
Document Operation (11)
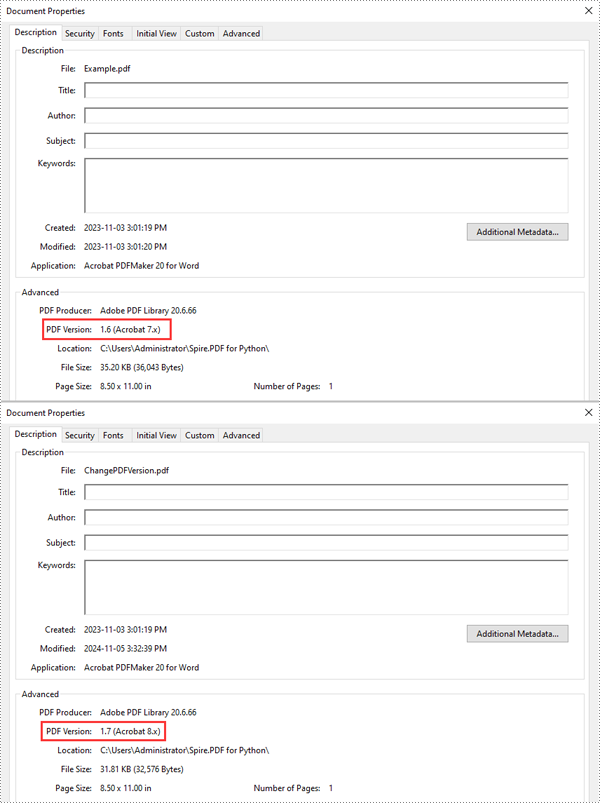
PDF files have different versions, each with unique features and compatibility standards. Changing the version of a PDF can be important when specific versions are required for compatibility with certain devices, software, or regulatory requirements. For instance, you may need to use an older PDF version when archiving or sharing files with users using older software. This article will introduce how to change the version of a PDF document in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Change PDF Version in Python
Spire.PDF for Python supports PDF versions ranging from 1.0 to 1.7. To convert a PDF file to a different version, simply set the desired version using the PdfDocument.FileInfo.Version property. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF document using the PdfDocument.LoadFromFile() method.
- Change the version of the PDF document to a newer or older version using the PdfDocument.FileInfo.Version property.
- Save the resulting document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Example.pdf")
# Change the version of the PDF to version 1.7
pdf.FileInfo.Version = PdfVersion.Version1_7
# Save the resulting document
pdf.SaveToFile("ChangePDFVersion.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Setting view preferences in PDF documents is a crucial feature that can significantly enhance user experience. By configuring options like page layout, display mode, and zoom level, you ensure recipients view the document as intended, without manual adjustments. This is especially useful for business reports, design plans, or educational materials, where consistent presentation is crucial for effectively delivering information and leaving a professional impression. This article will show how to set view preferences of PDF documents with Python code using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Set PDF Viewer Preferences with Python
Viewer preferences allow document creators to define how a PDF document is displayed when opened, including page layout, window layout, and display mode. Developers can use the properties under ViewerPreferences class to set those display options. The detailed steps are as follows:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the ViewerPreferences through using PdfDocument.ViewerPreferences property.
- Set the viewer preferences using properties under ViewerPreferences class.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the viewer preferences
preferences = pdf.ViewerPreferences
# Set the viewer preferences
preferences.FitWindow = True
preferences.CenterWindow = True
preferences.HideMenubar = True
preferences.HideToolbar = True
preferences.DisplayTitle = True
preferences.HideWindowUI = True
preferences.PageLayout = PdfPageLayout.SinglePage
preferences.BookMarkExpandOrCollapse = True
preferences.PrintScaling = PrintScalingMode.AppDefault
preferences.PageMode = PdfPageMode.UseThumbs
# Save the document
pdf.SaveToFile("output/ViewerPreferences.pdf")
pdf.Close()
Set the Opening Page and Zoom Level with Python
By creating PDF actions and setting them to be executed when the document is opened, developers can configure additional viewer preferences, such as the initial page display and zoom level. Here are the steps to follow:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfDestination object and set the location and zoom factor of the destination.
- Create a PdfGoToAction object using the destination.
- Set the action as the document open action through PdfDocument.AfterOpenAction property.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample1.pdf")
# Get the second page
page = pdf.Pages.get_Item(1)
# Create a PdfDestination object
dest = PdfDestination(page)
# Set the location and zoom factor of the destination
dest.Mode = PdfDestinationMode.Location
dest.Location = PointF(0.0, page.Size.Height / 2)
dest.Zoom = 0.8
# Create a PdfGoToAction object
action = PdfGoToAction(dest)
# Set the action as the document open action
pdf.AfterOpenAction = action
# Save the document
pdf.SaveToFile("output/OpenPageZoom.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Barcodes in PDFs can facilitate quicker data retrieval and processing. You can add barcodes to PDF files that contain detailed information such as the document's unique identifier, version number, creator, or even the entire document content. When scanned, all information is decoded immediately. This instant access is invaluable for businesses dealing with large volumes of documents, as it minimizes the time and effort required for manual searching and data entry. In this article, you will learn how to add barcodes to PDF in Python using Spire.PDF for Python and Spire.Barcode for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and Spire.Barcode for Python. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF pip install Spire.Barcode
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add Barcodes to PDF in Python
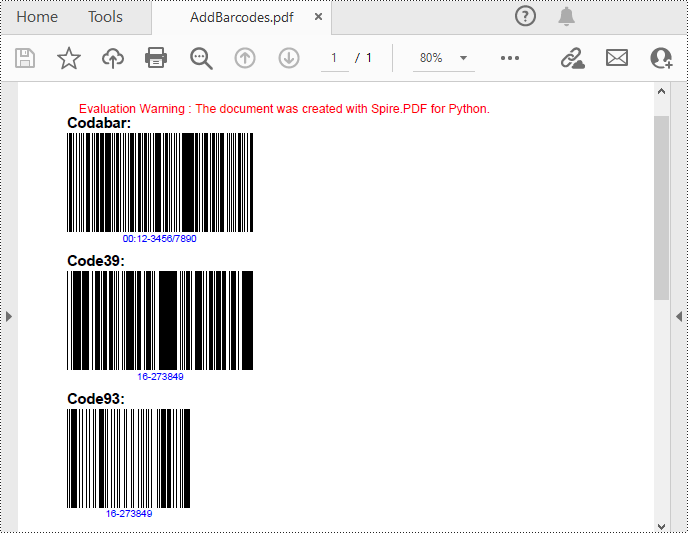
Spire.PDF for Python support several 1D barcode types represented by different classes, such as PdfCodabarBarcode, PdfCode11Barcode, PdfCode32Barcode, PdfCode39Barcode, PdfCode93Barcode.
Each class provides corresponding properties for setting the barcode text, size, color, etc. The following are the steps to draw the common Codabar, Code39 and Code93 barcodes at the specified locations on a PDF page.
- Create a PdfDocument object.
- Add a PDF page using PdfDocument.Pages.Add() method.
- Create a PdfTextWidget object and draw text on the page using PdfTextWidget.Draw() method.
- Create PdfCodabarBarcode, PdfCode39Barcode, PdfCode93Barcode objects.
- Set the gap between the barcode and the displayed text through the BarcodeToTextGapHeight property of the corresponding classes.
- Sets the barcode text display location through the TextDisplayLocation property of the corresponding classes.
- Set the barcode text color through the TextColor property of the corresponding classes.
- Draw the barcodes at specified locations on the PDF page using the Draw(page: PdfPageBase, location: PointF) method of the corresponding classes.
- Save the result PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PDF document
pdf = PdfDocument()
# Add a page
page = pdf.Pages.Add(PdfPageSize.A4())
# Initialize y-coordinate
y = 20.0
# Create a true type font
font = PdfTrueTypeFont("Arial", 12.0, PdfFontStyle.Bold, True)
# Draw text on the page
text = PdfTextWidget()
text.Font = font
text.Text = "Codabar:"
result = text.Draw(page, 0.0, y)
page = result.Page
y = result.Bounds.Bottom + 2
# Draw Codabar barcode on the page
Codabar = PdfCodabarBarcode("00:12-3456/7890")
Codabar.BarcodeToTextGapHeight = 1.0
Codabar.EnableCheckDigit = True
Codabar.ShowCheckDigit = True
Codabar.TextDisplayLocation = TextLocation.Bottom
Codabar.TextColor = PdfRGBColor(Color.get_Blue())
Codabar.Draw(page, PointF(0.0, y))
y = Codabar.Bounds.Bottom + 6
# Draw text on the page
text.Text = "Code39:"
result = text.Draw(page, 0.0, y)
page = result.Page
y = result.Bounds.Bottom + 2
# Draw Code39 barcode on the page
Code39 = PdfCode39Barcode("16-273849")
Code39.BarcodeToTextGapHeight = 1.0
Code39.TextDisplayLocation = TextLocation.Bottom
Code39.TextColor = PdfRGBColor(Color.get_Blue())
Code39.Draw(page, PointF(0.0, y))
y = Code39.Bounds.Bottom + 6
# Draw text on the page
text.Text = "Code93:"
result = text.Draw(page, 0.0, y)
page = result.Page
y = result.Bounds.Bottom + 2
# Draw Code93 barcode on the page
Code93 = PdfCode93Barcode("16-273849")
Code93.BarcodeToTextGapHeight = 1.0
Code93.TextDisplayLocation = TextLocation.Bottom
Code93.TextColor = PdfRGBColor(Color.get_Blue())
Code93.QuietZone.Bottom = 5.0
Code93.Draw(page, PointF(0.0, y))
# Save the document
pdf.SaveToFile("AddBarcodes.pdf")
pdf.Close()
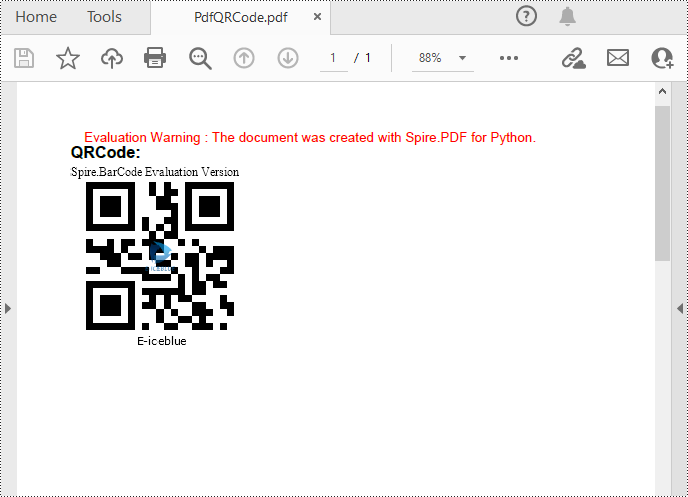
Add QR Codes to PDF in Python
To add 2D barcodes to a PDF file, the Spire.Barcode for Python library is required to generate QR code first, and then you can add the QR code image to the PDF file with the Spire.PDF for Python library. The following are the detailed steps.
- Create a PdfDocument object.
- Add a PDF page using PdfDocument.Pages.Add() method.
- Create a BarcodeSettings object.
- Call the corresponding properties of the BarcodeSettings class to set the barcode type, data, error correction level and width, etc.
- Create a BarCodeGenerator object based on the settings.
- Generate QR code image using BarCodeGenerator.GenerateImage() method.
- Save the QR code image to a PNG file.
- Draw the QR code image at a specified location on the PDF page using PdfPageBase.Canvas.DrawImage() method.
- Save the result PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
from spire.barcode import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Add a page
page = pdf.Pages.Add()
# Create a BarcodeSettings object
settings = BarcodeSettings()
# Set the barcode type to QR code
settings.Type = BarCodeType.QRCode
# Set the data of the QR code
settings.Data = "E-iceblue"
settings.Data2D = "E-iceblue"
# Set the width of the QR code
settings.X = 2
# Set the error correction level of the QR code
settings.QRCodeECL = QRCodeECL.M
# Set to show QR code text at the bottom
settings.ShowTextOnBottom = True
# Generate QR code image based on the settings
barCodeGenerator = BarCodeGenerator(settings)
QRimage = barCodeGenerator.GenerateImage()
# Save the QR code image to a .png file
with open("QRCode.png", "wb") as file:
file.write(QRimage)
# Initialize y-coordinate
y = 20.0
# Create a true type font
font = PdfTrueTypeFont("Arial", 12.0, PdfFontStyle.Bold, True)
# Draw text on the PDF page
text = PdfTextWidget()
text.Font = font
text.Text = "QRCode:"
result = text.Draw(page, 0.0, y)
page = result.Page
y = result.Bounds.Bottom + 2
# Draw QR code image on the PDF page
pdfImage = PdfImage.FromFile("QRCode.png")
page.Canvas.DrawImage(pdfImage, 0.0, y)
# Save the document
pdf.SaveToFile("PdfQRCode.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Comparing PDF documents is a common task when collaborating on projects or tracking changes. This allows users to quickly review and understand what has been modified, added, or removed between revisions. Effective PDF comparison streamlines the review process and ensures all stakeholders are aligned on the latest document content.
In this article, you will learn how to compare two PDF documents using Python and the Spire.PDF for Python library.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Compare Two PDF Documents in Python
Spire.PDF for Python provides the PdfComparer.Compare() method allowing developers to compare two PDF documents and save the comparison result to another PDF document. Here are the detailed steps.
- Load the first PDF document while initializing the PdfDocument object.
- Load the second PDF document while initializing another PdfDocument object.
- Initialize an instance of PdfComparer class, passing the two PdfDocument objects are the parameter.
- Call Compare() method of the PdfComparer object to compare the two PDF documents and save the result to a different PDF document.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Load the first document
doc_one = PdfDocument("C:\\Users\\Administrator\\Desktop\\PDF_ONE.pdf")
# Load the section document
doc_two = PdfDocument("C:\\Users\\Administrator\\Desktop\\PDF_TWO.pdf")
# Create a PdfComparer object
comparer = PdfComparer(doc_two, doc_one)
# Compare two documents and save the comparison result in a pdf document
comparer.Compare("output/CompareResult.pdf")
# Dispose resources
doc_one.Dispose()
doc_two.Dispose()

Compare Selected Pages in PDF Documents in Python
Instead of comparing two entire documents, you can specify the pages to compare using the PdfComparer.PdfCompareOptions.SetPageRanges() method. The following are the detailed steps.
- Load the first PDF document while initializing the PdfDocument object.
- Load the second PDF document while initializing another PdfDocument object.
- Initialize an instance of PdfComparer class, passing the two PdfDocument objects are the parameter.
- Specify the page range to compare using PdfComparer.PdfCompareOptions.SetPageRanges() method
- Call PdfComparer.Compare() method to compare the selected pages and save the result to a different PDF document.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Load the first document
doc_one = PdfDocument("C:\\Users\\Administrator\\Desktop\\PDF_ONE.pdf")
# Load the section document
doc_two = PdfDocument("C:\\Users\\Administrator\\Desktop\\PDF_TWO.pdf")
# Create a PdfComparer object
comparer = PdfComparer(doc_two, doc_one)
# Set page range for comparison
comparer.PdfCompareOptions.SetPageRanges(1, 3, 1, 3)
# Compare the selected pages and save the comparison result in a pdf document
comparer.Compare("output/CompareResult.pdf")
# Dispose resources
doc_one.Dispose()
doc_two.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
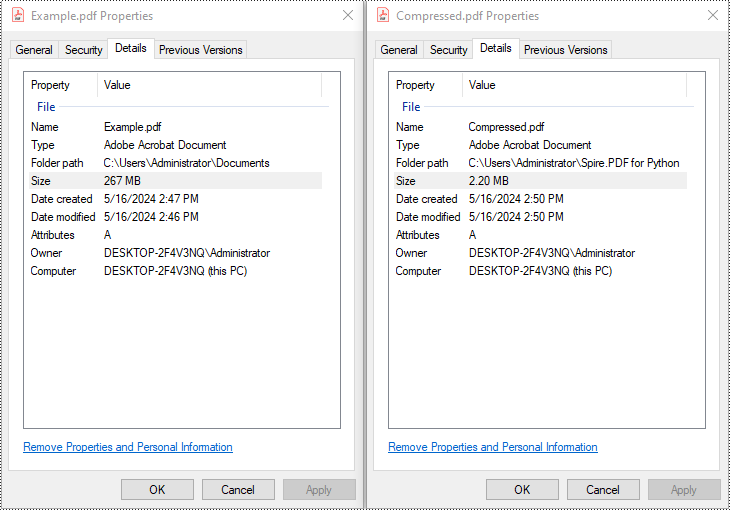
PDF has become the standard for sharing documents across various platforms and devices. However, large PDF files can be cumbersome to share, especially when dealing with limited storage space or slow internet connections. Compressing PDF files is an essential skill to optimize file size and ensure seamless document distribution. In this article, we will demonstrate how to compress PDF documents in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Compress PDF Documents in Python
PDF files are often large when they include high-resolution images or embedded fonts. To reduce the size of PDF files, consider compressing the images and fonts contained within them. The following steps explain how to compress PDF documents by compressing fonts and images using Spire.PDF for Python:
- Create a PdfCompressor object to compress a specified PDF file at a given path.
- Get the OptimizationOptions object using PdfCompressor.OptimizationOptions property.
- Enable font compression using OptimizationOptions.SetIsCompressFonts(True) method.
- Set image quality using OptimizationOptions.SetImageQuality(imageQuality:ImageQuality) method.
- Enable image resizing using OptimizationOptions.SetResizeImages(True) method.
- Enable image compression using OptimizationOptions.SetIsCompressImage(True) method.
- Compress the PDF file and save the compressed version to a new file using PdfCompressor.CompressToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfCompressor object to compress the specified PDF file at the given path
compressor = PdfCompressor("C:/Users/Administrator/Documents/Example.pdf")
# Get the OptimizationOptions object
compression_options = compressor.OptimizationOptions
# Enable font compression
compression_options.SetIsCompressFonts(True)
# Enable font unembedding
# compression_options.SetIsUnembedFonts(True)
# Set image quality
compression_options.SetImageQuality(ImageQuality.Medium)
# Enable image resizing
compression_options.SetResizeImages(True)
# Enable image compression
compression_options.SetIsCompressImage(True)
# Compress the PDF file and save the compressed version to a new file
compressor.CompressToFile("Compressed.pdf")
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Sometimes, when dealing with PDF documents, there is a need to split a page into different sections based on content or layout. For instance, splitting a mixed-layout page with both horizontal and vertical content into two separate parts. This type of splitting is not commonly available in basic PDF management functions but can be important for academic papers, magazine ads, or mixed-layout designs. This article explains how to use Spire.PDF for Python to perform horizontal or vertical PDF page splitting.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Split PDF Page Horizontally or Vertically with Python
Spire.PDF for Python not only supports splitting a PDF document into multiple PDF documents, but also allows splitting a specific page within a PDF into two or more pages. Here are the detailed steps to split a page:
- Create an instance of the PdfDocument class.
- Load the source PDF document using the PdfDocument.LoadFromFile() method.
- Retrieve the page(s) to be split using PdfDocument.Pages[].
- Create a new PDF document and set its page margins to 0.
- Set the width or height of the new document to half of the source document.
- Add a page to the new PDF document using the PdfDocument.Pages.Add() method.
- Create a template for the source document's page using the PdfPageBase.CreateTemplate() method.
- Draw the content of the source page onto the new page using the PdfTemplate.Draw() method.
- Save the split document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load the PDF document
pdf.LoadFromFile("Terms of service.pdf")
# Get the first page
page = pdf.Pages[0]
# Create a new PDF document and remove the page margins
newpdf = PdfDocument()
newpdf.PageSettings.Margins.All=0
# Horizontal splitting: Set the width of the new document's page to be the same as the width of the first page of the original document, and the height to half of the first page's height
newpdf.PageSettings.Width=page.Size.Width
newpdf.PageSettings.Height=page.Size.Height/2
'''
# Vertical splitting: Set the width of the new document's page to be half of the width of the first page of the original document, and the height to the same as the first page's height
newpdf.PageSettings.Width=page.Size.Width/2
newpdf.PageSettings.Height=page.Size.Height
'''
# Add a new page to the new PDF document
newPage = newpdf.Pages.Add()
# Set the text layout format
format = PdfTextLayout()
format.Break=PdfLayoutBreakType.FitPage
format.Layout=PdfLayoutType.Paginate
# Create a template based on the first page of the original document and draw it onto the new page of the new document, automatically paginating when the page is filled
page.CreateTemplate().Draw(newPage, PointF(0.0, 0.0), format)
# Save the document
newpdf.SaveToFile("HorizontalSplitting.pdf")
# Close the objects
newpdf.Close()
pdf.Close()
The result of horizontal splitting is as follows:
The result of vertical splitting is as follows:
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
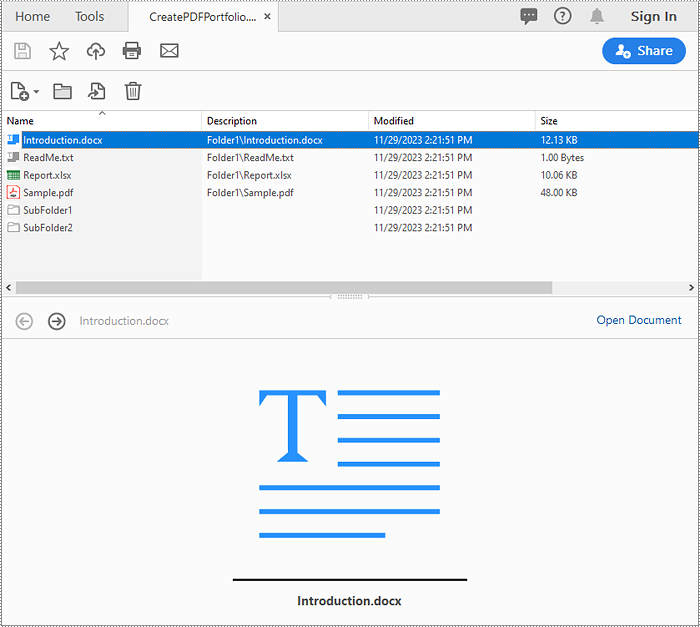
A PDF portfolio is a collection of files assembled into a single PDF document. It serves as a comprehensive and interactive showcase of various types of content, such as documents, images, presentations, videos, and more. Unlike a traditional PDF document, a PDF portfolio allows you to present multiple files in a cohesive and organized manner, providing a seamless browsing experience for the viewer. In this article, we will demonstrate how to create a PDF portfolio and how to identify if a PDF is a portfolio in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Create a PDF Portfolio with Python
Spire.PDF for Python allows you to generate a PDF portfolio by adding files to a PDF using the PdfDocument.Collection.AddFile() method. Furthermore, you can organize the files within the PDF portfolio by adding folders using the PdfDocument.Collection.Folders.CreateSubfolder() method. The detailed steps are as follows.
- Specify the output file path and the folders where the files to be included in the PDF portfolio are located.
- Create a PdfDocument object.
- Iterate through the files in the first folder and add them to the PDF portfolio using the PdfDocument.Collection.AddFile() method.
- Iterate through the files in the second folder. For each file, create a separate folder within the PDF portfolio using the PdfDocument.Collection.Folders.CreateSubfolder() method, and then add the file to the corresponding folder using the PdfFolder.AddFile() method.
- Save the resulting PDF portfolio using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
import glob
# Specify the folders where the files to be included in the PDF portfolio are located
input_folder1 = "Folder1/*"
input_folder2 = "Folder2/*"
# Specify the output file path
output_file = "CreatePDFPortfolio.pdf"
# Create a PdfDocument object
doc = PdfDocument()
# Get the list of file paths in the first folder
files1 = glob.glob(input_folder1)
# Loop through the files in the list
for i, file in enumerate(files1):
# Add each file to the PDF portfolio
doc.Collection.AddFile(file)
# Get the list of file paths in the second folder
files2 = glob.glob(input_folder2)
# Loop through the files in the list
for j, file in enumerate(files2):
# Create a separate folder for each file
folder = doc.Collection.Folders.CreateSubfolder(f"SubFolder{j + 1}")
# Add the file to the folder
folder.AddFile(file)
# Save the resulting PDF portfolio to the specified file path
doc.SaveToFile(output_file)
# Close the PdfDocument object
doc.Close()
Identify if a PDF is a Portfolio with Python
You can use the PdfDocument.IsPortfolio property to easily identify whether a PDF document is a portfolio or not. The detailed steps are as follows.
- Specify the input and output file paths.
- Create a PdfDocument object.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Identify whether the document is a portfolio or not using the PdfDocument.IsPortfolio property.
- Save the result to a text file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Specify the input and output file paths
input_file = "CreatePDFPortfolio.pdf"
output_file = "IsPDFPortfolio.txt"
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile(input_file)
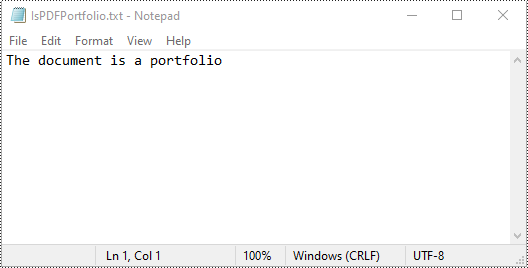
# Identify whether the document is a portfolio or not
if doc.IsPortfolio:
st = "The document is a portfolio"
else:
st = "The document is not a portfolio"
# Save the result to a text file
with open(output_file, "w") as text_file:
text_file.write(st)
# Close the PdfDocument object
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Layers in PDF are similar to layers in image editing software, where different elements of a document can be organized and managed separately. Each layer can contain different content, such as text, images, graphics, or annotations, and can be shown or hidden independently. PDF layers are often used to control the visibility and positioning of specific elements within a document, making it easier to manage complex layouts, create dynamic designs, or control the display of information. In this article, you will learn how to add, hide, remove layers in a PDF document in Python using Spire.PDF for Python.
- Add a Layer to PDF in Python
- Set Visibility of a Layer in PDF in Python
- Remove a Layer from PDF in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add a Layer to PDF in Python
A layer can be added to a PDF document using the Document.Layers.AddLayer() method. After the layer object is created, you can draw text, images, fields, or other elements on it to form its appearance. The detailed steps to add a layer to PDF using Spire.PDF for Java are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Create a layer using Document.Layers.AddLayer() method.
- Get a specific page through PdfDocument.Pages[index] property.
- Create a canvas for the layer based on the page using PdfLayer.CreateGraphics() method.
- Draw text on the canvas using PdfCanvas.DrawString() method.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
def AddLayerWatermark(doc):
# Create a layer named "Watermark"
layer = doc.Layers.AddLayer("Watermark")
# Create a font
font = PdfTrueTypeFont("Bodoni MT Black", 50.0, 1, True)
# Specify watermark text
watermarkText = "DO NOT COPY"
# Get text size
fontSize = font.MeasureString(watermarkText)
# Get page count
pageCount = doc.Pages.Count
# Loop through the pages
for i in range(0, pageCount):
# Get a specific page
page = doc.Pages[i]
# Create canvas for layer
canvas = layer.CreateGraphics(page.Canvas)
# Draw sting on the graphics
canvas.DrawString(watermarkText, font, PdfBrushes.get_Gray(), (canvas.Size.Width - fontSize.Width)/2, (canvas.Size.Height - fontSize.Height)/2 )
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Invoke AddLayerWatermark method to add a layer
AddLayerWatermark(doc)
# Save to file
doc.SaveToFile("output/AddLayer.pdf", FileFormat.PDF)
doc.Close()
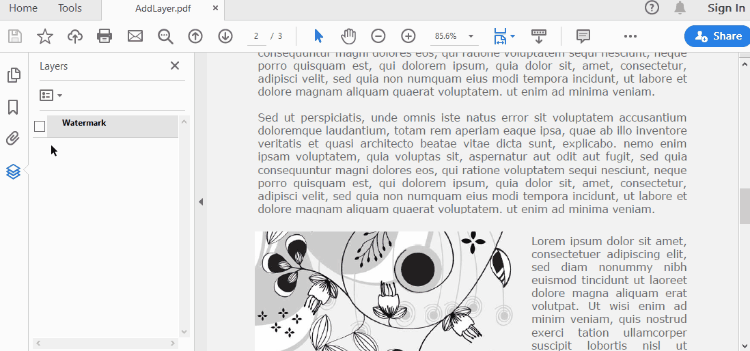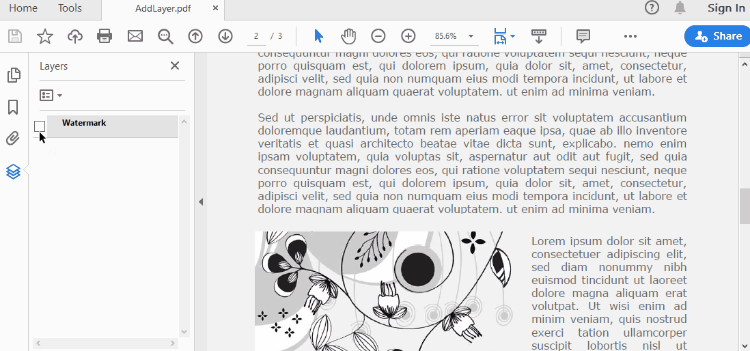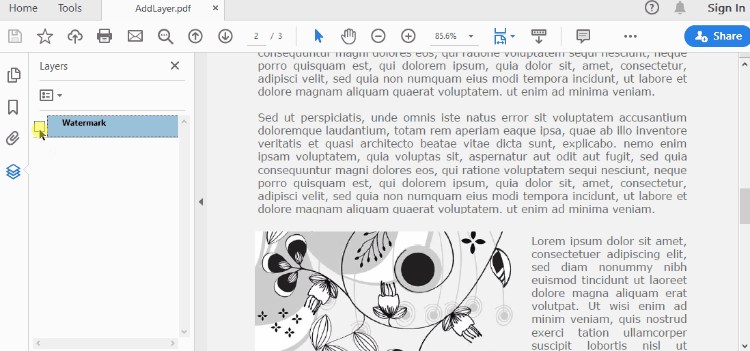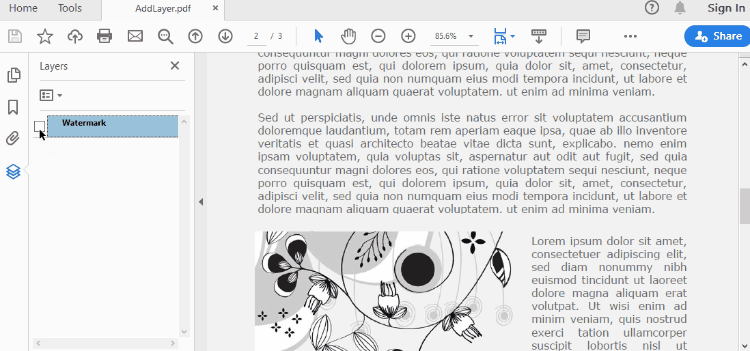
Set Visibility of a Layer in PDF in Python
To control the visibility of layers in a PDF document, you can use the PdfDocument.Layers[index].Visibility property. Set it to off to hide a layer, or set it to on to unhide a layer. The detailed steps are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Set the visibility of a certain layer through Document.Layers[index].Visibility property.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Layer.pdf")
# Hide a layer by setting the visibility to off
doc.Layers[0].Visibility = PdfVisibility.Off
# Save to file
doc.SaveToFile("output/HideLayer.pdf", FileFormat.PDF)
doc.Close()
Remove a Layer from PDF in Python
If a layer is no more wanted, you can remove it using the PdfDocument.Layers.RmoveLayer() method. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specific layer through PdfDocument.Layers[index] property.
- Remove the layer from the document using PdfDcument.Layers.RemoveLayer(PdfLayer.Name) method.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Layer.pdf")
# Delete the specific layer
doc.Layers.RemoveLayer(doc.Layers[0].Name)
# Save to file
doc.SaveToFile("output/RemoveLayer.pdf", FileFormat.PDF)
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
PDF properties refer to the information embedded within the document that provides detailed information about the documents, such as author, creation date, last modification date, etc. Users can check the properties of a PDF document in PDF viewers to quickly grasp the key information of the document. Apart from the built-in properties, PDF documents also offer the feature of customizing properties to help provide additional information about the document. Understanding how to specify and access this document information facilitates the creation of user-friendly documents and the processing of documents in large quantities. In this article, we will explore how to set and retrieve PDF properties through Python programs using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Set PDF Properties with Python
Spire.PDF for Python provides several properties under the PdfDocumentInformation class for setting built-in document properties, such as author, subject, keywords. Besides, it also provides the PdfDocumentInformation.SetCustomProperty() method to set custom properties. The following are the detailed steps to set PDF properties:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the properties of the document through PdfDocument.DocumentInformation property.
- Set the built-in properties through properties under PdfDocumentInformation class.
- Set custom properties using PdfDocumentInformation.SetCustomProperty() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get the properties of the document
properties = pdf.DocumentInformation
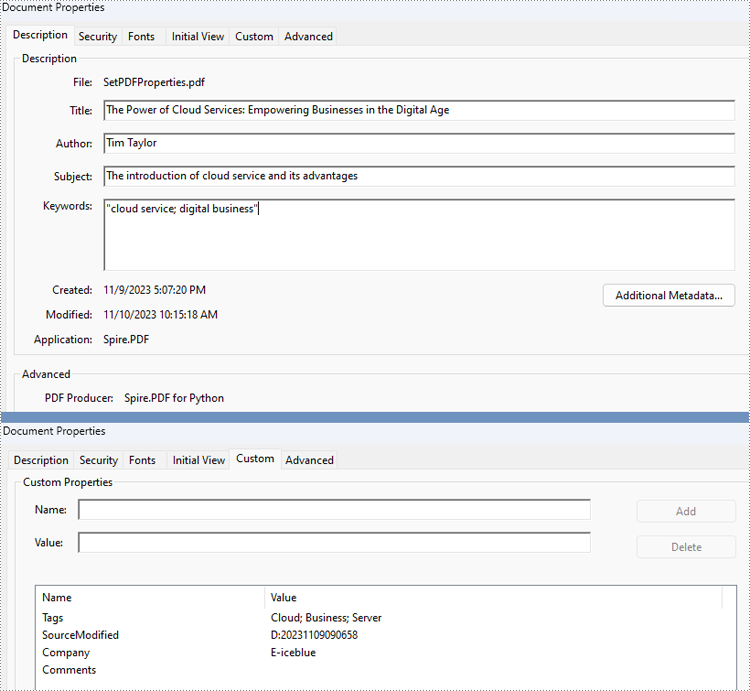
# Set built-in properties
properties.Author = "Tim Taylor"
properties.Creator = "Spire.PDF"
properties.Keywords = "cloud service; digital business"
properties.Subject = "The introduction of cloud service and its advantages"
properties.Title = "The Power of Cloud Services: Empowering Businesses in the Digital Age"
properties.Producer = "Spire.PDF for Python"
# Set custom properties
properties.SetCustomProperty("Company", "E-iceblue")
properties.SetCustomProperty("Tags", "Cloud; Business; Server")
# Save the document
pdf.SaveToFile("output/SetPDFProperties.pdf")
pdf.Close()
Retrieve PDF Properties with Python
Information in built-in PDF properties can be obtained using the properties under the PdfDocumentInformation class, while that in custom PDF properties can be obtained using PdfDocumentInformation.GetCustomProperty() method. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the properties of the document through PdfDocument.DocumentInformation property.
- Retrieve the built-in properties through properties under PdfDocumentInformation class and custom properties using PdfDocumentInformation.GetCustomProperty() method and print them.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("output\SetPDFProperties.pdf")
# Get the properties of the document
properties = pdf.DocumentInformation
# Create a StringBuilder object
information = ""
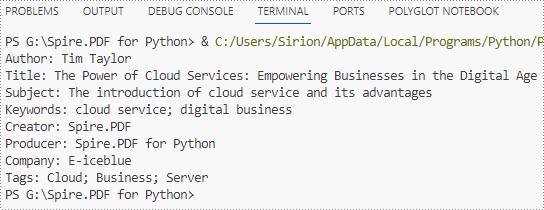
# Retrieve the built-in properties
information += "Author: " + properties.Author
information += "\nTitle: " + properties.Title
information += "\nSubject: " + properties.Subject
information += "\nKeywords: " + properties.Keywords
information += "\nCreator: " + properties.Creator
information += "\nProducer: " + properties.Producer
# Retrieve the custom properties
information += "\nCompany: " + properties.GetCustomProperty("Company")
information += "\nTags: " + properties.GetCustomProperty("Tags")
# Print the document properties
print(information)
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Large PDF files can sometimes be cumbersome to handle, especially when sharing or uploading them. Splitting a large PDF file into multiple smaller PDFs reduces the file size, making it more manageable and quicker to open and process. In this article, we will demonstrate how to split PDF documents in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
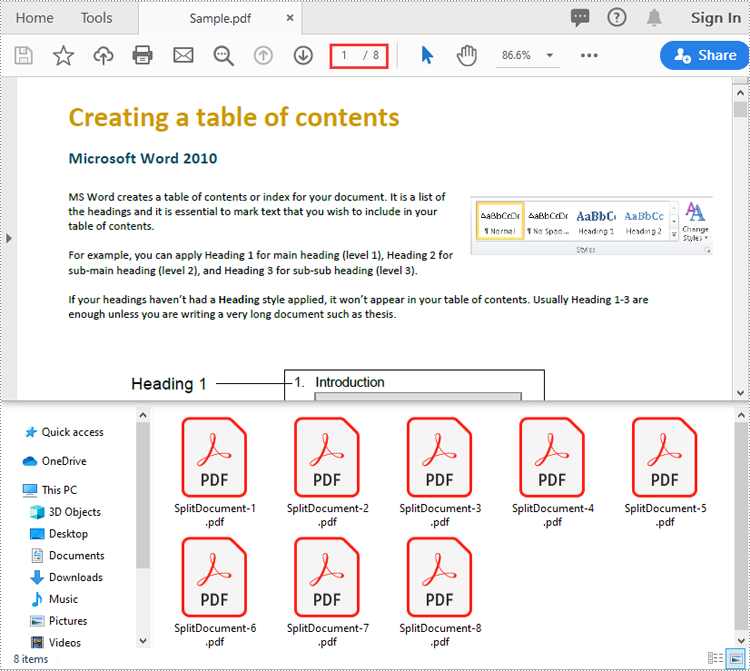
Split a PDF File into Multiple Single-Page PDFs in Python
Spire.PDF for Python offers the PdfDocument.Split() method to divide a multi-page PDF document into multiple single-page PDF files. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Split the document into multiple single-page PDFs using PdfDocument.Split() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Sample.pdf")
# Split the PDF file into multiple single-page PDFs
doc.Split("Output/SplitDocument-{0}.pdf", 1)
# Close the PdfDocument object
doc.Close()
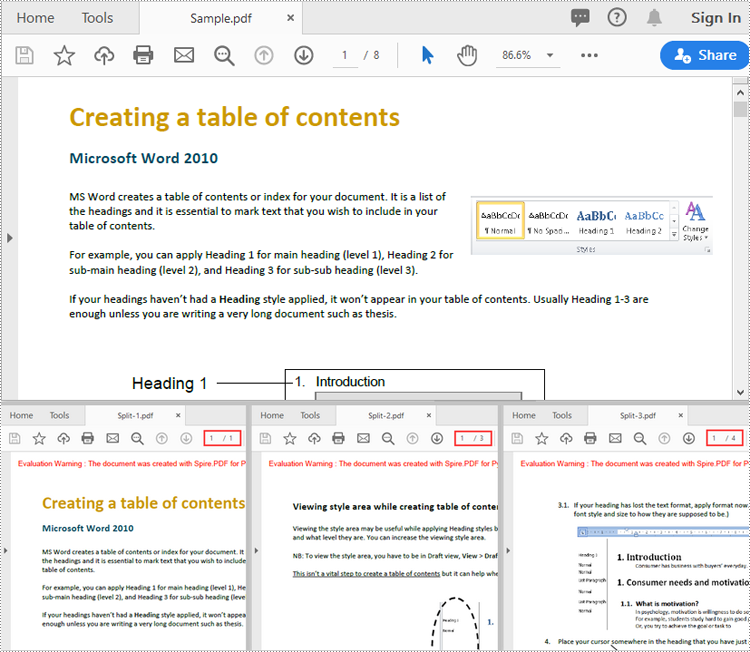
Split a PDF File by Page Ranges in Python
To split a PDF file into two or more PDF files by page ranges, you need to create two or more new PDF files, and then import the specific page or range of pages from the source PDF into the newly created PDF files. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Create three PdfDocument objects.
- Import the first page from the source file into the first document using PdfDocument.InsertPage() method.
- Import pages 2-4 from the source file into the second document using PdfDocument.InsertPageRange() method.
- Import the remaining pages from the source file into the third document using PdfDocument.InsertPageRange() method.
- Save the three documents using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Sample.pdf")
# Create three PdfDocument objects
newDoc_1 = PdfDocument()
newDoc_2 = PdfDocument()
newDoc_3 = PdfDocument()
# Insert the first page of the source file into the first document
newDoc_1.InsertPage(doc, 0)
# Insert pages 2-4 of the source file into the second document
newDoc_2.InsertPageRange(doc, 1, 3)
# Insert the rest pages of the source file into the third document
newDoc_3.InsertPageRange(doc, 4, doc.Pages.Count - 1)
# Save the three documents
newDoc_1.SaveToFile("Output1/Split-1.pdf")
newDoc_2.SaveToFile("Output1/Split-2.pdf")
newDoc_3.SaveToFile("Output1/Split-3.pdf")
# Close the PdfDocument objects
doc.Close()
newDoc_1.Close()
newDoc_2.Close()
newDoc_3.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
More...
