fixed layout and editing can be challenging, users can still perform small modifications such as replacing text with Python, and achieve a satisfactory editing result. In this article, we will explore how to utilize Spire.PDF for Python to find and replace text in PDF documents within a Python program.
- Find Text and Replace the First Match in PDF with Python
- Find Text and Replace All Matches in PDF with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Find Text and Replace the First Match in PDF with Python
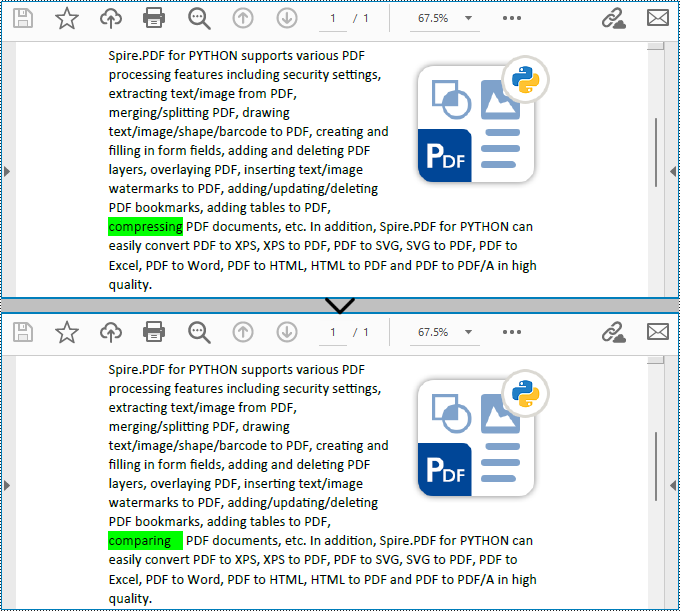
Spire.PDF for Python enables users to find text and replace the first match in PDF documents with the PdfTextReplacer.ReplaceText(string originalText, string newText) method. This replacement method is great for making simple replacements for words or phrases that only appear once on a single page of a document.
The detailed steps for finding text and replacing the first match are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page of the document using PdfDocument.Pages.get_Item() method.
- Create an object of PdfTextReplacer class based on the page.
- Find specific text and replace the first match on the page using PdfTextReplacer.ReplaceText() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Sample.pdf")
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextReplacer class
replacer = PdfTextReplacer(page)
# Find and replace the first matched text
replacer.ReplaceText("compressing", "comparing")
# Save the document
pdf.SaveToFile("output/ReplaceFirstMatch.pdf")
pdf.Close()
Find Text and Replace All Matches in PDF with Python
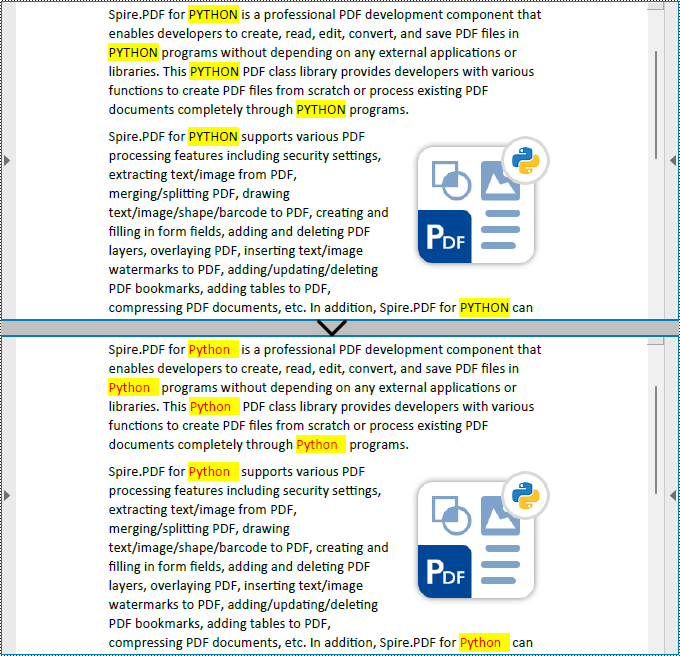
Spire.PDF for Python also provides the PdfTextReplacer.ReplaceAllText(string originalText, string newText, Color textColor) method to find specific text and replace all matches with new text (optionally resetting the text color). The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Loop through the pages in the document.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create an object of PdfTextReplacer class based on the page.
- Find specific text and replace all the matches with new text in a new color using PdfTextReplacer.ReplaceAllText() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Sample.pdf")
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextReplacer class based on the page
replacer = PdfTextReplacer(page)
# Find and replace all matched text with a new color
replacer.ReplaceAllText("PYTHON", "Python", Color.get_Red())
# Save the document
pdf.SaveToFile("output/ReplaceAllMatches.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

