
Annotation (3)
Adding annotations to PDFs is a common practice for adding comments, highlighting text, drawing shapes, and more. This feature is beneficial for collaborative document review, education, and professional presentations. It allows users to mark up documents digitally, enhancing communication and productivity.
In this article, you will learn how to add various types of annotations to a PDF document in Python using Spire.PDF for Python.
- Add a Text Markup Annotation to PDF
- Add a Free Text Annotation to PDF
- Add a Popup Annotation to PDF
- Add a Stamp Annotation to PDF
- Add a Shape Annotation to PDF
- Add a Web Link Annotation to PDF
- Add a File Link Annotation to PDF
- Add a Document Link Annotation to PDF
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add a Text Markup Annotation to PDF in Python
Text markup in PDF refers to the ability to emphasize important text by selecting and highlighting it. To add a text markup annotation to a PDF, you first need to locate the specific text within the document with the help of the PdfTextFinder class. Once the text is identified, you can create a PdfTextMarkupAnnotation object and apply it to the document.
The following are the steps to add a text markup annotation to PDF using Python:
- Create a PdfDocument object.
- Load a PDF file from the specified location.
- Get a page from the document.
- Find a specific piece of text within the page using PdfTextFinder class.
- Create a PdfTextMarkupAnnotation object based on the text found.
- Add the annotation to the page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the modified document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object based on the page
finder = PdfTextFinder(page)
# Set the find options
finder.Options.Parameter = TextFindParameter.WholeWord
finder.Options.Parameter = TextFindParameter.IgnoreCase
# Find the instances of the specified text
fragments = finder.Find("However, we cannot and do not guarantee that these measures will prevent "+
"every unauthorized attempt to access, use, or disclose your information since "+
"despite our efforts, no Internet and/or other electronic transmissions can be completely secure.");
# Get the first instance
textFragment = fragments[0]
# Specify annotation text
text = "Here is a markup annotation."
# Iterate through the text bounds
for i in range(len(textFragment.Bounds)):
# Get a specific bound
rect = textFragment.Bounds[i]
# Create a text markup annotation
annotation = PdfTextMarkupAnnotation("Administrator", text, rect)
# Set the markup color
annotation.TextMarkupColor = PdfRGBColor(Color.get_Green())
# Add the annotation to the collection of the annotations
page.AnnotationsWidget.Add(annotation)
# Save result to file
doc.SaveToFile("output/MarkupAnnotation.pdf")
# Dispose resources
doc.Dispose()

Add a Free Text Annotation to PDF in Python
Free text annotations allow adding freeform text comments directly on a PDF. To add a free text annotation at a specific location, you can use the PdfTextFinder class to obtain the coordinate information of the searched text, then create a PdfFreeTextAnnotation object based on that coordinates and add it to the document.
The following are the steps to add a free text annotation to PDF using Python:
- Create a PdfDocument object.
- Load a PDF file from the specified location.
- Get a page from the document.
- Find a specific piece of text within the page using PdfTextFinder class.
- Create a PdfFreeTextAnnotation object based on the coordinate information of the text found.
- Set the annotation content using PdfFreeTextAnnotation.Text property.
- Add the annotation to the page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the modified document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object based on the page
finder = PdfTextFinder(page)
# Set the find options
finder.Options.Parameter = TextFindParameter.WholeWord
finder.Options.Parameter = TextFindParameter.IgnoreCase
# Find the instances of the specified text
fragments = finder.Find("Children");
# Get the first instance
textFragment = fragments[0]
# Get the text bound
rect = textFragment.Bounds[0]
# Get the coordinates to add annotation
right = bound.Right
top = bound.Top
# Create a free text annotation
rectangle = RectangleF(right + 5, top + 2, 160.0, 18.0)
textAnnotation = PdfFreeTextAnnotation(rectangle)
# Set the content of the annotation
textAnnotation.Text = "Here is a free text annotation."
# Set other properties of annotation
font = PdfFont(PdfFontFamily.TimesRoman, 13.0, PdfFontStyle.Regular)
border = PdfAnnotationBorder(1.0)
textAnnotation.Font = font
textAnnotation.Border = border
textAnnotation.BorderColor = PdfRGBColor(Color.get_SkyBlue())
textAnnotation.Color = PdfRGBColor(Color.get_LightBlue())
textAnnotation.Opacity = 1.0
# Add the annotation to the collection of the annotations
page.AnnotationsWidget.Add(textAnnotation)
# Save result to file
doc.SaveToFile("output/FreeTextAnnotation.pdf")
# Dispose resources
doc.Dispose()

Add a Popup Annotation to PDF in Python
A popup annotation allows for the display of additional information or content in a pop-up window. To get a specific position to add a popup annotation, you can still use the PdfTextFinder class. Once the coordinate information is obtained, you can create a PdfPopupAnnotation object and add it to the document.
The steps to add a popup annotation to PDF using Python are as follows:
- Create a PdfDocument object.
- Load a PDF file from the specified location.
- Get a page from the document.
- Find a specific piece of text within the page using PdfTextFinder class.
- Create a PdfPopupAnnotation object based on the coordinate information of the text found.
- Set the annotation content using PdfPopupAnnotation.Text property.
- Add the annotation to the page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the modified document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object based on the page
finder = PdfTextFinder(page)
# Set the find options
finder.Options.Parameter = TextFindParameter.WholeWord
finder.Options.Parameter = TextFindParameter.IgnoreCase
# Find the instances of the specified text
fragments = finder.Find("Children");
# Get the first instance
textFragment = fragments[0]
# Get the text bound
bound = textFragment.Bounds[0]
# Get the coordinates to add annotation
right = bound.Right
top = bound.Top
# Create a free text annotation
rectangle = RectangleF(right + 5, top, 30.0, 30.0)
popupAnnotation = PdfPopupAnnotation(rectangle)
# Set the content of the annotation
popupAnnotation.Text = "Here is a popup annotation."
# Set the icon and color of the annotation
popupAnnotation.Icon = PdfPopupIcon.Comment
popupAnnotation.Color = PdfRGBColor(Color.get_Red())
# Add the annotation to the collection of the annotations
page.AnnotationsWidget.Add(popupAnnotation)
# Save result to file
doc.SaveToFile("output/PopupAnnotation.pdf")
# Dispose resources
doc.Dispose()

Add a Stamp Annotation to PDF in Python
Stamp annotations in PDF documents are a type of annotation that allow users to add custom "stamps" or symbols to a PDF file. To define the appearance of a stamp annotation, use the PdfTemplate class. Then, create a PdfRubberStampAnnotation object and apply the previously defined template as its appearance. Finally, add the annotation to the PDF document.
The steps to add a stamp annotation to PDF using Python are as follows:
- Create a PdfDocument object.
- Load a PDF file from the specified location.
- Get a page from the document.
- Create a PdfTemplate object and draw an image on the template.
- Create a PdfRubberStampAnnotation object and apply the template as its appearance.
- Add the annotation to the page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the modified document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get a specific page
page = doc.Pages[0]
# Load an image file
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\confidential.png")
# Get the width and height of the image
width = (float)(image.Width)
height = (float)(image.Height)
# Create a PdfTemplate object based on the size of the image
template = PdfTemplate(width, height, True)
# Draw image on the template
template.Graphics.DrawImage(image, 0.0, 0.0, width, height)
# Create a rubber stamp annotation, specifying its location and position
rect = RectangleF((float) (page.ActualSize.Width/2 - width/2), 90.0, width, height)
stamp = PdfRubberStampAnnotation(rect)
# Create a PdfAppearance object
pdfAppearance = PdfAppearance(stamp)
# Set the template as the normal state of the appearance
pdfAppearance.Normal = template
# Apply the appearance to the stamp
stamp.Appearance = pdfAppearance
# Add the stamp annotation to PDF
page.AnnotationsWidget.Add(stamp)
# Save the file
doc.SaveToFile("output/StampAnnotation.pdf")
# Dispose resources
doc.Dispose()

Add a Shape Annotation to PDF in Python
Shape annotations in PDF documents are a type of annotation that allow users to add various geometric shapes to the PDF file. Spire.PDF for Python offers the classes such as PdfPolyLineAnnotation, PdfLineAnnotation, and PdfPolygonAnnotation, allowing developers to add different types of shape annotations to PDF.
The steps to add a shape annotation to PDF using Python are as follows:
- Create a PdfDocument object.
- Load a PDF file from the specified location.
- Get a page from the document.
- Find a specific piece of text within the page using PdfTextFinder class.
- Create a PdfPolyLineAnnotation object based on the coordinate information of the text found.
- Set the annotation content using PdfPolyLineAnnotation.Text property.
- Add the annotation to the page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the modified document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object based on the page
finder = PdfTextFinder(page)
# Set the find options
finder.Options.Parameter = TextFindParameter.WholeWord
finder.Options.Parameter = TextFindParameter.IgnoreCase
# Find the instances of the specified text
fragments = finder.Find("Children");
# Get the first instance
textFragment = fragments[0]
# Get the text bound
bound = textFragment.Bounds[0]
# Get the coordinates to add annotation
left = bound.Left
top = bound.Top
right = bound.Right
bottom = bound.Bottom
# Create a shape annotation
polyLineAnnotation = PdfPolyLineAnnotation(page, [PointF(left, top), PointF(right, top), PointF(right - 5, bottom), PointF(left - 5, bottom), PointF(left, top)])
# Set the annotation text
polyLineAnnotation.Text = "Here is a shape annotation."
# Add the annotation to the collection of the annotations
page.AnnotationsWidget.Add(polyLineAnnotation)
# Save result to file
doc.SaveToFile("output/ShapeAnnotation.pdf")
# Dispose resources
doc.Dispose()

Add a Web Link Annotation to PDF in Python
Web link annotations in PDF documents enable users to embed clickable links to webpages, providing easy access to additional resources or related information online. You can use the PdfTextFinder class to find the specified text in a PDF document, and then create a PdfUriAnnotation object based on that text.
The following are the steps to add a web link annotation to PDF using Python:
- Create a PdfDocument object.
- Load a PDF file from the specified location.
- Get a page from the document.
- Find a specific piece of text within the page using PdfTextFinder class.
- Create a PdfUriAnnotation object based on the bound of the text.
- Add the annotation to the page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the modified document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object based on the page
finder = PdfTextFinder(page)
# Set the find options
finder.Options.Parameter = TextFindParameter.WholeWord
finder.Options.Parameter = TextFindParameter.IgnoreCase
# Find the instances of the specified text
fragments = finder.Find("Children");
# Get the first instance
textFragment = fragments[0]
# Get the text bound
bound = textFragment.Bounds[0]
# Create a Url annotation
urlAnnotation = PdfUriAnnotation(bound, "https://www.e-iceblue.com/");
# Add the annotation to the collection of the annotations
page.AnnotationsWidget.Add(urlAnnotation)
# Save result to file
doc.SaveToFile("output/WebLinkAnnotation.pdf")
# Dispose resources
doc.Dispose()

Add a File Link Annotation to PDF in Python
A file link annotation in a PDF document is a type of annotation that allows users to create a clickable link to an external file, such as another PDF, image, or document. Still, you can use the PdfTextFinder class to find the specified text in a PDF document, and then create a PdfFileLinkAnnotation object based on that text.
The following are the steps to add a file link annotation to PDF using Python:
- Create a PdfDocument object.
- Load a PDF file from the specified location.
- Get a page from the document.
- Find a specific piece of text within the page using PdfTextFinder class.
- Create a PdfFileLinkAnnotation object based on the bound of the text.
- Add the annotation to the page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the modified document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object based on the page
finder = PdfTextFinder(page)
# Set the find options
finder.Options.Parameter = TextFindParameter.WholeWord
finder.Options.Parameter = TextFindParameter.IgnoreCase
# Find the instances of the specified text
fragments = finder.Find("Children");
# Get the first instance
textFragment = fragments[0]
# Get the text bound
bound = textFragment.Bounds[0]
# Create a file link annotation
fileLinkAnnotation = PdfFileLinkAnnotation(bound, "C:\\Users\\Administrator\\Desktop\\Report.docx")
# Add the annotation to the collection of the annotations
page.AnnotationsWidget.Add(fileLinkAnnotation)
# Save result to file
doc.SaveToFile("output/FileLinkAnnotation.pdf")
# Dispose resources
doc.Dispose()
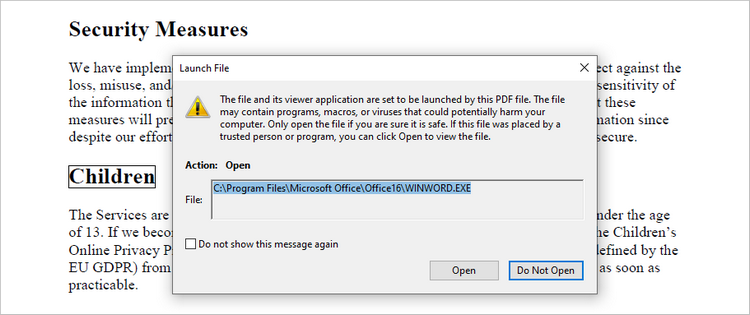
Add a Document Link Annotation to PDF in Python
A document link annotation in a PDF document is a type of annotation that creates a clickable link to a specific location within the same PDF file. To create a document link annotation, you can first use the PdfTextFinder class to identify the target text in the PDF document. Then, a PdfDocumentLinkAnnotation object is instantiated, and its destination property is configured to redirect the user to the specified location in the PDF.
The steps to add a document link annotation to PDF using Python are as follows:
- Create a PdfDocument object.
- Load a PDF file from the specified location.
- Get a page from the document.
- Find a specific piece of text within the page using PdfTextFinder class.
- Create a PdfDocumentLinkAnnotation object based on the bound of the text.
- Set the destination of the annotation using PdfDocumentLinkAnnotation.Destination property.
- Add the annotation to the page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the modified document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object based on the page
finder = PdfTextFinder(page)
# Set the find options
finder.Options.Parameter = TextFindParameter.WholeWord
finder.Options.Parameter = TextFindParameter.IgnoreCase
# Find the instances of the specified text
fragments = finder.Find("Children");
# Get the first instance
textFragment = fragments[0]
# Get the text bound
bound = textFragment.Bounds[0]
# Create a document link annotation
documentLinkAnnotation = PdfDocumentLinkAnnotation(bound)
# Set the destination of the annotation
documentLinkAnnotation.Destination = PdfDestination(doc.Pages[1]);
# Add the annotation to the collection of the annotations
page.AnnotationsWidget.Add(documentLinkAnnotation)
# Save result to file
doc.SaveToFile("output/DocumentLinkAnnotation.pdf")
# Dispose resources
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Managing PDF documents often involves removing annotations. Whether you're preparing documents for a presentation, sharing the final files with clients when questions are settled down, or archiving important records, deleting annotations can be essential.
Spire.PDF for Python allows users to delete annotations from PDFs in Python efficiently. Follow the instructions below to clean up your PDF files seamlessly.
- Delete Specified Annotations
- Delete All Annotations from a Page
- Delete All Annotations from the PDF Document
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install it, please refer to this tutorial: How to Install Spire.PDF for Python on Windows.
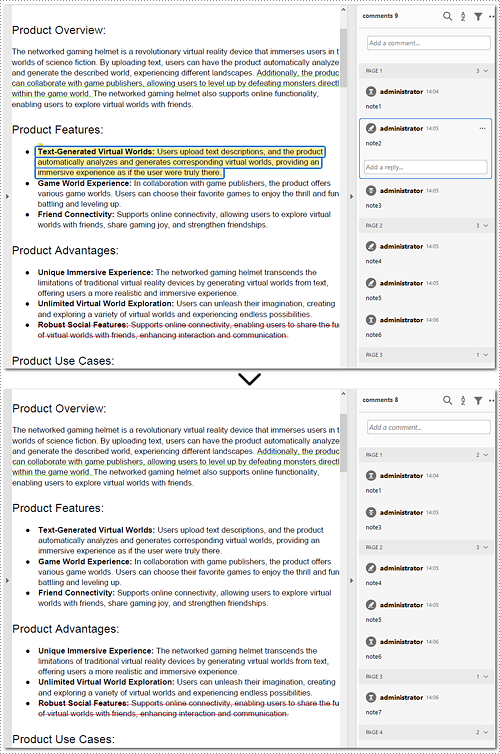
Delete Specified Annotations from PDF in Python
To delete a specified annotation from PDF documents, you need to target the annotation to be removed at first. Then you can remove it by calling the Page.AnnotationsWidget.RemoveAt() method offered by Spire.PDF for Python. This section will guide you through the whole process step by step.
Steps to remove an annotation from a page:
- Create a new Document object.
- Load a PDF document from files using Document.LoadFromFile() method.
- Get the specific page of the PDF with Document.Pages.get_Item() method.
- Delete the annotation from the page by calling Page.AnnotationsWidget.RemoveAt() method.
- Save the resulting document using Document.SaveToFile() method.
Here's the code example for you to refer to:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
doc = PdfDocument()
# Open the PDF document to be modified from the disk
doc.LoadFromFile("sample1.pdf")
# Get the first page of the document
page = doc.Pages.get_Item(0)
# Remove the 2nd annotation from the page
page.AnnotationsWidget.RemoveAt(1)
# Save the PDF document
doc.SaveToFile("output/delete_2nd_annotation.pdf", FileFormat.PDF)
doc.Close()
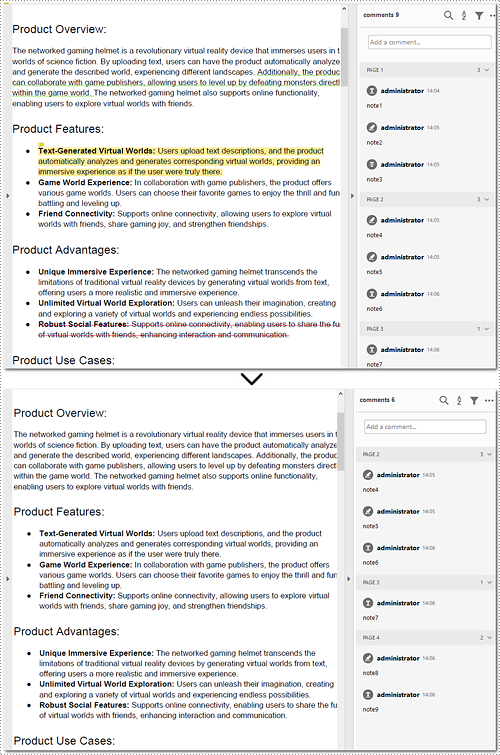
Delete All Annotations from a PDF Page in Python
The Pages.AnnotationsWidget.Clear() method provided by Spire.PDF for Python helps you to complete the task of removing each annotation from a page. This part will demonstrate how to delete all annotations from a page in Python with a detailed guide and a code example.
Steps to delete all annotations from a page:
- Create an instance of the Document class.
- Read the PDF document from the disk by Document.LoadFromFile() method.
- Remove annotations on the page using Pages.AnnotationsWidget.Clear() method.
- Write the document to disk with Document.SaveToFile() method.
Below is the code example of deleting annotations from the first page:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
document = PdfDocument()
# Load the file from the disk
document.LoadFromFile("sample1.pdf")
# Remove all annotations from the first page
document.Pages[0].AnnotationsWidget.Clear()
# Save the document
document.SaveToFile("output/delete_annotations_page.pdf", FileFormat.PDF)
document.Close()
Delete All Annotations of PDF Documents in Python
Removing all annotations from a PDF document involves retrieving the annotations first, which means you need to loop through each page to ensure that every annotation is deleted. The section will introduce how to accomplish the task in Python, providing detailed steps and an example to assist in cleaning up PDF documents.
Steps to remove all annotations of the whole PDF document:
- Instantiate a Document object.
- Open the document from files using Document.LoadFromFile() method.
- Loop through pages of the PDF document.
- Get each page of the PDF document with Document.Pages.get_Item() method.
- Remove all annotations from each page using Page.AnnotationsWidget.Clear() method.
- Save the document to your local file with Document.SaveToFile() method.
Here is the example for reference:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of PDF class
document = PdfDocument()
# Load the file to be operated from the disk
document.LoadFromFile("sample1.pdf")
# Loop through all pages in the PDF document
for i in range(document.Pages.Count):
# Get a specific page
page = document.Pages.get_Item(i)
# Remove all annotations from the page
page.AnnotationsWidget.Clear()
# Save the resulting document
document.SaveToFile("output/delete_all_annotations.pdf", FileFormat.PDF)
document.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Stamps are a powerful tool in PDF documents that allow users to mark and annotate specific areas or sections of a PDF file. Often used for approval, review, or to indicate a specific status, stamps can greatly enhance collaboration and document management. In PDF, stamps can take various forms, such as a simple checkmark, a customized graphic, a date and time stamp, or even a signature. In this article, you will learn how to add image stamps and dynamic stamps to a PDF document in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
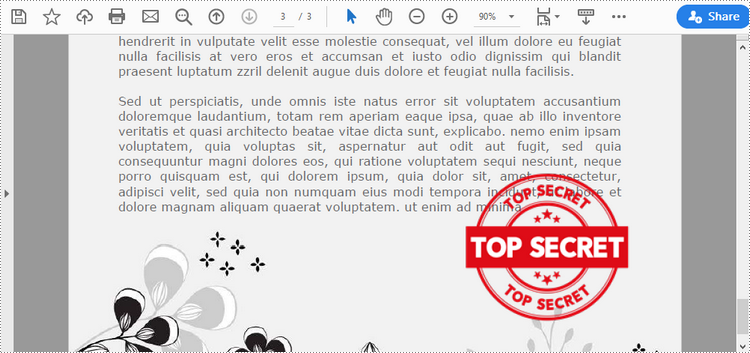
Add an Image Stamp to PDF Documents in Python
Spire.PDF for Python offers the PdfRubberStampAnnotation class to represent a rubber stamp in a PDF document. In order to create the appearance of a rubber stamp, the PdfTemplate class is used. The PdfTemplate is a piece of canvas on which you can draw whatever information you want, such as text, images, date, and time.
Image stamps can include logos, signatures, watermarks, or any other custom graphics that you want to overlay onto your PDFs. The main steps to add an image stamp to PDF using Spire.PDF for Python are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Load an image that you want to stamp on PDF using PdfImage.FromFile() method.
- Create a PdfTemplate object with the dimensions of the image.
- Draw the image on the template using PdfTemplate.Graphics.DrawImage() method.
- Create a PdfRubberStampAnnotation object, and set the template as its appearance.
- Add the stamp to a specific PDF page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the document to a different file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Get a specific page
page = doc.Pages[2]
# Load an image file
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\secret.png")
# Get the width and height of the image
width = (float)(image.Width)
height = (float)(image.Height)
# Create a PdfTemplate object based on the size of the image
template = PdfTemplate(width, height, True)
# Draw image on the template
template.Graphics.DrawImage(image, 0.0, 0.0, width, height)
# Create a rubber stamp annotation, specifying its location and position
rect = RectangleF((float) (page.ActualSize.Width - width - 50), (float) (page.ActualSize.Height - height - 40), width, height)
stamp = PdfRubberStampAnnotation(rect)
# Create a PdfAppearance object
pdfAppearance = PdfAppearance(stamp)
# Set the template as the normal state of the appearance
pdfAppearance.Normal = template
# Apply the appearance to the stamp
stamp.Appearance = pdfAppearance
# Add the stamp annotation to PDF
page.AnnotationsWidget.Add(stamp)
# Save the file
doc.SaveToFile("output/ImageStamp.pdf")
doc.Close()
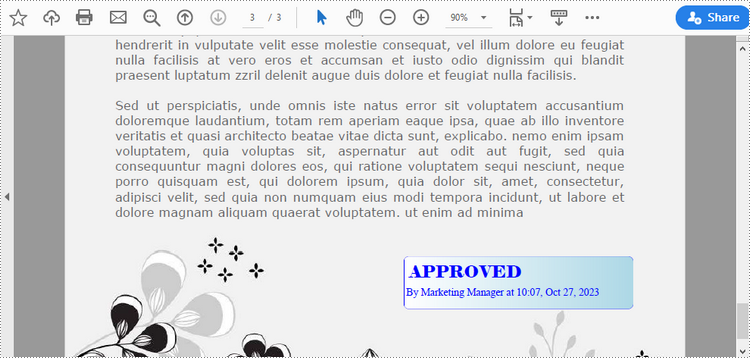
Add a Dynamic Stamp to PDF in Python
Unlike static stamps, dynamic stamps can contain variable information such as the date, time, or user input. The following are the steps to create a dynamic stamp in PDF using Spire.PDF for Python.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Create a PdfTemplate object with desired size.
- Draw strings on the template using PdfTemplate.Graphics.DrawString() method.
- Create a PdfRubberStampAnnotation object, and set the template as its appearance.
- Add the stamp to a specific PDF page using PdfPageBase.AnnotationsWidget.Add() method.
- Save the document to a different file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Get a specific page
page = doc.Pages[2]
# Create a PdfTemplate object
template = PdfTemplate(220.0, 50.0, True)
# Create two fonts
font1 = PdfTrueTypeFont("Elephant", 16.0, 0, True)
font2 = PdfTrueTypeFont("Times New Roman", 10.0, 0, True)
# Create a solid brush and a gradient brush
solidBrush = PdfSolidBrush(PdfRGBColor(Color.get_Blue()))
rectangle1 = RectangleF(PointF(0.0, 0.0), template.Size)
linearGradientBrush = PdfLinearGradientBrush(rectangle1, PdfRGBColor(Color.get_White()), PdfRGBColor(Color.get_LightBlue()), PdfLinearGradientMode.Horizontal)
# Create a pen
pen = PdfPen(solidBrush)
# Create a rounded rectangle path
CornerRadius = 10.0
path = PdfPath()
path.AddArc(template.GetBounds().X, template.GetBounds().Y, CornerRadius, CornerRadius, 180.0, 90.0)
path.AddArc(template.GetBounds().X + template.Width - CornerRadius, template.GetBounds().Y, CornerRadius, CornerRadius, 270.0, 90.0)
path.AddArc(template.GetBounds().X + template.Width - CornerRadius, template.GetBounds().Y + template.Height - CornerRadius, CornerRadius, CornerRadius, 0.0, 90.0)
path.AddArc(template.GetBounds().X, template.GetBounds().Y + template.Height - CornerRadius, CornerRadius, CornerRadius, 90.0, 90.0)
path.AddLine(template.GetBounds().X, template.GetBounds().Y + template.Height - CornerRadius, template.GetBounds().X, template.GetBounds().Y + CornerRadius / 2)
# Draw path on the template
template.Graphics.DrawPath(pen, path)
template.Graphics.DrawPath(linearGradientBrush, path)
# Draw text on the template
string1 = "APPROVED\n"
string2 = "By Marketing Manager at " + DateTime.get_Now().ToString("HH:mm, MMM dd, yyyy")
template.Graphics.DrawString(string1, font1, solidBrush, PointF(5.0, 5.0))
template.Graphics.DrawString(string2, font2, solidBrush, PointF(2.0, 28.0))
# Create a rubber stamp, specifying its size and location
rectangle2 = RectangleF((float) (page.ActualSize.Width - 220.0 - 50.0), (float) (page.ActualSize.Height - 50.0 - 100.0), 220.0, 50.0)
stamp = PdfRubberStampAnnotation(rectangle2)
# Create a PdfAppearance object and apply the template as its normal state
apprearance = PdfAppearance(stamp)
apprearance.Normal = template
# Apply the appearance to stamp
stamp.Appearance = apprearance
# Add the stamp annotation to annotation collection
page.AnnotationsWidget.Add(stamp)
# Save the file
doc.SaveToFile("output/DynamicStamp.pdf", FileFormat.PDF)
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
