Python (318)
Retrieving the coordinates of text or images within a PDF document can quickly locate specific elements, which is valuable for extracting content from PDFs. This capability also enables adding annotations, marks, or stamps to the desired locations in a PDF, allowing for more advanced document processing and manipulation.
In this article, you will learn how to get coordinates of the specified text or image in a PDF document using Spire.PDF for Python.
- Get Coordinates of the Specified Text in PDF in Python
- Get Coordinates of the Specified Image in PDF in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
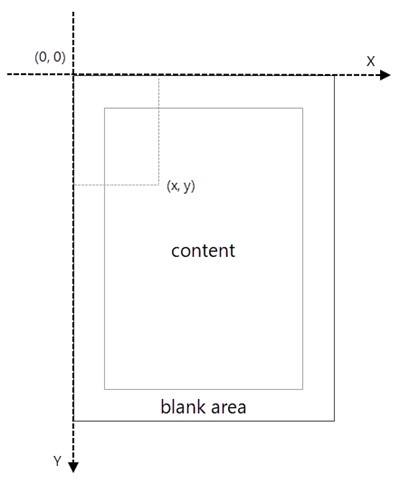
Coordinate System in Spire.PDF
When using Spire.PDF to process an existing PDF document, the origin of the coordinate system is located at the top left corner of the page. The X-axis extends horizontally from the origin to the right, and the Y-axis extends vertically downward from the origin (shown as below).
Get Coordinates of the Specified Text in PDF in Python
To find the coordinates of a specific piece of text within a PDF document, you must first use the PdfTextFinder.Find() method to locate all instances of the target text on a particular page. Once you have found these instances, you can then access the PdfTextFragment.Positions property to retrieve the precise (X, Y) coordinates for each instance of the text.
The steps to get coordinates of the specified text in PDF are as follows.
- Create a PdfDocument object.
- Load a PDF document from a specified path.
- Get a specific page from the document.
- Create a PdfTextFinder object.
- Specify find options through PdfTextFinder.Options property.
- Search for a string within the page using PdfTextFinder.Find() method.
- Get a specific instance of the search results.
- Get X and Y coordinates of the text through PdfTextFragment.Positions[0].X and PdfTextFragment.Positions[0].Y properties.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object
textFinder = PdfTextFinder(page)
# Specify find options
findOptions = PdfTextFindOptions()
findOptions.Parameter = TextFindParameter.IgnoreCase
findOptions.Parameter = TextFindParameter.WholeWord
textFinder.Options = findOptions
# Search for the string "PRIVACY POLICY" within the page
findResults = textFinder.Find("PRIVACY POLICY")
# Get the first instance of the results
result = findResults[0]
# Get X/Y coordinates of the found text
x = int(result.Positions[0].X)
y = int(result.Positions[0].Y)
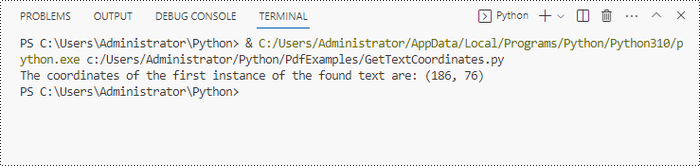
print("The coordinates of the first instance of the found text are:", (x, y))
# Dispose resources
doc.Dispose()
Get Coordinates of the Specified Image in PDF in Python
Spire.PDF for Python provides the PdfImageHelper class, which allows users to extract image details from a specific page within a PDF file. By doing so, you can leverage the PdfImageInfo.Bounds property to retrieve the (X, Y) coordinates of an individual image.
The steps to get coordinates of the specified image in PDF are as follows.
- Create a PdfDocument object.
- Load a PDF document from a specified path.
- Get a specific page from the document.
- Create a PdfImageHelper object.
- Get the image information from the page using PdfImageHelper.GetImagesInfo() method.
- Get X and Y coordinates of a specific image through PdfImageInfo.Bounds property.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfImageHelper object
imageHelper = PdfImageHelper()
# Get image information from the page
imageInformation = imageHelper.GetImagesInfo(page)
# Get X/Y coordinates of a specific image
x = int(imageInformation[0].Bounds.X)
y = int(imageInformation[0].Bounds.Y)
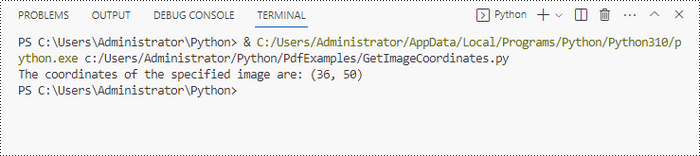
print("The coordinates of the specified image are:", (x, y))
# Dispose resources
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
PDF has become the standard for sharing documents across various platforms and devices. However, large PDF files can be cumbersome to share, especially when dealing with limited storage space or slow internet connections. Compressing PDF files is an essential skill to optimize file size and ensure seamless document distribution. In this article, we will demonstrate how to compress PDF documents in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Compress PDF Documents in Python
PDF files are often large when they include high-resolution images or embedded fonts. To reduce the size of PDF files, consider compressing the images and fonts contained within them. The following steps explain how to compress PDF documents by compressing fonts and images using Spire.PDF for Python:
- Create a PdfCompressor object to compress a specified PDF file at a given path.
- Get the OptimizationOptions object using PdfCompressor.OptimizationOptions property.
- Enable font compression using OptimizationOptions.SetIsCompressFonts(True) method.
- Set image quality using OptimizationOptions.SetImageQuality(imageQuality:ImageQuality) method.
- Enable image resizing using OptimizationOptions.SetResizeImages(True) method.
- Enable image compression using OptimizationOptions.SetIsCompressImage(True) method.
- Compress the PDF file and save the compressed version to a new file using PdfCompressor.CompressToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfCompressor object to compress the specified PDF file at the given path
compressor = PdfCompressor("C:/Users/Administrator/Documents/Example.pdf")
# Get the OptimizationOptions object
compression_options = compressor.OptimizationOptions
# Enable font compression
compression_options.SetIsCompressFonts(True)
# Enable font unembedding
# compression_options.SetIsUnembedFonts(True)
# Set image quality
compression_options.SetImageQuality(ImageQuality.Medium)
# Enable image resizing
compression_options.SetResizeImages(True)
# Enable image compression
compression_options.SetIsCompressImage(True)
# Compress the PDF file and save the compressed version to a new file
compressor.CompressToFile("Compressed.pdf")
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add, Read, and Remove Built-in Document Properties in Word Documents
2024-05-16 01:17:49 Written by KoohjiWord documents often contain metadata known as document properties, which include information like title, author, subject, and keywords. Manipulating these properties is invaluable for maintaining organized documentation, enhancing searchability, and ensuring proper attribution in collaborative environments. With Spire.Doc for Python, developers can automate the tasks of adding, reading, and removing document properties in Word documents to streamline document management workflows and enable the integration of these processes into larger automated systems. This article provides detailed steps and code examples that demonstrate how to utilize Spire.Doc for Python to effectively manage document properties within Word files.
- Add Built-in Document Properties to Word Documents with Python
- Read Built-in Document Properties from Word Documents with Python
- Remove Built-in Document Properties from Word Documents with Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.Doc
If you are unsure how to install, please refer to: How to Install Spire.Doc for Python on Windows
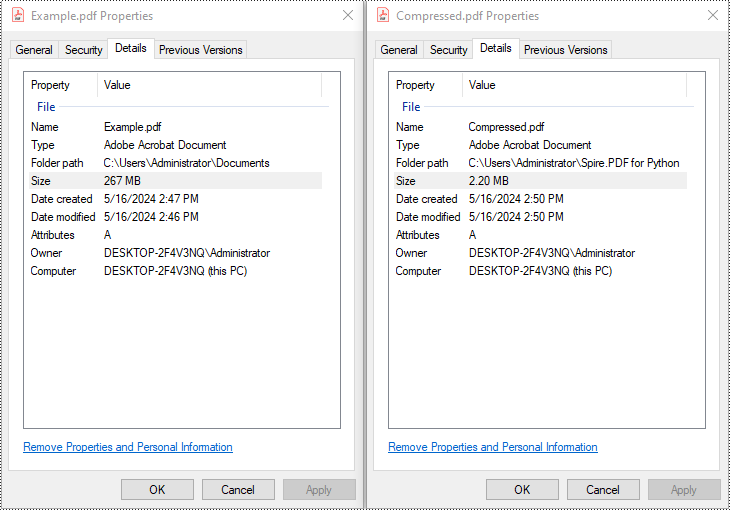
Add Built-in Document Properties to Word Documents with Python
Spire.Doc for Python provides developers with the Document.BuiltinDocumentProperties property to access the built-in properties of Word documents. The value of these properties can be set using the corresponding properties under the BuiltinDocumentProperties class.
The following steps show how to add the main built-in properties in Word documents:
- Create an object of Document class.
- Load a Word document using Document.LoadFromFile() method.
- Get the built-in properties through Document.BuiltinDocumentProperties property.
- Add values to the properties with properties under BuiltinDocumentProperties property.
- Save the document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document
doc = Document()
# Load a Word document
doc.LoadFromFile("Sample.docx")
# Set the built-in property
builtinProperty = doc.BuiltinDocumentProperties
builtinProperty.Title = "Revolutionizing Artificial Intelligence"
builtinProperty.Subject = "Advanced Applications and Future Directions of Neural Networks in Artificial Intelligence"
builtinProperty.Author = "Simon"
builtinProperty.Manager = "Arie"
builtinProperty.Company = "AI Research Lab"
builtinProperty.Category = "Research"
builtinProperty.Keywords = "Machine Learning, Neural Network, Artificial Intelligence"
builtinProperty.Comments = "This paper is about the state of the art of artificial intelligence."
builtinProperty.HyperLinkBase = "www.e-iceblue.com"
# Save the document
doc.SaveToFile("output/AddPropertyWord.docx", FileFormat.Docx2019)
doc.Close()
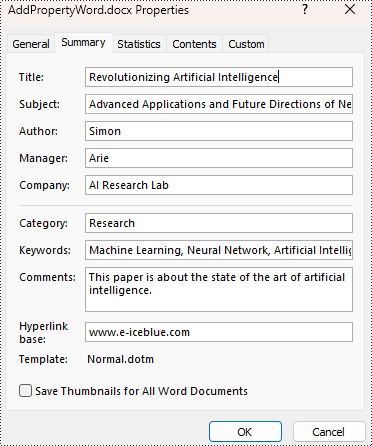
Read Built-in Document Properties from Word Documents with Python
Besides adding values, the properties under the BuiltinDocumentProperties class also empower developers to read existing built-in properties of Word documents. This enables various functionalities like document search, information extraction, and document analysis.
The detailed steps for reading document built-in properties using Spire.Doc for Python are as follows:
- Create an object of Document class.
- Load a Word document using Document.LoadFromFile() method.
- Get the built-in properties of Document using Document.BuiltinDocumentProperties property.
- Get the value of the properties using properties under BuiltinDocumentProperties class.
- Output the built-in properties of the document.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document
doc = Document()
# Load a Word document
doc.LoadFromFile("output/AddPropertyWord.docx")
# Get the built-in properties of the document
builtinProperties = doc.BuiltinDocumentProperties
# Get the value of the built-in properties
properties = [
"Author: " + builtinProperties.Author,
"Company: " + builtinProperties.Company,
"Title: " + builtinProperties.Title,
"Subject: " + builtinProperties.Subject,
"Keywords: " + builtinProperties.Keywords,
"Category: " + builtinProperties.Category,
"Manager: " + builtinProperties.Manager,
"Comments: " + builtinProperties.Comments,
"Hyperlink Base: " + builtinProperties.HyperLinkBase,
"Word Count: " + str(builtinProperties.WordCount),
"Page Count: " + str(builtinProperties.PageCount),
]
# Output the built-in properties
for i in range(0, len(properties)):
print(properties[i])
doc.Close()
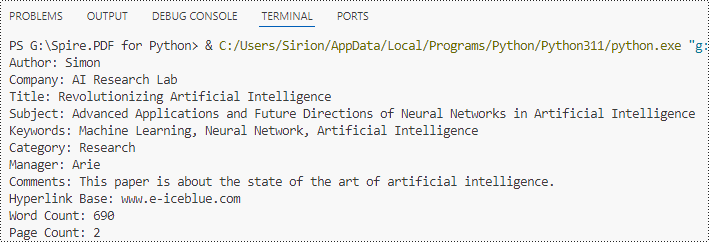
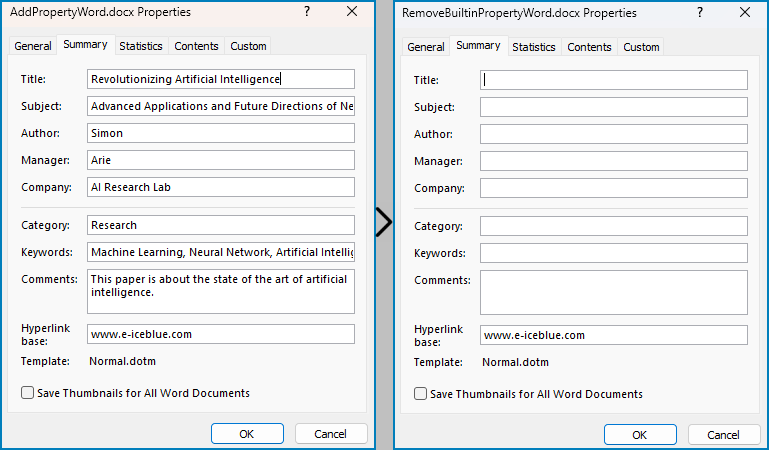
Remove Built-in Document Properties from Word Documents with Python
The built-in document properties of a Word document that contain specific content can be removed by setting them to null values. This protects private information while retaining necessary details.
The detailed steps for removing specific built-in document properties from Word documents are as follows:
- Create an object of Document class.
- Load a Word document using Document.LoadFromFile() method.
- Get the built-in properties of the document through Document.BuiltinDocumentProperties property.
- Set the value of some properties to none to remove the properties with properties under BuiltinDocumentProperties class.
- Save the document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an instance of the Document class
doc = Document()
# Load the Word document
doc.LoadFromFile("output/AddPropertyWord.docx")
# Get the document's built-in properties
builtinProperties = doc.BuiltinDocumentProperties
# Remove the built-in properties by setting them to None
builtinProperties.Author = None
builtinProperties.Company = None
builtinProperties.Title = None
builtinProperties.Subject = None
builtinProperties.Keywords = None
builtinProperties.Comments = None
builtinProperties.Category = None
builtinProperties.Manager = None
# Save the document
doc.SaveToFile("output/RemovePropertyWord.docx", FileFormat.Docx)
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Tables in PDFs often contain valuable data that may need to be analyzed, processed, or visualized. Extracting tables from PDFs enables you to import the data into spreadsheet software or data analysis tools, where you can perform calculations, generate charts, apply statistical analysis, and gain insights from the information. In this article, we will demonstrate how to extract tables from PDF in Python using Spire.PDF for Python and Spire.XLS for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and Spire.XLS for Python. Spire.PDF is responsible for extracting data from PDF tables, and Spire.XLS is responsible for creating an Excel document based on the data obtained from PDF.
Spire.PDF for Python and Spire.XLS for Python can be easily installed in your Windows through the following pip commands.
pip install Spire.PDF pip install Spire.XLS
If you are unsure how to install, please refer to these tutorials:
Extract Tables from PDF in Python
Spire.PDF for Python offers the PdfTableExtractor.ExtractTable(pageIndex) method to extract tables from a page in a searchable PDF document. After the tables are extracted, you can loop through the rows and columns in each table and then get the text contained within each table cell using the PdfTable.GetText(rowIndex, columnIndex) method. The detailed steps are as follows:
- Create an instance of PdfDocument class.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Loop through the pages in the PDF document.
- Extract tables from the pages using PdfTableExtractor.ExtractTable() method.
- Loop through the extracted tables.
- Get the text of the cells in the tables using PdfTable.GetText() method and save them to a list.
- Write the content of the list into a .txt file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load the sample PDF file
doc.LoadFromFile("TableExample.pdf")
# Create a list to store the extracted data
builder = []
# Create a PdfTableExtractor object
extractor = PdfTableExtractor(doc)
# Loop through the pages
for pageIndex in range(doc.Pages.Count):
# Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
# Determine if the table list is not empty
if tableList is not None and len(tableList) > 0:
# Loop through the tables in the list
for table in tableList:
# Get row number and column number of a certain table
row = table.GetRowCount()
column = table.GetColumnCount()
# Loop through the row and column
for i in range(row):
for j in range(column):
# Get text from the specific cell
text = table.GetText(i, j)
# Add the text to the list
builder.append(text + " ")
builder.append("\n")
builder.append("\n")
# Write the content of the list into a text file
with open("Table.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
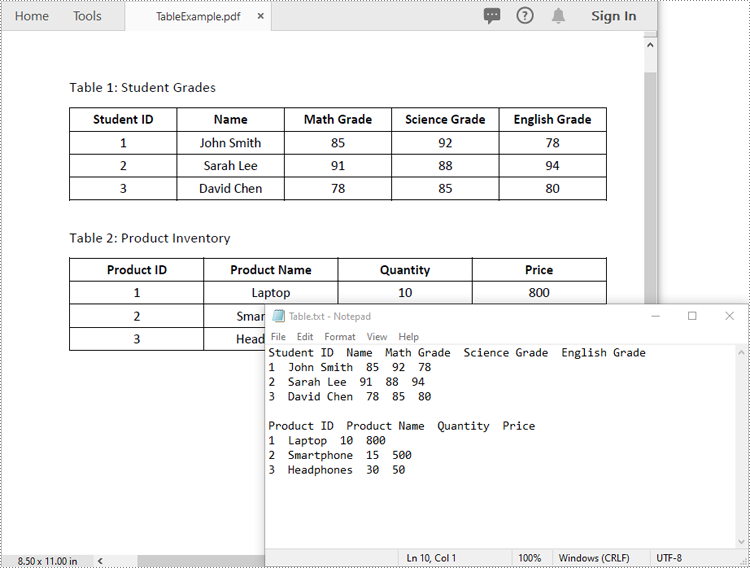
Extract Tables from PDF to Excel in Python
After you get the text of each table cell, you can write it into an Excel worksheet for further analysis by using the Worksheet.Range[rowIndex, columnIndex].Value property offered by Spire.XLS for Python. The detailed steps are as follows:
- Create an instance of PdfDocument class.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Create an instance of Workbook class and clear the default worksheets in it.
- Loop through the pages in the PDF document.
- Extract tables from the pages using PdfTableExtractor.ExtractTable() method.
- Loop through the extracted tables.
- For each table, add a worksheet to the workbook using Workbook.Worksheets.Add() method.
- Get the text of the cells in the table using PdfTable.GetText() method.
- Write the text to specific cells in the worksheet using Worksheet.Range[rowIndex, columnIndex].Value property.
- Save the resultant workbook to an Excel file using Workbook.SaveToFile() method.
- Python
from spire.pdf import *
from spire.xls import *
# Create a PdfDocument object
doc = PdfDocument()
# Load the sample PDF file
doc.LoadFromFile("TableExample.pdf")
# Create a Workbook object
workbook = Workbook()
# Clear default worksheets
workbook.Worksheets.Clear()
# Create a PdfTableExtractor object
extractor = PdfTableExtractor(doc)
sheetNumber = 1
# Loop through the pages
for pageIndex in range(doc.Pages.Count):
# Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
# Determine if the table list is not empty
if tableList is not None and len(tableList) > 0:
# Loop through the tables in the list
for table in tableList:
# Add a worksheet
sheet = workbook.Worksheets.Add(f"sheet{sheetNumber}")
# Get row number and column number of a certain table
row = table.GetRowCount()
column = table.GetColumnCount()
# Loop through the rows and columns
for i in range(row):
for j in range(column):
# Get text from the specific cell
text = table.GetText(i, j)
# Write text to a specified cell
sheet.Range[i + 1, j + 1].Value = text
# Auto-fit columns
sheet.AllocatedRange.AutoFitColumns()
sheetNumber += 1
# Save to file
workbook.SaveToFile("ToExcel.xlsx", ExcelVersion.Version2013)
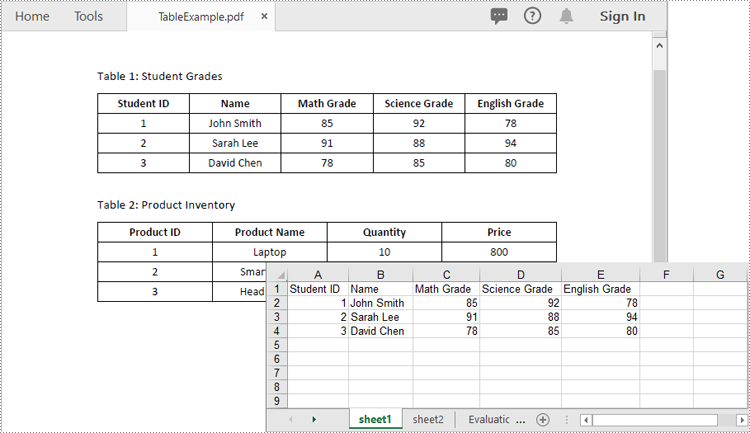
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Adding page numbers to a Word document is a fundamental feature that enhances readability and navigation, especially in lengthy documents. It allows readers to find specific content more easily and helps authors organize their work. Word offers flexible options for adding page numbers, including choosing the location (header, footer, or body) and customizing the format and appearance to match your document's design needs.
In this article, you will learn how to add pager numbers to a Word document, as well as customizing their appearance using Spire.Doc for Python.
- Add Page Numbers to a Word Document
- Add Page Numbers to a Specific Section
- Add Discontinuous Page Numbers to Different Sections
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
Add Page Numbers to a Word Document in Python
To dynamically add page numbers to a Word document using Spire.Doc, you can leverage various fields such as FieldPage, FieldNumPages, and FieldSection. These fields serve as placeholders for the current page number, total page count, and section number, enabling you to customize and automate the pagination process.
You can embed these placeholders in the header or footer of your document by calling the Paragraph.AppendField() method.
Here's a step-by-step guide on how to insert a FieldPage and FieldNumPages field in the footer, which will display the page number in the format "X / Y":
- Create a Document object.
- Load a Word document from a specified file path.
- Get the first section using Document.Sections[index] property
- Get the footer of the first section using Section.HeadersFooters.Footer property.
- Add a paragraph to the footer using HeaderFooter.AddParagraph() method.
- Insert a FieldPage field, and a FieldNumPages field to the paragraph using Paragraph.AppendField() method.
- Save the document to a different Word file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word file
document.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.docx")
# Get the first section
section = document.Sections[0]
# Get the footer of the section
footer = section.HeadersFooters.Footer
# Add "page number / page count" to the footer
footerParagraph = footer.AddParagraph()
footerParagraph.AppendField("page number", FieldType.FieldPage)
footerParagraph.AppendText(" / ")
footerParagraph.AppendField("page count", FieldType.FieldNumPages)
footerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
# Apply formatting to the page number
style = ParagraphStyle(document)
style.CharacterFormat.Bold = True
style.CharacterFormat.FontName = "Times New Roman"
style.CharacterFormat.FontSize = 18
style.CharacterFormat.TextColor = Color.get_Red()
document.Styles.Add(style)
footerParagraph.ApplyStyle(style)
# Save the document
document.SaveToFile("Output/AddPageNumbersToDocument.docx")
# Dispose resources
document.Dispose()

Add Page Numbers to a Specific Section in Python
By default, when you add page numbers to the footer of a section, they are automatically linked to the preceding section, maintaining a continuous sequence of page numbers. This behavior is convenient for most documents but may not be ideal when you want to start numbering from a certain section without affecting the numbering in other parts of the document.
If you need to add page numbers to a specific section without them being linked to the previous section, you must unlink the subsequent sections and clear the contents of their footers. Here's how you can do it using Spire.Doc for Python.
- Create a Document object.
- Load a Word document from a specified file path.
- Get a specific section using Document.Sections[index] property
- Get the footer of the section using Section.HeadersFooters.Footer property.
- Restart page numbering from 1 by setting Section.PageSetup.RestartPageNumbering property to true and Section.PageSetup.PageStartingNumber property to 1.
- Insert a FieldPage field and a FieldSection field to the footer using Paragraph.AppendField() method.
- Disable "Link to previous" by setting HeadersFooters.Footer.LinkToPrevious propety to false.
- Delete the content of the footers in the subsequent sections
- Save the document to a different Word file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word file
document.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.docx")
# Get a specific section
sectionIndex = 1
section = document.Sections[sectionIndex]
# Restart page numbering from 1
section.PageSetup.RestartPageNumbering = True
section.PageSetup.PageStartingNumber = 1
# Get the footer of the section
footer = section.HeadersFooters.Footer
# Add "Page X, Section Y" to the footer
footerParagraph = footer.AddParagraph()
footerParagraph.AppendText("Page ")
footerParagraph.AppendField("page number", FieldType.FieldPage)
footerParagraph.AppendText(", Section ")
footerParagraph.AppendField("section number", FieldType.FieldSection)
footerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
# Apply formatting to the page number
style = ParagraphStyle(document);
style.CharacterFormat.Bold = True
style.CharacterFormat.FontName = "Times New Roman"
style.CharacterFormat.FontSize = 18
style.CharacterFormat.TextColor = Color.get_Red()
document.Styles.Add(style)
footerParagraph.ApplyStyle(style)
# Disable "Link to previous" in the subsequent section
document.Sections[sectionIndex + 1].HeadersFooters.Footer.LinkToPrevious = False
# Delete the content of the footers in the subsequent sections
for i in range(sectionIndex +1, document.Sections.Count, 1):
document.Sections[i].HeadersFooters.Footer.ChildObjects.Clear()
document.Sections[i].HeadersFooters.Footer.AddParagraph()
# Save the document
document.SaveToFile("Output/AddPageNumbersToSection.docx")
# Dispose resources
document.Dispose()

Add Discontinuous Page Numbers to Different Sections in Python
When working with documents that contain multiple sections, you might want to start page numbering anew for each section to clearly distinguish between them. To achieve this, you must go through each section individually, add page numbers, and then reset the page numbering for the next section.
The following are the steps to add discontinuous page numbers to different sections using Spire.Doc for Python.
- Create a Document object.
- Load a Word document from a specified file path.
- Iterate through the sections in the document.
- Get a specific section using Document.Sections[index] property
- Get the footer of the section using Section.HeadersFooters.Footer property.
- Restart page numbering from 1 by setting Section.PageSetup.RestartPageNumbering property to true and Section.PageSetup.PageStartingNumber property to 1.
- Insert a FieldPage field and a FieldSection field to the footer using Paragraph.AppendField() method.
- Save the document to a different Word file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word file
document.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.docx")
# Iterate through the sections in the document
for i in range(document.Sections.Count):
# Get a specific section
section = document.Sections[i]
# Restart page numbering from 1
section.PageSetup.RestartPageNumbering = True
section.PageSetup.PageStartingNumber = 1
# Get the footer of the section
footer = section.HeadersFooters.Footer
# Add "Page X, Section Y" to the footer
footerParagraph = footer.AddParagraph()
footerParagraph.AppendText("Page ")
footerParagraph.AppendField("page number", FieldType.FieldPage)
footerParagraph.AppendText(", Section ")
footerParagraph.AppendField("section number", FieldType.FieldSection)
footerParagraph.Format.HorizontalAlignment = HorizontalAlignment.Center
# Apply formatting to the page number
style = ParagraphStyle(document)
style.CharacterFormat.Bold = True
style.CharacterFormat.FontName = "Times New Roman";
style.CharacterFormat.FontSize = 18;
style.CharacterFormat.TextColor = Color.get_Red()
document.Styles.Add(style)
footerParagraph.ApplyStyle(style)
# Save the document
document.SaveToFile("Output/AddDifferentPageNumbersToSections.docx")
# Dispose resources
document.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create, Modify, and Copy Slide Master in PowerPoint Presentations
2024-05-13 01:14:23 Written by KoohjiSlide Master in PowerPoint presentations is a powerful feature that lies at the heart of designing consistent and professional-looking slideshows. It's essentially a blueprint or a template that controls the overall design and layout of the slides, allowing users to establish uniformity across presentations without having to manually format each slide individually. In this article, we will explore how to harness the power of Spire.Presentation for Python to create, modify, and apply slide masters in PowerPoint presentations within Python programs.
- Create and Apply Slide Masters in PowerPoint Presentations
- Modify Slide Masters in PowerPoint Presentations
- Copy Slide Masters Between PowerPoint Presentations
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to: How to Install Spire.Presentation for Python on Windows
Create and Apply Slide Masters in PowerPoint Presentations
Every PowerPoint presentation in PowerPoint, regardless of whether it is newly created or not, will have at least one slide master. Developers can modify the default master or create new ones and apply them to slides with Spire.Presentation for Python to achieve a consistent style and content layout across the presentation.
The detailed steps for creating new slide masters and applying them to the slides in a presentation file are as follows:
- Create an object of Presentation class and load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Create slide masters using Presentation.Masters.AppendSlide() method.
- Use the methods under IMasterSlide class to set the backgrounds, customize color schemes, insert images, shapes, and text, etc.
- Apply the slide masters to specific slides through ISlide.Layout property.
- Save the presentation using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of Presentation class
pres = Presentation()
# Load a Presentation file
pres.LoadFromFile("Sample.pptx")
# Add a cover slide master and a body slide master
master1 = pres.Masters.AppendSlide(pres.Masters.get_Item(0))
coverMaster = pres.Masters.get_Item(master1)
master2 = pres.Masters.AppendSlide(pres.Masters.get_Item(0))
bodyMaster = pres.Masters.get_Item(master2)
# Set background images for the two slide masters
pic1 = "Background1.jpg"
pic2 = "Background2.jpg"
rect = RectangleF.FromLTRB (0, 0, pres.SlideSize.Size.Width, pres.SlideSize.Size.Height)
coverMaster.SlideBackground.Fill.FillType = FillFormatType.Picture
image1 = coverMaster.Shapes.AppendEmbedImageByPath (ShapeType.Rectangle, pic1, rect)
coverMaster.SlideBackground.Fill.PictureFill.Picture.EmbedImage = image1.PictureFill.Picture.EmbedImage
bodyMaster.SlideBackground.Fill.FillType = FillFormatType.Picture
image2 = bodyMaster.Shapes.AppendEmbedImageByPath (ShapeType.Rectangle, pic2, rect)
bodyMaster.SlideBackground.Fill.PictureFill.Picture.EmbedImage = image2.PictureFill.Picture.EmbedImage
# Insert a logo to the body slide master
logo = "Logo.png"
bodyMaster.Shapes.AppendEmbedImageByPath(ShapeType.Rectangle, logo, RectangleF.FromLTRB(pres.SlideSize.Size.Width - 110, 10, pres.SlideSize.Size.Width - 10, 110))
# Insert text to the body slide master
shape = bodyMaster.Shapes.AppendShape(ShapeType.Rectangle, RectangleF.FromLTRB(pres.SlideSize.Size.Width - 210, 110, pres.SlideSize.Size.Width - 10, 150))
shape.Fill.FillType = FillFormatType.none
shape.Line.FillType = FillFormatType.none
shape.TextFrame.Text = "Spire.Presentation"
# Set the color scheme for the two slide masters
coverMaster.Theme.ColorScheme.Accent1.Color = Color.get_Red()
coverMaster.Theme.ColorScheme.Accent2.Color = Color.get_Blue()
bodyMaster.Theme.ColorScheme.Accent1.Color = Color.get_Brown()
coverMaster.Theme.ColorScheme.Accent2.Color = Color.get_Green()
# Apply the first master with layout to the first slide
pres.Slides.get_Item(0).Layout = coverMaster.Layouts.GetByType(SlideLayoutType.Title)
# Apply the second master with layout to other slides
for i in range(1, pres.Slides.Count):
pres.Slides.get_Item(i).Layout = bodyMaster.Layouts.GetByType(SlideLayoutType.TitleAndObject)
# Save the document
pres.SaveToFile("output/CreateAndApplySlideMaster.pptx", FileFormat.Pptx2016)
pres.Dispose()
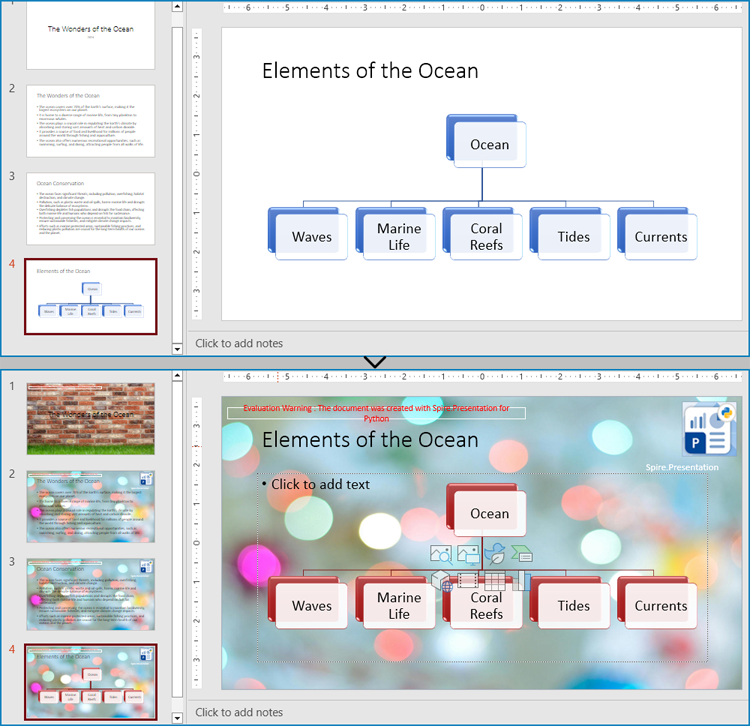
Modify Slide Masters in PowerPoint Presentations
A presentation can have multiple slide masters, which can be applied to different slides to achieve a unified style application and modification for different types of slides.
The Presentation.Masters.get_Item() method in Spire.Presentation for Python allows developers to retrieve the specified slide master in the presentation by index and modify the master. The following step-by-step example demonstrates how to retrieve a slide master and modify its background, color scheme, and embedded images:
- Create an object of Presentation class and load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Get a slide master through Presentation.Masters property.
- Use the methods under IMasterSlide class to change the background, set the color scheme, delete and insert text and images, etc.
- Save the presentation using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an object of Presentation
pres = Presentation()
# Load a PowerPoint presentation
pres.LoadFromFile("output/CreateAndApplySlideMaster.pptx")
# Get the third slide master
master = pres.Masters[2]
# Change the background
master.SlideBackground.Type = BackgroundType.Custom
master.SlideBackground.Fill.FillType = FillFormatType.Solid
master.SlideBackground.Fill.SolidColor.Color = Color.get_LightBlue()
# Change the color sheme
master.Theme.ColorScheme.Accent1.Color = Color.get_Red()
master.Theme.ColorScheme.Accent2.Color = Color.get_Green()
# Remove the pictures in the slide master
pictures = [shape for shape in master.Shapes if isinstance(shape, SlidePicture)]
for picture in pictures:
master.Shapes.Remove(picture)
# Change the text in the slide master
texts = [shape for shape in master.Shapes if isinstance(shape, IAutoShape)]
for text in texts:
if len(text.TextFrame.Text) != 0:
text.TextFrame.Text = "Spire.Presentation for Python"
# Save the presentation
pres.SaveToFile("output/ModifySlideMaster.pptx", FileFormat.Pptx2016)
pres.Dispose()
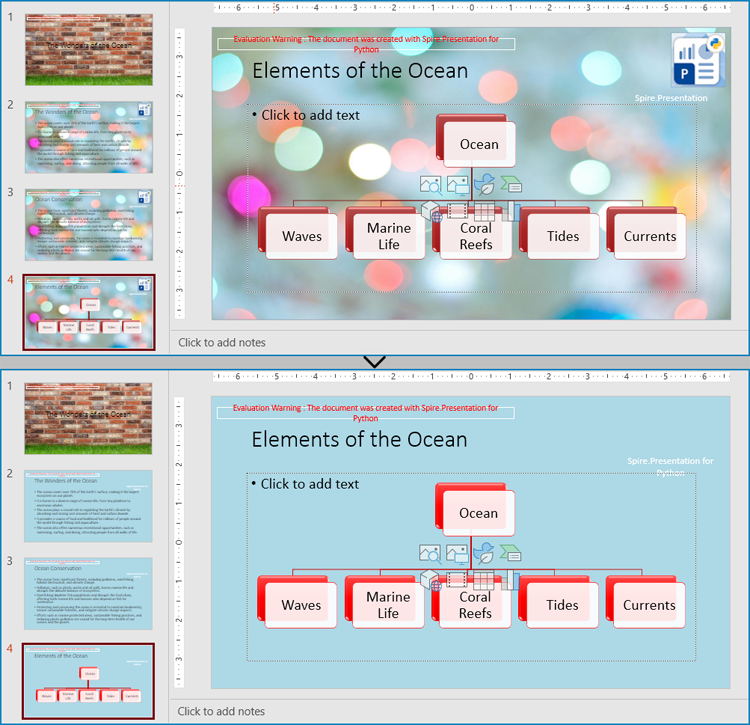
Copy Slide Masters Between PowerPoint Presentations
Applying the slide style of a presentation to another presentation can be achieved by copying the slide master between presentations and applying the master style to the specified slides. The following are the steps to copy the slide master between presentations and apply it to the specified slides:
- Create two objects of Presentation class and load two presentation documents using Presentation.LoadFromFile() method.
- Get the slide master of the second presentation using Presentation.Masters.get_Item() method.
- Add the slide master to the first presentation using Presentation.Masters.AppendSlide() method.
- Apply the slide master to the slides in the second presentation through ISlide.Layout property.
- Save the first presentation using Presentation.SaveToFile() method.
- Python
from spire.presentation import *
from spire.presentation.common import *
# Create two objects of Presentation
pres1 = Presentation()
pres2 = Presentation()
# Load two PowerPoint documents
pres1.LoadFromFile("Sample.pptx")
pres2.LoadFromFile("Template.pptx")
# Get the slide master of the second presentation
master = pres2.Masters.get_Item(0)
# Add the slide master to the first presentation
index = pres1.Masters.AppendSlide(master)
# Apply the slide master to the first presentation
pres1.Slides.get_Item(0).Layout = pres1.Masters.get_Item(index).Layouts.GetByType(SlideLayoutType.Title)
for i in range(1, pres1.Slides.Count):
pres1.Slides.get_Item(i).Layout = pres1.Masters.get_Item(index).Layouts.GetByType(SlideLayoutType.TitleAndObject)
# Save the first presentation
pres1.SaveToFile("output/CopySlideMaster.pptx", FileFormat.Pptx2013)
pres1.Dispose()
pres2.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
TIFF is a popular image format used in scanning and archiving due to its high quality and support for a wide range of color spaces. On the other hand, PDFs are widely used for document exchange because they preserve the layout and formatting of a document while compressing the file size. Conversion between these formats can be useful for various purposes such as archival, editing, or sharing documents.
In this article, you will learn how to convert PDF to TIFF and TIFF to PDF using the Spire.PDF for Python and Pillow libraries.
Install Spire.PDF for Python
This situation relies on the combination of Spire.PDF for Python and Pillow (PIL). Spire.PDF is used to read, create and convert PDF documents, while the PIL library is used for handling TIFF files and accessing their frames.
The libraries can be easily installed on your device through the following pip command.
pip install Spire.PDF pip install pillow
Convert PDF to TIFF in Python
To complete the PDF to TIFF conversion, you first need to load the PDF document and convert the individual pages into image streams using Spire.PDF. Subsequently, these image streams are then merged together using the functionality of the PIL library, resulting in a consolidated TIFF image.
The following are the steps to convert PDF to TIFF using Python.
- Create a PdfDocument object.
- Load a PDF document from a specified file path.
- Iterate through the pages in the document.
- Convert each page into an image stream using PdfDocument.SaveAsImage() method.
- Convert the image stream into a PIL image.
- Combine these PIL images into a single TIFF image.
- Python
from spire.pdf.common import *
from spire.pdf import *
from PIL import Image
from io import BytesIO
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Create an empty list to store PIL Images
images = []
# Iterate through all pages in the document
for i in range(doc.Pages.Count):
# Convert a specific page to an image stream
with doc.SaveAsImage(i) as imageData:
# Open the image stream as a PIL image
img = Image.open(BytesIO(imageData.ToArray()))
# Append the PIL image to list
images.append(img)
# Save the PIL Images as a multi-page TIFF file
images[0].save("Output/ToTIFF.tiff", save_all=True, append_images=images[1:])
# Dispose resources
doc.Dispose()
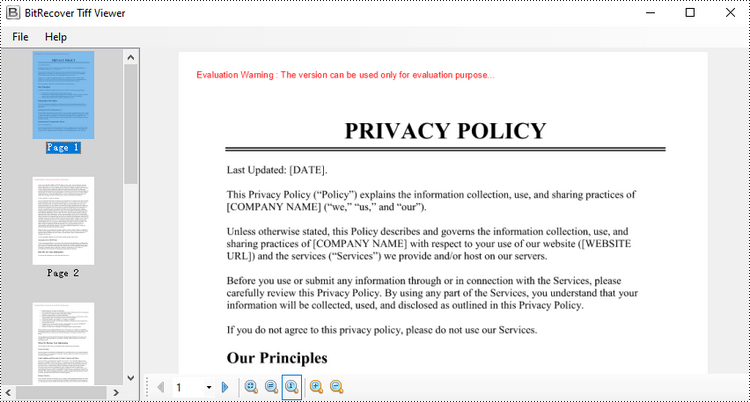
Convert TIFF to PDF in Python
With the assistance of the PIL library, you can load a TIFF file and transform each frame into distinct PNG files. Afterwards, you can utilize Spire.PDF to draw these PNG files onto pages within a PDF document.
To convert a TIFF image to a PDF document using Python, follow these steps.
- Create a PdfDocument object.
- Load a TIFF image.
- Iterate though the frames in the TIFF image.
- Get a specific frame, and save it as a PNG file.
- Add a page to the PDF document.
- Draw the image on the page at the specified location using PdfPageBase.Canvas.DrawImage() method.
- Save the document to a PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
from PIL import Image
import io
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a TIFF image
tiff_image = Image.open("C:\\Users\\Administrator\\Desktop\\TIFF.tiff")
# Iterate through the frames in it
for i in range(tiff_image.n_frames):
# Go to the current frame
tiff_image.seek(i)
# Extract the image of the current frame
frame_image = tiff_image.copy()
# Save the image to a PNG file
frame_image.save(f"temp/output_frame_{i}.png")
# Load the image file to PdfImage
image = PdfImage.FromFile(f"temp/output_frame_{i}.png")
# Get image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page to the document
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save the document to a PDF file
doc.SaveToFile("Output/TiffToPdf.pdf",FileFormat.PDF)
# Dispose resources
doc.Dispose()
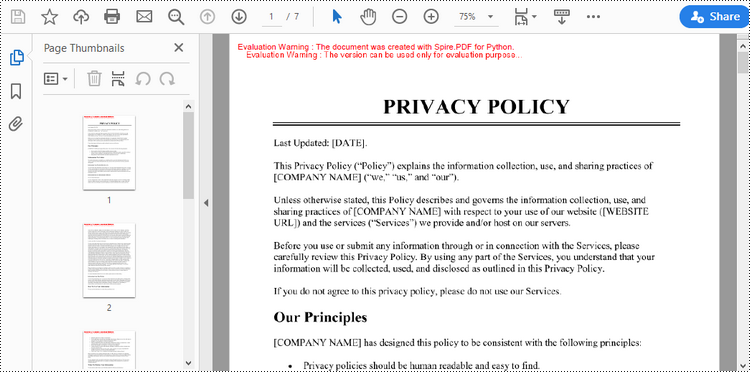
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
In the modern office environment, Microsoft Word has become an indispensable part of our daily work and study. Whether it's writing reports, creating resumes, or designing promotional materials, Word provides us with a rich set of features and tools. Among them, the function of adding shapes is particularly popular among users because it allows us to easily enhance the visual appeal and expressiveness of documents. Manipulating shape elements is one of the highlights of Spire.Doc functionality, and this article will introduce you to how to add or delete shapes in Word using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Add Shapes in Word Document in Python
Spire.Doc for Python supports adding various shapes such as rectangles, trapezoids, triangles, arrows, lines, emoticons, and many other predefined shape types. By calling the Paragraph.AppendShape(width: float, height: float, shapeType: 'ShapeType') method, you can not only easily insert these shapes at any position in the document but also customize various properties of the shapes, such as fill color, border style, rotation angle, transparency, etc., to meet different typesetting needs and visual effects. Below are the detailed steps:
- Create a new Document object.
- Call Document.AddSection() and Section.AddParagraph() methods to add a section and a paragraph within the section, respectively.
- Call the Paragraph.AppendShape(width: float, height: float, shapeType: 'ShapeType') method to add a shape on the paragraph, where width and height represent the dimensions of the shape, and shapeType enum is used to specify the type of shape.
- Define the style of the shape, such as fill color, border color, border style, and width.
- Set the horizontal and vertical position of the shape relative to the page.
- Add multiple other types of shapes using the same method.
- Save the document using the Document.SaveToFile() method.
- Python
from spire.doc import * from spire.doc.common import * # Create a new Document object doc = Document() # Add a new section in the document sec = doc.AddSection() # Add a paragraph in the new section para = sec.AddParagraph() # Add a rectangle shape in the paragraph with width and height both 60 shape1 = para.AppendShape(60, 60, ShapeType.Rectangle) # Define the fill color of the shape shape1.FillColor = Color.get_YellowGreen() # Define the border color shape1.StrokeColor = Color.get_Gray() # Define the border style and width shape1.LineStyle = ShapeLineStyle.Single shape1.StrokeWeight = 1 # Set the horizontal and vertical position of the shape relative to the page shape1.HorizontalOrigin = HorizontalOrigin.Page shape1.HorizontalPosition = 100 shape1.VerticalOrigin = VerticalOrigin.Page shape1.VerticalPosition = 200 # Similarly, add a triangle shape in the same paragraph and set its properties shape2 = para.AppendShape(60, 60, ShapeType.Triangle) shape2.FillColor = Color.get_Green() shape2.StrokeColor = Color.get_Gray() shape2.LineStyle = ShapeLineStyle.Single shape2.StrokeWeight = 1 shape2.HorizontalOrigin = HorizontalOrigin.Page shape2.HorizontalPosition = 200 shape2.VerticalOrigin = VerticalOrigin.Page shape2.VerticalPosition = 200 # Add an arrow shape and set its properties shape3 = para.AppendShape(60, 60, ShapeType.Arrow) shape3.FillColor = Color.get_SeaGreen() shape3.StrokeColor = Color.get_Gray() shape3.LineStyle = ShapeLineStyle.Single shape3.StrokeWeight = 1 shape3.HorizontalOrigin = HorizontalOrigin.Page shape3.HorizontalPosition = 300 shape3.VerticalOrigin = VerticalOrigin.Page shape3.VerticalPosition = 200 # Add a smiley face shape and set its properties shape4 = para.AppendShape(60, 60, ShapeType.SmileyFace) shape4.FillColor = Color.get_LightGreen() shape4.StrokeColor = Color.get_Gray() shape4.LineStyle = ShapeLineStyle.Single shape4.StrokeWeight = 1 shape4.HorizontalOrigin = HorizontalOrigin.Page shape4.HorizontalPosition = 400 shape4.VerticalOrigin = VerticalOrigin.Page shape4.VerticalPosition = 200 # Save the document outputFile = "AddShapes.docx" doc.SaveToFile(outputFile, FileFormat.Docx2016) # Release the document doc.Close()

Add Shape Group in Word Document
Spire.Doc for Python not only provides the functionality to add individual shapes (such as rectangles, circles, lines, etc.) but also supports creating and managing grouped shapes. A grouped shape is a special collection of shapes that organizes multiple independent shapes together to form a whole, sharing the same transformation properties (such as position, rotation angle, etc.). Here are the specific steps to achieve this:
- Create an object of the Document class.
- Call the Document.AddSection() method to add a blank section.
- Call the Section.AddParagraph() method to add a blank paragraph in the section.
- Call Paragraph.AppendShapeGroup() to add a shape group and specify its dimensions.
- Create a Textbox and specify its shape type, dimensions, position, fill color, and other properties.
- Add paragraphs within the Textbox and insert text, setting the paragraph's horizontal alignment to center.
- Add the Textbox to the list of child objects of the shape group.
- Similar to the above steps, create shapes for symbols like arrows, diamond-shaped text boxes, octagonal text boxes, and set their properties, adding them to the list of child objects of the shape group.
- Save the document using the Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Add a section to the document
sec = doc.AddSection()
# Add a paragraph to the section
para = sec.AddParagraph()
# Add a shape group to the paragraph and specify its horizontal position
shapegroup = para.AppendShapeGroup(375, 350)
shapegroup.HorizontalPosition = 180
# Calculate the relative unit scale X and Y for the shape group for subsequent element size positioning
X = float((shapegroup.Width / 1000.0))
Y = float((shapegroup.Height / 1000.0))
# Create a rounded rectangle text box
txtBox = TextBox(doc)
# Set the shape type of the text box
txtBox.SetShapeType(ShapeType.RoundRectangle)
# Set the width and height of the text box
txtBox.Width = 125 / X
txtBox.Height = 54 / Y
# Add a paragraph inside the text box and set its horizontal alignment to center
paragraph = txtBox.Body.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
# Add the text "Step One" to the paragraph
paragraph.AppendText("Step One")
# Set the horizontal and vertical position of the text box
txtBox.HorizontalPosition = 19 / X
txtBox.VerticalPosition = 27 / Y
# Set the fill color of the text box and remove the border line
txtBox.Format.FillColor = Color.FromRgb(153, 255, 255)
txtBox.Format.NoLine = True
# Add the text box to the list of child objects of the shape group
shapegroup.ChildObjects.Add(txtBox)
# Create a downward arrow shape and specify its shape type
arrowLineShape = ShapeObject(doc, ShapeType.DownArrow)
# Set the width and height of the arrow shape
arrowLineShape.Width = 16 / X
arrowLineShape.Height = 40 / Y
# Set the horizontal and vertical position of the arrow shape
arrowLineShape.HorizontalPosition = 73 / X
arrowLineShape.VerticalPosition = 87 / Y
# Set the stroke color of the arrow shape
arrowLineShape.StrokeColor = Color.get_CadetBlue()
# Add the arrow shape to the list of child objects of the shape group
shapegroup.ChildObjects.Add(arrowLineShape)
# (Similar subsequent code, creating diamond-shaped text boxes, downward arrow shapes, and octagonal text boxes, with corresponding property settings and positioning)
txtBox = TextBox(doc)
txtBox.SetShapeType(ShapeType.Diamond)
txtBox.Width = 125 / X
txtBox.Height = 54 / Y
paragraph = txtBox.Body.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText("Step Two")
txtBox.HorizontalPosition = 19 / X
txtBox.VerticalPosition = 131 / Y
txtBox.Format.FillColor = Color.FromRgb(0, 102, 102)
txtBox.Format.NoLine = True
shapegroup.ChildObjects.Add(txtBox)
arrowLineShape = ShapeObject(doc, ShapeType.DownArrow)
arrowLineShape.Width = 16 / X
arrowLineShape.Height = 40 / Y
arrowLineShape.HorizontalPosition = 73 / X
arrowLineShape.VerticalPosition = 192 / Y
arrowLineShape.StrokeColor = Color.get_CadetBlue()
shapegroup.ChildObjects.Add(arrowLineShape)
txtBox = TextBox(doc)
txtBox.SetShapeType(ShapeType.Octagon)
txtBox.Width = 149 / X
txtBox.Height = 59 / Y
paragraph = txtBox.Body.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText("Step Three")
txtBox.HorizontalPosition = 7 / X
txtBox.VerticalPosition = 236 / Y
txtBox.Format.FillColor = Color.FromRgb(51, 204, 204)
txtBox.Format.NoLine = True
shapegroup.ChildObjects.Add(txtBox)
# Define the output file name
outputFile = "ShapeGroup.docx"
# Save the document
doc.SaveToFile(outputFile, FileFormat.Docx2016)
# Close the document object
doc.Close()
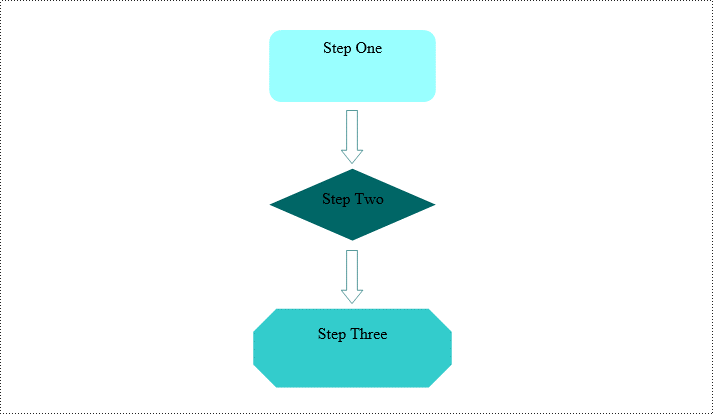
Remove Shapes from Word Document
Spire.Doc for Python supports efficiently removing individual shapes and shape groups from a Word document. Below are the detailed steps:
- Create an object of the Document class.
- Call the Document.LoadFromFile() method to load a document containing shapes.
- Traverse through all the sections of the document and the body elements within the sections to get paragraphs.
- Check if the child elements under the paragraph are shape objects or shape group objects.
- Call the Paragraph.ChildObjects.Remove() method to remove the shape object.
- Save the document using the Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of the Document class
doc = Document()
# Load a Word document
doc.LoadFromFile("ShapeGroup.docx")
# Iterate through all sections of the document
for s in range(doc.Sections.Count):
# Get the current section
section = doc.Sections[s]
# Iterate through all child objects within the section
for i in range(section.Body.ChildObjects.Count):
# Get the current child object
document_object = section.Body.ChildObjects[i]
# If the current child object is a paragraph
if isinstance(document_object, Paragraph):
# Convert the child object to a paragraph object
paragraph = document_object
# Initialize the inner loop index
j = 0
# Iterate through all child objects within the paragraph
while j < paragraph.ChildObjects.Count:
# Get the current child object within the paragraph
c_obj = paragraph.ChildObjects[j]
# If the current child object is a shape group or shape object
if isinstance(c_obj, ShapeGroup) or isinstance(c_obj, ShapeObject):
# Remove the shape object from the paragraph
paragraph.ChildObjects.Remove(c_obj)
# Update the inner loop index
j -= 1
# Increment the inner loop index
j += 1
# Save the document
doc.SaveToFile("RemovedShapes.docx", FileFormat.Docx2016)
# Close the document object
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
In Microsoft Excel, text alignment and text orientation are crucial formatting options for optimizing the presentation of text within cells. Text alignment determines the horizontal or vertical positioning of text within a cell, while text orientation controls the tilt angle or display direction of the text. By flexibly utilizing these formatting options, you can customize the appearance of text within cells to create professional and visually appealing spreadsheets. In this article, we will demonstrate how to set text alignment and orientation in Excel in Python using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Set Text Alignment and Orientation in Excel in Python
Spire.XLS for Python provides the CellRange.Style.HorizontalAlignment and CellRange.Style.VerticalAlignment properties that enable you to customize the horizontal and vertical alignment of text in a single cell or range of cells. Additionally, it allows you to change the orientation of text by applying rotation to cells using the CellRange.Style.Rotation property. The detailed steps are as follows:
- Create an object of the Workbook class.
- Load an Excel file using the Workbook.LoadFromFile() method.
- Get a specific worksheet using the Workbook.Worksheets[index] property.
- Set the horizontal alignment for text in specific cells to Left, Center, Right, or General using the CellRange.Style.HorizontalAlignment property.
- Set the vertical alignment for text in specific cells to Top, Center, or Bottom using the CellRange.Style.VerticalAlignment property.
- Change the orientation for text in specific cells using the CellRange.Style.Rotation property.
- Save the result file using the Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create an object of the Workbook class
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Example.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Set the horizontal alignment for text in a specific cell to Left
sheet.Range["B1"].Style.HorizontalAlignment = HorizontalAlignType.Left
# Set the horizontal alignment for text in a specific cell to Center
sheet.Range["B2"].Style.HorizontalAlignment = HorizontalAlignType.Center
# Set the horizontal alignment for text in a specific cell to Right
sheet.Range["B3"].Style.HorizontalAlignment = HorizontalAlignType.Right
# Set the horizontal alignment for text in a specific cell to General
sheet.Range["B4"].Style.HorizontalAlignment = HorizontalAlignType.General
# Set the vertical alignment for text in a specific cell to Top
sheet.Range["B5"].Style.VerticalAlignment = VerticalAlignType.Top
# Set the vertical alignment for text in a specific cell to Center
sheet.Range["B6"].Style.VerticalAlignment = VerticalAlignType.Center
# Set the vertical alignment for text in a specific cell to Bottom
sheet.Range["B7"].Style.VerticalAlignment = VerticalAlignType.Bottom
# Change the text orientation in specific cells by applying rotation
sheet.Range["B8"].Style.Rotation = 45
sheet.Range["B9"].Style.Rotation = 90
# Save the result file
workbook.SaveToFile("TextAlignmentAndOrientation.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
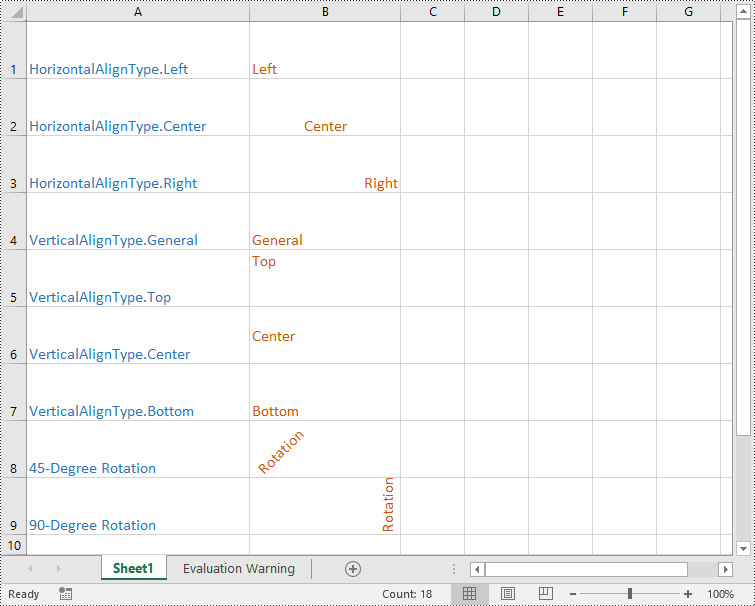
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.XLS for Python is a high-performance library for reading and writing Excel spreadsheets in Python. With Spire.XLS, you can create, read, edit, and convert XLS and XLSX files without the need for Microsoft Excel to be installed on your system.
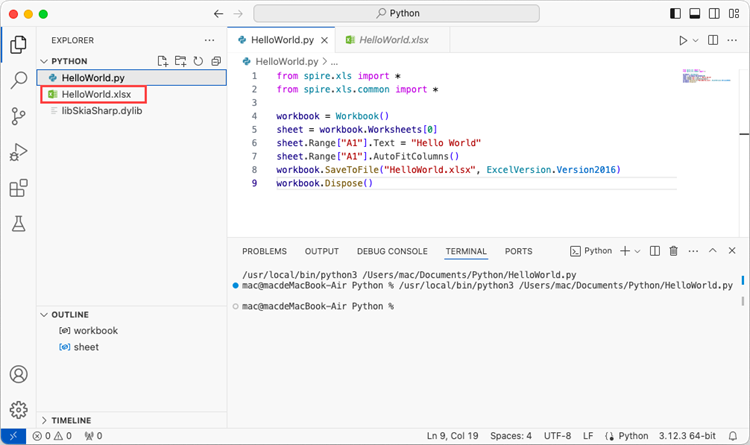
This article demonstrates how to install Spire.XLS for Python on Mac.
Step 1
Download the most recent version of Python for macOS and install it on your Mac. If you have already completed this step, proceed directly to step 2.
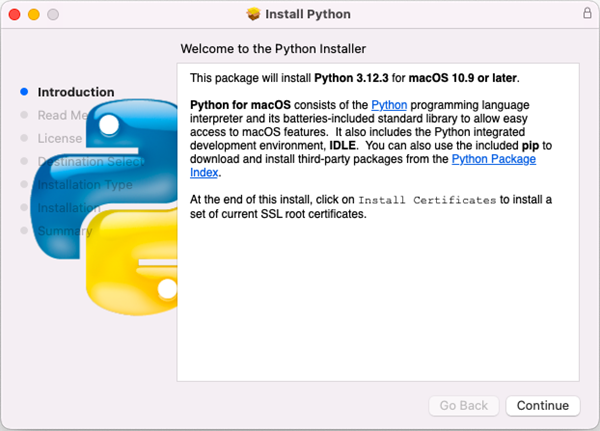
Step 2
Open VS Code and search for 'Python' in the Extensions panel. Click 'Install' to add support for Python in your VS Code.
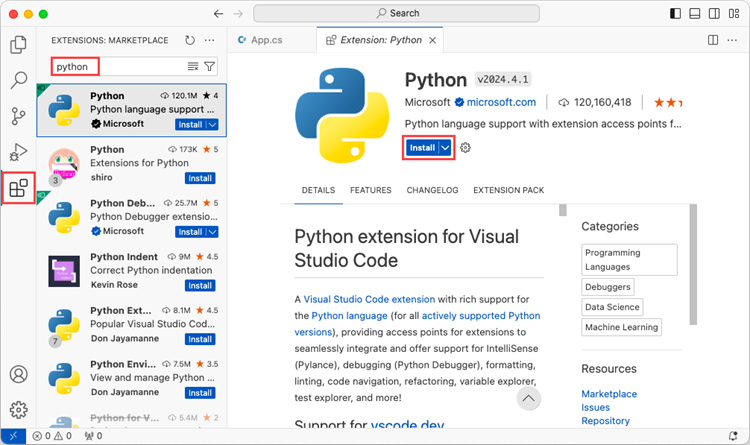
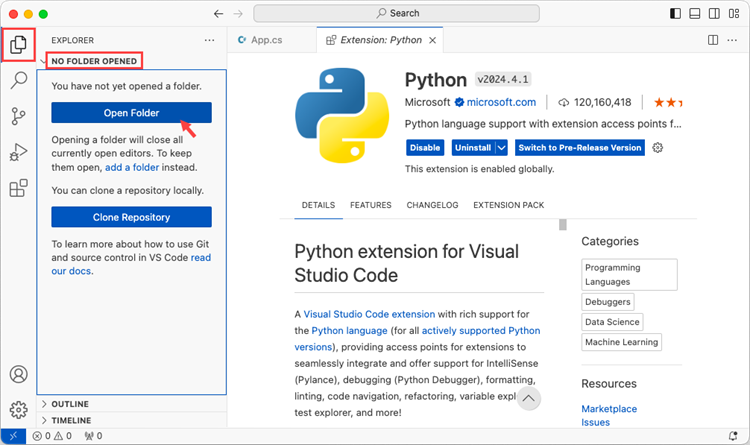
Step 3
Click 'Explorer' > 'NO FOLRDER OPENED' > 'Open Folder'.
Choose an existing folder as the workspace, or you can create a new folder and then open it.
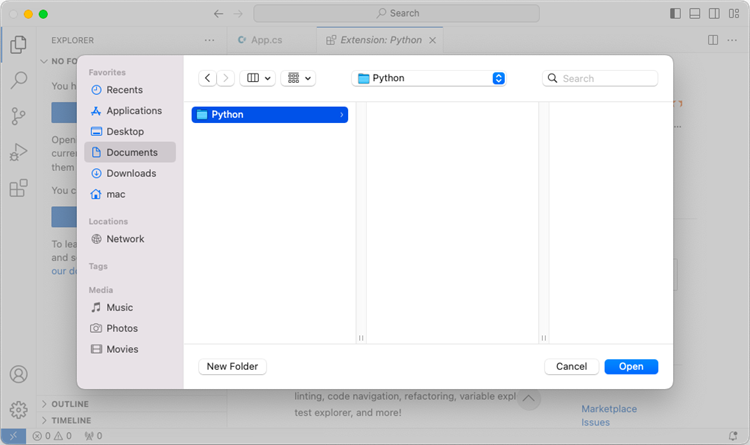
Add a .py file to the folder you just opened and name it whatever you want (in this case, HelloWorld.py).
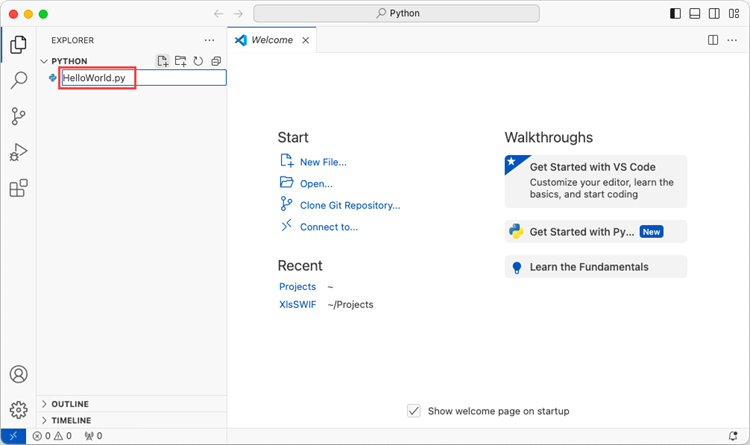
Step 4
Use the keyboard shortcut Ctrl + ` to open the Terminal. Then, install Spire.XLS for Python by entering the following command line in the terminal.
pip3 install spire.xls
Note that pip3 is a package installer specifically designed for Python 3.x versions, while pip is a package installer for Python 2.x versions. If you are working with Python 2.x, you can use the pip command.
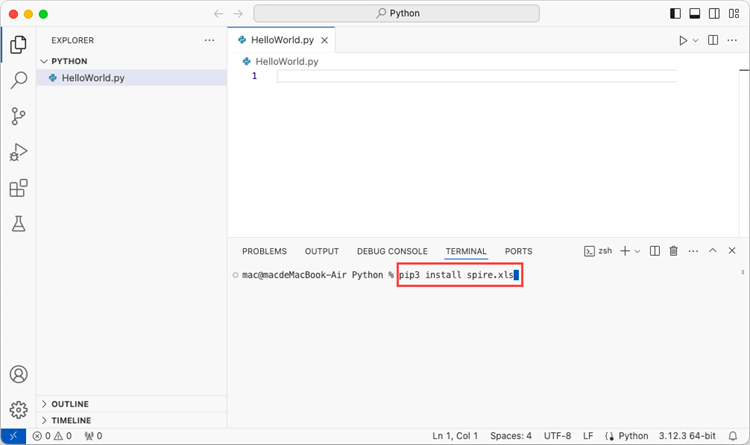
Step 5
Open a Terminal window on your Mac, and type the following command to obtain the installation path of Python on your system.
python3 -m pip --version
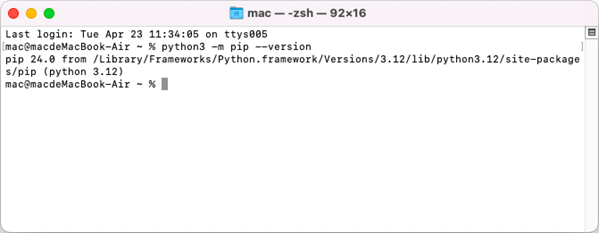
Step 6
Add the following code snippet to the 'HelloWorld.py' file.
- Python
from spire.xls.common import *
from spire.xls import *
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Range["A1"].Text = "Hello World"
sheet.Range["A1"].AutoFitColumns()
workbook.SaveToFile("HelloWorld.xlsx", ExcelVersion.Version2010)
workbook.Dispose()
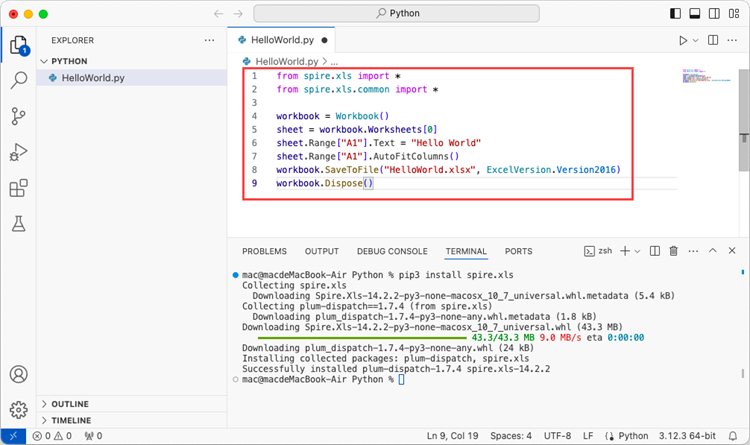
After executing the Python file, you will find the resulting Excel document displayed in the 'EXPLORER' panel.