
Starting from version 1.9.15, Spire.OCR for Java provides a new model for extracting text from images. In this article, we will demonstrate how to use this new model to extract text from images in Java.
The detailed steps are as follows.
Step 1: Create a Java Project in IntelliJ IDEA.
Step 2: Add Spire.OCR.jar to Your Project.
Option 1: Install Spire.OCR for Java via Maven.
If you're using Maven, you can install Spire.OCR for Java by adding the following code to your project's pom.xml file:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.ocr</artifactId>
<version>1.9.15</version>
</dependency>
</dependencies>
Option 2: Manually Import Spire.OCR.jar.
First, download Spire.OCR for Java from the following link and extract it to a specific directory:
https://www.e-iceblue.com/Download/ocr-for-java.html
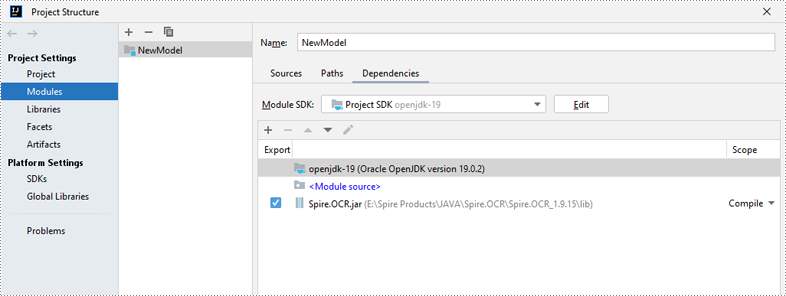
Next, in IntelliJ IDEA, go to File > Project Structure > Modules > Dependencies. In the Dependencies pane, click the "+" button and select JARs or Directories. Navigate to the directory where Spire.OCR for Java is located, open the lib folder and select the Spire.OCR.jar file, then click OK to add it as the project’s dependency.
Step 3: Download the New Model and Associated Dependencies of Spire.OCR for Java.
Download the new model and associated dependencies (Model&Lib.zip) from the following link and extract the package to a specific directory, such as D:\.
https://www.e-iceblue.com/resource/ocr_java/Model&Lib.zip
Step 4: Implement Text Extraction from Images Using the New Model of Spire.OCR for Java.
Use the following code to extract text from images with the new OCR model of Spire.OCR for Java:
- Java
import com.spire.ocr.*;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
try {
// Initialize the OcrScanner instance
OcrScanner scanner = new OcrScanner();
// Configure OCR options
// Set the path to the new model and the language for text recognition. Supported languages include English, Chinese, Chinesetraditional, French, German, Japanese, and Korean.
ConfigureOptions configureOptions = new ConfigureOptions("D:\\Model&Lib\\Model", "English");
// Set the path to the associated dependencies
configureOptions.setLibPath("D:\\Model&Lib\\Lib\\win-x64");
scanner.ConfigureDependencies(configureOptions);
// Perform text extraction from the image
scanner.scan("Sample.png");
// Save the extracted text to a file
saveTextToFile(scanner, "output.txt");
} catch (OcrException e) {
e.printStackTrace();
}
}
private static void saveTextToFile(OcrScanner scanner, String filePath) {
try {
String text = scanner.getText().toString();
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath))) {
writer.write(text);
}
} catch (IOException | OcrException e) {
e.printStackTrace();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

