Python: Convert PDF to PowerPoint
PDF (Portable Document Format) files are widely used for sharing and distributing documents due to their consistent formatting and broad compatibility. However, when it comes to presentations, PowerPoint remains the preferred format for many users. PowerPoint offers a wide range of features and tools that enable the creation of dynamic, interactive, and visually appealing slideshows. Unlike static PDF documents, PowerPoint presentations allow for the incorporation of animations, transitions, multimedia elements, and other interactive components, making them more engaging and effective for delivering information to the audience.
By converting PDF to PowerPoint, you can transform a static document into a captivating and impactful presentation that resonates with your audience and helps to achieve your communication goals. In this article, we will explain how to convert PDF files to PowerPoint format in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to PowerPoint in Python
Spire.PDF for Python provides the PdfDocument.SaveToFile(filename:str, FileFormat.PPTX) method to convert a PDF document into a PowerPoint presentation. With this method, each page of the original PDF document will be converted into a single slide in the output PPTX presentation.
The detailed steps to convert a PDF document to PowerPoint format are as follows:
- Create an object of the PdfDocument class.
- Load a sample PDF document using the PdfDocument.LoadFromFile() method.
- Save the PDF document as a PowerPoint PPTX file using the PdfDocument.SaveToFile(filename:str, FileFormat.PPTX) method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a sample PDF document
pdf.LoadFromFile("Sample.pdf")
# Save the PDF document as a PowerPoint PPTX file
pdf.SaveToFile("PdfToPowerPoint.pptx", FileFormat.PPTX)
pdf.Close()
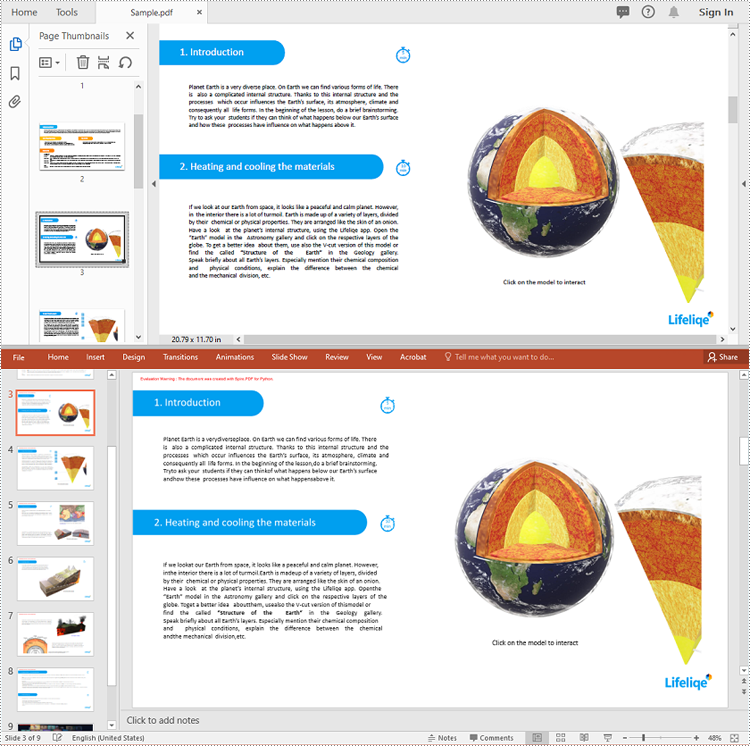
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Doc for Java 12.7.6 enhances the conversion from RTF to Word and PDF
We are delighted to announce the release of Spire.Doc for Java 12.7.6. This version enhances the conversion from RTF to Word and PDF. Moreover, some known issues are fixed in this version, such as the issue that the content was lost after loading and saving RTF. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREDOC-10082 SPIREDOC-10362 |
Fixes the issue that the content layout was not correct after converting RTF to PDF and Word. |
| Bug | SPIREDOC-10444 | Fixes the issue that the content was lost after loading and saving RTF. |
| Bug | SPIREDOC-10461 | Fixes the issue that the program threw "For input string: 20" error when loading RTF. |
| Bug | SPIREDOC-10462 | Fixes the issue that the program threw "Index 4 out of bounds for length 4" error when loading RTF. |
Spire.PDF for C++ 10.7.0 optimizes the conversion from PDF to OFD
We're pleased to announce the release of Spire.PDF for C++ 10.7.0. This release reduces the size of the resulting file when converting PDF to OFD. Details are shown below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREPDF-6785 | Reduces the size of the resulting file when converting PDF to OFD |
C#: Extract Tables from Word Documents
Tables in Word documents often contain valuable information, ranging from financial data and research results to survey results and statistical records. Extracting the data contained within these tables can unlock a wealth of opportunities, empowering you to leverage it for a variety of purposes, such as in-depth data analysis, trend identification, and seamless integration with other tools or databases. In this article, we will demonstrate how to extract tables from Word documents in C# using Spire.Doc for .NET.
Install Spire.Doc for .NET
To begin with, you need to add the DLL files included in the Spire.Doc for .NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Doc
Extract Tables from Word in C#
In Spire.Doc for .NET, the Section.Tables property is used to access the tables contained within a section of a Word document. This property returns a collection of ITable objects, where each object represents a distinct table in the section. Once you have the ITable objects, you can iterate through their rows and cells, and then retrieve the textual content of each cell using cell.Paragraphs[index].Text property.
The detailed steps to extract tables from a Word document are as follows:
- Create an object of the Document class and load a Word document using Document.LoadFromFile() method.
- Iterate through the sections in the document and get the table collection of each section through Section.Tables property.
- Iterate through the tables in each section and create a string object for each table.
- Iterate through the rows in each table and the cells in each row, then get the text of each cell through TableCell.Paragraphs[index].Text property and add the cell text to the string.
- Save each string to a text file.
- C#
using Spire.Doc;
using Spire.Doc.Collections;
using Spire.Doc.Interface;
using System.IO;
using System.Text;
namespace ExtractWordTable
{
internal class Program
{
static void Main(string[] args)
{
// Create an object of the Document class
Document doc = new Document();
// Load a Word document
doc.LoadFromFile("Tables.docx");
// Iterate through the sections in the document
for (int sectionIndex = 0; sectionIndex < doc.Sections.Count; sectionIndex++)
{
// Get the current section
Section section = doc.Sections[sectionIndex];
// Get the table collection of the section
TableCollection tables = section.Tables;
// Iterate through the tables in the section
for (int tableIndex = 0; tableIndex < tables.Count; tableIndex++)
{
// Get the current table
ITable table = tables[tableIndex];
// Initialize a string to store the table data
string tableData = "";
// Iterate through the rows in the table
for (int rowIndex = 0; rowIndex < table.Rows.Count; rowIndex++)
{
// Get the current row
TableRow row = table.Rows[rowIndex];
// Iterate through the cells in the row
for (int cellIndex = 0; cellIndex < row.Cells.Count; cellIndex++)
{
// Get the current cell
TableCell cell = table.Rows[rowIndex].Cells[cellIndex];
// Get the text in the cell
string cellText = "";
for (int paraIndex = 0; paraIndex < cell.Paragraphs.Count; paraIndex++)
{
cellText += (cell.Paragraphs[paraIndex].Text.Trim() + " ");
}
// Add the text to the string
tableData += cellText.Trim();
if (cellIndex < table.Rows[rowIndex].Cells.Count - 1)
{
tableData += "\t";
}
}
// Add a new line
tableData += "\n";
}
// Save the table data to a text file
string filePath = Path.Combine("Tables", $"Section{sectionIndex + 1}_Table{tableIndex + 1}.txt");
File.WriteAllText(filePath, tableData, Encoding.UTF8);
}
}
doc.Close();
}
}
}
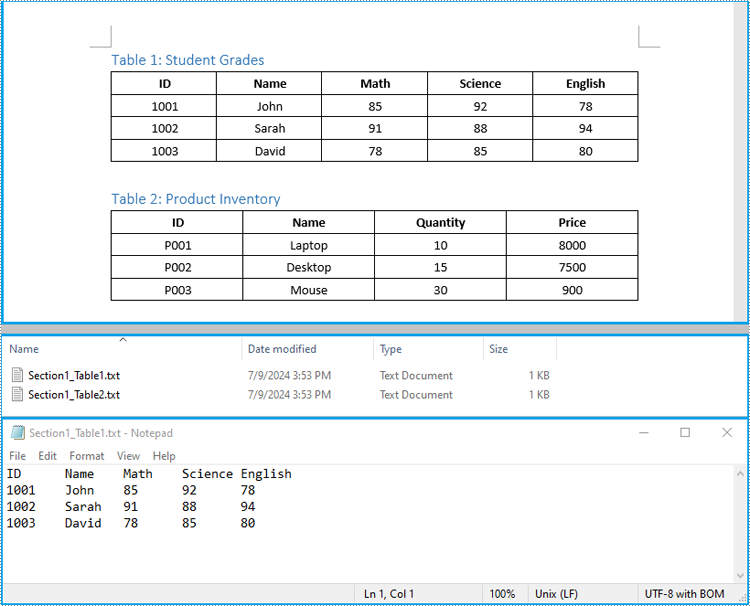
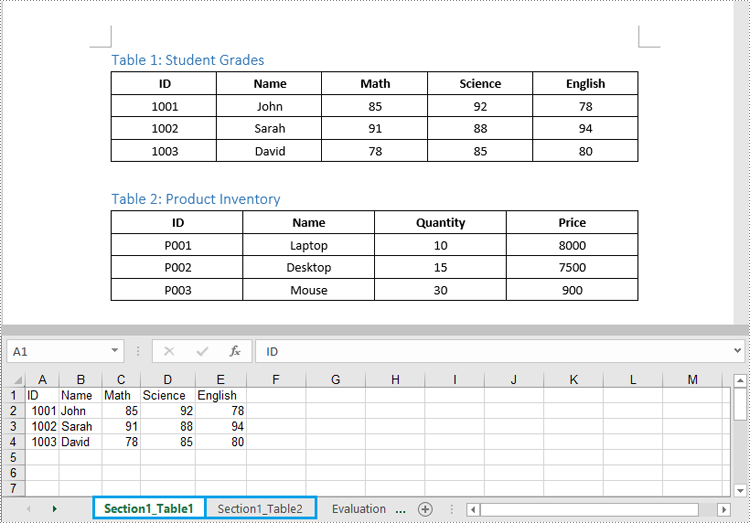
Extract Tables from Word to Excel in C#
In addition to saving the extracted table data to text files, you can also write the data directly into Excel worksheets by using the Spire.XLS for .NET library. However, before you can use Spire.XLS, you need to install it via NuGet:
Install-Package Spire.XLS
The detailed steps to extract tables from Word documents to Excel worksheets are as follows:
- Create an object of the Document class and load a Word document using the Document.LoadFromFile() method.
- Create an object of the Workbook class and clear the default worksheets using Workbook.Worksheets.Clear() method.
- Iterate through the sections in the document and get the table collection of each section through Section.Tables property.
- Iterate through the tables in the section and add a worksheet for each table to the workbook using Workbook.Worksheets.Add() method.
- Iterate through the rows in each table and the cells in each row, then get the text of each cell through TableCell.Paragraphs[index].Text property and write the text to the worksheet using Worksheet.SetCellValue() method.
- Save the workbook to an Excel file using Workbook.SaveToFile() method.
- C#
using Spire.Doc;
using Spire.Doc.Interface;
using Spire.Xls;
namespace ExtractWordTableToExcel
{
internal class Program
{
static void Main(string[] args)
{
// Create an object of the Document class
Document doc = new Document();
// Load a Word document
doc.LoadFromFile("Tables.docx");
// Create an object of the Workbook class
Workbook wb = new Workbook();
// Remove the default worksheets
wb.Worksheets.Clear();
// Iterate through the sections in the document
for (int sectionIndex = 0; sectionIndex < doc.Sections.Count; sectionIndex++)
{
// Get the current section
Section section = doc.Sections[sectionIndex];
// Iterate through the tables in the section
for (int tableIndex = 0; tableIndex < section.Tables.Count; tableIndex++)
{
// Get the current table
ITable table = section.Tables[tableIndex];
// Add a worksheet to the workbook
Worksheet ws = wb.Worksheets.Add($"Section{sectionIndex + 1}_Table{tableIndex + 1}");
// Iterate through the rows in the table
for (int rowIndex = 0; rowIndex < table.Rows.Count; rowIndex++)
{
// Get the current row
TableRow row = table.Rows[rowIndex];
// Iterate through the cells in the row
for (int cellIndex = 0; cellIndex < row.Cells.Count; cellIndex++)
{
// Get the current cell
TableCell cell = row.Cells[cellIndex];
// Get the text in the cell
string cellText = "";
for (int paraIndex = 0; paraIndex < cell.Paragraphs.Count; paraIndex++)
{
cellText += (cell.Paragraphs[paraIndex].Text.Trim() + " ");
}
// Write the cell text to the worksheet
ws.SetCellValue(rowIndex + 1, cellIndex + 1, cellText);
}
// Autofit the width of the columns in the worksheet
ws.Range.AutoFitColumns();
}
}
}
// Save the workbook to an Excel file
wb.SaveToFile("Tables/WordTableToExcel.xlsx", ExcelVersion.Version2016);
doc.Close();
wb.Dispose();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.PDF for Python 10.7.1 supports converting PDF to PPTX
We're pleased to announce the release of Spire.PDF for Python 10.7.1. This version supports converting PDF documents to PPTX documents, and also adds new encryption and decryption interfaces for PDF documents. In addition, some issues that occurred when converting PDF to PDF/A and HTML have been successfully fixed. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-6830 | Adds new encryption and decryption interfaces for PDF documents.
# Encryption
pdfDocument = PdfDocument()
securityPolicy = PdfPasswordSecurityPolicy("123456789", "M123456789")
securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_128
securityPolicy.DocumentPrivilege = PdfDocumentPrivilege.ForbidAll()
securityPolicy.DocumentPrivilege.AllowPrint = True
pdfDocument.Encrypt(securityPolicy)
pdfMargin = PdfMargins()
unitCvtr = PdfUnitConvertor()
pdfMargin.Left = unitCvtr.ConvertUnits(0, PdfGraphicsUnit.Pixel, PdfGraphicsUnit.Point)
pdfMargin.Right = unitCvtr.ConvertUnits(0,PdfGraphicsUnit.Pixel, PdfGraphicsUnit.Point)
pdfMargin.Top = unitCvtr.ConvertUnits(0, PdfGraphicsUnit.Pixel, PdfGraphicsUnit.Point)
pdfMargin.Bottom = unitCvtr.ConvertUnits(0, PdfGraphicsUnit.Pixel, PdfGraphicsUnit.Point)
pageSize = PdfPageSize.A4()
spirePage = pdfDocument.Pages.Add(pageSize, pdfMargin)
pdfDocument.SaveToFile("1.pdf", FileFormat.PDF)
pdfDocument.Dispose()
# Decryption
pdfDocument = PdfDocument()
pdfDocument.LoadFromFile("input.pdf","123456789")
pdfDocument.Decrypt("M123456789")
pdfDocument.SaveToFile("output.pdf", FileFormat.PDF)
pdfDocument.Dispose()
|
| New feature | SPIREPDF-6853 | Adds a method to delete images.
pdf = PdfDocument() pdf.LoadFromFile(inputfile) page = pdf.Pages[0] imageHelper = PdfImageHelper() imageInfos = imageHelper.GetImagesInfo(page) imageHelper.DeleteImage(imageInfos[0]) pdf.SaveToFile(outputFile, FileFormat.PDF) pdf.Close() |
| New feature | SPIREPDF-6861 | Supports converting PDF documents to PPTX documents.
pdfDocument = PdfDocument()
pdfDocument.LoadFromFile("Sample.pdf")
pdfDocument.SaveToFile("ConvertPDFtoPowerPoint.pptx", FileFormat.PPTX)
|
| Bug | SPIREPDF-6511 | Fixes the issue that the application threw "Cannot find table 'loca' in the font file" when loading SVG files. |
| Bug | SPIREPDF-6737 | Fixes the issue that the hyperlinks became inactive after converting PDF documents to PDF/A documents. |
| Bug | SPIREPDF-6817 | Fixes the issue that the red annotations were lost after converting PDF documents to HTML documents. |
Spire.Presentation 9.7.4 supports converting PowerPoint documents to Markdown files
We are excited to announce the release of Spire.Presentation 9.7.4. This version supports converting PowerPoint documents to Markdown files. Besides, some known issues are fixed in this version, such as the issue that the waterfall chart was displayed incorrectly after modifying its data. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Supports converting PowerPoint documents to Markdown files.
Presentation ppt = new Presentation();
ppt.LoadFromFile("1.pptx");
ppt.SaveToFile("1.md", FileFormat.Markdown);
ppt.Dispose();
|
| Bug | SPIREPPT-2522 | Fixes the issue that the waterfall chart is displayed incorrectly after modifying its data. |
| Bug | SPIREPPT-2534 | Fixes the issue that the program threw System.ArgumentException when setting document property "_MarkAsFinal". |
| Bug | SPIREPPT-2535 | Fixes the issue that the tilt angle of text was lost after converting slides to pictures. |
Python: Remove Tables in Word
Tables in Word documents can sometimes disrupt the flow of text or the visual balance of a page. Removing these tables can help in creating a more aesthetically pleasing document, which is crucial for reports, presentations, or publications where appearance is important. In this article, you will learn how to remove tables from a Word document in Python using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Remove a Specified Table in Word in Python
Spire.Doc for Python provides the Section.Tables.RemoveAt(int index) method to delete a specified table in a Word document by index. The following are the detailed steps.
- Create a Document instance.
- Load a Word document using Document.LoadFromFile() method.
- Get a specified section using Document.Sections[] property.
- Delete a specified table by index using Section.Tables.RemoveAt() method.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import * from spire.doc.common import * inputFile = "Tables.docx" outputFile = "RemoveTable.docx" # Create a Document instance doc = Document() # Load a Word document doc.LoadFromFile(inputFile) # Get the first section in the document sec = doc.Sections[0] # Remove the first table in the section sec.Tables.RemoveAt(0) # Save the result document doc.SaveToFile(outputFile, FileFormat.Docx) doc.Close()
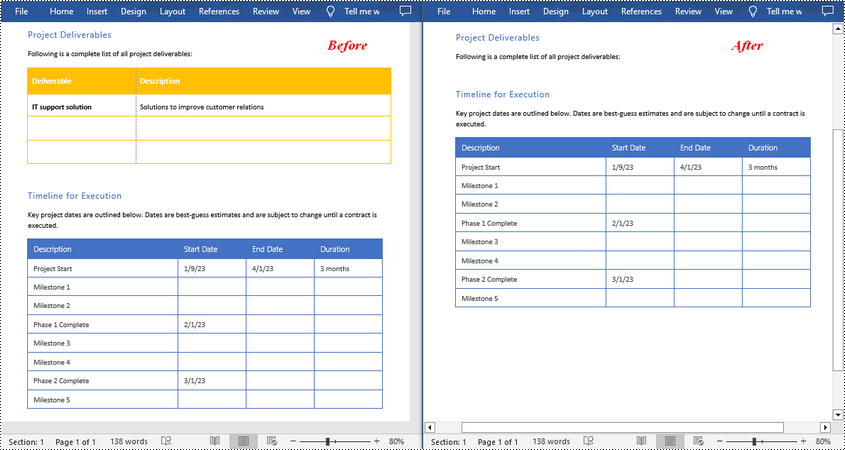
Remove All Tables in Word in Python
To delete all tables from a Word document, you need to iterate through all sections in the document, then iterate through all tables in each section and remove them through the Section.Tables.Remove() method. The following are the detailed steps.
- Create a Document instance.
- Load a Word document using Document.LoadFromFile() method.
- Iterate through all sections in the document.
- Iterate through all tables in each section.
- Delete the tables using Section.Tables.Remove() method.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
inputFile = "Tables.docx"
outputFile = "RemoveAllTables.docx"
# Create a Document instance
doc = Document()
# Load a Word document
doc.LoadFromFile(inputFile)
# Iterate through all sections in the document
for i in range(doc.Sections.Count):
sec = doc.Sections.get_Item(i)
# Iterate through all tables in each section
for j in range(sec.Tables.Count):
table = sec.Tables.get_Item(j)
# Remove the table
sec.Tables.Remove(table)
# Save the result document
doc.SaveToFile(outputFile, FileFormat.Docx)
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Doc 12.7.3 fixes the issue that image data filling failed during mail merge
We are happy to announce the release of Spire.Doc 12.7.3. This version fixes the issue that the image data was failed to be filled during mail merge. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREDOC-10644 | Fixes the issue that the image data was failed to be filled during mail merge. |
Python: Convert Markdown to PDF
Markdown has become a popular choice for writing structured text due to its simplicity and readability, making it widely used for documentation, README files, and note-taking. However, sometimes there arises a need to present this content in a more universal and polished format, such as PDF, which is compatible across various devices and platforms without formatting inconsistencies. Converting Markdown files to PDF documents not only enhances portability but also adds a professional touch, enabling easier distribution for reports, manuals, or sharing content with non-technical audiences who may not be familiar with Markdown syntax.
This article will demonstrate how to convert Markdown files to PDF documents using Spire.Doc for Python to automate the conversion process.
- Convert Markdown Files to PDF Documents with Python
- Convert Markdown to PDF and Customize Page Settings
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to: How to Install Spire.Doc for Python on Windows
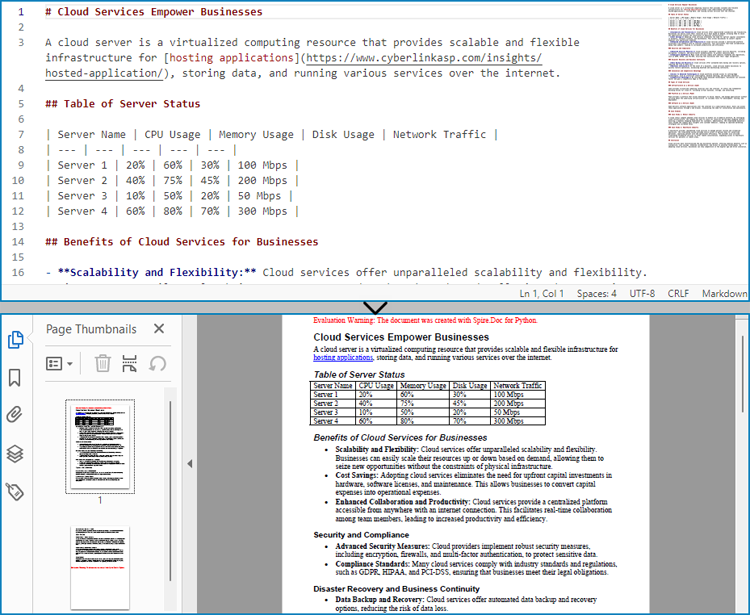
Convert Markdown Files to PDF Documents with Python
With Spire.Doc for Python, developers can load Markdown files using Document.LoadFromFile(string: fileName, FileFormat.Markdown) method, and then save the files to PDF documents using Document.SaveToFile(string: fileName, FileFormat.PDF) method. Besides, developers can also convert Markdown files to HTML, XPS, and SVG formats by specifying enumeration items of the FileFormat enumeration class.
The detailed steps for converting a Markdown file to a PDF document are as follows:
- Create an instance of Document class.
- Load a Markdown file using Document.LoadFromFile(string: fileName, FileFormat.Markdown) method.
- Convert the Markdown file to a PDF document and save it using Document.SaveToFile(string: fileName, FileFormat.PDF) method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class
doc = Document()
# Load a Markdown file
doc.LoadFromFile("Sample.md", FileFormat.Markdown)
# Save the file to a PDF document
doc.SaveToFile("output/MarkdownToPDF.pdf", FileFormat.PDF)
doc.Dispose()
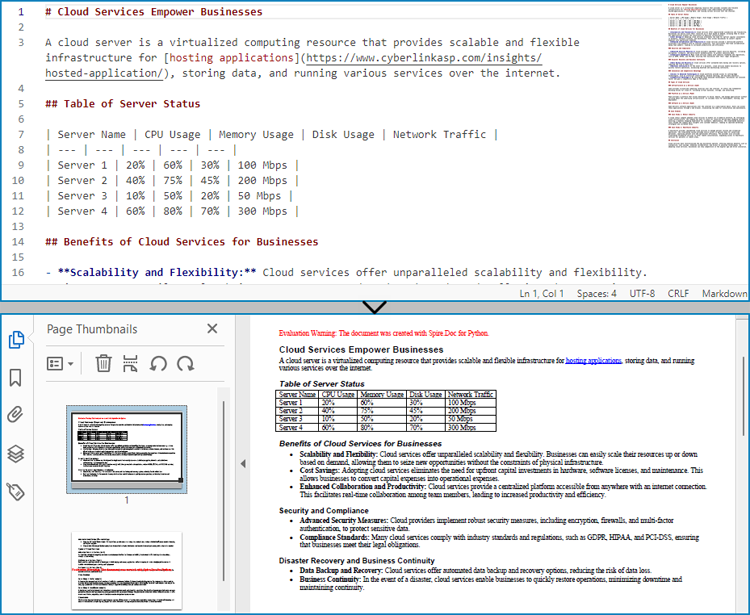
Convert Markdown to PDF and Customize Page Settings
Spire.Doc for Python supports performing basic page setup before converting Markdown files to formats like PDF, allowing for control over the appearance of the converted document.
The detailed steps to convert a Markdown file to a PDF document and customize the page settings are as follows:
- Create an instance of Document class.
- Load a Markdown file using Document.LoadFromFile(string: fileName, FileFormat.Markdown) method.
- Get the default section using Document.Sections.get_Item() method.
- Get the page settings through Section.PageSetup property and set the page size, orientation, and margins through properties under PageSetup class.
- Convert the Markdown file to a PDF document and save it using Document.SaveToFile(string: fileName, FileFormat.PDF) method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an instance of Document class
doc = Document()
# Load a Word document
doc.LoadFromFile("Sample.md", FileFormat.Markdown)
# Get the default section
section = doc.Sections.get_Item(0)
# Get the page settings
pageSetup = section.PageSetup
# Customize the page settings
pageSetup.PageSize = PageSize.A4()
pageSetup.Orientation = PageOrientation.Landscape
pageSetup.Margins.All = 50
# Save the Markdown document to a PDF file
doc.SaveToFile("output/MarkdownToPDFPageSetup.pdf", FileFormat.PDF)
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Create & Edit Documents Online: Word, Excel, PowerPoint
The advantages of using an online document editor over a traditional desktop application include enhanced accessibility, seamless collaboration, automatic version control, cross-platform compatibility, and reduced hardware requirements. These features make online document editors a versatile and efficient choice for users who require the ability to access, edit, and share documents from anywhere.
This article demonstrates how to create and edit MS Word, Excel and PowerPoint documents online using the Spire.Cloud.Office document editor library.
- Spire.Cloud.Office Document Editor
- Create a New Document
- Edit an Existing Document
- Co-Edit a Document
Spire.Cloud.Office Document Editor
Spire.Cloud.Office is a feature-rich HTML-5 based document editor component that can be easily integrated into web applications. With the document editor component, your end-users can view, create, edit, and collaborate on diverse document types within a web browser.
To utilize the services offered by Spire.Cloud.Office, you will need to first install it on your system.
- Install Spire.Cloud.Office for .NET on Windows
- Install Spire.Cloud.Office for Linux on Ubuntu
- Install Spire.Cloud.Office for Linux on CentOS
After the installation is complete, you can integrate Spire.Cloud.Office editor in your own web application or visit the example application hosted on port 3000 to explore the editor’s functionality.
The example page offers options to upload existing documents or create new ones. Spire.Office.Cloud supports loading DOC/DOCX, XLS/XLSX, and PPT/PPTX files, and exporting files to DOCX, XLSX, and PPTX formats.

Create a New Document
With the "Create Document", "Create Spreadsheet", and "Create Presentation" buttons on the example page, users can create a new Word document, a new Excel spreadsheet, and a new PowerPoint presentation, respectively.
Upon clicking "Create Document", a new Word document named "new.docx" will be generated, and the editor will launch with the blank document ready for editing.
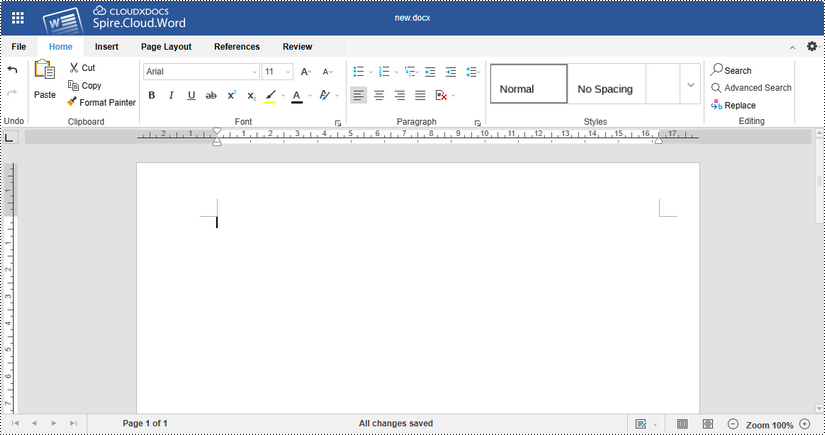
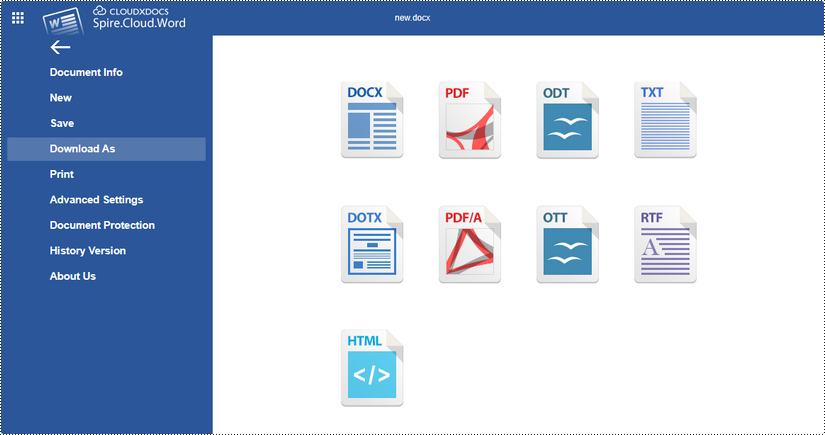
Once you've finished editing the document, click "File" on the menu and you'll get the options to download the file and save it to your local folder in the desired format.
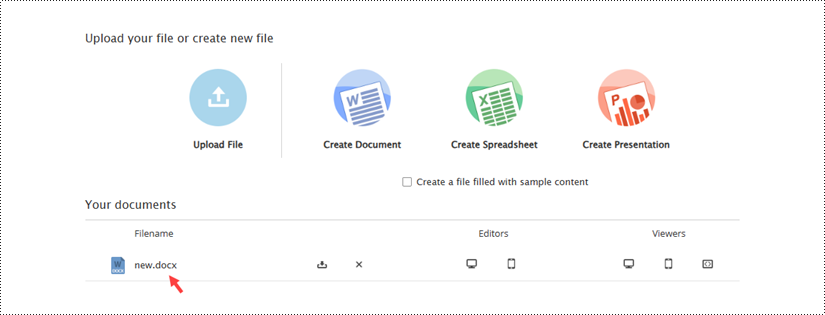
Alternatively, you can click "Save" to preserve the changes made to the "new.docx" document, which can be found on the example page.
Edit an Existing Document
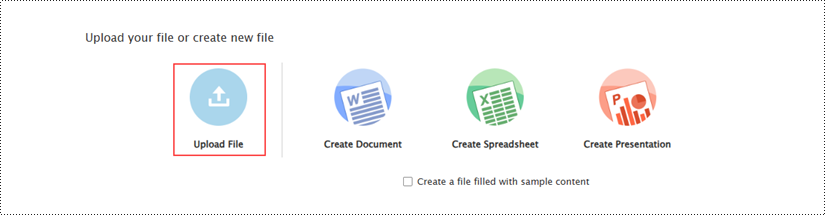
On the example page, click the "Upload File" button to load an existing document for editing.
Once the file has been uploaded, it will appear on the example page. To open the document in the editor, click the computer icon in the "Editors" section.
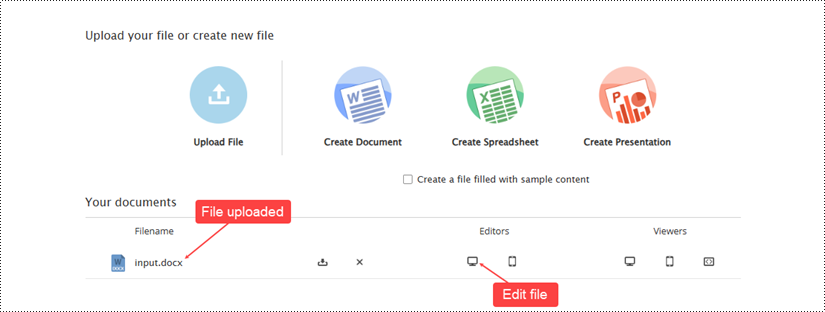
Use the editing tools provided in the document editor to make any desired modifications to the file. Once you have finished making changes, save the updated document by clicking "File" and then selecting "Save".
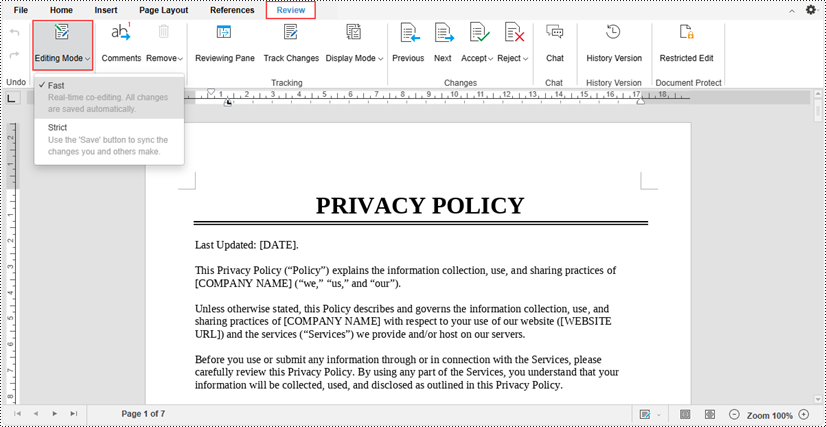
Co-Edit a Document
Spire.Cloud.Office's real-time collaboration features enable multiple users to work on the same document simultaneously. Two different collaborative editing modes are available under the "Review" tab - "Editing Mode".
- Fast Mode: All editors can see the changes made to the document in real-time as they are being typed or made.
- Strict Mode: Changes made by editors are protected and only become visible to other editors after the document has been explicitly saved.
By default, the Fast mode is enabled.
When a document is being collaboratively edited by multiple users, any changes made by one editor are instantly reflected in the document interface for all other editors in real-time.
