
Tables in PDFs often contain valuable data that may need to be analyzed, processed, or visualized. Extracting tables from PDFs enables you to import the data into spreadsheet software or data analysis tools, where you can perform calculations, generate charts, apply statistical analysis, and gain insights from the information. In this article, we will demonstrate how to extract tables from PDF in Python using Spire.PDF for Python and Spire.XLS for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and Spire.XLS for Python. Spire.PDF is responsible for extracting data from PDF tables, and Spire.XLS is responsible for creating an Excel document based on the data obtained from PDF.
Spire.PDF for Python and Spire.XLS for Python can be easily installed in your Windows through the following pip commands.
pip install Spire.PDF pip install Spire.XLS
If you are unsure how to install, please refer to these tutorials:
Extract Tables from PDF in Python
Spire.PDF for Python offers the PdfTableExtractor.ExtractTable(pageIndex) method to extract tables from a page in a searchable PDF document. After the tables are extracted, you can loop through the rows and columns in each table and then get the text contained within each table cell using the PdfTable.GetText(rowIndex, columnIndex) method. The detailed steps are as follows:
- Create an instance of PdfDocument class.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Loop through the pages in the PDF document.
- Extract tables from the pages using PdfTableExtractor.ExtractTable() method.
- Loop through the extracted tables.
- Get the text of the cells in the tables using PdfTable.GetText() method and save them to a list.
- Write the content of the list into a .txt file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load the sample PDF file
doc.LoadFromFile("TableExample.pdf")
# Create a list to store the extracted data
builder = []
# Create a PdfTableExtractor object
extractor = PdfTableExtractor(doc)
# Loop through the pages
for pageIndex in range(doc.Pages.Count):
# Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
# Determine if the table list is not empty
if tableList is not None and len(tableList) > 0:
# Loop through the tables in the list
for table in tableList:
# Get row number and column number of a certain table
row = table.GetRowCount()
column = table.GetColumnCount()
# Loop through the row and column
for i in range(row):
for j in range(column):
# Get text from the specific cell
text = table.GetText(i, j)
# Add the text to the list
builder.append(text + " ")
builder.append("\n")
builder.append("\n")
# Write the content of the list into a text file
with open("Table.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
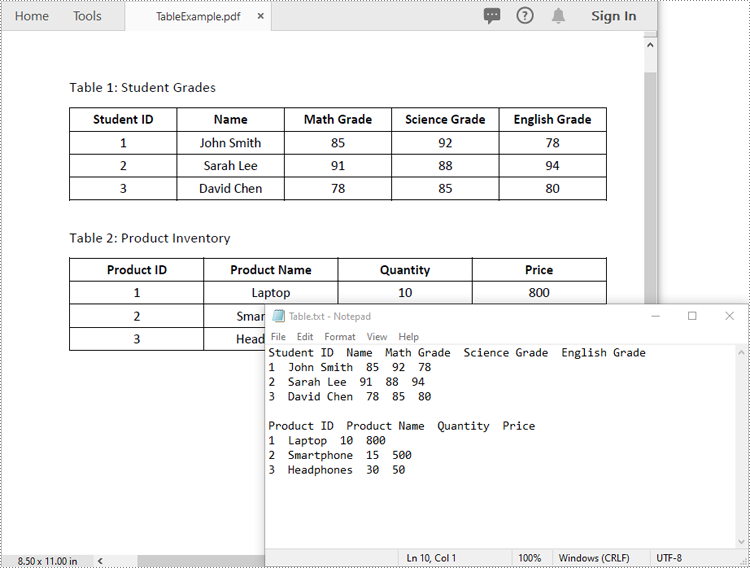
Extract Tables from PDF to Excel in Python
After you get the text of each table cell, you can write it into an Excel worksheet for further analysis by using the Worksheet.Range[rowIndex, columnIndex].Value property offered by Spire.XLS for Python. The detailed steps are as follows:
- Create an instance of PdfDocument class.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Create an instance of Workbook class and clear the default worksheets in it.
- Loop through the pages in the PDF document.
- Extract tables from the pages using PdfTableExtractor.ExtractTable() method.
- Loop through the extracted tables.
- For each table, add a worksheet to the workbook using Workbook.Worksheets.Add() method.
- Get the text of the cells in the table using PdfTable.GetText() method.
- Write the text to specific cells in the worksheet using Worksheet.Range[rowIndex, columnIndex].Value property.
- Save the resultant workbook to an Excel file using Workbook.SaveToFile() method.
- Python
from spire.pdf import *
from spire.xls import *
# Create a PdfDocument object
doc = PdfDocument()
# Load the sample PDF file
doc.LoadFromFile("TableExample.pdf")
# Create a Workbook object
workbook = Workbook()
# Clear default worksheets
workbook.Worksheets.Clear()
# Create a PdfTableExtractor object
extractor = PdfTableExtractor(doc)
sheetNumber = 1
# Loop through the pages
for pageIndex in range(doc.Pages.Count):
# Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
# Determine if the table list is not empty
if tableList is not None and len(tableList) > 0:
# Loop through the tables in the list
for table in tableList:
# Add a worksheet
sheet = workbook.Worksheets.Add(f"sheet{sheetNumber}")
# Get row number and column number of a certain table
row = table.GetRowCount()
column = table.GetColumnCount()
# Loop through the rows and columns
for i in range(row):
for j in range(column):
# Get text from the specific cell
text = table.GetText(i, j)
# Write text to a specified cell
sheet.Range[i + 1, j + 1].Value = text
# Auto-fit columns
sheet.AllocatedRange.AutoFitColumns()
sheetNumber += 1
# Save to file
workbook.SaveToFile("ToExcel.xlsx", ExcelVersion.Version2013)
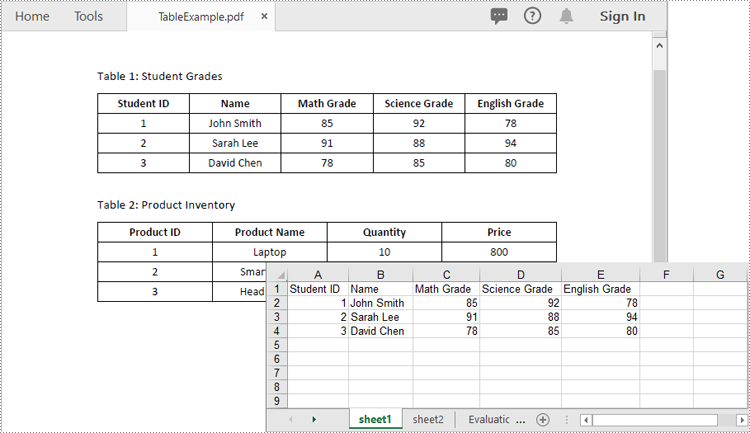
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

