Python: Convert Charts and Shapes in Excel to Images
Charts and shapes in Excel are vital tools for clear and effective data presentation. Sometimes, it's beneficial to convert these visual elements into images. Perhaps you need to include a specific chart in a report or presentation outside of Excel. Or maybe you want to use an Excel-created infographic on your company's website. Regardless of the use case, knowing how to export these visuals as standalone image files can be invaluable. In this guide, we will explore how to convert charts and shapes in Excel to images in Python using Spire.XLS for Python.
- Convert a Specific Chart in an Excel Worksheet to Image in Python
- Convert All Charts in an Excel Worksheet to Images in Python
- Convert a Chart Sheet in Excel to Image in Python
- Convert Shapes in Excel to Images in Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Convert a Specific Chart in an Excel Worksheet to Image in Python
Spire.XLS for Python offers the Workbook.SaveChartAsImage(worksheet: Worksheet, chartIndex: int) method, allowing you to convert a specific chart within a worksheet into an image stream. This image stream can then be saved as an image file in various formats, including PNG, JPG, BMP, and more. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using the Workbook.LoadFromFile() method.
- Get a specific worksheet in the file using the Workbook.Worksheets[] property.
- Save a specific chart in the worksheet to an image stream using the Workbook.SaveChartAsImage(worksheet: Worksheet, chartIndex: int) method.
- Save the image stream to an image file using the Stream.Save() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Charts.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Save the first chart in the worksheet to an image stream
image_stream = workbook.SaveChartAsImage(sheet, 0)
# Save the image stream to a PNG image file
image_stream.Save("Output/chart.png")
workbook.Dispose()
Convert All Charts in an Excel Worksheet to Images in Python
To convert all charts in an Excel worksheet to images, you can use the Workbook.SaveChartAsImage(worksheet: Worksheet) method. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using the Workbook.LoadFromFile() method.
- Get a specific worksheet in the file using the Workbook.Worksheets[] property.
- Save all charts in the worksheet to a list of image streams using the Workbook.SaveChartAsImage(worksheet: Worksheet) method.
- Iterate through the image streams in the list and save them to separate image files.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Charts.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
image_streams = []
# Save the charts in the worksheet to a list of image streams
image_streams = workbook.SaveChartAsImage(sheet)
# Save the image streams to PNG image files
for i, image_stream in enumerate(image_streams):
image_stream.Save(f"Output/chart-{i}.png")
workbook.Dispose()
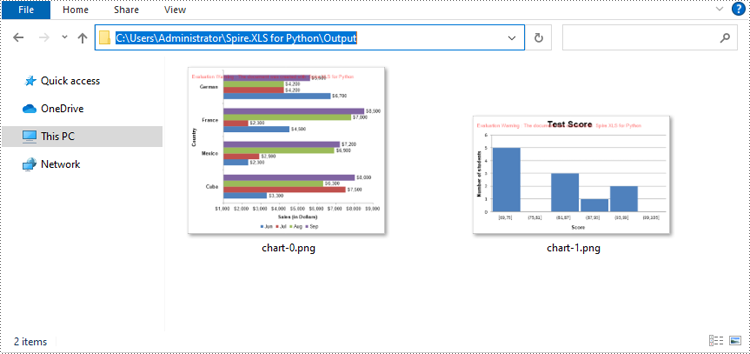
Convert a Chart Sheet in Excel to Image in Python
In Microsoft Excel, a chart sheet is a special type of sheet that is dedicated to displaying a single chart or graph. You can convert a chart sheet in an Excel workbook to an image using the Workbook.SaveChartAsImage(chartSheet: ChartSheet) method. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using the Workbook.LoadFromFile() method.
- Get a specific chart sheet in the file using the Workbook.Chartsheets[] property.
- Save the chart sheet to an image stream using the Workbook.SaveChartAsImage(chartSheet: ChartSheet) method.
- Save the image stream to an image file.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("ChartSheet.xlsx")
# Get the first chart sheet
chart_sheet = workbook.Chartsheets[0]
# Save the chart sheet to an image stream
image_stream = workbook.SaveChartAsImage(chart_sheet)
# Save the image stream to a PNG image file
image_stream.Save("Output/chartSheet.png")
workbook.Dispose()
Convert Shapes in Excel to Images in Python
In addition to converting charts or chart sheets to images, you can also convert shapes in an Excel worksheet to images by using the XlsShape.SaveToImage() method. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using the Workbook.LoadFromFile() method.
- Get a specific worksheet in the file using the Workbook.Worksheets[] property.
- Iterate through all the shapes in the worksheet.
- Typecast the shape to an XlsShape object.
- Save the shape to an image stream using the XlsShape.SaveToImage() method.
- Save the image stream to an image file.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Shapes.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Iterate through all the shapes in the worksheet
for i, shape in enumerate(sheet.PrstGeomShapes):
xls_shape = XlsShape(shape)
# Save the shape to an image stream
image_stream = shape.SaveToImage()
# Save the image stream to a PNG image file
image_stream.Save(f"Output/shape_{i}.png")
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create and Execute Conditional Mail Merges in Word Documents
Conditional mail merge in Word documents is a powerful method for personalized communication at scale. Unlike other mail merges that apply the same template to all recipients, conditional mail merge allows users to customize content based on specific criteria or conditions, ensuring that each recipient receives information that is directly relevant to them. By leveraging Python, users can automate the creation and execution of conditional mail merges.
This article will show how to create and execute conditional mail merges in Word documents through Python code using Spire.Doc for Python.
- Create Conditional Mail Merge in a Word Document with Python
- Execute Conditional Mail Merge in a Word Document with Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to: How to Install Spire.Doc for Python on Windows
Create Conditional Mail Merge in a Word Document with Python
A conditional mail merge uses an If field containing a mail merge field, which alters the merge results based on the data. To add a conditional mail merge to a Word document, insert an If field, then include a mail merge field within the If field’s code, and finish by adding the field end mark to complete the setup. The condition is controlled by the code within the If field.
The detailed steps for adding a conditional mail merge to a Word document are as follows:
- Create an instance of the Document class to generate a Word document.
- Add a section to the document and configure the page setup.
- Create paragraph styles, add paragraphs, and set their formats.
- Create an IfField object, set its starting code through the IfField.Code property, and insert it into a paragraph using the Paragraph.Items.Add() method.
- Append a mail merge field to the paragraph using the Paragraph.AppendField() method.
- Append the remaining code to the paragraph using the Paragraph.AppendText() method.
- Append a field end mark to end the If field using the Paragraph.AppendFieldMark() method.
- Set the end mark as the end mark of the If field through the IfField.End property.
- Save the document using the Document.SaveToFile() method.
- Python
from spire.doc import *
# Create an instance of Document
doc = Document()
# Add a section to the document
section = doc.AddSection()
# Set the page size and margins
section.PageSetup.PageSize = PageSize.A4()
section.PageSetup.Margins.All = 50
# Create a paragraph style
style = ParagraphStyle(doc)
style.Name = "Style1"
style.CharacterFormat.FontName = "Arial"
style.CharacterFormat.FontSize = 14
style.ParagraphFormat.BeforeSpacing = 5
style.ParagraphFormat.AfterSpacing = 10
doc.Styles.Add(style)
# Add paragraphs and set the style
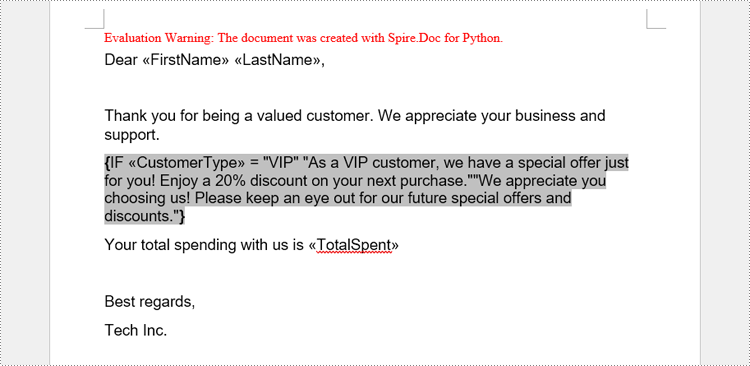
paragraph = section.AddParagraph()
paragraph.AppendText("Dear ")
paragraph.AppendField("FirstName", FieldType.FieldMergeField)
paragraph.AppendText(" ")
paragraph.AppendField("LastName", FieldType.FieldMergeField)
paragraph.AppendText(",")
paragraph.ApplyStyle(style.Name)
paragraph = section.AddParagraph()
paragraph.AppendText("\r\nThank you for being a valued customer. We appreciate your business and support.")
paragraph.ApplyStyle(style.Name)
# Add an If field to a paragraph
paragraph = section.AddParagraph()
ifField = IfField(doc)
ifField.Type = FieldType.FieldIf
ifField.Code = "IF "
paragraph.Items.Add(ifField)
# Add a mail merge field in the code of the If field
paragraph.AppendField("CustomerType", FieldType.FieldMergeField)
paragraph.AppendText(" = ")
paragraph.AppendText("\"VIP\"")
paragraph.AppendText(" \"As a VIP customer, we have a special offer just for you! Enjoy a 20% discount on your next "
"purchase.\"")
paragraph.AppendText("\"We appreciate you choosing us! Please keep an eye out for our future special offers and "
"discounts.\"")
# Add a field end mark at the end to end the If field
endIf = paragraph.AppendFieldMark(FieldMarkType.FieldEnd)
ifField.End = endIf
paragraph.ApplyStyle(style.Name)
# Add paragraphs and set the style
paragraph = section.AddParagraph()
paragraph.AppendText("Your total spending with us is ")
paragraph.AppendField("TotalSpent", FieldType.FieldMergeField)
paragraph.ApplyStyle(style.Name)
paragraph = section.AddParagraph()
paragraph.AppendText("\r\nBest regards,\r\nTech Inc.")
paragraph.ApplyStyle(style.Name)
# Save the document
doc.SaveToFile("output/ConditionalMailMerge.docx", FileFormat.Docx)
doc.Close()
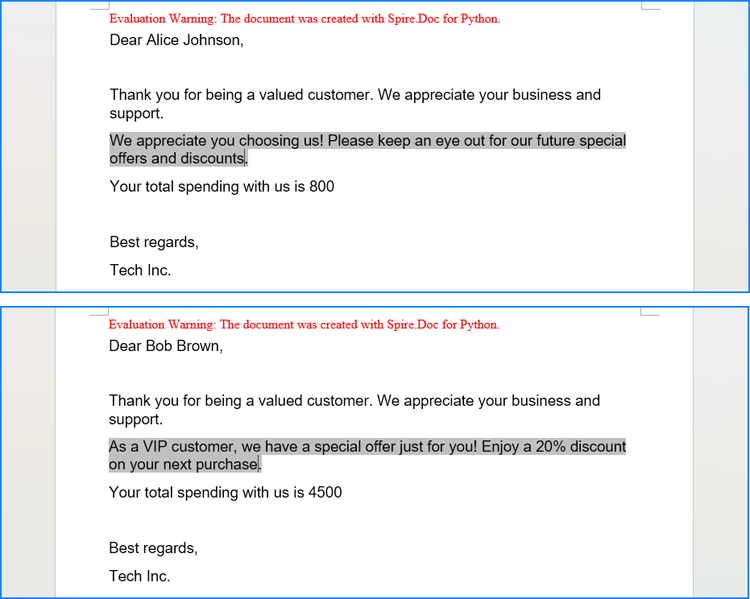
Execute Conditional Mail Merge in a Word Document with Python
The Document.MailMerge.Execute(fieldNames: list[str], fieldValues: list[str]) method provided by Spire.Doc for Python allows for mail merge operations within Word documents. After the merge, you can update the results of conditional mail merges by setting the Document.IsUpdateFields property to True. The detailed steps are as follows:
- Read the data in the table used for the merge as a two-dimensional list.
- Iterate through the data rows, skipping the header:
- Create an instance of the Document class and load the Word document to be merged.
- Get the names of the mail merge fields as a list using the Document.MailMerge.GetMergeFieldNames() method.
- Execute the mail merge with the data using the Document.MailMerge.Execute() method.
- Update the If field by setting the Document.IsUpdateFields property to True.
- Save the document using the Document.SaveToFile() method.
- Python
from spire.doc import *
import csv
# Read the data from a CSV file
data = []
with open("Customers.csv", "r") as csvfile:
read = csv.reader(csvfile)
for row in read:
data.append(row)
# Iterate through the data rows by skipping the header
for i in range(1, len(data)):
# Create an instance of Document and load a Word document
doc = Document("output/ConditionalMailMerge.docx")
# Get the field names from the document
fieldNames = doc.MailMerge.GetMergeFieldNames()
# Execute the mail merge
doc.MailMerge.Execute(fieldNames, data[i])
# Update the If field
doc.IsUpdateFields = True
# Save the document
doc.SaveToFile(f"output/Customers/{data[i][0]} {data[i][1]}.docx", FileFormat.Docx2019)
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Doc 12.8.2 enhances the conversion from Word to OFD and PDF
We are happy to announce the release of Spire.Doc 12.8.2. This version enhances the conversion from Word to OFD and PDF. Some known bugs are fixed in this update as well, such as the issue that extra blank pages are generated when converting Word to OFD. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREDOC-10219 | Fixes the issue that extra blank pages are generated when converting Word to OFD. |
| Bug | SPIREDOC-10365 | Fixes the issue that the VBA was lost after saving Docm. |
| Bug | SPIREDOC-10389 | Fixes the issue that the application threw the exception "Wrong Word version" when loading Word documents encrypted using the WPS tool. |
| Bug | SPIREDOC-10425 | Fixes the issue that the application threw the exception 'System. ArgumentNullException' when converting Word to PDF. |
| Bug | SPIREDOC-10456 | Fixes the issue that the borderless text boxes added using the WPS tool were not successfully parsed. |
| Bug | SPIREDOC-10554 | Fixes the issue that the images didn't display when adding HTML that contains the image paths starting with https. |
| Bug | SPIREDOC-10587 | Fixes the issue that the application threw the exception "Unknown boolean value" when converting Word to PDF. |
Python: Delete Annotations from PDF Documents
Managing PDF documents often involves removing annotations. Whether you're preparing documents for a presentation, sharing the final files with clients when questions are settled down, or archiving important records, deleting annotations can be essential.
Spire.PDF for Python allows users to delete annotations from PDFs in Python efficiently. Follow the instructions below to clean up your PDF files seamlessly.
- Delete Specified Annotations
- Delete All Annotations from a Page
- Delete All Annotations from the PDF Document
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install it, please refer to this tutorial: How to Install Spire.PDF for Python on Windows.
Delete Specified Annotations from PDF in Python
To delete a specified annotation from PDF documents, you need to target the annotation to be removed at first. Then you can remove it by calling the Page.AnnotationsWidget.RemoveAt() method offered by Spire.PDF for Python. This section will guide you through the whole process step by step.
Steps to remove an annotation from a page:
- Create a new Document object.
- Load a PDF document from files using Document.LoadFromFile() method.
- Get the specific page of the PDF with Document.Pages.get_Item() method.
- Delete the annotation from the page by calling Page.AnnotationsWidget.RemoveAt() method.
- Save the resulting document using Document.SaveToFile() method.
Here's the code example for you to refer to:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
doc = PdfDocument()
# Open the PDF document to be modified from the disk
doc.LoadFromFile("sample1.pdf")
# Get the first page of the document
page = doc.Pages.get_Item(0)
# Remove the 2nd annotation from the page
page.AnnotationsWidget.RemoveAt(1)
# Save the PDF document
doc.SaveToFile("output/delete_2nd_annotation.pdf", FileFormat.PDF)
doc.Close()
Delete All Annotations from a PDF Page in Python
The Pages.AnnotationsWidget.Clear() method provided by Spire.PDF for Python helps you to complete the task of removing each annotation from a page. This part will demonstrate how to delete all annotations from a page in Python with a detailed guide and a code example.
Steps to delete all annotations from a page:
- Create an instance of the Document class.
- Read the PDF document from the disk by Document.LoadFromFile() method.
- Remove annotations on the page using Pages.AnnotationsWidget.Clear() method.
- Write the document to disk with Document.SaveToFile() method.
Below is the code example of deleting annotations from the first page:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
document = PdfDocument()
# Load the file from the disk
document.LoadFromFile("sample1.pdf")
# Remove all annotations from the first page
document.Pages[0].AnnotationsWidget.Clear()
# Save the document
document.SaveToFile("output/delete_annotations_page.pdf", FileFormat.PDF)
document.Close()
Delete All Annotations of PDF Documents in Python
Removing all annotations from a PDF document involves retrieving the annotations first, which means you need to loop through each page to ensure that every annotation is deleted. The section will introduce how to accomplish the task in Python, providing detailed steps and an example to assist in cleaning up PDF documents.
Steps to remove all annotations of the whole PDF document:
- Instantiate a Document object.
- Open the document from files using Document.LoadFromFile() method.
- Loop through pages of the PDF document.
- Get each page of the PDF document with Document.Pages.get_Item() method.
- Remove all annotations from each page using Page.AnnotationsWidget.Clear() method.
- Save the document to your local file with Document.SaveToFile() method.
Here is the example for reference:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of PDF class
document = PdfDocument()
# Load the file to be operated from the disk
document.LoadFromFile("sample1.pdf")
# Loop through all pages in the PDF document
for i in range(document.Pages.Count):
# Get a specific page
page = document.Pages.get_Item(i)
# Remove all annotations from the page
page.AnnotationsWidget.Clear()
# Save the resulting document
document.SaveToFile("output/delete_all_annotations.pdf", FileFormat.PDF)
document.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Set Page Setup Options in Excel
Page setup in Excel refers to the various settings that control how an Excel worksheet will be printed or displayed in a print preview. These settings determine the appearance and layout of the printed document, ensuring that it meets the desired formatting and readability standards. Page setup options include page margins, orientation, paper size, print area, headers, footers, scaling, and other print-related settings. In this article, we will explain how to set page setup options in Excel in Python using Spire.XLS for Python.
- Set Page Margins in Excel in Python
- Set Page Orientation in Excel in Python
- Set Paper Size in Excel in Python
- Set Print Area in Excel in Python
- Set Scaling Factor in Excel in Python
- Set FitToPages Options in Excel in Python
- Set Headers and Footers in Excel in Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Set Page Margins in Excel in Python
In Spire.XLS for Python, the PageSetup class is used to configure page setup options for Excel worksheets. You can access the PageSetup object of a worksheet through the Worksheet.PageSetup property. Then, you can use properties like PageSetup.TopMargin, PageSetup.BottomMargin, PageSetup.LeftMargin, PageSetup.RightMargin, PageSetup.HeaderMarginInch, and PageSetup.FooterMarginInch to set the respective margins for the worksheet. The detailed steps are as follows:
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the top, bottom, left, right, header, and footer margins using PageSetup.TopMargin, PageSetup.BottomMargin, PageSetup.LeftMargin, PageSetup.RightMargin, PageSetup.HeaderMarginInch, and PageSetup.FooterMarginInch properties.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the PageSetup object of the worksheet
pageSetup = sheet.PageSetup
# Set top, bottom, left, and right page margins for the worksheet
# The measure of the unit is Inch (1 inch = 2.54 cm)
pageSetup.TopMargin = 1
pageSetup.BottomMargin = 1
pageSetup.LeftMargin = 1
pageSetup.RightMargin = 1
pageSetup.HeaderMarginInch= 1
pageSetup.FooterMarginInch= 1
# Save the modified workbook to a new file
workbook.SaveToFile("SetPageMargins.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Set Page Orientation in Excel in Python
To set the page orientation for an Excel worksheet, you can use the PageSetup.Orientation property. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the page orientation using PageSetup.Orientation property.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the PageSetup object of the worksheet
pageSetup = sheet.PageSetup
# Set the page orientation for printing the worksheet to landscape mode
pageSetup.Orientation = PageOrientationType.Landscape
# Save the modified workbook to a new file
workbook.SaveToFile("SetPageOrientation.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Set Paper Size in Excel in Python
You can set a wide range of paper sizes, such as A3, A4, A5, B4, B5, Letter, Legal, and Tabloid for printing an Excel worksheet using the PageSetup.PaperSize property. The detailed steps are as follows:
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the paper size using PageSetup.PaperSize property.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the PageSetup object of the worksheet
pageSetup = sheet.PageSetup
# Set the paper size to A4
pageSetup.PaperSize = PaperSizeType.PaperA4
# Save the modified workbook to a new file
workbook.SaveToFile("SetPaperSize.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Set Print Area in Excel in Python
The print area of an Excel worksheet can be customized using the PageSetup.PringArea property. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the print area using PageSetup.PringArea property.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the PageSetup object of the worksheet
pageSetup = sheet.PageSetup
# Set the print area of the worksheet to "A1:E5"
pageSetup.PrintArea = "A1:E5"
# Save the modified workbook to a new file
workbook.SaveToFile("SetPrintArea.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
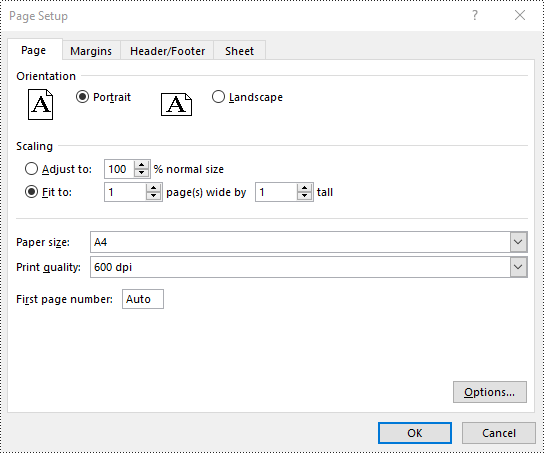
Set Scaling Factor in Excel in Python
You can scale the content of a worksheet to a specific percentage of its original size with the PageSetup.Zoom property. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Set the scaling factor using PageSetup.Zoom property.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the PageSetup object of the worksheet
pageSetup = sheet.PageSetup
# Set the scaling factor of the worksheet to 90%
pageSetup.Zoom = 90
# Save the modified workbook to a new file
workbook.SaveToFile("SetScalingFactor.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
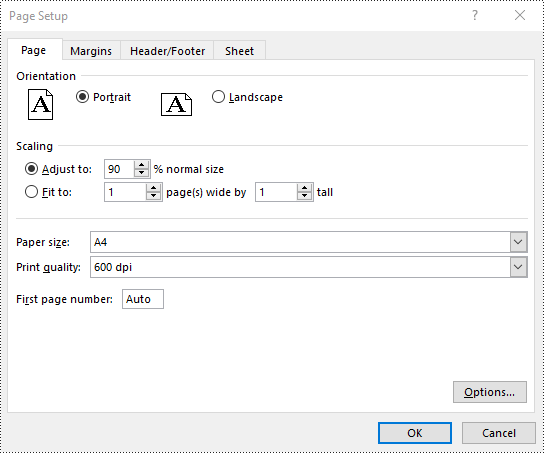
Set FitToPages Options in Excel in Python
In addition to scaling the content of a worksheet to a specific percentage of its original size, you can also fit the content of a worksheet to a specific number of pages using PageSetup.FitToPagesTall and PageSetup.FitToPagesWide properties. The detailed steps are as follows.
- Create an object of the Workbook class.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet using Workbook.Worksheets[index] property.
- Access the PageSetup object of the worksheet using Worksheet.PageSetup property.
- Fit the content of the worksheet to one page using PageSetup.FitToPagesTall and PageSetup.FitToPagesWide properties.
- Save the modified workbook to a new file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Sample.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the PageSetup object of the worksheet
pageSetup = sheet.PageSetup
# Fit the content of the worksheet within one page vertically (i.e., all rows will fit on a single page)
pageSetup.FitToPagesTall = 1
# Fit the content of the worksheet within one page horizontally (i.e., all columns will fit on a single page)
pageSetup.FitToPagesWide = 1
# Save the modified workbook to a new file
workbook.SaveToFile("FitToPages.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Set Headers and Footers in Excel in Python
For setting headers and footers in Excel, please check this article: Python: Add Headers and Footers to Excel.
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
C#: Merge or Split Tables in Word
Tables in Word documents allow users to organize data in a clear and structured manner. However, as documents grow in complexity, the need to adjust table structures often arises. Whether you need to combine multiple tables for a comprehensive view or divide a large table for better readability, mastering the art of merging and splitting tables in Word can significantly improve the presentation of your data. In this article, you will learn how to merge or split tables in Word in C# using Spire.Doc for .NET.
Install Spire.Doc for .NET
To begin with, you need to add the DLL files included in the Spire.Doc for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Doc
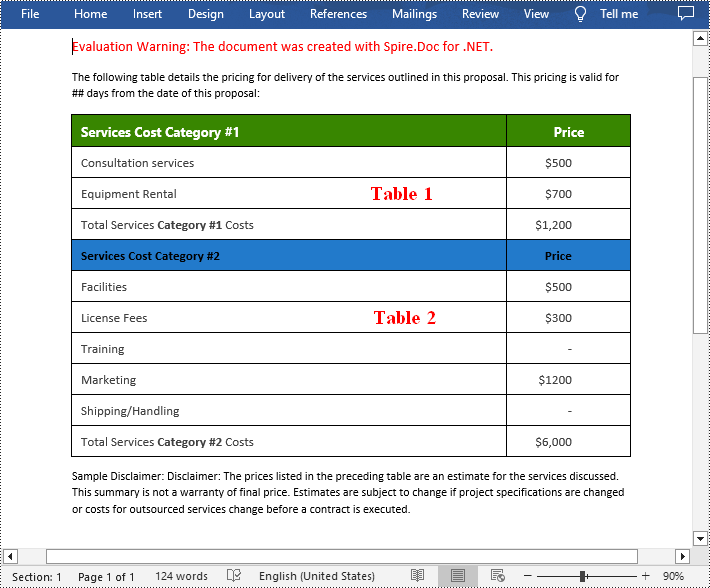
Merge Tables in Word in C#
With Spire.Doc for .NET, you can combine two or more tables into one by copying all rows from other tables to the target table and then deleting the other tables. The following are the detailed steps.
- Create a Document instance.
- Load a Word document using Document.LoadFromFile() method.
- Get a specified section using Document.Sections[] property.
- Get two tables in the section using section.Tables[] property.
- Iterate through all rows in the second table and copy them using Table.Rows[].Clone() method.
- Add the rows of the second table to the first table using Table.Rows.Add() method.
- Save the result document using Document.SaveToFile() method.
- C#
using Spire.Doc;
namespace CombineTables
{
class Program
{
static void Main(string[] args)
{
//Create a Document instance
Document doc = new Document();
//Load a Word document
doc.LoadFromFile("Cost.docx");
//Get the first section
Section section = doc.Sections[0];
//Get the first and second table in the section
Table table1 = section.Tables[0] as Table;
Table table2 = section.Tables[1] as Table;
//Add the rows of table2 to table1
for (int i = 0; i < table2.Rows.Count; i++)
{
table1.Rows.Add(table2.Rows[i].Clone());
}
//Remove the table2
section.Tables.Remove(table2);
//Save the result document
doc.SaveToFile("CombineTables.docx", FileFormat.Docx);
}
}
}
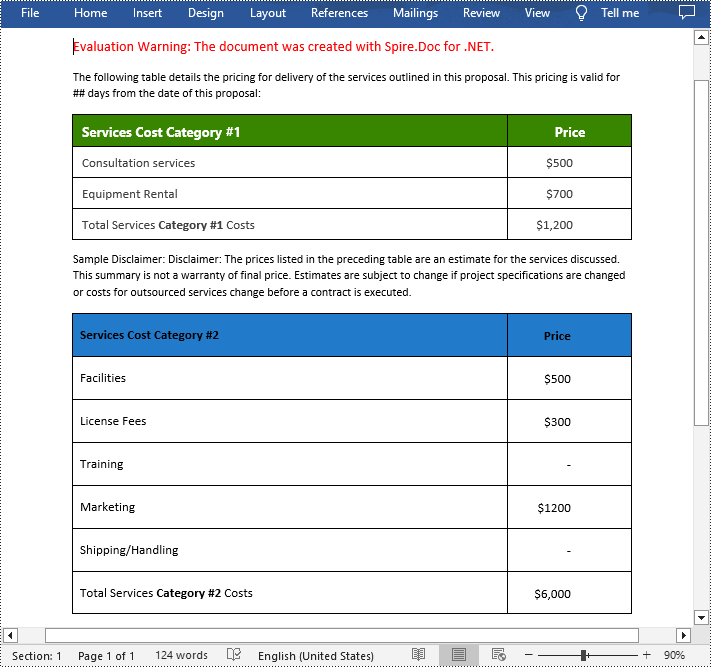
Split Tables in Word in C#
To split a table into two or more tables, you need to create a new table, then copy the specified rows from the original table to the new table, and then delete those rows from the original table. The following are the detailed steps.
- Create a Document instance.
- Load a Word document using Document.LoadFromFile() method.
- Get a specified section using Document.Sections[] property.
- Get a specified table in the section using section.Tables[] property.
- Specify the row index where the table will be split.
- Create a new instance of the Table class.
- Iterate through the specified rows in the original table and copy them using Table.Rows[].Clone() method.
- Add the specified rows to the new table using Table.Rows.Add() method.
- Iterate through the copied rows and remove each row from the original table using Table.Rows.RemoveAt() method.
- Add the new table to the section using Section.Tables.Add() method.
- Save the result document using Document.SaveToFile() method.
- C#
using Spire.Doc;
namespace SplitWordTable
{
class Program
{
static void Main(string[] args)
{
//Create a Document instance
Document doc = new Document();
//Load a Word document
doc.LoadFromFile("CombineTables.docx");
//Get the first section
Section section = doc.Sections[0];
//Get the first table in the section
Table table = section.Tables[0] as Table;
//Specify to split the table from the fifth row
int splitIndex = 4;
//Create a new table
Table newTable = new Table(section.Document);
//Adds rows (from the 5th to the last row) to the new table
for (int i = splitIndex; i < table.Rows.Count; i++)
{
newTable.Rows.Add(table.Rows[i].Clone());
}
//Delete rows from the original table
for (int i = table.Rows.Count - 1; i >= splitIndex; i--)
{
table.Rows.RemoveAt(i);
}
//Add the new table to the section
section.Tables.Add(newTable);
//Save the result document
doc.SaveToFile("SplitTable.docx", FileFormat.Docx);
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Office for Java 9.7.0 is released
We're pleased to announce the release of Spire.Office for Java 9.7.0. This version contains many new features, such as Spire.Doc for Java supports embedding CSS and images when converting Word documents to HTML files in HTML Fixed format; Spire.Presentation for Java supports adding comments to specified text in PowerPoint; Spire.Barcode for Java supports obtaining barcode information, including barcode type, data value and vertex position information. In addition, many known issues have also been successfully fixed in this version. More details are listed below.
Here is a list of changes made in this release
Spire.Doc for Java
| Category | ID | Description |
| New feature | SPIREDOC-10687 | Supports embedding CSS and images when converting Word documents to HTML files in HTML Fixed format.
String inputFile = "1.docx"; String outputFile ="1.html"; Document doc = new Document(); doc.loadFromFile(inputFile); doc.getHtmlExportOptions().setCssStyleSheetType(CssStyleSheetType.Internal); doc.getHtmlExportOptions().setImageEmbedded(true); doc.saveToFile(outputFile, FileFormat.HtmlFixed); doc.dispose(); |
| Bug | SPIREDOC-9829 SPIREDOC-10609 |
Fixes the issue that the orientation of added images was incorrect. |
| Bug | SPIREDOC-10006 SPIREDOC-10636 SPIREDOC-10692 |
Fixes the issue that the size of OFD documents converted from Docx documents becomes bigger. |
| Bug | SPIREDOC-10327 | Fixes the issue that watermarks in HTML documents converted from Docx documents were lost. |
| Bug | SPIREDOC-10379 SPIREDOC-10509 SPIREDOC-10531 SPIREDOC-10650 |
Fixes an issue that content was lost after converting a Docx document to a PDF document. |
| Bug | SPIREDOC-10591 | Fixes an issue that the editing area was lost after converting an XML document to a Doc document. |
| Bug | SPIREDOC-10615 | Fixes the issue that the program threw an exception when converting Word to PDF under multi-threading. |
| Bug | SPIREDOC-10623 | Fixes the issue that page numbers were formatted incorrectly after converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10627 | Fixes the issue that the program threw "The authentication or decryption has failed." error when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10634 SPIREDOC-10701 |
Fixes the issue that the program threw an exception when converting Word to OFD under multi-threading. |
| Bug | SPIREDOC-10670 | Fixes the issue that the text orientation changed after converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10685 SPIREDOC-10697 |
Fixes the issue that the page numbers of requests after the second time were lost after adding a table of contents in a Web project. |
| Bug | SPIREDOC-10713 | Fixes the issue that font embedding failed when converting Docx documents to PDF documents. |
Spire.PDF for Java
| Category | ID | Description |
| Bug | SPIREPDF-6804 | Fixes the error occurred when opening compressed PDF files. |
| Bug | SPIREPDF-6831 | Fixed the issue that the effect of the PdfInkAnnotation added to PDF was incorrect. |
| Bug | SPIREPDF-6856 | Fixes the issue that the program threw "NullPointerException" when obtaining the PDF JavaScript. |
| Bug | SPIREPDF-6865 | Fixes the issue that the program threw "java.lang.NoClassDefFoundError" when compressing images with the "ImageQuality.Medium" setting. |
| Bug | SPIREPDF-6870 | Fixed the issue that the size of PDF documents was not reduced after splitting. |
| Bug | SPIREPDF-6879 | Fixes the issue of creating a PdfActionAnnotation but retrieving its type as PdfTextWebLinkAnnotationWidget. |
| Bug | SPIREPDF-6886 | Fixes the issue that the program threw "NullPointerException" when replacing text in PDF. |
Spire.Presentation for Java
| Category | ID | Description |
| New feature | SPIREPPT-2559 | Supports adding comments to specified text in PowerPoint.
Presentation ppt = new Presentation();
ISlide slide = ppt.getSlides().get(0);
IAutoShape shape = ppt.getSlides().get(0).getShapes().appendShape(ShapeType.RECTANGLE, new Rectangle2D.Double(100, 250, 350, 200));
ppt.getSlides().get(0).getShapes().get(0).getLine().getFillFormat().getSolidFillColor().setColor(Color.white);
shape.getFill().setFillType(FillFormatType.SOLID);
shape.getFill().getSolidColor().setColor(Color.GRAY);
ParagraphEx paragraphEx = shape.getTextFrame().getTextRange().getParagraph();
PortionEx ex = new PortionEx("TextTextmdTextText\ttmdTextTextmdText\ttmdTextTextmdtEXT\ttTextmd");
paragraphEx.getTextRanges().append(ex);
ICommentAuthor commentAuthor = ppt.getCommentAuthors().addAuthor("test","12");
paragraphEx.addComment(commentAuthor,slide,shape,ex,"123");
String result = "result.pptx";
ppt.saveToFile(result, FileFormat.PPTX_2013);
Presentation ppt = new Presentation();
ppt.loadFromFile(inputFile);
ISlide slide = ppt.getSlides().get(0);
IAutoShape shape = (IAutoShape) slide.getShapes().get(0);
ParagraphEx paragraphEx = shape.getTextFrame().getTextRange().getParagraph();
PortionEx portionEx = paragraphEx.getTextRanges().get(0);
ICommentAuthor commentAuthor = ppt.getCommentAuthors().addAuthor("test","18");
paragraphEx.addComment(commentAuthor,slide,shape,portionEx,"123456789");
String result = "result.pptx";
ppt.saveToFile(result, FileFormat.PPTX_2013);
|
| Bug | SPIREPPT-2550 | Fixes the issue that the shape height was incorrect after adding content to the shape. |
| Bug | SPIREPPT-2560 | Fixes the issue that the effect of modifying the shape position was incorrect. |
| Bug | SPIREPPT-2561 | Fixes the issue that the greater-than and less-than symbols in Latex formulas were parsed incorrectly. |
Spire.Barcode for Java
| Category | ID | Description |
| New feature | SPIREBARCODE-258 | The BarcodeScanner class supports obtaining barcode information, including barcode type, data value and vertex position information.
BarcodeInfo[] infos = BarcodeScanner.scanInfo("barcode.png");
Point[] loaction = infos[0].getVertexes();
BarCodeReadType barCodeReadType = infos[0].getReadType();
String dataString = infos[0].getDataString();
|
| New feature | - | The BarcodeScanner class supports scanning Aztec type.
String[] s = BarcodeScanner.scan("AZTEC.png",BarCodeType.Aztec);
|
| New feature | - | The BarcodeScanner class supports scanning with more overload settings.
Public static String[] scan(BufferedImage bitmap, java.awt.Rectangle rect, BarCodeType barcodeType, boolean IncludeCheckSum) Public static String[] scan(String fileName, BarCodeType barcodeType, boolean IncludeCheckSum) Public static String scanOne(String fileName, BarCodeType barcodeType, boolean IncludeCheckSum) Public static String scanOne(InputStream stream, BarCodeType barcodeType, boolean IncludeCheckSum) |
| New feature | - | Adds external use enumerations.
com.spire.barcode.publics.drawing.FontStyle com.spire.barcode.publics.drawing.GraphicsUnit com.spire.barcode.publics.drawing.StringAlignment |
| New feature | - | Adjustments to the IBarCodeSettings interface.
Recycled: public java.awt.Font getTopTextFont() public java.awt.Font getBottomTextFont() public java.awt.Font getTextFont() Modified: public void setBottomTextFont(java.awt.Font value)->public void setBottomTextFont(String familyName, float fontSize) public void setTopTextFont(java.awt.Font value)->public void setTopTextFont(String familyName, float fontSize) public boolean showBottomText->public boolean isShowBottomText() public void setShowBottomText(boolean value) -> public void isShowBottomText(boolean value) public com.spire.barcode.GraphicsUnit getUnit() -> public com.spire.barcode.publics.drawing.GraphicsUnit getUnit() public void setUnit(com.spire.barcode.GraphicsUnit value) -> public void setUnit(com.spire.barcode.publics.drawing.GraphicsUnit value) public void setTextFont(java.awt.Font value) -> public void setTextFont(String familyName, float fontSize) public float getLeftMargin() ->The default value adjusted from 5 to 4. Newly Added: public float getTopTextMargin() public void setTopTextMargin(float value) public int getAztecErrorCorrection() public void setAztecErrorCorrection(int value) public int getAztecLayers() public void setAztecLayers(int value) public DataMatrixSymbolShape getDataMatrixSymbolShape() public void setDataMatrixSymbolShape(DataMatrixSymbolShape value) public ITF14BorderType getITF14BearerBars() public void setITF14BearerBars(ITF14BorderType value) public void setTextFont(String familyName, float fontSize, com.spire.barcode.publics.drawing.FontStyle style) public boolean isShowStartCharAndStopChar() public void isShowStartCharAndStopChar(boolean value) |
| New feature | - | Adjustments to the BarcodeSettings class interfaces.
Recycled: public java.awt.Font getTextFont() public java.awt.Font getTopTextFont() public java.awt.Font getBottomTextFont() Modified: public void setTextFont(java.awt.Font value) -> public void setTextFont(String familyName, float sizePoints) public com.spire.barcode.GraphicsUnit getUnit() -> public com.spire.barcode.publics.drawing.GraphicsUnit getUnit() public void setUnit(com.spire.barcode.GraphicsUnit value) -> public void setUnit(com.spire.barcode.publics.drawing.GraphicsUnit value) public com.spire.barcode.StringAlignment getTextAlignment() -> public com.spire.barcode.publics.drawing.StringAlignment getTextAlignment() public void setTextAlignment(com.spire.barcode.StringAlignment value) -> public void setTextAlignment(com.spire.barcode.publics.drawing.StringAlignment value) public com.spire.barcode.StringAlignment getTopTextAligment() -> public com.spire.barcode.publics.drawing.StringAlignment getTopTextAligment() public void setTopTextAligment(com.spire.barcode.StringAlignment value) -> public void setTopTextAligment(com.spire.barcode.publics.drawing.StringAlignment value) public void setBottomTextFont(java.awt.Font value) -> public void setBottomTextFont(String familyName, float fontSize) public void setTopTextFont(java.awt.Font value) -> public void setTopTextFont(String familyName, float fontSize) public boolean showBottomText->public boolean isShowBottomText() public void setShowBottomText(boolean value) -> public void isShowBottomText(boolean value) public com.spire.barcode.StringAlignment getBottomTextAlignment() -> public com.spire.barcode.publics.drawing.StringAlignment getBottomTextAlignment() public void setBottomTextAlignment(com.spire.barcode.StringAlignment value) -> public void setBottomTextAlignment(com.spire.barcode.publics.drawing.StringAlignment value) public float getLeftMargin() ->The default value adjusted from 5 to 4. Newly Added: public float getTopTextMargin() public void setTopTextMargin(float value) public void setTextFont(String familyName, float sizePoints, com.spire.barcode.publics.drawing.FontStyle style) public void setTopTextFont(String familyName, float fontSize, com.spire.barcode.publics.drawing.FontStyle style) public void setITF14BearerBars(ITF14BorderType value) public boolean isShowStartCharAndStopChar() public void isShowStartCharAndStopChar(boolean value) public int getAztecLayers() public void setAztecLayers(int value) public int getAztecErrorCorrection() public void setAztecErrorCorrection(int value) public DataMatrixSymbolShape getDataMatrixSymbolShape() public void setDataMatrixSymbolShape(DataMatrixSymbolShape value) public void setBottomTextFont(String familyName, float fontSize, com.spire.barcode.publics.drawing.FontStyle style) |
Spire.OCR for Java
| Category | ID | Description |
| New feature | - | Adds the ConfigureOptions class and new method ConfigureDependencies(ConfigureOptions configureOptions), which supports configuring OCR models, languages, and dependency libraries.
import com.spire.ocr.*;
import java.awt.geom.Rectangle2D;
public class OCRTest {
public static void main(String[] args) throws Exception{
OcrScanner scanner = new OcrScanner();
ConfigureOptions configureOptions = new ConfigureOptions("D:\\LanguageModel", "English");
String dependencies = "dependencies/";
configureOptions.setLibPath(dependencies);
scanner.ConfigureDependencies(configureOptions);
String imageFile = "Sample.png";
scanner. scan(imageFile);
String scannedText=scanner.getText().toString();
StringBuilder stringBuilder=new StringBuilder();
for(IOCRTextBlock blockItem :scanner.getText().getBlocks()){
Rectangle2D rectangle2D=blockItem.getBox();
stringBuilder.append(blockItem.getText() +","+ "X"+ rectangle2D.getX()+"; Y:"+rectangle2D.getY()+ "; Width:"+ rectangle2D.getWidth()+ "; Height:"+ rectangle2D.getHeight());
}
}
}
|
Spire.Doc for Java 12.7.17 supports embedding CSS and images when converting Word to HTML files in HTML Fixed format
We are delighted to announce the release of Spire.Doc for Java 12.7.17. This version supports embedding CSS and images when converting Word documents to HTML files in HTML Fixed format. Besides, it also enhances the conversion from DOCX to OFD, HTML, and PDF. Moreover, a lot of known issues are fixed successfully in this version, such as the issue that the orientation of the added image was not correct. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREDOC-10687 | Supports embedding CSS and images when converting Word documents to HTML files in HTML Fixed format.
String inputFile = "1.docx"; String outputFile ="1.html"; Document doc = new Document(); doc.loadFromFile(inputFile); doc.getHtmlExportOptions().setCssStyleSheetType(CssStyleSheetType.Internal); doc.getHtmlExportOptions().setImageEmbedded(true); doc.saveToFile(outputFile, FileFormat.HtmlFixed); doc.dispose(); |
| Bug | SPIREDOC-9829 SPIREDOC-10609 |
Fixes the issue that the orientation of added images was incorrect. |
| Bug | SPIREDOC-10006 SPIREDOC-10636 SPIREDOC-10692 |
Fixes the issue that the size of OFD documents converted from Docx documents becomes bigger. |
| Bug | SPIREDOC-10327 | Fixes the issue that watermarks in HTML documents converted from Docx documents were lost. |
| Bug | SPIREDOC-10379 SPIREDOC-10509 SPIREDOC-10531 SPIREDOC-10650 |
Fixes an issue that content was lost after converting a Docx document to a PDF document. |
| Bug | SPIREDOC-10591 | Fixes an issue that the editing area was lost after converting an XML document to a Doc document. |
| Bug | SPIREDOC-10615 | Fixes the issue that the program threw an exception when converting Word to PDF under multi-threading. |
| Bug | SPIREDOC-10623 | Fixes the issue that page numbers were formatted incorrectly after converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10627 | Fixes the issue that the program threw "The authentication or decryption has failed." error when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10634 SPIREDOC-10701 |
Fixes the issue that the program threw an exception when converting Word to OFD under multi-threading. |
| Bug | SPIREDOC-10670 | Fixes the issue that the text orientation changed after converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10685 SPIREDOC-10697 |
Fixes the issue that the page numbers of requests after the second time were lost after adding a table of contents in a Web project. |
| Bug | SPIREDOC-10713 | Fixes the issue that font embedding failed when converting Docx documents to PDF documents. |
Spire.Presentation for Java 9.7.6 supports adding comments to specified text in PowerPoint
We are pleased to announce the release of Spire.Presentation for Java 9.7.6. This version supports adding comments to specified text in PowerPoint, and also fixes some known issues, such as the incorrect shape height after adding content to the shape. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPPT-2559 | Supports adding comments to specified text in PowerPoint.
Presentation ppt = new Presentation();
ISlide slide = ppt.getSlides().get(0);
IAutoShape shape = ppt.getSlides().get(0).getShapes().appendShape(ShapeType.RECTANGLE, new Rectangle2D.Double(100, 250, 350, 200));
ppt.getSlides().get(0).getShapes().get(0).getLine().getFillFormat().getSolidFillColor().setColor(Color.white);
shape.getFill().setFillType(FillFormatType.SOLID);
shape.getFill().getSolidColor().setColor(Color.GRAY);
ParagraphEx paragraphEx = shape.getTextFrame().getTextRange().getParagraph();
PortionEx ex = new PortionEx("TextTextmdTextText\ttmdTextTextmdText\ttmdTextTextmdtEXT\ttTextmd");
paragraphEx.getTextRanges().append(ex);
ICommentAuthor commentAuthor = ppt.getCommentAuthors().addAuthor("test","12");
paragraphEx.addComment(commentAuthor,slide,shape,ex,"123");
String result = "result.pptx";
ppt.saveToFile(result, FileFormat.PPTX_2013);
Presentation ppt = new Presentation();
ppt.loadFromFile(inputFile);
ISlide slide = ppt.getSlides().get(0);
IAutoShape shape = (IAutoShape) slide.getShapes().get(0);
ParagraphEx paragraphEx = shape.getTextFrame().getTextRange().getParagraph();
PortionEx portionEx = paragraphEx.getTextRanges().get(0);
ICommentAuthor commentAuthor = ppt.getCommentAuthors().addAuthor("test","18");
paragraphEx.addComment(commentAuthor,slide,shape,portionEx,"123456789");
String result = "result.pptx";
ppt.saveToFile(result, FileFormat.PPTX_2013);
|
| Bug | SPIREPPT-2550 | Fixes the issue that the shape height was incorrect after adding content to the shape. |
| Bug | SPIREPPT-2560 | Fixes the issue that the effect of modifying the shape position was incorrect. |
| Bug | SPIREPPT-2561 | Fixes the issue that the greater-than and less-than symbols in Latex formulas were parsed incorrectly. |
Python: Remove Images from Slides and Slide Masters in PowerPoint
Removing images from slides and slide masters can be essential for many reasons, such as decluttering slides, maintaining uniformity, preparing templates, or modifying a template. Using Python, you can easily handle this task in seconds.
This guide will demonstrate removing images from slides and slide masters in PowerPoint documents in Python with Spire.Presentation for Python. Check this page and make a clean presentation.
- Remove Images from Slides
- Remove Images from Slide Masters
- Remove Specified Images from Slides
- Remove Specified Images from Slide Masters
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install it, please refer to this tutorial: How to Install Spire. Presentation for Python on Windows.
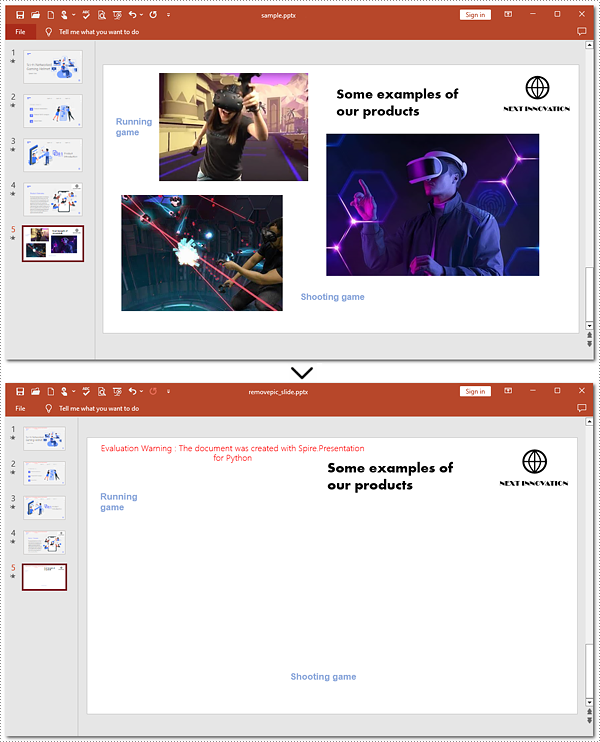
Remove Images from Slides of PowerPoint in Python
Removing images from PowerPoint slides can be efficiently managed using Python. The Presentation.Shapes.RemoveAt() method published by Spire. Presentation for Python allows users to delete pictures from a PowerPoint presentation without effort. The following instructions will guide you through the whole process.
Steps to remove images from a slide:
- Create an object for the Presentation class.
- Load the target PowerPoint document to be operated with the Presentation.LoadFromFile() method.
- Get the slide that you want to modify using the Presentation.Slides[] property.
- Loop through shapes on the slide.
- Determine if these shapes are images.
- Remove images from the slide using the Presentation.Shapes.RemoveAt() method.
- Save the resulting PowerPoint document with the Presentation.SaveToFile() method.
Here's the code example for reference:
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
ppt = Presentation()
# Load the PowerPoint document to be modified from the disk
ppt.LoadFromFile("sample.pptx")
# Get the fifth slide
slide = ppt.Slides[4]
# Loop through shapes on the slide
for i in range(slide.Shapes.Count - 1, -1, -1):
# Check if those shapes are images
if isinstance(slide.Shapes[i], SlidePicture):
# Remove pictures on the fifth slide
slide.Shapes.RemoveAt(i)
# Save to file
ppt.SaveToFile("removepic_slide.pptx", FileFormat.Pptx2013)
# Release the resources
ppt.Dispose()
Remove Images from Slide Masters of PowerPoint Using Python
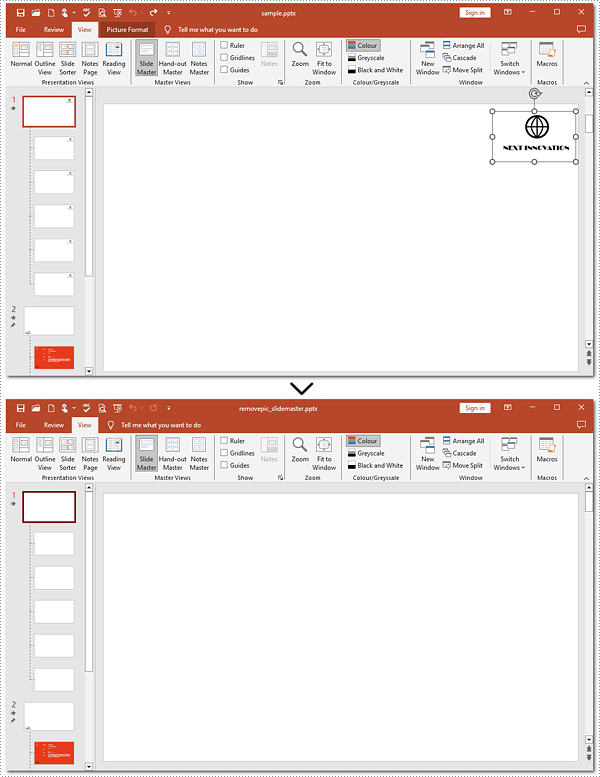
Removing images from slide masters is basically the same as doing that from a slide. To apply this action, you can use Presentation.Shapes.RemoveAt() method provided by Spire.Presentation for Python. Check out the steps below and make a nice and clean presentation.
Steps to remove images from Slide Masters:
- Instantiate a Presentation object.
- Read the PowerPoint document from disk using the Presentation.LoadFromFile() method.
- Get the second Slide Master with the Presentation.Masters[] property.
- Iterate through images on the second Slide Master.
- Confirm whether these shapes are images.
- Remove images from the second Slide Master using the Shapes.RemoveAt() method.
- Save the modified document with the Presentation.SaveToFile() method.
Here's the code example:
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of the Presentation class
pre = Presentation()
# Open the sample PowerPoint document from the disk
pre.LoadFromFile("sample.pptx")
# Retrieve the first Slide Master
master = pre.Masters[0]
# Loop through shapes on the slide master
for i in range(master.Shapes.Count - 1, -1, -1):
# Check whether these shapes are images
if isinstance(master.Shapes[i], SlidePicture):
# Remove images on the first slide master
master.Shapes.RemoveAt(i)
# Save the generated file
pre.SaveToFile("removepic_slidemaster.pptx", FileFormat.Pptx2013)
# Release the resources
pre.Dispose()
Delete Specified Images from Slides with Python
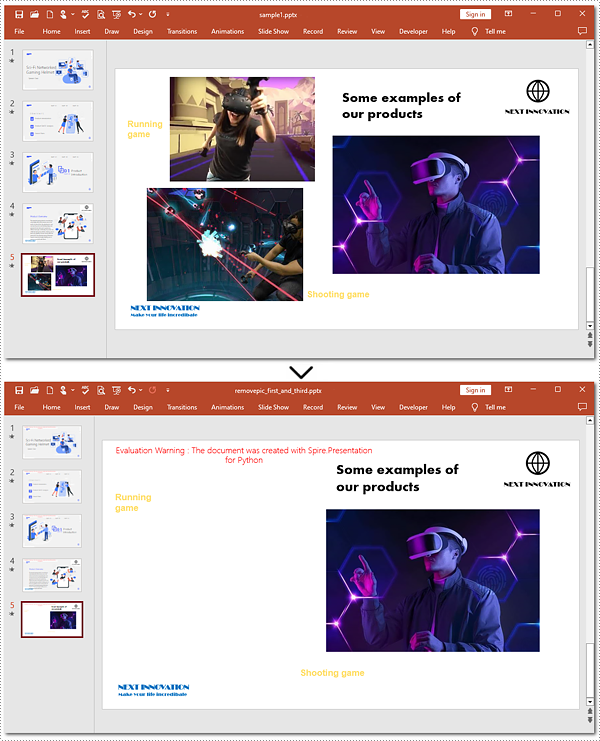
When working with PowerPoint presentations, you may need to remove specific images from your slides to refine your content. The guide below will walk you through targeting and removing specified images from a slide.
Steps to delete specified images:
- Instantiate an object of the Presentation class.
- Load the target file from the disk with the Presentation.LoadFromFile() method.
- Create a list to store image indexes.
- Get the 5th slide using the Presentation.Slides[] property.
- Loop through shapes on the slide.
- Verify whether these shapes are images.
- Find the 1st and 3rd pictures.
- Delete these two pictures by the Shapes.RemoveAt() method.
- Save the generated presentation using the Presentation.SaveToFile() method.
Below is the code example to refer to:
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
ppt = Presentation()
# Load the PowerPoint document from the disk
ppt.LoadFromFile("sample1.pptx")
# Create a list to keep track of image indexes to delete
indexes = []
# Get the fifth slide
slide = ppt.Slides[4]
# Iterate through shapes on the slide
image_index = 0
for i in range(slide.Shapes.Count - 1, -1, -1):
# Check if shapes are pictures
if isinstance(slide.Shapes[i], SlidePicture):
image_index += 1
# Record indexes of the first and third images
if image_index in (1, 3):
indexes.append(i)
# Remove the first and third images
for index in indexes:
slide.Shapes.RemoveAt(index)
# Save to file
ppt.SaveToFile("removepic_first_and_third.pptx", FileFormat.Pptx2013)
# Release the resources
ppt.Dispose()
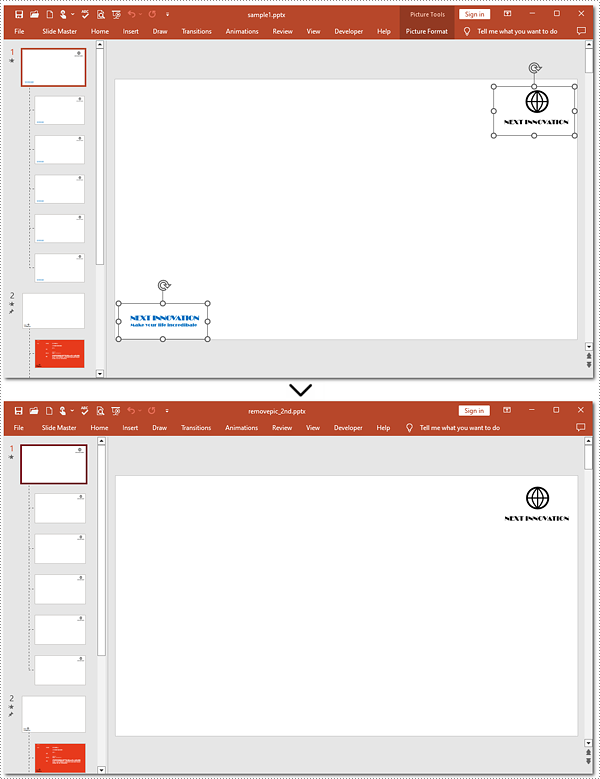
Delete Specified Images from Slide Masters in Python
Shapes.RemoveAt() method also supports removing a specified image from a slide master. To complete the task, you need to target the picture to be deleted. Refer to the detailed steps and a code example to finish the process.
Steps to remove a specified picture from a slide master:
- Create a new object for the Presentation class.
- Read the document from the disk using the Presentation.LoadFromFlie() method.
- Retrieve the 1st slide master by the Presentation.Masters[] property.
- Iterate through shapes on the slide master.
- Check if these shapes are images.
- Remove the 2nd picture with the Shapes.RemoveAt() method.
- Save the resulting presentation to the disk using the Presentation.SaveToFile() method.
Here is the code example:
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create an instance of the Presentation class
pre = Presentation()
# Open the sample PowerPoint document from the disk
pre.LoadFromFile("sample1.pptx")
# Retrieve the first Slide Master
master = pre.Masters[0]
# Loop through the shapes in reverse order
for i in range(master.Shapes.Count - 1, -1, -1):
# Check whether shapes are images
if isinstance(master.Shapes[i], SlidePicture):
# Remove the second image from the slide master
if i == 1:
master.Shapes.RemoveAt(i)
break
# Save the generated file
pre.SaveToFile("removepic_2nd.pptx", FileFormat.Pptx2013)
# Release the resources
pre.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.