
Spire.Presentation 9.11.3 support setting whether to save SlidePicture shapes as graphic tags when converting PowerPoint to SVG
We're glad to announce the release of Spire.Presentation 9.11.3. This version adds a new property to set whether to save SlidePicture shapes as graphic tags when converting PPTX to SVG, and also fix several issues that occurred when converting PPTX to PDFA/SVG, and loading PowerPoint files. Check below for more details.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPPT-2636 | Adds a new boolean property "ppt.SaveToSvgOption.ConvertPictureUsingGraphicTag" to set whether to save SlidePicture shapes as graphic tags when converting PPTX to SVG.
ppt.SaveToSvgOption.ConvertPictureUsingGraphicTag = true; |
| Bug | SPIREPPT-2552 | Fixes the issue that PDFA standards were not applied when converting PPTX documents to PDFA documents. |
| Bug | SPIREPPT-2615 | Fixes the issue that the text direction was incorrect when converting PPTX documents to SVG files. |
| Bug | SPIREPPT-2628 | Fixes the issue that the background color was incorrect when using the "shape.SaveAsSvgInSlide()" method to convert to SVG documents. |
| Bug | SPIREPPT-2629 | Fixes the issue that the text was not properly aligned when converting slides to SVG documents. |
| Bug | SPIREPPT-2631 | Fixes the issue that the application threw "System.NullReferenceException: Object reference not set to an instance of an object" exception when loading PPTX documents. |
Spire.Presentation for Python 9.11.1 supports the functionality to get the slides from "section"
We are pleased to announce the release of Spire.Presentation for Python 9.11.1. The latest version supports the functionality to get the slides from "section". Moreover, some known bugs are fixed successfully in this update, such as the issue that errors occurred when using SlideCountPerPageForPrint and ContainingHiddenSlides methods. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPPT-2575 | Supports the functionality to get the slides from "section".
ppt = Presentation()
ppt.LoadFromFile(inputFile)
section=ppt.SectionList[0]
slides=section.GetSlides()
sb = [] i=0 for slide in slides:
sb.append("SlideID:"+str(slides[i].SlideID))
i=i+1
File.AppendAllText(outputFile, sb)
ppt.Dispose
|
| New feature | SPIREPPT-2605 | Supports the functionality to get the Left and Top values of SmartArt.
# Create a Presentation oject
presentation = Presentation()
# Load a PowerPoint document
presentation.LoadFromFile(inputFile)
sb = []
# Get custom document properties
for shape in presentation.Slides[0].Shapes:
if isinstance(shape, ISmartArt):
sa = shape if isinstance(shape, ISmartArt) else None
sb.append("left: " + str(sa.Left))
sb.append("top: " + str(sa.Top))
File.AppendAllText(outputFile, sb)
presentation.Dispose()
|
| New feature | SPIREPPT-2621 | Supports the DisplayFormat property.
# Create a Presentation oject
presentation = Presentation()
presentation.LoadFromFile(inputFile)
shape = presentation.Slides[0].Shapes[0]
textrange = shape.TextFrame.Paragraphs[0].TextRanges[0]
displayformat = textrange.DisplayFormat
sb = []
sb.append("text :" + str(textrange.Text))
sb.append("is bold :" + str(displayformat.IsBold))
sb.append("is italic :" + str(displayformat.IsItalic))
sb.append("latin_font FontName = :" + str(displayformat.LatinFont.FontName))
File.AppendAllText(outputFile, sb)
presentation.Dispose()
|
| Bug | SPIREPPT-2503 | Fixes the issue that errors occurred when using SlideCountPerPageForPrint and ContainingHiddenSlides methods. |
| Bug | SPIREPPT-2564 SPIREPPT-2566 |
Fixes the issue that there were incorrect layouts when converting PPT to PDF. |
| Bug | SPIREPPT-2618 | Optimized the time consumption issue of converting PPT to images. |
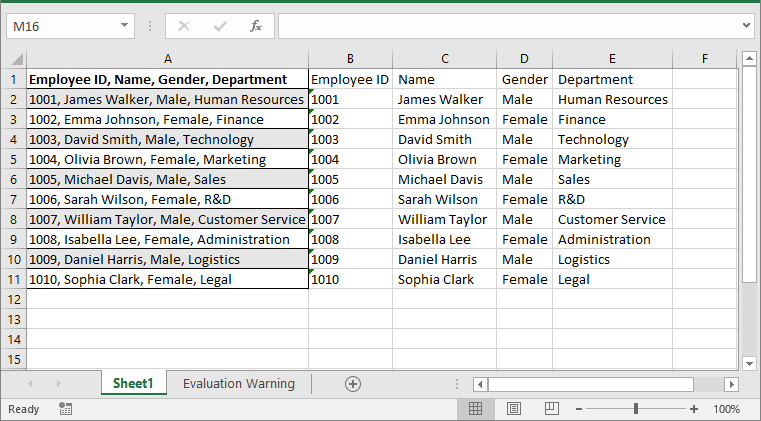
Python: Convert Text to Multiple Columns in Excel
When importing data from external sources or pasting large volumes of information into Excel, it's common for the data to be placed in a single column. This can make the data difficult to work with, especially when you need to separate it for in-depth analysis. By converting the text into multiple columns, you can create a clearer structure that allows for easier sorting, filtering, and analysis. In this article, we will introduce how to convert text to multiple columns in Excel in Python using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Convert Text to Multiple Columns in Excel in Python
Spire.XLS for Python does not offer a direct method for converting text in a cell into multiple columns. However, you can accomplish this by first retrieving the cell content using the CellRange.Text property. Next, use the str.split() method to split the text based on a specified delimiter, such as a comma, space, or semicolon. Finally, write the split data into individual columns. The detailed steps are as follows:
- Create an object of the Workbook class.
- Load an Excel workbook using the Workbook.LoadFromFile() method.
- Access a specific worksheet using the Workbook.Worksheets[index] property.
- Loop through each row in the sheet.
- Get the content of the first cell in the current row using the CellRange.Text property. Next, split the content based on a specified delimiter using the str.split() method, and finally, write the split data into separate columns.
- Automatically adjust column widths in the worksheet using the Worksheet.AllocatedRange.AutoFitColumns() method.
- Save the modified workbook to a new file using the Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Specify the input and output Excel File paths
inputFile = "Template.xlsx"
outputFile = "ConvertTextToColumns.xlsx"
# Create an object of the Workbook class
workbook = Workbook()
# Load the Excel file
workbook.LoadFromFile(inputFile)
# Get the first worksheet in the file
sheet = workbook.Worksheets[0]
# Loop through each row in the worksheet
for i in range(sheet.LastRow):
# Get the text of the first cell in the current row
text = sheet.Range[i + 1, 1].Text
# Split the text by comma
splitText = text.split(',')
# Write the split data into individual columns
for j in range(len(splitText)):
sheet.Range[i + 1, j + 2].Text = splitText[j]
# Automatically adjust column widths in the worksheet
sheet.AllocatedRange.AutoFitColumns()
# Save the modified Excel file
workbook.SaveToFile(outputFile, ExcelVersion.Version2013)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
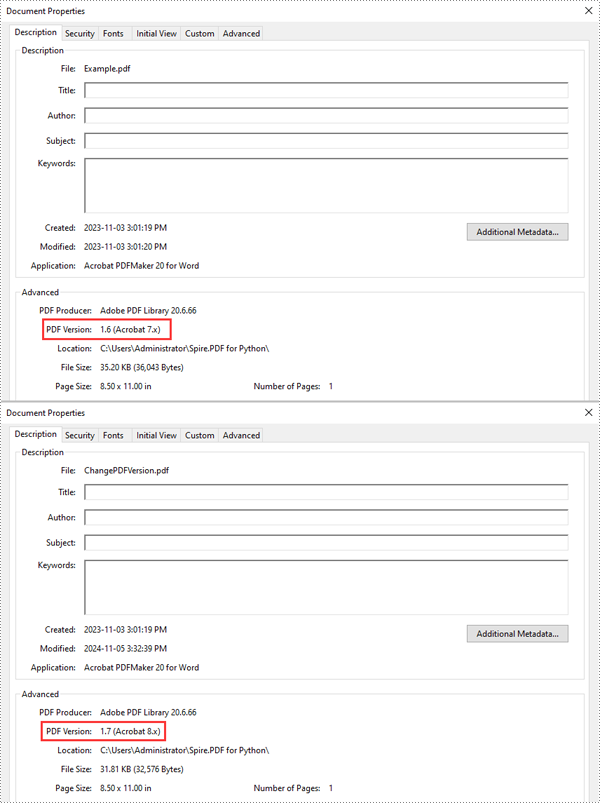
Python: Change PDF Version
PDF files have different versions, each with unique features and compatibility standards. Changing the version of a PDF can be important when specific versions are required for compatibility with certain devices, software, or regulatory requirements. For instance, you may need to use an older PDF version when archiving or sharing files with users using older software. This article will introduce how to change the version of a PDF document in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Change PDF Version in Python
Spire.PDF for Python supports PDF versions ranging from 1.0 to 1.7. To convert a PDF file to a different version, simply set the desired version using the PdfDocument.FileInfo.Version property. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF document using the PdfDocument.LoadFromFile() method.
- Change the version of the PDF document to a newer or older version using the PdfDocument.FileInfo.Version property.
- Save the resulting document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Example.pdf")
# Change the version of the PDF to version 1.7
pdf.FileInfo.Version = PdfVersion.Version1_7
# Save the resulting document
pdf.SaveToFile("ChangePDFVersion.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.PDF 10.11.1 supports extracting video and audio from PDF documents
We are delighted to announce the release of Spire.PDF 10.11.1. This version supports extracting video and audio from PDF documents. Besides, it enhances the conversion from PDF to images. Moreover, a lot of known issues are fixed successfully in this version, such as the issue that merging PDF documents failed. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-7145 | Supported the functionality to extract video and audio from PDF documents.
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile(inputFile);
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
PdfAnnotationCollection ancoll = page.Annotations;
for (int j = 0; j < ancoll.Count; j++)
{
PdfRichMediaAnnotationWidget MediaWidget = ancoll[j] as PdfRichMediaAnnotationWidget;
byte[] data = MediaWidget.RichMediaData;
string embedFileName = MediaWidget.RichMediaName;
File.WriteAllBytes(outputFile + embedFileName,data);
}
}
|
| Bug | SPIREPDF-6786 | Fixes the issue that highlighting text did not work correctly. |
| Bug | SPIREPDF-7055 | Fixes the issue that the program threw "Cannot find table 'loca' in the font file" when loading SVG. |
| Bug | SPIREPDF-7114 | Fixes the issue that merging PDF documents failed to work. |
| Bug | SPIREPDF-7126 | Fixes the issue that page size could not be set using PageSettings.PaperFormat when using ChromeHtmlConverter to convert HTML to PDF. |
| Bug | SPIREPDF-7129 | Fixes the issue that the result of PdfDocument.Conformance was incorrect. |
| Bug | SPIREPDF-7133 | Fixes the issue that the result of signature validity verification was incorrect. |
| Bug | SPIREPDF-7144 | Fixes the issue that the result of bookmark style modification was incorrect. |
| Bug | SPIREPDF-7148 | Optimizes the time consumption of PDF to image conversion. |
Python: Remove Backgrounds from PowerPoint Slide or Slide Masters
A well-chosen background can enhance a presentation's appeal, but overly elaborate colors or images may distract viewers and obscure the main message. Additionally, when reusing templates, the original background may not suit the new content. In these cases, removing the background becomes essential to keep your slides clear and focused. This article will show you how to remove backgrounds from PowerPoint slides or slide masters in Python with Spire.Presentation for Python, giving you the flexibility to create clean, professional presentations that keep the audience's attention on what matters.
- Remove Backgrounds from the Specified Slide
- Remove Backgrounds from All Slides
- Remove Backgrounds from PowerPoint Slide Masters
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Remove Backgrounds from the Specified Slide
There are typically two types of backgrounds in PowerPoint: background colors and background images. Although these backgrounds differ in their setup, the method to clear them is the same - using the BackgroundType property provided by Spire.Presentation for Python. Let's take a closer look at how to remove backgrounds from a PowerPoint slide with it.
Steps to remove background from a specified slide:
- Create an object for the Presentation class.
- Load a PowerPoint presentation from the local storage using Presentation.LoadFromFile() method.
- Get a certain slide with Presentation.Slides[] method.
- Remove the background by configuring BackgroundType property to none.
- Save the modified PowerPoint presentation using Presentation.SaveToFile() method, and release the memory.
Here is the code example of removing the background on the fourth slide:
- Python
from spire.presentation import *
# Create a Presentation document object
presentation = Presentation()
# Read the presentation document from file
presentation.LoadFromFile("imagebackground.pptx")
# Get the fourth slide
slide = presentation.Slides[3]
# Remove the background by setting the background type
slide.SlideBackground.Type = BackgroundType.none
# Save the modified presentation
presentation.SaveToFile("RemoveBackground.pptx", FileFormat.Pptx2010)
# Release resource
presentation.Dispose()

Remove Backgrounds from All Slides
Batch-deleting all slide backgrounds follows nearly the same steps as deleting a single slide background. The main difference is that you'll need to loop through each slide before setting the background type to ensure no slides are missed.
Steps to remove backgrounds from PowerPoint slides in a batch:
- Instantiate a Presentation class.
- Specify the file path to read a PowerPoint presentation using Presentation.LoadFromFile() method.
- Loop through each slide in the presentation.
- Remove all backgournds by applying BackgroundType.none property to each slide.
- Save the updated PowerPoint presentation as a new file with Presentation.SaveToFile() method, and release the resource.
Below is the code example for removing each background from PowerPoint slides:
- Python
from spire.presentation import *
# Create a Presentation document object
presentation = Presentation()
# Read the presentation document from file
presentation.LoadFromFile("presentation.pptx")
# Loop through each slide
for slide in presentation.Slides:
# Remove the background image or color by setting the background type
slide.SlideBackground.Type = BackgroundType.none
# Save the modified presentation
presentation.SaveToFile("RemoveBackground_allSlides.pptx", FileFormat.Pptx2010)
# Release resource
presentation.Dispose()

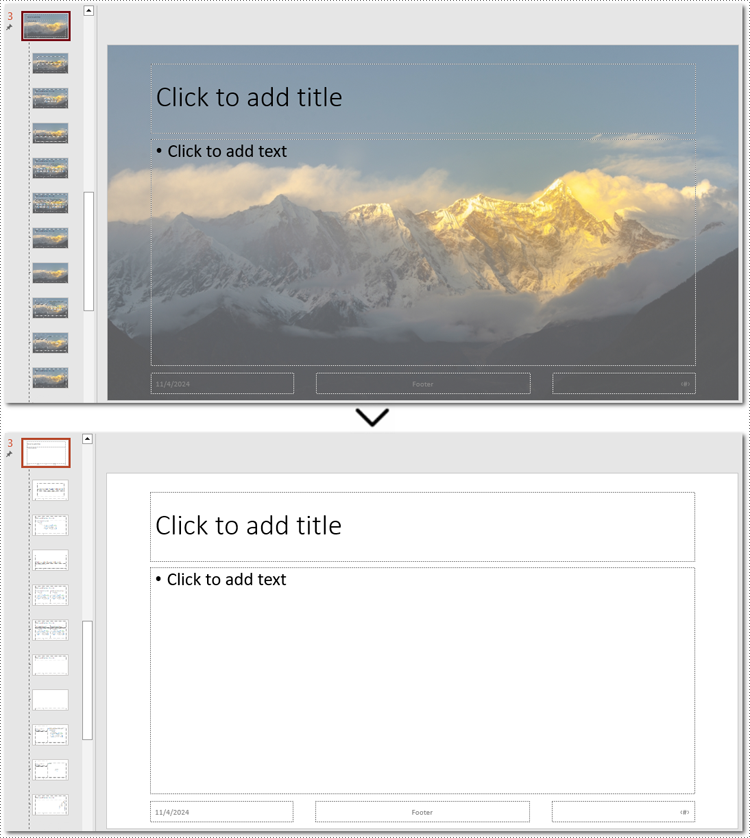
How to Remove Backgrounds from PowerPoint Slide Masters
If the slide background still exists after using the above method, you may need to remove the slide master's background instead. Unlike individual slides, setting the background of a slide master applies changes across all slides, so removing the slide master background can efficiently clear all backgrounds at once.
Steps to remove backgrounds from PowerPoint slide masters:
- Create an instance of the Presentation class.
- Load a presentation from the disk with Presentation.LoadFromFile() method.
- Retrieve a specified slide master using Presentation.Masters[] method.
- Access the background of the slide master with Masters.SlideBackground property.
- Remove the background by setting BackgroundType property to none.
- Save the newly modified PowerPoint presentation with Presentation.SaveToFile() method.
Note: Since the process of batch-removing slide master backgrounds is almost similar to deleting background from a slide master, this section will show the steps in the code comments rather than listing them separately.
Here is an example of removing the background from the third slide master:
- Python
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load the sample file from the disk
presentation.LoadFromFile("presentation.pptx")
# Get the third slide master
master = presentation.Masters[2]
# Access the background of the slide master
SlideBackground = master.SlideBackground
# Clear the background by setting the slide master background style to none
master.SlideBackground.Type = BackgroundType.none
# Loop through each slide master
#for master in presentation.Masters:
# Set the background type to none to remove it
#master.SlideBackground.Type = BackgroundType.none
# Save the result presentation
presentation.SaveToFile("remove_background.pptx", FileFormat.Pptx2013)
# Release resources
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Doc for Java 12.11.0 optimizes the conversions from Word to PDF and HTML
We're pleased to announce the release of Spire.Doc for Java 12.11.0. This version optimizes the conversions from Word to PDF, HTML, as well as RTF to PDF, and also fixes some issues that occurred when loading and saving Word files. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREDOC-10693 | Fixes the issue that the highlighting effect was incorrect when searching. |
| Bug | SPIREDOC-10726 | Fixes the issue that the table borders were not displaying in WPS after saving doc as docx. |
| Bug | SPIREDOC-10747 | Fixes the issue that the program threw an "IllegalArgumentException" when converting Word to PDF. |
| Bug | SPIREDOC-10755 | Fixes the issue that the border properties of the table changed. |
| Bug | SPIREDOC-10794 | Fixes the issue that the column widths in tables were inconsistent after converting Word to HTML. |
| Bug | SPIREDOC-10833 | Fixes the issue that the program threw an "Unexpected table container" error when converting Word to PDF. |
| Bug | SPIREDOC-10861 | Fixes the issue that the layout was inconsistent when converting Word to HTML. |
| Bug | SPIREDOC-10862 | Fixes the issue that the images were lost when converting RTF to PDF. |
| Bug | SPIREDOC-10864 | Fixed the issue of incorrect effect after accept the revisions. |
| Bug | SPIREDOC-10868 | Fixes the issue that the program threw the error "The string contains invalid characters" when loading Word. |
| Bug | SPIREDOC-10822 | Fixed the issue of incorrect effect when adding LaTeX formula. |
Spire.XLS for Java 14.11.0 enhances the conversion from Excel to PDF
We are excited to announce the release of Spire.XLS for Java 14.11.0. The latest version enhances the conversion from Excel to PDF. Besides, some known bugs are fixed successfully in this update, such as the issue that font sizes were inconsistent after saving some Excel files. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREXLS-5446 | Fixes the issue that the program threw "Specified argument was out of the range of valid values" when converting XLSX to XLSB. |
| Bug | SPIREXLS-5493 | Fixes the issue that incorrect effect occurred when using Worksheet.autoFitColumn. |
| Bug | SPIREXLS-5516 | Fixes the issue that content got lost when converting Excel to PDF. |
| Bug | SPIREXLS-5526 | Fixes the issue that font sizes were inconsistent after saving some Excel files. |
C#: Convert HTML to PDF using ChromeHtmlConverter
HTML is widely used to present content in web browsers, but preserving its exact layout when sharing or printing can be challenging. PDF, by contrast, is a universally accepted format that reliably maintains document layout across various devices and operating systems. Converting HTML to PDF is particularly useful in web development, especially when creating printable versions of web pages or generating reports from web data.
Spire.PDF for .NET now supports a streamlined method to convert HTML to PDF in C# using the ChromeHtmlConverter class. This tutorial provides step-by-step guidance on performing this conversion effectively.
- Convert HTML to PDF with ChromeHtmlConverter in C#
- Generate Output Logs During HTML to PDF Conversion in C#
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLLs files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Install Google Chrome
This method requires Google Chrome to perform the conversion. If Chrome is not already installed, you can download it from this link and install it.
Convert HTML to PDF using ChromeHtmlConverter in C#
You can utilize the ChromeHtmlConverter.ConvertToPdf() method to convert an HTML file to a PDF using the Chrome plugin. This method accepts 3 parameters, including the input HTML file path, output PDF file path, and ConvertOptions which allows customization of conversion settings like conversion timeout, PDF paper size and page margins. The detailed steps are as follows.
- Create an instance of the ChromeHtmlConverter class and provide the path to the Chrome plugin (chrome.exe) as a parameter in the class constructor.
- Create an instance of the ConvertOptions class.
- Customize the conversion settings, such as the conversion timeout, the paper size and page margins of the converted PDF through the properties of the ConvertOptions class.
- Convert an HTML file to PDF using the ChromeHtmlConverter.ConvertToPdf() method.
- C#
using Spire.Additions.Chrome;
namespace ConvertHtmlToPdfUsingChrome
{
internal class Program
{
static void Main(string[] args)
{
//Specify the input URL and output PDF file path
string inputUrl = @"https://www.e-iceblue.com/Tutorials/Spire.PDF/Spire.PDF-Program-Guide/C-/VB.NET-Convert-Image-to-PDF.html";
string outputFile = @"HtmlToPDF.pdf";
//Specify the path to the Chrome plugin
string chromeLocation = @"C:\Program Files\Google\Chrome\Application\chrome.exe";
//Create an instance of the ChromeHtmlConverter class
ChromeHtmlConverter converter = new ChromeHtmlConverter(chromeLocation);
// Create an instance of the ConvertOptions class
ConvertOptions options = new ConvertOptions();
//Set conversion timeout
options.Timeout = 10 * 3000;
//Set paper size and page margins of the converted PDF
options.PageSettings = new PageSettings()
{
PaperWidth = 8.27,
PaperHeight = 11.69,
MarginTop = 0,
MarginLeft = 0,
MarginRight = 0,
MarginBottom = 0
};
//Convert the URL to PDF
converter.ConvertToPdf(inputUrl, outputFile, options);
}
}
}
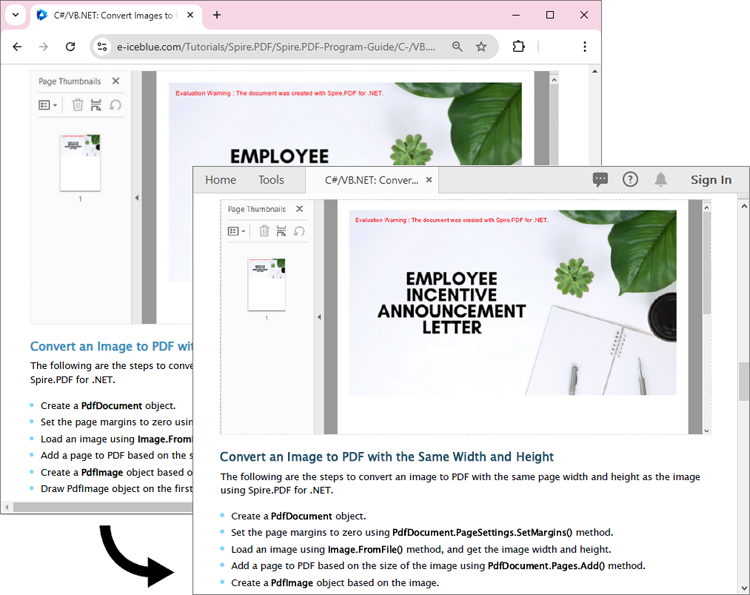
The converted PDF file maintains the same appearance as if the HTML file were printed to PDF directly through the Chrome browser:
Generate Output Logs During HTML to PDF Conversion in C#
Spire.PDF for .NET enables you to generate output logs during HTML to PDF conversion using the Logger class. The detailed steps are as follows.
- Create an instance of the ChromeHtmlConverter class and provide the path to the Chrome plugin (chrome.exe) as a parameter in the class constructor.
- Enable Logging by creating a Logger object and assigning it to the ChromeHtmlConverter.Logger property.
- Create an instance of the ConvertOptions class.
- Customize the conversion settings, such as the conversion timeout, the paper size and page margins of the converted PDF through the properties of the ConvertOptions class.
- Convert an HTML file to PDF using the ChromeHtmlConverter.ConvertToPdf() method.
- C#
using Spire.Additions.Chrome;
namespace ConvertHtmlToPdfUsingChrome
{
internal class Program
{
static void Main(string[] args)
{
//Specify the input URL and output PDF file path
string inputUrl = @"https://www.e-iceblue.com/Tutorials/Spire.PDF/Spire.PDF-Program-Guide/C-/VB.NET-Convert-Image-to-PDF.html";
string outputFile = @"HtmlToPDF.pdf";
// Specify the log file path
string logFilePath = @"Logs.txt";
//Specify the path to the Chrome plugin
string chromeLocation = @"C:\Program Files\Google\Chrome\Application\chrome.exe";
//Create an instance of the ChromeHtmlConverter class
ChromeHtmlConverter converter = new ChromeHtmlConverter(chromeLocation);
//Enable logging
converter.Logger = new Logger(logFilePath);
//Create an instance of the ConvertOptions class
ConvertOptions options = new ConvertOptions();
//Set conversion timeout
options.Timeout = 10 * 3000;
//Set paper size and page margins of the converted PDF
options.PageSettings = new PageSettings()
{
PaperWidth = 8.27,
PaperHeight = 11.69,
MarginTop = 0,
MarginLeft = 0,
MarginRight = 0,
MarginBottom = 0
};
//Convert the URL to PDF
converter.ConvertToPdf(inputUrl, outputFile, options);
}
}
}
Here is the screenshot of the output log file:
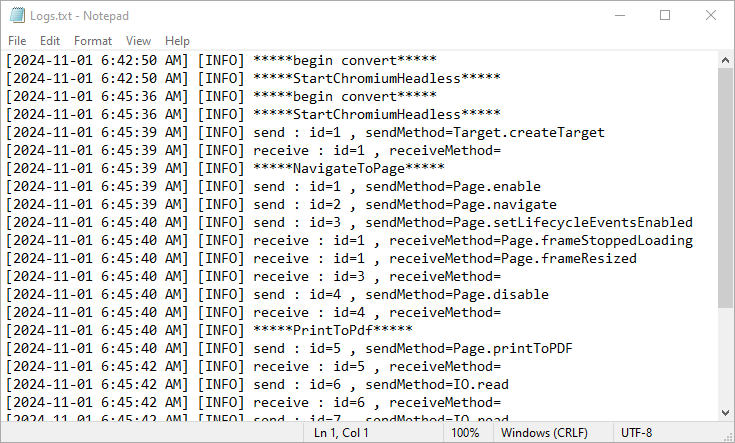
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Import and Export PDF Form Data
PDF forms are essential tools for collecting information across various industries. Understanding how to import and export this data in different formats like FDF, XFDF, and XML can greatly enhance your data management processes. For instance, importing form data allows you to update or pre-fill PDF forms with existing information, saving time and increasing accuracy. Conversely, exporting form data enables you to share collected information effortlessly with other applications, facilitating seamless integration and minimizing manual entry errors. In this article, we will introduce how to import and export PDF form data in Python using Spire.PDF for Python.
- Import PDF Form Data from FDF, XFDF or XML Files in Python
- Export PDF Form Data to FDF, XFDF or XML Files in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Import PDF Form Data from FDF, XFDF or XML Files in Python
Spire.PDF for Python offers the PdfFormWidget.ImportData() method for importing PDF form data from FDF, XFDF, or XML files. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using PdfDocument.Form property.
- Import form data from an FDF, XFDF or XML file using PdfFormWidget.ImportData() method.
- Save the resulting document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Forms.pdf")
# Get the form of the document
pdfForm = pdf.Form
formWidget = PdfFormWidget(pdfForm)
# Import PDF form data from an XML file
formWidget.ImportData("Data.xml", DataFormat.Xml)
# Import PDF form data from an FDF file
# formWidget.ImportData("Data.fdf", DataFormat.Fdf)
# Import PDF form data from an XFDF file
# formWidget.ImportData("Data.xfdf", DataFormat.XFdf)
# Save the resulting document
pdf.SaveToFile("Output.pdf")
# Close the PdfDocument object
pdf.Close()
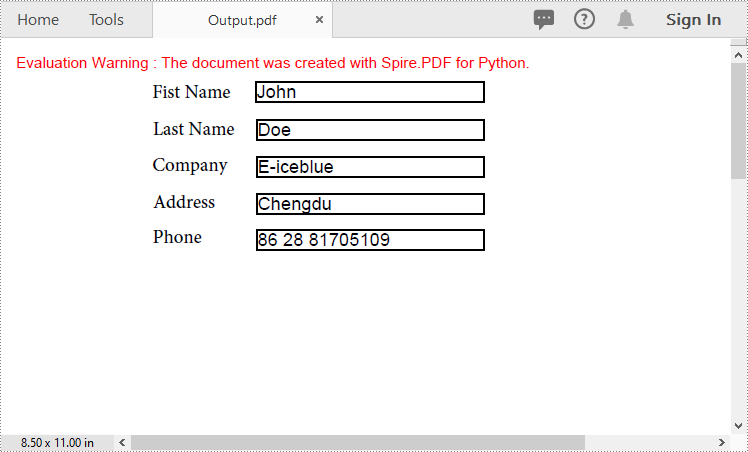
Export PDF Form Data to FDF, XFDF or XML Files in Python
Spire.PDF for Python also enables developers to export PDF form data to FDF, XFDF, or XML files by using the PdfFormWidget.ExportData() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the form of the PDF document using PdfDocument.Form property.
- Export form data to an FDF, XFDF or XML file using PdfFormWidget.ExportData() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Forms.pdf")
# Get the form of the document
pdfForm = pdf.Form
formWidget = PdfFormWidget(pdfForm)
# Export PDF form data to an XML file
formWidget.ExportData("Data.xml", DataFormat.Xml, "Form")
# Export PDF form data to an FDF file
# formWidget.ExportData("Data.fdf", DataFormat.Fdf, "Form")
# Export PDF form data to an XFDF file
# formWidget.ExportData("Data.xfdf", DataFormat.XFdf, "Form")
# Close the PdfDocument object
pdf.Close()
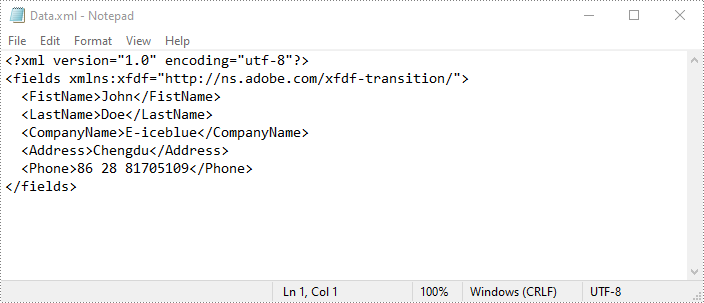
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.