Python: Change or Remove Borders for Tables in Word
Tables are a powerful formatting tool in Word, allowing you to organize and present data effectively. However, the default table borders may not always align with your document's style and purpose. By selectively changing or removing the borders, you can achieve a variety of visual effects to suit your requirements. In this article, we will explore how to change and remove borders for tables in Word documents in Python using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Change Borders for a Table in Word in Python
Spire.Doc for Python empowers you to retrieve the borders collection of a table by using the Table.TableFormat.Borders property. Once retrieved, you can access individual borders (like top border, bottom border, left border, right border, horizontal border, and vertical border) from the collection and then modify them by adjusting their line style, width, and color. The detailed steps are as follows.
- Create an object of the Document class.
- Load a Word document using Document.LoadFromFile() method.
- Get a specific section using Document.Sections[index] property.
- Get a specific table using Section.Tables[index] property.
- Get the borders collection of the table using Table.TableFormat.Borders property.
- Get an individual border, such as the top border from the borders collection using Borders.Top property, and then change its line style, width and color.
- Refer to the above step to get other individual borders from the borders collection, and then change their line style, width and color.
- Save the resulting document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of the Document class
document = Document()
# Load a Word document
document.LoadFromFile("Table.docx")
# Add a section to the document
section = document.Sections[0]
# Get the first table in the section
table = section.Tables[0] if isinstance(section.Tables[0], Table) else None
# Get the collection of the borders
borders = table.TableFormat.Borders
# Get the top border and change border style, line width, and color
topBorder = borders.Top
topBorder.BorderType = BorderStyle.Single
topBorder.LineWidth = 1.0
topBorder.Color = Color.get_YellowGreen()
# Get the left border and change border style, line width, and color
leftBorder = borders.Left
leftBorder.BorderType = BorderStyle.Single
leftBorder.LineWidth = 1.0
leftBorder.Color = Color.get_YellowGreen()
# Get the right border and change border style, line width, and color
rightBorder = borders.Right
rightBorder.BorderType = BorderStyle.Single
rightBorder.LineWidth = 1.0
rightBorder.Color = Color.get_YellowGreen()
# Get the bottom border and change border style, line width, and color
bottomBorder = borders.Bottom
bottomBorder.BorderType = BorderStyle.Single
bottomBorder.LineWidth = 1.0
bottomBorder.Color = Color.get_YellowGreen()
# Get the horizontal border and change border style, line width, and color
horizontalBorder = borders.Horizontal
horizontalBorder.BorderType = BorderStyle.Dot
horizontalBorder.LineWidth = 1.0
horizontalBorder.Color = Color.get_Orange()
# Get the vertical border and change border style, line width, and color
verticalBorder = borders.Vertical
verticalBorder.BorderType = BorderStyle.Dot
verticalBorder.LineWidth = 1.0
verticalBorder.Color = Color.get_CornflowerBlue()
# Save the resulting document
document.SaveToFile("ChangeBorders.docx", FileFormat.Docx2013)
document.Close()
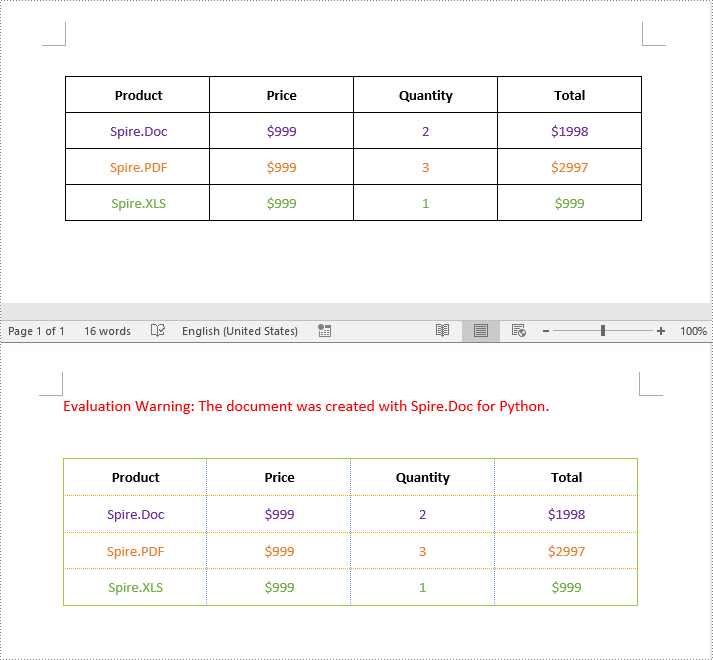
Remove Borders from a Table in Word in Python
To remove borders from a table, you need to set the BorderType property of the borders to BorderStyle.none. The detailed steps are as follows.
- Create an object of the Document class.
- Load a Word document using Document.LoadFromFile() method.
- Get a specific section using Document.Sections[index] property.
- Get a specific table using Section.Tables[index] property.
- Get the borders collection of the table using Table.TableFormat.Borders property.
- Get an individual border, such as the top border from the borders collection using Borders.Top property. Then set the BorderType property of the top border to BorderStyle.none.
- Refer to the above step to get other individual borders from the borders collection and then set the BorderType property of the borders to BorderStyle.none.
- Save the resulting document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Initialize an instance of the Document class
document = Document()
document.LoadFromFile("ChangeBorders.docx")
# Add a section to the document
section = document.Sections[0]
# Get the first table in the section
table = section.Tables[0] if isinstance(section.Tables[0], Table) else None
# Get the borders collection of the table
borders = table.TableFormat.Borders
# Remove top border
topBorder = borders.Top
topBorder.BorderType = BorderStyle.none
# Remove left border
leftBorder = borders.Left
leftBorder.BorderType = BorderStyle.none
# Remove right border
rightBorder = borders.Right
rightBorder.BorderType = BorderStyle.none
# Remove bottom border
bottomBorder = borders.Bottom
bottomBorder.BorderType = BorderStyle.none
# remove inside horizontal border
horizontalBorder = borders.Horizontal
horizontalBorder.BorderType = BorderStyle.none
# Remove inside vertical border
verticalBorder = borders.Vertical
verticalBorder.BorderType = BorderStyle.none
# Save the resulting document
document.SaveToFile("RemoveBorders.docx", FileFormat.Docx2013)
document.Close()
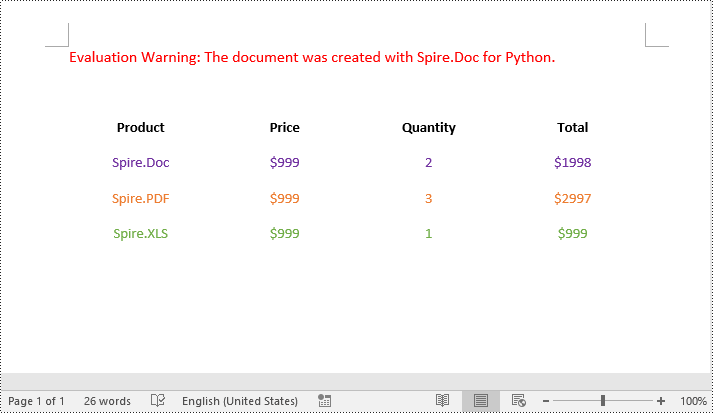
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Extract Tables from PowerPoint Presentations
PowerPoint presentations often serve as repositories of essential data and information shared during meetings, lectures, and conferences. They frequently include tables for data presentation and basic analysis. However, to further analyze the data or integrate it into reports and spreadsheets, it becomes necessary to extract these tables and save them in other formats. By leveraging Python, users can efficiently extract tables from PowerPoint presentations, transforming static slides into dynamic data sets ready for processing.
This article aims to demonstrate how to extract tables from PowerPoint presentations and write them to text and Excel worksheets using Spire.Presentation for Python, thereby enhancing the utilization of data in presentations and streamlining the data extraction process.
- Extract Table Data from PowerPoint Presentations to Text Files
- Extract Table Data from PowerPoint Presentations to Excel Worksheets
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to: How to Install Spire.Presentation for Python on Windows
Extract Table Data from PowerPoint Presentations to Text Files
Spire.Presentation for Python provides the ITable class which represents a table in a presentation slide. By iterating through the shapes in each slide to check if it’s an instance of ITable class, developers can retrieve all the tables in the presentation file and get the data in the tables.
The detailed steps for extracting tables from PowerPoint presentations and writing them to text files are as follows:
- Create an instance of Presentation class and load a PowerPoint file using Presentation.LoadFromFile() method.
- Iterate through all the slides in the file and then all the shapes in the slides.
- Check if a shape is an instance of ITable class. If it is, iterate through the rows and then the cells in each row. Get the cell values using TableRow[].TextFrame.Text property and append them to strings.
- Write the table data to text files.
- Python
from spire.presentation import *
from spire.presentation.common import *
# Create an instance of Presentation
presentation = Presentation()
# Load a PowerPoint file
presentation.LoadFromFile("Sample.pptx")
tables = []
# Iterate through all the slides
for slide in presentation.Slides:
# Iterate through all the shapes
for shape in slide.Shapes:
# Check whether the shape is a table
if isinstance(shape, ITable):
tableData = ""
# Iterate through all the rows
for row in shape.TableRows:
rowData = ""
# Iterate through all the cells in the row
for i in range(0, row.Count):
# Get the cell value
cellValue = row[i].TextFrame.Text
rowData += (cellValue + "\t" if i < row.Count - 1 else cellValue)
tableData += (rowData + "\n")
tables.append(tableData)
# Write the tables to text files
for idx, table in enumerate(tables, start=1):
fileName = f"output/Tables/Table-{idx}.txt"
with open(fileName, "w") as f:
f.write(table)
presentation.Dispose()
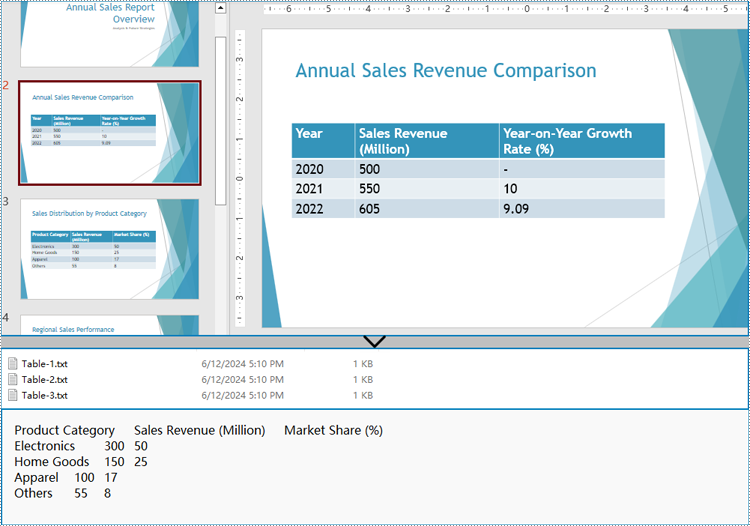
Extract Table Data from PowerPoint Presentations to Excel Worksheets
After extracting table data from presentations using Spire.Presentation for Python, developers can further utilize Spire.XLS for Python to write this data into Excel worksheets, facilitating further analysis, referencing, and format conversion.
Install Spire.XLS for Python via PyPI:
pip install Spire.XLS
The detailed steps for extracting tables from PowerPoint presentations and writing them to Excel worksheets are as follows:
- Create an instance of Presentation class and load a PowerPoint file using Presentation.LoadFromFile() method.
- Create an instance of Workbook class and clear the default worksheets.
- Iterate through the slides in the presentation and then the shapes in the slides to check if the shapes are instances of ITable class. Append all the ITable instances to a list.
- Iterate through the tables in the list and add a worksheet to the workbook for each table using Workbook.Worksheets.Add() method.
- Iterate through the rows of each table and then the cells in the rows to get the cell values through TableRow.TextFrame.Text property. Write the values to the corresponding cells in the worksheet through Worksheet.Range[].Value property.
- Save the workbook using Workbook.SaveToFile() method.
- Python
from spire.presentation import *
from spire.presentation.common import *
from spire.xls import *
from spire.xls.common import *
# Create an instance of Presentation
presentation = Presentation()
# Load a PowerPoint file
presentation.LoadFromFile("Sample.pptx")
# Create an Excel file and clear the default worksheets
workbook = Workbook()
workbook.Worksheets.Clear()
tables = []
# Iterate through all the slides
for slide in presentation.Slides:
# Iterate through all the shapes
for shape in slide.Shapes:
# Check whether the shape is a table
if isinstance(shape, ITable):
tables.append(shape)
# Iterate through all the tables
for t in range(len(tables)):
table = tables[t]
sheet = workbook.Worksheets.Add(f"Sheet-{t+1}")
for i in range(0, table.TableRows.Count):
row = table.TableRows[i]
for j in range(0, row.Count):
sheet.Range[i + 1, j + 1].Value = row[j].TextFrame.Text
# Autofit rows and columns
sheet.AllocatedRange.AutoFitColumns()
sheet.AllocatedRange.AutoFitRows()
# Save the Excel file
workbook.SaveToFile("output/PresentationTables.xlsx", FileFormat.Version2016)
presentation.Dispose()
workbook.Dispose()
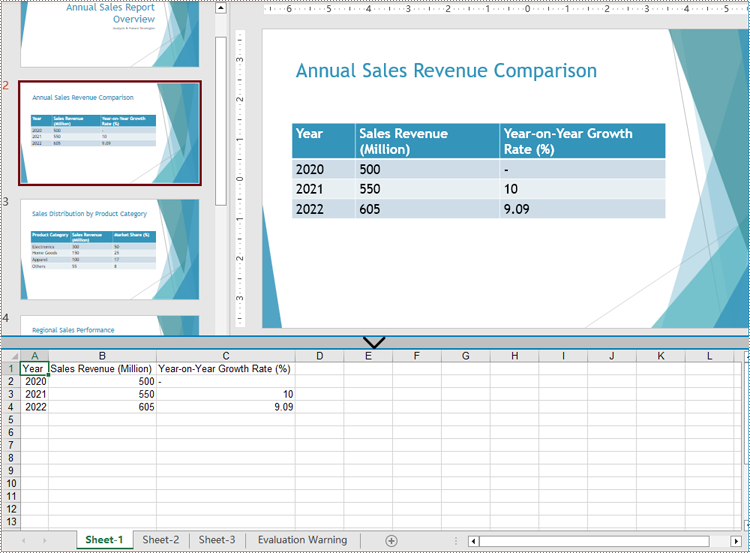
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Count Words, Pages, Characters, Paragraphs and Lines in Word
Various written documents, such as academic papers, reports, and legal materials, often have specific formatting guidelines that encompass word count, page count, and other essential metrics. Accurately measuring these elements is crucial as it ensures that your document adheres to the required standards and meets the expected quality benchmarks. In this article, we will explain how to count words, pages, characters, paragraphs, and lines in a Word document in Python using Spire.Doc for Python.
- Count Words, Pages, Characters, Paragraphs, and Lines in a Word Document in Python
- Count Words and Characters in a Specific Paragraph of a Word Document in Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python. It can be easily installed in your Windows through the following pip commands.
pip install Spire.Doc
If you are unsure how to install, please refer to: How to Install Spire.Doc for Python on Windows
Count Words, Pages, Characters, Paragraphs, and Lines in a Word Document in Python
Spire.Doc for Python offers the BuiltinDocumentProperties class that empowers you to retrieve crucial information from your Word document. By utilizing this class, you can access a wealth of details, including the built-in document properties, as well as the number of words, pages, characters, paragraphs, and lines contained within the document.
The steps below explain how to get the number of words, pages, characters, paragraphs, and lines in a Word document in Python using Spire.Doc for Python:
- Create an object of the Document class.
- Load a Word document using the Document.LoadFromFile() method.
- Get the BuiltinDocumentProperties object using the Document.BuiltinDocumentProperties property.
- Get the number of words, characters, paragraphs, lines, and pages in the document using the WordCount, CharCount, ParagraphCount, LinesCount, PageCount properties of the BuiltinDocumentProperties class, and append the result to a list.
- Write the content of the list into a text file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of the Document class
doc = Document()
# Load a Word document
doc = Document("Input.docx")
# Create a list
sb = []
# Get the built-in properties of the document
properties = doc.BuiltinDocumentProperties
# Get the number of words, characters, paragraphs, lines, and pages and append the result to the list
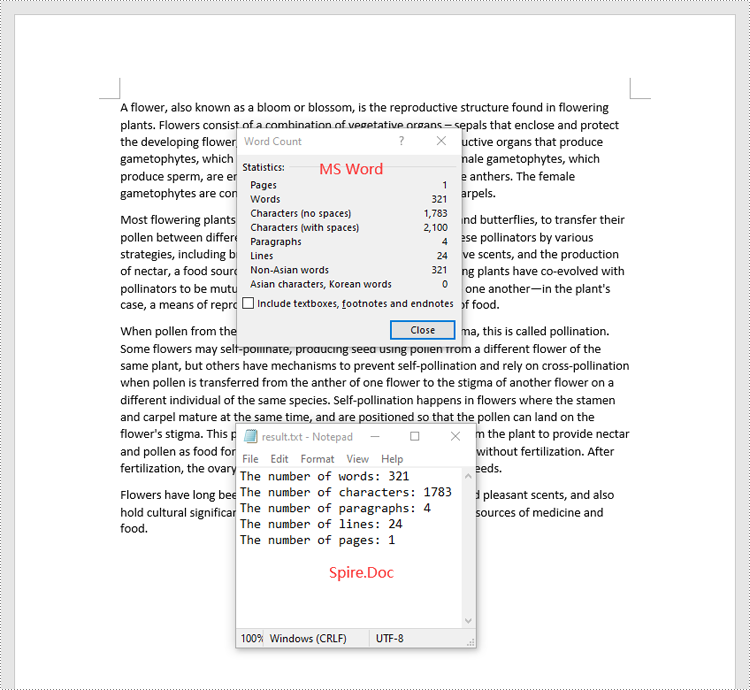
sb.append("The number of words: " + str(properties.WordCount))
sb.append("The number of characters: " + str(properties.CharCount))
sb.append("The number of paragraphs: " + str(properties.ParagraphCount))
sb.append("The number of lines: " + str(properties.LinesCount))
sb.append("The number of pages: " + str(properties.PageCount))
# Save the data in the list to a text file
with open("result.txt", "w") as file:
file.write("\n".join(sb))
doc.Close()
Count Words and Characters in a Specific Paragraph of a Word Document in Python
In addition to retrieving the overall word count, page count, and other metrics for an entire Word document, you are also able to get the word count and character count for a specific paragraph by using the Paragraph.WordCount and Paragraph.CharCount properties.
The steps below explain how to get the number of words and characters of a paragraph in a Word document in Python using Spire.Doc for Python:
- Create an object of the Document class.
- Load a Word document using the Document.LoadFromFile() method.
- Get a specific paragraph using the Document.Sections[sectionIndex].Paragraphs[paragraphIndex] property.
- Get the number of words and characters in the paragraph using the Paragraph.WordCount and Paragraph.CharCount properties, and append the result to a list.
- Write the content of the list into a text file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of the Document class
doc = Document()
# Load a Word document
doc = Document("Input.docx")
# Get a specific paragraph
paragraph = doc.Sections[0].Paragraphs[0]
# Create a list
sb = []
# Get the number of words and characters in the paragraph and append the result to the list
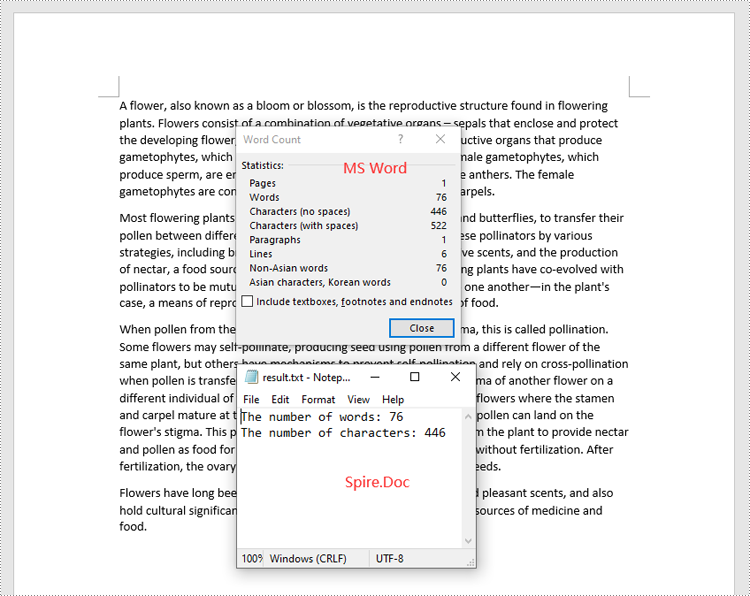
sb.append("The number of words: " + str(paragraph.WordCount))
sb.append("The number of characters: " + str(paragraph.CharCount))
# Save the data in the list to a text file
with open("result.txt", "w") as file:
file.write("\n".join(sb))
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.PDF for Python 10.6.1 supports comparing PDF documents
We're pleased to announce the release of Spire.PDF for Python 10.6.1. This version supports comparing PDF documents and fixes some known issues, such as the application throwing an exception when obtaining image coordinates. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-6784 | Supports comparing PDF documents.
pdf1 = PdfDocument() pdf1.LoadFromFile(inputFile_1) pdf2 = PdfDocument() pdf2.LoadFromFile(inputFile_2) comparer = PdfComparer(pdf1, pdf2) comparer.Compare(outputFile) |
| Bug | SPIREPDF-6764 | Fixes the issue that the application threw an exception when obtaining image coordinates. |
| Bug | SPIREPDF-6795 | Fixes the issue that the application threw an exception when getting images using the PdfImageHelper.GetImagesInfo() method. |
| Bug | SPIREPDF-6809 | Fixes the issue that the application threw an exception when setting the markup color using the PdfTextMarkupAnnotation.TextMarkupColor property. |
Spire.PDF 10.6.7 supports converting PDF to Markdown
We are delighted to announce the release of Spire.PDF 10.6.7. This version supports converting PDF documents to Markdown files. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Supports converting PDF documents to Markdown files.
PdfDocument doc = new PdfDocument("input.pdf");
doc.SaveToFile("output.md", FileFormat.Markdown);
|
Python: Add, Count, Retrieve and Remove Word Variables
When dealing with a large volume of customized documents such as contracts, reports, or personal letters, the variable feature in Word documents becomes crucial. Variables allow you to store and reuse information like dates, names, or product details, making the documents more personalized and dynamic. This article will delve into how to use Spire.Doc for Python to insert, count, retrieve, and delete variables in Word documents, enhancing the efficiency and flexibility of document management.
- Add Variables into Word Documents
- Count the Number of Variables in a Word Document
- Retrieve Variables from a Word Document
- Delete Variables from a Word Document
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Window through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Window
Add Variables into Word Documents with Python
The way Word variables work is based on the concept of "fields". When you insert a variable into a Word document, what you're actually doing is inserting a field, which points to a value stored either in the document properties or an external data source. Upon updating the fields, Word recalculates them to display the most current information.
Spire.Doc for Python offers the VariableCollection.Add(name, value) method to insert variables into Word documents. Here are the detailed steps:
- Create a Document object.
- Call the Document.AddSection() method to create a new section.
- Call the Section.AddParagraph() method to create a new paragraph.
- Call the Paragraph.AppendField(fieldName, fieldType) method to add a variable field (FieldDocVariable) within the paragraph.
- Set Document.IsUpdateFields to True to update the fields.
- Save the document by Document.SaveToFile() method.
- Python
from spire.doc import *
# Create a Document object
document = Document()
# Add a new section to the document
section = document.AddSection()
# Add a new paragraph within the newly created section
paragraph = section.AddParagraph()
# Append a FieldDocVariable type field named "CompanyName" to the paragraph
paragraph.AppendField("CompanyName", FieldType.FieldDocVariable)
# Add the variable to the document's variable collection
document.Variables.Add("CompanyName", "E-ICEBLUE")
# Update fields
document.IsUpdateFields = True
# Save the document to a specified path
document.SaveToFile("AddVariable.docx", FileFormat.Docx2016)
# Dispose the document
document.Dispose()

Count the Number of Variables in a Word Document with Python
Here are the detailed steps to use the Document.Variables.Count property to get the number of variables:
- Create a Document object.
- Call the Document.LoadFromFile() method to load the document that contains the variables.
- Use the Document.Variables.Count property to obtain the number of variables.
- Print the count in console.
- Python
from spire.doc import *
# Create a Document object
document = Document()
# Load an existing document
document.LoadFromFile("AddVariable.docx")
# Get the count of variables in the document
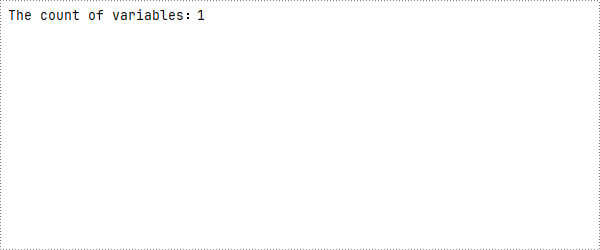
count=document.Variables.Count
# Print to console
print(f"The count of variables:{count}")
Retrieve Variables from a Word Document with Python
Spire.Doc for Python provides the GetNameByIndex(int index) and GetValueByIndex(int index) methods to retrieve variable names and values by their indices. Below are the detailed steps:
- Create a Document object.
- Call the Document.LoadFromFile() method to load the document that contains the variables.
- Call the Document.Variables.GetNameByIndex(index) method to obtain the variable name.
- Call the Document.Variables.GetValueByIndex(index) method to obtain the variable value.
- Call the Document.Variables.get_Item(name) to obtain variable value through the variable name.
- Print the count in console.
- Python
from spire.doc import *
# Create a Document object
document = Document()
# Load an existing document
document.LoadFromFile("AddVariable.docx")
# Obtain variable name based on index 0
name=document.Variables.GetNameByIndex(0)
# Obtain variable value based on index 0
value=document.Variables.GetValueByIndex(0)
# Obtain variable value through the variable name
value1=document.Variables.get_Item("CompanyName")
# Print to console
print("Variable Name:", name)
print("Variable Value:", value)

Delete Variables from a Word Document with Python
The VariableCollection.Remove(name) method can be used to delete a specified variable from the document, with the parameter being the name of the variable.
- Create a Document object.
- Call the Document.LoadFromFile() method to load the document that contains the variables.
- Call the Document.Variables.Remove(name) method to remove the variable.
- Set Document.IsUpdateFields to True to update the fields.
- Save the document by Document.SaveToFile() method.
- Python
from spire.doc import *
# Create a Document object
document = Document()
# Load an existing document
document.LoadFromFile("AddVariable.docx")
# Remove the variable named "CompanyName"
document.Variables.Remove("CompanyName")
# Update fields
document.IsUpdateFields=True
# Save the document
document.SaveToFile("RemoveVariable.docx",FileFormat.Docx2016)
# Dispose the document
document.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
How to Install Spire.Doc for Python on Mac
Spire.Doc for Python is a robust library that enables you to read and write Microsoft Word documents using Python. With Spire.Doc, you can create, read, edit, and convert both DOC and DOCX file formats without requiring Microsoft Word to be installed on your system.
This article demonstrates how to install Spire.Doc for Python on Mac.
Step 1
Download the most recent version of Python for macOS and install it on your Mac. If you have already completed this step, proceed directly to step 2.
Step 2
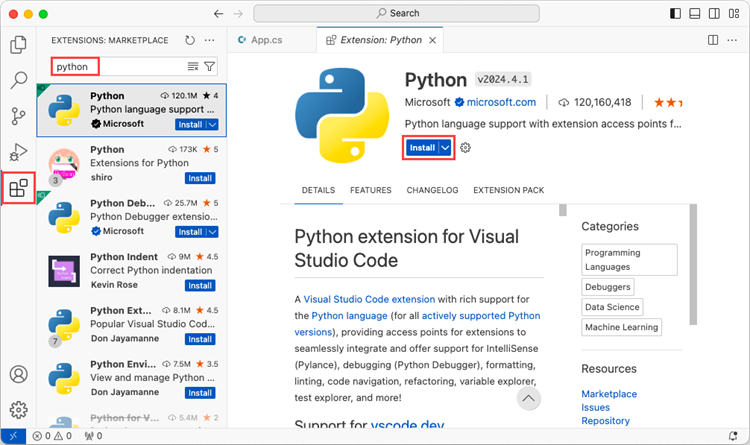
Open VS Code and search for 'Python' in the Extensions panel. Click 'Install' to add support for Python in your VS Code.
Step 3
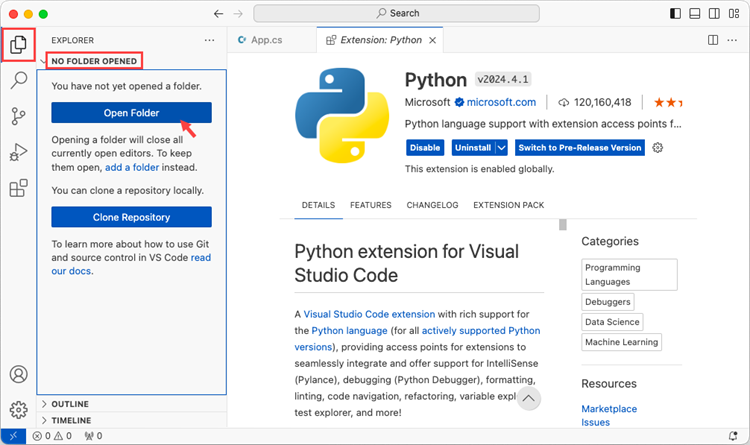
Click 'Explorer' > 'NO FOLRDER OPENED' > 'Open Folder'.
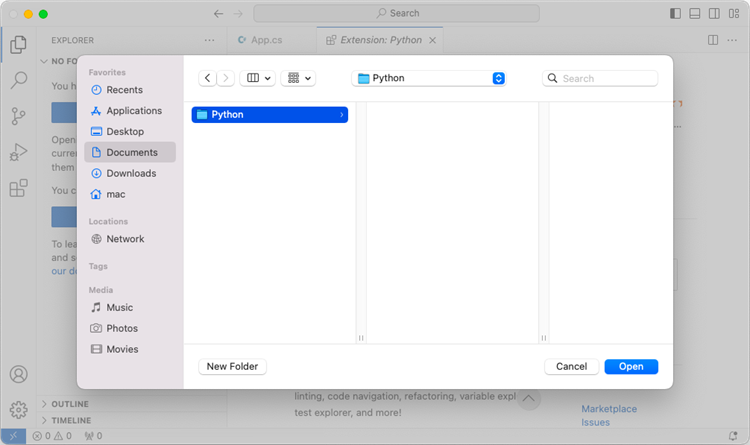
Choose an existing folder as the workspace, or you can create a new folder and then open it.
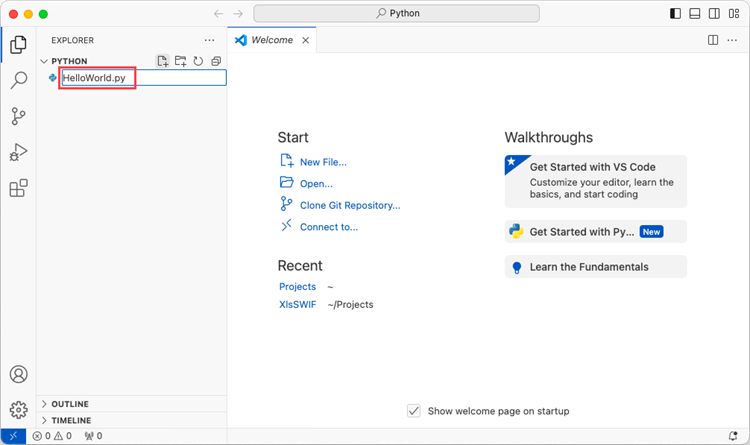
Add a .py file to the folder you just opened and name it whatever you want (in this case, HelloWorld.py).
Step 4
Use the keyboard shortcut Ctrl + ' to open the Terminal. Then, install Spire.Doc for Python by entering the following command line in the terminal.
pip3 install spire.doc
Note that pip3 is a package installer specifically designed for Python 3.x versions, while pip is a package installer for Python 2.x versions. If you are working with Python 2.x, you can use the pip command.
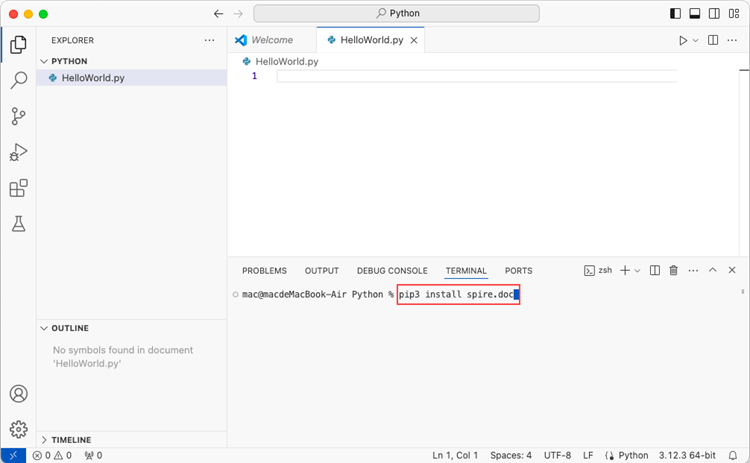
Step 5
Open a Terminal window on your Mac, and type the following command to obtain the installation path of Python on your system.
python3 -m pip --version
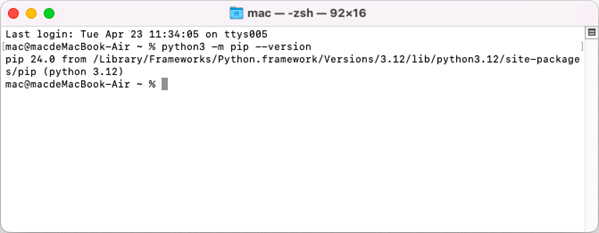
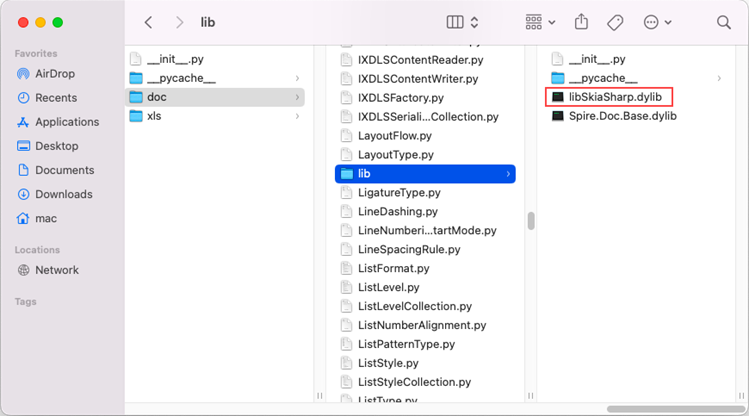
Find the libSkiaSharp.dylib file under the site-packages/spire/doc/lib folder. The full path in this case is /Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/spire/doc/lib/libSkiaSharp.dylib
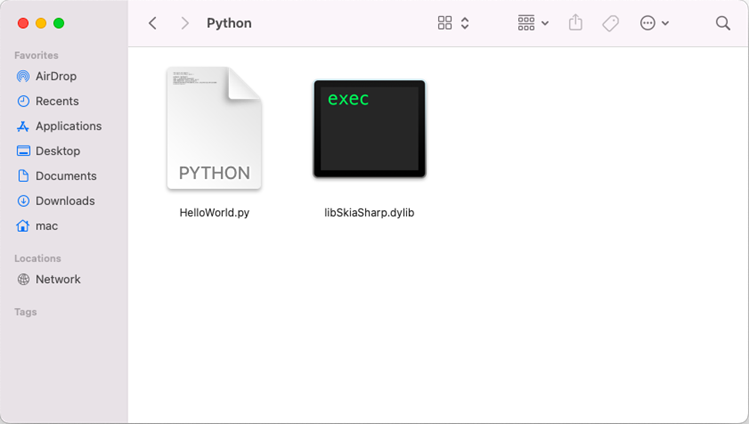
Copy the libSkiaSharp.dylib file into the folder where your .py file is located.
Step 6
Add the following code snippet to the 'HelloWorld.py' file.
- Python
from spire.doc.common import *
from spire.doc import *
document = Document()
section = document.AddSection()
paragraph = section.AddParagraph()
paragraph.AppendText("Hello World")
document.SaveToFile("HelloWorld.docx", FileFormat.Docx2019)
document.Dispose()
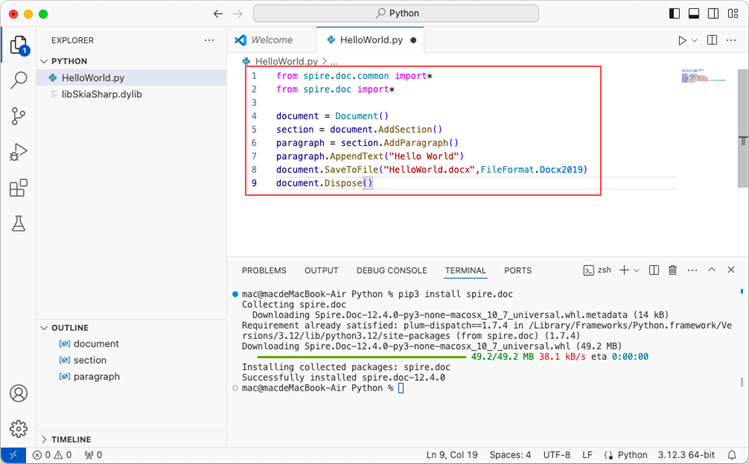
After executing the Python file, you will find the resulting Word document in the 'EXPLORER' panel.
C#: Add or Remove Columns in A PowerPoint Text Box
Displaying PowerPoint text box content in multiple columns significantly enhances the presentation of information and audience comprehension. It improves readability by shortening line lengths, making dense text more digestible; optimizes visual layout for an aesthetically pleasing and professional look; and utilizes space efficiently to ensure that information is abundant yet uncluttered. In this article, we will introduce how to add or remove columns in a PowerPoint text box using Spire.Presentation for .NET in C# projects.
Install Spire.Presentation for .NET
To begin with, you need to add the DLL files included in the Spire.Presentation for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Presentation
Add Columns to a PowerPoint Text Box with C#
Spire.Presentation provides the Shape.TextFrame.ColumnCount property to set the number of columns for content and the Shape.TextFrame.ColumnSpacing property to set the spacing between columns. Below are the detailed steps:
- Create a Presentation object.
- Load a PowerPoint document using the Presentation.LoadFromFile() method.
- Retrieve the first slide using Presentation.Slides[0].
- Obtain the first text box object as IAutoShape.
- Use the Shape.TextFrame.ColumnCount property to set the number of columns for the text box content.
- Use the Shape.TextFrame.ColumnSpacing property to set the spacing between columns.
- Save the document to a specified path using the Presentation.SaveToFile() method.
- C#
using Spire.Presentation;
namespace Spire.PresentationDemo
{
internal class Program
{
static void Main(string[] args)
{
// Create a Presentation object
Presentation presentation = new Presentation();
// Load the PPTX file
presentation.LoadFromFile("Sample1.pptx");
// Get the first slide
ISlide slide = presentation.Slides[0];
// Check if the first shape on the slide is of type IAutoShape
if (slide.Shapes[0] is IAutoShape)
{
// Cast the first shape to an IAutoShape object
IAutoShape shape = (IAutoShape)slide.Shapes[0];
// Set the number of columns in the shape's text frame to 2
shape.TextFrame.ColumnCount = 2;
// Set the column spacing in the shape's text frame to 25 pt
shape.TextFrame.ColumnSpacing = 25f;
}
// Save the modified presentation as a new PPTX file
presentation.SaveToFile("SetColumns.pptx", Spire.Presentation.FileFormat.Pptx2016);
// Dispose of the resources used by the Presentation object
presentation.Dispose();
}
}
}

Remove Columns from a PowerPoint Text Box with C#
To remove the columns from the Powerpoint text box, simply set the Shape.TextFrame.ColumnCount property to 1. Below are the detailed steps:
- Create a Presentation object.
- Load a PowerPoint document using the Presentation.LoadFromFile() method.
- Retrieve a slide using the Presentation.Slides[index] property.
- Obtain the text box object as IAutoShape.
- Set Shape.TextFrame.ColumnCount = 1 to remove the columns.
- Save the document to a specified path using the Presentation.SaveToFile() method.
- C#
using Spire.Presentation;
namespace SpirePresentationDemo
{
internal class Program
{
static void Main(string[] args)
{
// Create a Presentation object
Presentation presentation = new Presentation();
// Load the PPTX file
presentation.LoadFromFile("Sample2.pptx");
// Get the first slide
ISlide slide = presentation.Slides[0];
// Check if the first shape on the slide is of type IAutoShape
if (slide.Shapes[0] is IAutoShape)
{
// Cast the first shape to an IAutoShape object
IAutoShape shape = (IAutoShape)slide.Shapes[0];
// Set the column count of the shape's text frame to 1
shape.TextFrame.ColumnCount = 1;
}
// Save the modified presentation as a new PPTX file
presentation.SaveToFile("RemoveColumns.pptx", Spire.Presentation.FileFormat.Pptx2016);
// Dispose of the resources used by the Presentation object
presentation.Dispose();
}
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Barcode for Java 5.1.11 supports obtaining barcode information
We are happy to announce the release of Spire.Barcode for Java 5.1.11. In this version, the BarcodeScanner class adds several methods for obtaining barcode information, scanning Aztec type, and scanning with more overload settings. Moreover, this release also includes some internal interface adjustments. Details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREBARCODE-258 | The BarcodeScanner class supports obtaining barcode information, including barcode type, data value and vertex position information.
BarcodeInfo[] infos = BarcodeScanner.scanInfo("barcode.png");
Point[] loaction = infos[0].getVertexes();
BarCodeReadType barCodeReadType = infos[0].getReadType();
String dataString = infos[0].getDataString();
|
| New feature | - | The BarcodeScanner class supports scanning Aztec type.
String[] s = BarcodeScanner.scan("AZTEC.png",BarCodeType.Aztec);
|
| New feature | - | The BarcodeScanner class supports scanning with more overload settings.
Public static String[] scan(BufferedImage bitmap, java.awt.Rectangle rect, BarCodeType barcodeType, boolean IncludeCheckSum) Public static String[] scan(String fileName, BarCodeType barcodeType, boolean IncludeCheckSum) Public static String scanOne(String fileName, BarCodeType barcodeType, boolean IncludeCheckSum) Public static String scanOne(InputStream stream, BarCodeType barcodeType, boolean IncludeCheckSum) |
| New feature | - | Adds external use enumerations.
com.spire.barcode.publics.drawing.FontStyle com.spire.barcode.publics.drawing.GraphicsUnit com.spire.barcode.publics.drawing.StringAlignment |
| New feature | - | Adjustments to the IBarCodeSettings interface.
Recycled: public java.awt.Font getTopTextFont() public java.awt.Font getBottomTextFont() public java.awt.Font getTextFont() Modified: public void setBottomTextFont(java.awt.Font value)->public void setBottomTextFont(String familyName, float fontSize) public void setTopTextFont(java.awt.Font value)->public void setTopTextFont(String familyName, float fontSize) public boolean showBottomText->public boolean isShowBottomText() public void setShowBottomText(boolean value) -> public void isShowBottomText(boolean value) public com.spire.barcode.GraphicsUnit getUnit() -> public com.spire.barcode.publics.drawing.GraphicsUnit getUnit() public void setUnit(com.spire.barcode.GraphicsUnit value) -> public void setUnit(com.spire.barcode.publics.drawing.GraphicsUnit value) public void setTextFont(java.awt.Font value) -> public void setTextFont(String familyName, float fontSize) public float getLeftMargin() ->The default value adjusted from 5 to 4. Newly Added: public float getTopTextMargin() public void setTopTextMargin(float value) public int getAztecErrorCorrection() public void setAztecErrorCorrection(int value) public int getAztecLayers() public void setAztecLayers(int value) public DataMatrixSymbolShape getDataMatrixSymbolShape() public void setDataMatrixSymbolShape(DataMatrixSymbolShape value) public ITF14BorderType getITF14BearerBars() public void setITF14BearerBars(ITF14BorderType value) public void setTextFont(String familyName, float fontSize, com.spire.barcode.publics.drawing.FontStyle style) public boolean isShowStartCharAndStopChar() public void isShowStartCharAndStopChar(boolean value) |
| New feature | - | Adjustments to the BarcodeSettings class interfaces.
Recycled: public java.awt.Font getTextFont() public java.awt.Font getTopTextFont() public java.awt.Font getBottomTextFont() Modified: public void setTextFont(java.awt.Font value) -> public void setTextFont(String familyName, float sizePoints) public com.spire.barcode.GraphicsUnit getUnit() -> public com.spire.barcode.publics.drawing.GraphicsUnit getUnit() public void setUnit(com.spire.barcode.GraphicsUnit value) -> public void setUnit(com.spire.barcode.publics.drawing.GraphicsUnit value) public com.spire.barcode.StringAlignment getTextAlignment() -> public com.spire.barcode.publics.drawing.StringAlignment getTextAlignment() public void setTextAlignment(com.spire.barcode.StringAlignment value) -> public void setTextAlignment(com.spire.barcode.publics.drawing.StringAlignment value) public com.spire.barcode.StringAlignment getTopTextAligment() -> public com.spire.barcode.publics.drawing.StringAlignment getTopTextAligment() public void setTopTextAligment(com.spire.barcode.StringAlignment value) -> public void setTopTextAligment(com.spire.barcode.publics.drawing.StringAlignment value) public void setBottomTextFont(java.awt.Font value) -> public void setBottomTextFont(String familyName, float fontSize) public void setTopTextFont(java.awt.Font value) -> public void setTopTextFont(String familyName, float fontSize) public boolean showBottomText->public boolean isShowBottomText() public void setShowBottomText(boolean value) -> public void isShowBottomText(boolean value) public com.spire.barcode.StringAlignment getBottomTextAlignment() -> public com.spire.barcode.publics.drawing.StringAlignment getBottomTextAlignment() public void setBottomTextAlignment(com.spire.barcode.StringAlignment value) -> public void setBottomTextAlignment(com.spire.barcode.publics.drawing.StringAlignment value) public float getLeftMargin() ->The default value adjusted from 5 to 4. Newly Added: public float getTopTextMargin() public void setTopTextMargin(float value) public void setTextFont(String familyName, float sizePoints, com.spire.barcode.publics.drawing.FontStyle style) public void setTopTextFont(String familyName, float fontSize, com.spire.barcode.publics.drawing.FontStyle style) public void setITF14BearerBars(ITF14BorderType value) public boolean isShowStartCharAndStopChar() public void isShowStartCharAndStopChar(boolean value) public int getAztecLayers() public void setAztecLayers(int value) public int getAztecErrorCorrection() public void setAztecErrorCorrection(int value) public DataMatrixSymbolShape getDataMatrixSymbolShape() public void setDataMatrixSymbolShape(DataMatrixSymbolShape value) public void setBottomTextFont(String familyName, float fontSize, com.spire.barcode.publics.drawing.FontStyle style) |
Python: Insert or Remove Section Breaks in Word
Section breaks in Word allow users to divide a document into sections, each with unique formatting options. This is especially useful when working with long documents where you want to apply different layouts, headers, footers, margins or page orientations within the same document. In this article, you will learn how to insert or remove section breaks in Word in Python using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Insert Section Breaks in Word in Python
Spire.Doc for Python provides the Paragraph.InsertSectionBreak(breakType: SectionBreakType) method to insert a specified type of section break to a paragraph. The following table provides an overview of the supported section break types, along with their corresponding Enums and descriptions:
| Section Break | Enum | Description |
| New page | SectionBreakType.New_Page | Start the new section on a new page. |
| Continuous | SectionBreakType.No_Break | Start the new section on the same page, allowing for continuous content flow. |
| Odd page | SectionBreakType.Odd_Page | Start the new section on the next odd-numbered page. |
| Even page | SectionBreakType.Even_Page | Start the new section on the next even-numbered page. |
| New column | SectionBreakType.New_Column | Start the new section in the next column if columns are enabled. |
The following are the detailed steps to insert a continuous section break:
- Create a Document instance.
- Load a Word document using Document.LoadFromFile() method.
- Get a specified section using Document.Sections[] property.
- Get a specified paragraph of the section using Section.Paragraphs[] property.
- Add a section break to the end of the paragraph using Paragraph.InsertSectionBreak() method.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import * from spire.doc.common import * inputFile = "sample.docx" outputFile = "InsertSectionBreak.docx" # Create a Document instance document = Document() # Load a Word document document.LoadFromFile(inputFile) # Get the first section in the document section = document.Sections[0] # Get the second paragraph in the section paragraph = section.Paragraphs[1] # Insert a continuous section break paragraph.InsertSectionBreak(SectionBreakType.NoBreak) # Save the result document document.SaveToFile(outputFile, FileFormat.Docx2016) document.Close()

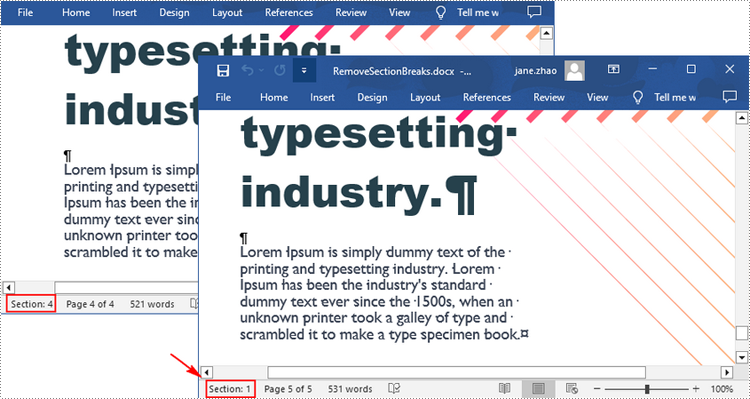
Remove Section Breaks in Word in Python
To delete all sections breaks in a Word document, we need to access the first section in the document, then copy the contents of the other sections to the first section and delete them. The following are the detailed steps:
- Create a Document instance.
- Load a Word document using Document.LoadFromFile() method.
- Get the first section using Document.Sections[] property.
- Iterate through other sections in the document.
- Get the second section, and then iterate through to get its child objects.
- Clone the child objects of the second section and add them to the first section using Section.Body.ChildObjects.Add() method.
- Delete the second section using Document.Sections.Remove() method.
- Repeat the process to copy and delete the remaining sections.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
inputFile = "Report.docx"
outputFile = "RemoveSectionBreaks.docx"
# Create a Document instance
document = Document()
# Load a Word document
document.LoadFromFile(inputFile)
# Get the first section in the document
sec = document.Sections[0]
# Iterate through other sections in the document
for i in range(document.Sections.Count - 1):
# Get the second section in the document
section = document.Sections[1]
# Iterate through all child objects of the second section
for j in range(section.Body.ChildObjects.Count):
# Get the child objects
obj = section.Body.ChildObjects.get_Item(j)
# Clone the child objects to the first section
sec.Body.ChildObjects.Add(obj.Clone())
# Remove the second section
document.Sections.Remove(section)
# Save the result document
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.