Python-PDF-zu-Text-Konvertierung: Text aus PDFs abrufen
Inhaltsverzeichnis
Mit Pip installieren
pip install Spire.PDF
verwandte Links
Im heutigen digitalen Zeitalter ist die Fähigkeit, Informationen aus PDF-Dokumenten schnell und effizient zu extrahieren, für verschiedene Branchen und Fachleute von entscheidender Bedeutung. Unabhängig davon, ob Sie ein Forscher oder Datenanalyst sind oder einfach mit einer großen Menge an PDF-Dateien arbeiten, können Sie durch die Konvertierung von PDFs in ein bearbeitbares Textformat wertvolle Zeit und Mühe sparen. Hier kommt Python, eine vielseitige und leistungsstarke Programmiersprache, mit ihren umfangreichen Konvertierungsfunktionen zum Einsatz PDF in Text in Python umwandeln.

In diesem Artikel erfahren Sie, wie Sie es verwenden Python für PDF in Text Konvertierung und entfesselt die Leistungsfähigkeit von Python bei der PDF-Dateiverarbeitung. Dieser Artikel umfasst die folgenden Themen:
- Python-API für die Konvertierung von PDF in Text
- Anleitung zum Konvertieren von PDF in Text in Python
- Python zum Konvertieren von PDF in Text, ohne das Layout beizubehalten
- Python zum Konvertieren von PDF in Text und Beibehalten des Layouts
- Python zum Konvertieren eines bestimmten PDF-Seitenbereichs in Text
- Holen Sie sich eine kostenlose Lizenz für die API zum Konvertieren von PDF in Text in Python
- Erfahren Sie mehr über die PDF-Verarbeitung mit Python
Python-API für die Konvertierung von PDF in Text
Um Python für die Konvertierung von PDF in Text zu verwenden, ist eine PDF-Verarbeitungs-API – Spire.PDF for Python – erforderlich. Diese Python-Bibliothek wurde für die Bearbeitung von PDF-Dokumenten in Python-Programmen entwickelt, wodurch Python-Programme mit verschiedenen PDF-Verarbeitungsfähigkeiten ausgestattet werden.
Wir können Laden Sie Spire.PDF for Python herunter und fügen Sie es unserem Projekt hinzu oder installieren Sie es einfach über PyPI mit dem folgenden Code:
pip install Spire.PDF
Anleitung zum Konvertieren von PDF in Text in Python
Bevor wir mit der Konvertierung von PDF in Text mit Python fortfahren, werfen wir einen Blick auf die wichtigsten Vorteile, die es uns bieten kann:
- Bearbeitbarkeit: Durch das Konvertieren von PDF in Text können Sie das Dokument einfacher bearbeiten, da Textdateien auf den meisten Geräten geöffnet und bearbeitet werden können.
- Barrierefreiheit: Textdateien sind im Allgemeinen besser zugänglich als PDFs. Ganz gleich, ob es sich um einen Desktop oder ein Mobiltelefon handelt, Textdateien können problemlos auf Geräten angezeigt werden.
- Integration mit anderen Anwendungen: Textdateien können nahtlos in verschiedene Anwendungen und Arbeitsabläufe integriert werden.
Schritte zum Konvertieren von PDF-Dokumenten in Textdateien in Python:
- Installieren Spire.PDF for Python.
- Module importieren.
- Erstellen Sie ein Objekt der Klasse PdfDocument und laden Sie eine PDF-Datei mit der Methode LoadFromFile().
- Erstellen Sie ein Objekt der PdfTextExtractOptions-Klasse und legen Sie die Textextraktionsoptionen fest, einschließlich der Extraktion des gesamten Textes, der Anzeige ausgeblendeten Textes, der Extraktion nur des Texts in einem bestimmten Bereich und der einfachen Extraktion.
- Rufen Sie mit der Methode PdfDocument.Pages.get_Item() eine Seite im Dokument ab und erstellen Sie PdfTextExtractor-Objekte basierend auf jeder Seite, um den Text mit der Methode Extract() mit angegebenen Optionen aus der Seite zu extrahieren.
- Speichern Sie den extrahierten Text als Textdatei und schließen Sie das PdfDocument-Objekt.
Python zum Konvertieren von PDF in Text ohne Beibehaltung des Layouts
Wenn Sie die einfache Extraktionsmethode zum Extrahieren von Text aus PDF verwenden, behält das Programm die leeren Bereiche nicht bei und verfolgt nicht die aktuelle Y-Position jeder Zeichenfolge und fügt einen Zeilenumbruch in die Ausgabe ein, wenn sich die Y-Position geändert hat.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
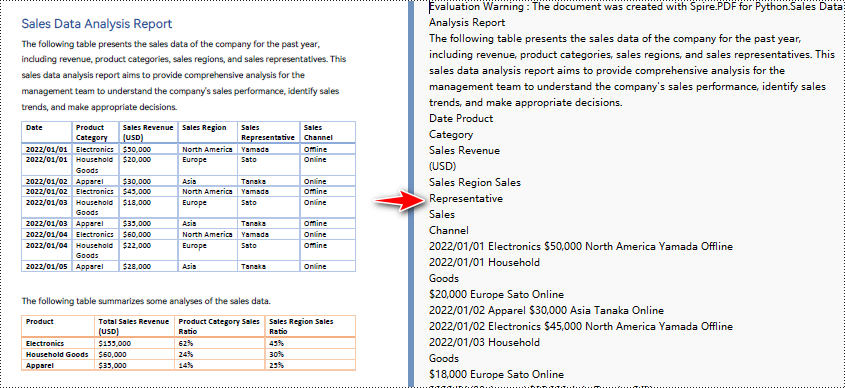
Python zum Konvertieren von PDF in Text und Beibehalten des Layouts
Wenn Sie die Standardextraktionsmethode zum Extrahieren von Text aus PDF verwenden, extrahiert das Programm den Text Zeile für Zeile, einschließlich Leerzeichen.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
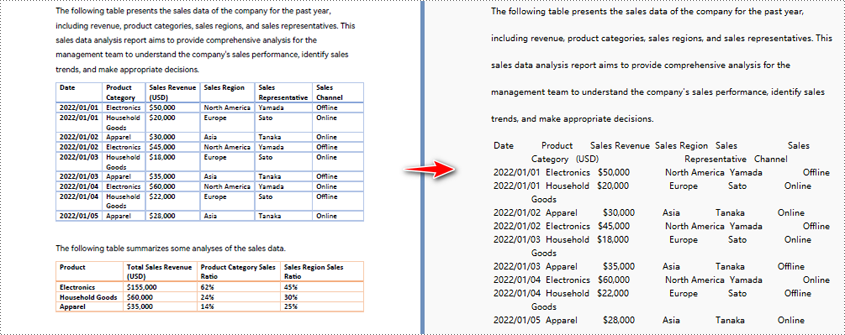
Python zum Konvertieren eines bestimmten PDF-Seitenbereichs in Text
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
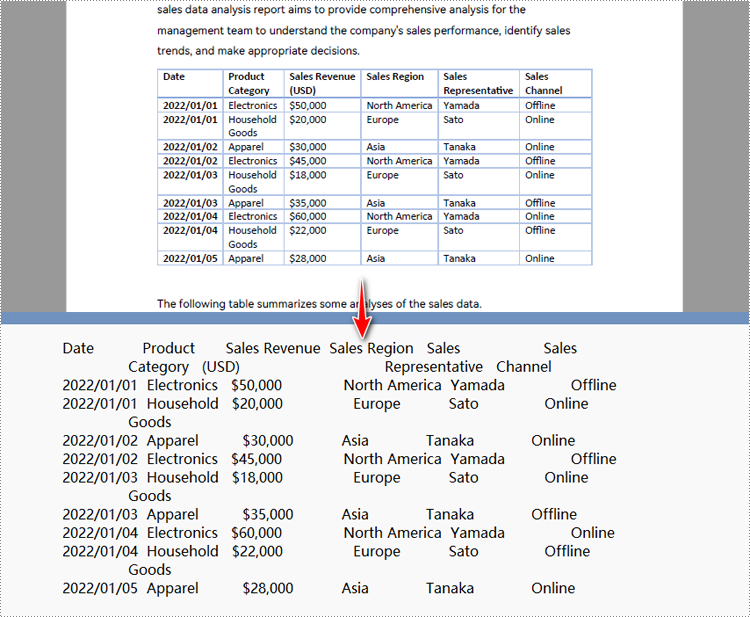
Holen Sie sich eine kostenlose Lizenz für die API zum Konvertieren von PDF in Text in Python
Benutzer können Beantragen Sie eine kostenlose temporäre Lizenz um Spire.PDF für Python auszuprobieren und die Python-PDF-zu-Text-Konvertierungsfunktionen ohne Einschränkungen zu testen.
Erfahren Sie mehr über die PDF-Verarbeitung mit Python
Neben der Konvertierung von PDF in Text mit Python können wir über die folgenden Quellen auch weitere PDF-Verarbeitungsfunktionen dieser API erkunden:
- So extrahieren Sie Text aus PDF-Dokumenten mit Python
- Tutorials zur PDF-Verarbeitung mit Python
- Konvertieren bildbasierter PDF-Dokumente in Text (OCR)
Abschluss
In diesem Blogbeitrag haben wir es untersucht Python in PDF-zu-Text-Konvertierung. Indem wir die Betriebsschritte befolgen und auf die Codebeispiele im Artikel verweisen, können wir schnell etwas erreichen PDF-zu-Text-Konvertierung in Python Programme. Darüber hinaus bietet der Artikel Einblicke in die Vorteile der Konvertierung von PDF-Dokumenten in Textdateien. Noch wichtiger ist, dass wir aus den Referenzen im Artikel weitere Kenntnisse über den Umgang mit PDF-Dokumenten mit Python und Methoden zur Konvertierung bildbasierter PDF-Dokumente in Text mithilfe von OCR-Tools gewinnen können. Sollten bei der Nutzung von Spire.PDF for Python Probleme auftreten, können Sie technischen Support erhalten, indem Sie sich über das Spire.PDF-Forum oder per E-Mail an unser Team wenden.
Conversión de PDF a texto de Python: recuperar texto de archivos PDF
Tabla de contenido
Instalar con Pip
pip install Spire.PDF
enlaces relacionados
En la era digital actual, la capacidad de extraer información de documentos PDF de forma rápida y eficiente es crucial para diversas industrias y profesionales. Ya sea que sea investigador, analista de datos o simplemente trabaje con un gran volumen de archivos PDF, poder convertir archivos PDF a formato de texto editable puede ahorrarle tiempo y esfuerzo valiosos. Aquí es donde Python, un lenguaje de programación potente y versátil, viene al rescate con sus amplias funciones para convertir PDF a texto en Python.
En este artículo, exploraremos cómo usar Python para PDF a texto conversión, liberando el poder de Python en el procesamiento de archivos PDF. Este artículo incluye los siguientes temas:
- API de Python para conversión de PDF a texto
- Guía para convertir PDF a texto en Python
- Python para convertir PDF a texto sin mantener el diseño
- Python para convertir PDF a texto y mantener el diseño
- Python para convertir un área de página PDF especificada en texto
- Obtenga una licencia gratuita para la API para convertir PDF a texto en Python
- Obtenga más información sobre el procesamiento de PDF con Python
API de Python para conversión de PDF a texto
Para utilizar Python para la conversión de PDF a texto, se necesita una API de procesamiento de PDF: Spire.PDF for Python. Esta biblioteca de Python está diseñada para la manipulación de documentos PDF en programas Python, lo que permite a los programas Python varias capacidades de procesamiento de PDF.
Podemos descargar Spire.PDF for Python y agregarlo a nuestro proyecto, o simplemente instalarlo a través de PyPI con el siguiente código:
pip install Spire.PDF
Guía para convertir PDF a texto en Python
Antes de continuar con la conversión de PDF a texto usando Python, veamos las principales ventajas que nos puede ofrecer:
- Editabilidad: Convertir PDF a texto le permite editar el documento más fácilmente, ya que los archivos de texto se pueden abrir y editar en la mayoría de los dispositivos.
- Accesibilidad: los archivos de texto son generalmente más accesibles que los PDF. Ya sea una computadora de escritorio o un teléfono móvil, los archivos de texto se pueden ver en los dispositivos con facilidad.
- Integración con otras aplicaciones: los archivos de texto se pueden integrar perfectamente en varias aplicaciones y flujos de trabajo.
Pasos para convertir documentos PDF a archivos de texto en Python:
- Instale Spire.PDF for Python.
- Importar módulos.
- Cree un objeto de la clase PdfDocument y cargue un archivo PDF usando el método LoadFromFile().
- Cree un objeto de la clase PdfTextExtractOptions y configure las opciones de extracción de texto, incluida la extracción de todo el texto, la visualización de texto oculto, la extracción solo de texto en un área específica y la extracción simple.
- Obtenga una página en el documento usando el método PdfDocument.Pages.get_Item() y cree objetos PdfTextExtractor basados en cada página para extraer el texto de la página usando el método Extract() con opciones específicas.
- Guarde el texto extraído como un archivo de texto y cierre el objeto PdfDocument.
Python para convertir PDF a texto sin mantener el diseño
Cuando se utiliza el método de extracción simple para extraer texto de un PDF, el programa no retendrá las áreas en blanco ni realizará un seguimiento de la posición Y actual de cada cadena ni insertará un salto de línea en la salida si la posición Y ha cambiado.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python para convertir PDF a texto y mantener el diseño
Cuando se utiliza el método de extracción predeterminado para extraer texto de un PDF, el programa extraerá el texto línea por línea, incluidos los espacios en blanco.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python para convertir un área de página PDF especificada en texto
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Obtenga una licencia gratuita para la API para convertir PDF a texto en Python
Los usuarios pueden solicitar una licencia temporal gratuita Pruebe Spire.PDF for Python y evalúe las funciones de conversión de PDF a texto de Python sin ninguna limitación.
Obtenga más información sobre el procesamiento de PDF con Python
Además de convertir PDF a texto con Python, también podemos explorar más funciones de procesamiento de PDF de esta API a través de las siguientes fuentes:
- Cómo extraer texto de documentos PDF con Python
- Tutoriales para el procesamiento de PDF con Python
- Conversión de documentos PDF basados en imágenes a texto (OCR)
Conclusión
En esta publicación de blog, hemos explorado Python en conversión de PDF a texto. Siguiendo los pasos operativos y consultando los ejemplos de código del artículo, podemos lograr resultados rápidos Conversión de PDF a texto en Python programas. Además, el artículo proporciona información sobre los beneficios de convertir documentos PDF en archivos de texto. Más importante aún, podemos obtener más conocimientos sobre el manejo de documentos PDF con Python y métodos para convertir documentos PDF basados en imágenes en texto a través de herramientas OCR a partir de las referencias del artículo. Si surge algún problema durante el uso de Spire.PDF for Python, puede obtener asistencia técnica comunicándose con nuestro equipo a través del foro de Spire.PDF o por correo electrónico.
Python PDF를 텍스트로 변환: PDF에서 텍스트 검색
목차
핍으로 설치
pip install Spire.PDF
관련된 링크들
오늘날의 디지털 시대에 PDF 문서에서 정보를 빠르고 효율적으로 추출하는 능력은 다양한 산업과 전문가에게 매우 중요합니다. 연구자, 데이터 분석가 또는 단순히 대량의 PDF 파일을 처리하는 경우 PDF를 편집 가능한 텍스트 형식으로 변환하면 귀중한 시간과 노력을 절약할 수 있습니다. 다재다능하고 강력한 프로그래밍 언어인 Python이 변환을 위한 광범위한 기능을 통해 구출되는 곳입니다 Python에서 PDF를 텍스트로.
이번 글에서는 사용법을 알아보겠습니다 PDF를 텍스트로 변환하는 Python 변환하여 PDF 파일 처리에 Python의 강력한 기능을 활용합니다. 이 문서에는 다음 주제가 포함되어 있습니다.
- PDF를 텍스트로 변환하기 위한 Python API
- Python에서 PDF를 텍스트로 변환하기 위한 가이드
- 레이아웃을 유지하지 않고 PDF를 텍스트로 변환하는 Python
- PDF를 텍스트로 변환하고 레이아웃을 유지하는 Python
- 지정된 PDF 페이지 영역을 텍스트로 변환하는 Python
- Python에서 PDF를 텍스트로 변환하는 API에 대한 무료 라이센스 받기
- Python을 사용한 PDF 처리에 대해 자세히 알아보기
PDF를 텍스트로 변환하기 위한 Python API
PDF를 텍스트로 변환하기 위해 Python을 사용하려면 PDF 처리 API인 Spire.PDF for Python가 필요합니다. 이 Python 라이브러리는 Python 프로그램에서 PDF 문서 조작을 위해 설계되었으며, Python 프로그램에 다양한 PDF 처리 기능을 제공합니다.
우리는 할 수 있다 Spire.PDF for Python 다운로드 프로젝트에 추가하거나 다음 코드를 사용하여 PyPI를 통해 간단히 설치하세요.
pip install Spire.PDF
Python에서 PDF를 텍스트로 변환하기 위한 가이드
Python을 사용하여 PDF를 텍스트로 변환하기 전에 Python이 제공할 수 있는 주요 이점을 살펴보겠습니다.
- 편집 가능성: PDF를 텍스트로 변환하면 대부분의 장치에서 텍스트 파일을 열고 편집할 수 있으므로 문서를 더 쉽게 편집할 수 있습니다.
- 접근성: 일반적으로 텍스트 파일은 PDF보다 접근성이 더 높습니다. 데스크톱이든 휴대폰이든 텍스트 파일을 장치에서 쉽게 볼 수 있습니다.
- 다른 애플리케이션과 통합: 텍스트 파일은 다양한 애플리케이션 및 작업 흐름에 원활하게 통합될 수 있습니다.
Python에서 PDF 문서를 텍스트 파일로 변환하는 단계:
- Spire.PDF for Python를 설치합니다.
- 모듈을 가져옵니다.
- PdfDocument 클래스의 객체를 생성하고 LoadFromFile() 메서드를 사용하여 PDF 파일을 로드합니다.
- PdfTextExtractOptions 클래스의 객체를 생성하고 모든 텍스트 추출, 숨겨진 텍스트 표시, 지정된 영역의 텍스트만 추출, 단순 추출을 포함한 텍스트 추출 옵션을 설정합니다.
- PdfDocument.Pages.get_Item() 메소드를 사용하여 문서에서 페이지를 가져오고 각 페이지를 기반으로 PdfTextExtractor 객체를 생성하여 지정된 옵션과 함께 Extract() 메소드를 사용하여 페이지에서 텍스트를 추출합니다.
- 추출된 텍스트를 텍스트 파일로 저장하고 PdfDocument 개체를 닫습니다.
레이아웃 유지 없이 PDF를 텍스트로 변환하는 Python
PDF에서 텍스트를 추출하기 위해 단순 추출 방법을 사용할 때 프로그램은 빈 영역을 유지하지 않고 각 문자열의 현재 Y 위치를 추적하며 Y 위치가 변경된 경우 출력에 줄 바꿈을 삽입합니다.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
PDF를 텍스트로 변환하고 레이아웃을 유지하는 Python
기본 추출 방법을 사용하여 PDF에서 텍스트를 추출하는 경우 프로그램은 공백을 포함하여 한 줄씩 텍스트를 추출합니다.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
지정된 PDF 페이지 영역을 텍스트로 변환하는 Python
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python에서 PDF를 텍스트로 변환하는 API에 대한 무료 라이센스 받기
사용자는 다음을 수행할 수 있습니다 무료 임시 라이센스를 신청하세요 Spire.PDF for Python를 사용해 보고 Python PDF를 텍스트로 변환하는 기능을 제한 없이 평가해 보세요.
Python을 사용한 PDF 처리에 대해 자세히 알아보기
Python을 사용하여 PDF를 텍스트로 변환하는 것 외에도 다음 소스를 통해 이 API의 더 많은 PDF 처리 기능을 탐색할 수도 있습니다.
결론
이번 블로그 게시물에서 우리는 PDF의 Python을 텍스트로 변환합니다. 운영 단계를 따르고 기사의 코드 예제를 참조하면 빠르게 달성할 수 있습니다 Python에서 PDF를 텍스트로 변환 프로그램들. 또한 이 기사는 PDF 문서를 텍스트 파일로 변환할 때의 이점에 대한 통찰력을 제공합니다. 더 중요한 것은 기사의 참고 자료에서 Python을 사용하여 PDF 문서를 처리하는 방법과 OCR 도구를 통해 이미지 기반 PDF 문서를 텍스트로 변환하는 방법에 대한 추가 지식을 얻을 수 있다는 것입니다. Spire.PDF for Python를 사용하는 동안 문제가 발생하는 경우 다음을 통해 당사 팀에 문의하여 기술 지원을 받을 수 있습니다 Spire.PDF 포럼 또는 이메일.
Conversione da PDF a testo in Python: recupera testo da PDF
Sommario
Installa con Pip
pip install Spire.PDF
Link correlati
Nell'era digitale di oggi, la capacità di estrarre informazioni dai documenti PDF in modo rapido ed efficiente è fondamentale per vari settori e professionisti. Che tu sia un ricercatore, un analista di dati o semplicemente hai a che fare con un grande volume di file PDF, la possibilità di convertire i PDF in un formato di testo modificabile può farti risparmiare tempo e fatica preziosi. È qui che Python, un linguaggio di programmazione versatile e potente, viene in soccorso con le sue estese funzionalità per convertire PDF in testo in Python.
In questo articolo esploreremo come utilizzarlo Python per PDF in testo conversione, liberando la potenza di Python nell'elaborazione dei file PDF. Questo articolo include i seguenti argomenti:
- API Python per la conversione da PDF a testo
- Guida per convertire PDF in testo in Python
- Python per convertire PDF in testo senza mantenere il layout
- Python per convertire PDF in testo e mantenere il layout
- Python per convertire un'area della pagina PDF specificata in testo
- Ottieni una licenza gratuita per l'API per convertire PDF in testo in Python
- Ulteriori informazioni sull'elaborazione dei PDF con Python
API Python per la conversione da PDF a testo
Per utilizzare Python per la conversione da PDF a testo, è necessaria un'API di elaborazione PDF: Spire.PDF for Python. Questa libreria Python è progettata per la manipolazione di documenti PDF nei programmi Python, che fornisce ai programmi Python varie capacità di elaborazione PDF.
Possiamo scaricare Spire.PDF for Python e aggiungilo al nostro progetto o semplicemente installalo tramite PyPI con il seguente codice:
pip install Spire.PDF
Guida per convertire PDF in testo in Python
Prima di procedere con la conversione di PDF in testo utilizzando Python, diamo un'occhiata ai principali vantaggi che può offrirci:
- Modificabilità: la conversione di PDF in testo consente di modificare il documento più facilmente, poiché i file di testo possono essere aperti e modificati sulla maggior parte dei dispositivi.
- Accessibilità: i file di testo sono generalmente più accessibili dei PDF. Che si tratti di un desktop o di un telefono cellulare, i file di testo possono essere visualizzati facilmente sui dispositivi.
- Integrazione con altre applicazioni: i file di testo possono essere perfettamente integrati in varie applicazioni e flussi di lavoro.
Passaggi per convertire documenti PDF in file di testo in Python:
- Installa Spire.PDF for Python.
- Importa moduli.
- Crea un oggetto della classe PdfDocument e carica un file PDF utilizzando il metodo LoadFromFile().
- Crea un oggetto della classe PdfTextExtractOptions e imposta le opzioni di estrazione del testo, inclusa l'estrazione di tutto il testo, la visualizzazione del testo nascosto, l'estrazione solo del testo in un'area specifica e l'estrazione semplice.
- Ottieni una pagina nel documento utilizzando il metodo PdfDocument.Pages.get_Item() e crea oggetti PdfTextExtractor basati su ciascuna pagina per estrarre il testo dalla pagina utilizzando il metodo Extract() con le opzioni specificate.
- Salva il testo estratto come file di testo e chiudi l'oggetto PdfDocument.
Python per convertire PDF in testo senza mantenere il layout
Quando si utilizza il metodo di estrazione semplice per estrarre testo da PDF, il programma non manterrà le aree vuote e terrà traccia della posizione Y corrente di ciascuna stringa e inserirà un'interruzione di riga nell'output se la posizione Y è cambiata.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python per convertire PDF in testo e mantenere il layout
Quando si utilizza il metodo di estrazione predefinito per estrarre testo da PDF, il programma estrarrà il testo riga per riga, compresi gli spazi vuoti.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python per convertire un'area della pagina PDF specificata in testo
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Ottieni una licenza gratuita per l'API per convertire PDF in testo in Python
Gli utenti possono richiedere una licenza temporanea gratuita per provare Spire.PDF for Python e valutare le funzionalità di conversione da PDF a testo di Python senza alcuna limitazione.
Ulteriori informazioni sull'elaborazione dei PDF con Python
Oltre a convertire PDF in testo con Python, possiamo anche esplorare altre funzionalità di elaborazione PDF di questa API attraverso le seguenti fonti:
- Come estrarre testo da documenti PDF con Python
- Tutorial per l'elaborazione di PDF con Python
- Conversione di documenti PDF basati su immagini in testo (OCR)
Conclusione
In questo post del blog, abbiamo esplorato Python nella conversione da PDF a testo. Seguendo i passaggi operativi e facendo riferimento agli esempi di codice nell'articolo, possiamo ottenere risultati rapidi Conversione da PDF a testo in Python programmi. Inoltre, l'articolo fornisce approfondimenti sui vantaggi della conversione di documenti PDF in file di testo. Ancora più importante, possiamo acquisire ulteriori conoscenze sulla gestione dei documenti PDF con Python e sui metodi per convertire documenti PDF basati su immagini in testo tramite strumenti OCR dai riferimenti nell'articolo. Se si verificano problemi durante l'utilizzo di Spire.PDF for Python, è possibile ottenere supporto tecnico contattando il nostro team tramite il forum Spire.PDF o tramite e-mail.
Conversion Python PDF en texte : récupérer du texte à partir de PDF
Table des matières
Installer avec Pip
pip install Spire.PDF
Liens connexes
À l’ère numérique d’aujourd’hui, la capacité d’extraire rapidement et efficacement des informations à partir de documents PDF est cruciale pour diverses industries et professionnels. Que vous soyez chercheur, analyste de données ou que vous traitiez simplement un grand volume de fichiers PDF, la possibilité de convertir des PDF au format texte modifiable peut vous faire gagner un temps et des efforts précieux. C'est là que Python, un langage de programmation polyvalent et puissant, vient à la rescousse avec ses fonctionnalités étendues de conversion de PDF en texte en Python.
Dans cet article, nous explorerons comment utiliser Python pour PDF en texte conversion, libérant la puissance de Python dans le traitement des fichiers PDF. Cet article comprend les sujets suivants :
- API Python pour la conversion de PDF en texte
- Guide de conversion de PDF en texte en Python
- Python pour convertir un PDF en texte sans conserver la mise en page
- Python pour convertir un PDF en texte et conserver la mise en page
- Python pour convertir une zone de page PDF spécifiée en texte
- Obtenez une licence gratuite pour l'API permettant de convertir un PDF en texte en Python
- En savoir plus sur le traitement PDF avec Python
API Python pour la conversion de PDF en texte
Pour utiliser Python pour la conversion de PDF en texte, une API de traitement PDF – Spire.PDF for Python est nécessaire. Cette bibliothèque Python est conçue pour la manipulation de documents PDF dans les programmes Python, ce qui donne aux programmes Python diverses capacités de traitement PDF.
Nous pouvons télécharger Spire.PDF for Python et ajoutez-le à notre projet, ou installez-le simplement via PyPI avec le code suivant :
pip install Spire.PDF
Guide de conversion de PDF en texte en Python
Avant de procéder à la conversion de PDF en texte à l'aide de Python, examinons les principaux avantages qu'il peut nous offrir :
- Modifiable: la conversion d'un PDF en texte vous permet de modifier le document plus facilement, car les fichiers texte peuvent être ouverts et modifiés sur la plupart des appareils.
- Accessibilité: les fichiers texte sont généralement plus accessibles que les PDF. Qu'il s'agisse d'un ordinateur de bureau ou d'un téléphone mobile, les fichiers texte peuvent être facilement visualisés sur des appareils.
- Intégration avec d'autres applications: les fichiers texte peuvent être intégrés de manière transparente dans diverses applications et flux de travail.
Étapes pour convertir des documents PDF en fichiers texte en Python :
- Installez Spire.PDF for Python.
- Importer des modules.
- Créez un objet de la classe PdfDocument et chargez un fichier PDF à l'aide de la méthode LoadFromFile().
- Créez un objet de la classe PdfTextExtractOptions et définissez les options d'extraction de texte, notamment l'extraction de tout le texte, l'affichage du texte masqué, l'extraction uniquement du texte dans une zone spécifiée et l'extraction simple.
- Obtenez une page du document à l'aide de la méthode PdfDocument.Pages.get_Item() et créez des objets PdfTextExtractor basés sur chaque page pour extraire le texte de la page à l'aide de la méthode Extract() avec les options spécifiées.
- Enregistrez le texte extrait en tant que fichier texte et fermez l'objet PdfDocument.
Python pour convertir un PDF en texte sans conserver la mise en page
Lorsque vous utilisez la méthode d'extraction simple pour extraire du texte à partir d'un PDF, le programme ne conservera pas les zones vides, ne gardera pas trace de la position Y actuelle de chaque chaîne et n'insérera pas un saut de ligne dans la sortie si la position Y a changé.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python pour convertir un PDF en texte et conserver la mise en page
Lorsque vous utilisez la méthode d'extraction par défaut pour extraire le texte d'un PDF, le programme extraira le texte ligne par ligne, y compris les espaces.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python pour convertir une zone de page PDF spécifiée en texte
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Obtenez une licence gratuite pour l'API permettant de convertir un PDF en texte en Python
Les utilisateurs peuvent demander une licence temporaire gratuite pour essayer Spire.PDF for Python et évaluer les fonctionnalités de conversion Python PDF en texte sans aucune limitation.
En savoir plus sur le traitement PDF avec Python
Outre la conversion de PDF en texte avec Python, nous pouvons également explorer davantage de fonctionnalités de traitement PDF de cette API via les sources suivantes :
- Comment extraire du texte de documents PDF avec Python
- Tutoriels pour le traitement PDF avec Python
- Conversion de documents PDF basés sur des images en texte (OCR)
Conclusion
Dans cet article de blog, nous avons exploré Python dans la conversion PDF en texte. En suivant les étapes opérationnelles et en vous référant aux exemples de code dans l'article, nous pouvons réaliser rapidement Conversion de PDF en texte en Python programmes. De plus, l'article donne un aperçu des avantages de la conversion de documents PDF en fichiers texte. Plus important encore, nous pouvons acquérir des connaissances supplémentaires sur la gestion des documents PDF avec Python et les méthodes permettant de convertir des documents PDF basés sur des images en texte via les outils OCR à partir des références contenues dans l'article. Si des problèmes surviennent lors de l'utilisation de Spire.PDF for Python, une assistance technique peut être obtenue en contactant notre équipe via le Forum Spire.PDF ou email.
Leia arquivos Excel com Python
Índice
Instalar com Pip
pip install Spire.XLS
Links Relacionados
Arquivos Excel (planilhas) são usados por pessoas em todo o mundo para organizar, analisar e armazenar dados tabulares. Devido à sua popularidade, os desenvolvedores frequentemente encontram situações em que precisam extrair dados do Excel ou criar relatórios no formato Excel. Ser capaz de leia arquivos Excel com Python abre um conjunto abrangente de possibilidades para processamento e automação de dados. Neste artigo você aprenderá como ler dados (valores de texto ou números) de uma célula, um intervalo de células ou uma planilha inteira usando a biblioteca Spire.XLS for Python.
- Leia os dados de uma célula específica em Python
- Ler dados de um intervalo de células em Python
- Leia dados de uma planilha do Excel em Python
- Leia o valor em vez da fórmula em uma célula em Python
Biblioteca Python para leitura do Excel
Spire.XLS for Python é uma biblioteca Python confiável de nível empresarial para criar, escrever, ler e editando Excel documentos (XLS, XLSX, XLSB, XLSM, ODS) em um aplicativo Python. Ele fornece um conjunto abrangente de interfaces, classes e propriedades que permitem aos programadores ler e escrever Excel arquivos com facilidade. Especificamente, uma célula em uma pasta de trabalho pode ser acessada usando a propriedade Worksheet.Range e o valor da célula pode ser obtido usando a propriedade CellRange.Value.
A biblioteca é fácil de instalar executando o seguinte comando pip. Se você quiser importar manualmente as dependências necessárias, consulte Como instalar Spire.XLS for Python no código VS
pip install Spire.XLS
Classes e propriedades em Spire.XLS para API Python
- Classe de pasta de trabalho: representa um modelo de pasta de trabalho do Excel, que você pode usar para criar uma pasta de trabalho do zero ou carregar um documento Excel existente e fazer modificações nele.
- Classe de planilha: representa uma planilha em uma pasta de trabalho.
- Classe CellRange: representa uma célula específica ou um intervalo de células em uma pasta de trabalho.
- Propriedade Worksheet.Range: Obtém uma célula ou intervalo e retorna um objeto da classe CellRange.
- Propriedade Worksheet.AllocatedRange: Obtém o intervalo de células que contém os dados e retorna um objeto da classe CellRange.
- Propriedade CellRange.Value: Obtém o valor numérico ou valor de texto de uma célula. Mas se uma célula tiver uma fórmula, esta propriedade retornará a fórmula em vez do resultado da fórmula.
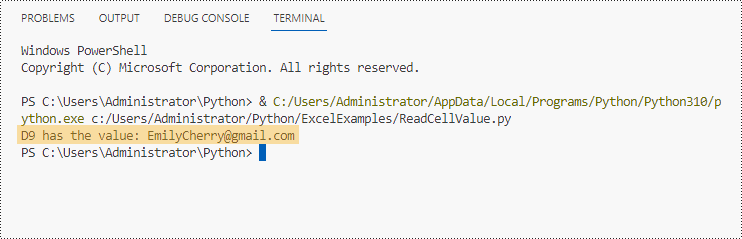
Leia os dados de uma célula específica em Python
Com Spire.XLS for Python, você pode obter facilmente o valor de uma determinada célula usando a propriedade CellRange.Value. As etapas para ler dados de uma célula específica do Excel em Python são as seguintes.
- Instanciar classe de pasta de trabalho
- Carregue um documento Excel usando o método LoadFromFile.
- Obtenha uma planilha específica usando a propriedade Workbook.Worksheets[index].
- Obtenha uma célula específica usando a propriedade Worksheet.Range.
- Obtenha o valor da célula usando a propriedade CellRange.Value
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D9"]
# Get the value of the cell
print("D9 has the value: " + certainCell.Value)
Ler dados de um intervalo de células em Python
Já sabemos como obter o valor de uma célula, para obter os valores de um intervalo de células, como certas linhas ou colunas, só precisamos usar instruções de loop para iterar pelas células e depois extraí-las uma por uma. As etapas para ler dados de um intervalo de células do Excel em Python são as seguintes.
- Instanciar classe de pasta de trabalho
- Carregue um documento Excel usando o método LoadFromFile.
- Obtenha uma planilha específica usando a propriedade Workbook.Worksheets[index].
- Obtenha um intervalo de células específico usando a propriedade Worksheet.Range.
- Use instruções de loop for para recuperar cada célula no intervalo e obter o valor de uma célula específica usando a propriedade CellRange.Value
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a cell range
cellRange = sheet.Range["A2:H5"]
# Iterate through the rows
for i in range(len(cellRange.Rows)):
# Iterate through the columns
for j in range(len(cellRange.Rows[i].Columns)):
# Get data of a specific cell
print(cellRange[i + 2, j + 1].Value + " ", end='')
print("")
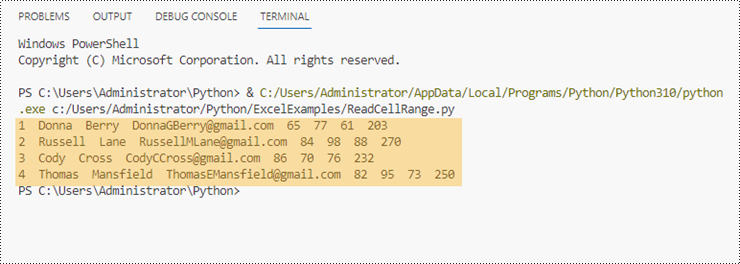
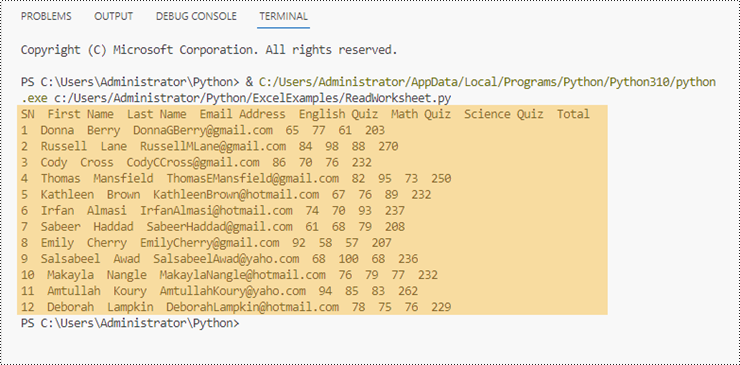
Leia dados de uma planilha do Excel em Python
Spire.XLS for Python oferece a propriedade Worksheet.AllocatedRange para obter automaticamente o intervalo de células que contém dados de uma planilha. Em seguida, percorremos as células dentro do intervalo de células, em vez de toda a planilha, e recuperamos os valores das células um por um. A seguir estão as etapas para ler dados de uma planilha do Excel em Python.
- Instanciar classe de pasta de trabalho.
- Carregue um documento Excel usando o método LoadFromFile.
- Obtenha uma planilha específica usando a propriedade Workbook.Worksheets[index].
- Obtenha o intervalo de células que contém dados da planilha usando a propriedade Worksheet.AllocatedRange.
- Use instruções de loop for para recuperar cada célula no intervalo e obter o valor de uma célula específica usando a propriedade CellRange.Value.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get the first worksheet
sheet = wb.Worksheets[0]
# Get the cell range containing data
locatedRange = sheet.AllocatedRange
# Iterate through the rows
for i in range(len(sheet.Rows)):
# Iterate through the columns
for j in range(len(locatedRange.Rows[i].Columns)):
# Get data of a specific cell
print(locatedRange[i + 1, j + 1].Value + " ", end='')
print("")
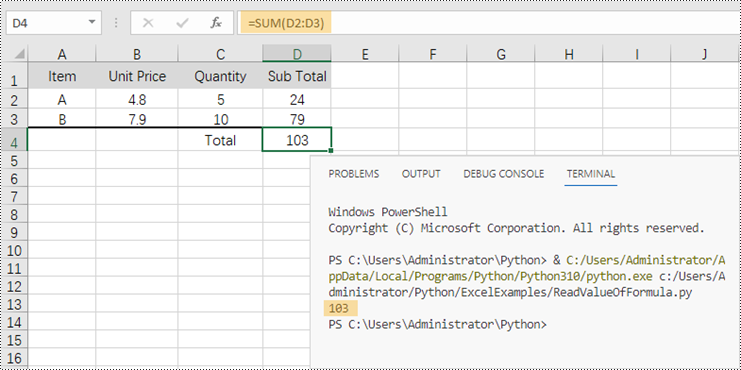
Leia o valor em vez da fórmula em uma célula em Python
Conforme mencionado anteriormente, quando uma célula contém uma fórmula, a propriedade CellRange.Value retorna a própria fórmula, não o valor da fórmula. Se quisermos obter o valor, precisamos usar o método str(CellRange.FormulaValue). A seguir estão as etapas para ler o valor em vez da fórmula em uma célula do Excel em Python.
- Instanciar classe de pasta de trabalho.
- Carregue um documento Excel usando o método LoadFromFile.
- Obtenha uma planilha específica usando a propriedade Workbook.Worksheets[index].
- Obtenha uma célula específica usando a propriedade Worksheet.Range.
- Determine se a célula possui fórmula usando a propriedade CellRange.HasFormula.
- Obtenha o valor da fórmula da célula usando o método str(CellRange.FormulaValue).
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Formula.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D4"]
# Determine if the cell has formula
if(certainCell.HasFormula):
# Get the formula value of the cell
print(str(certainCell.FormulaValue))
Conclusão
Nesta postagem do blog, aprendemos como ler dados de células, regiões de células e planilhas em Python com a ajuda do Spire.XLS para API Python. Também discutimos como determinar se uma célula possui uma fórmula e como obter o valor da fórmula. Esta biblioteca suporta a extração de muitos outros elementos no Excel, como imagens, hiperlinks e objetos OEL. Confira nossa documentação online para mais tutoriais. Se você tiver alguma dúvida, entre em contato conosco por e-mail ou no fórum.
Чтение файлов Excel с помощью Python
Оглавление
Установить с помощью Пипа
pip install Spire.XLS
Ссылки по теме
Файлы Excel (электронные таблицы) используются людьми во всем мире для организации, анализа и хранения табличных данных. Из-за своей популярности разработчики часто сталкиваются с ситуациями, когда им необходимо извлечь данные из Excel или создать отчеты в формате Excel. Быть способным читать файлы Excel с помощью Python открывает обширный набор возможностей для обработки и автоматизации данных. В этой статье вы узнаете, как читать данные (текстовые или числовые значения) из ячейки, диапазона ячеек или всего листа с помощью библиотеки Spire.XLS for Python.
- Чтение данных конкретной ячейки в Python
- Чтение данных из диапазона ячеек в Python
- Чтение данных из листа Excel в Python
- Чтение значения вместо формулы в ячейке в Python
Библиотека Python для чтения Excel
Spire.XLS for Python — это надежная библиотека Python корпоративного уровня для создания, записи, чтения и редактирование Excel документы (XLS, XLSX, XLSB, XLSM, ODS) в приложении Python. Он предоставляет полный набор интерфейсов, классов и свойств, которые позволяют программистам читать и написать Excel файлы с легкостью. В частности, доступ к ячейке в книге можно получить с помощью свойства Worksheet.Range, а значение ячейки можно получить с помощью свойства CellRange.Value.
Библиотеку легко установить, выполнив следующую команду pip. Если вы хотите вручную импортировать необходимые зависимости, см Как установить Spire.XLS for Python в VS Code
pip install Spire.XLS
Классы и свойства в Spire.XLS for Python API
- Класс Workbook : представляет модель книги Excel, которую можно использовать для создания книги с нуля или загрузки существующего документа Excel и внесения в него изменений.
- Класс Worksheet: представляет лист в книге.
- Класс CellRange: представляет определенную ячейку или диапазон ячеек в книге.
- Свойство Worksheet.Range: получает ячейку или диапазон и возвращает объект класса CellRange.
- Свойство Worksheet.AllocatedRange: получает диапазон ячеек, содержащий данные, и возвращает объект класса CellRange.
- Свойство CellRange.Value: получает числовое или текстовое значение ячейки. Но если в ячейке есть формула, это свойство возвращает формулу вместо результата формулы.
Чтение данных конкретной ячейки в Python
С помощью Spire.XLS for Python вы можете легко получить значение определенной ячейки, используя свойство CellRange.Value. Шаги для чтения данных конкретной ячейки Excel в Python следующие.
- Создание экземпляра класса рабочей книги
- Загрузите документ Excel с помощью метода LoadFromFile.
- Получите конкретный лист, используя свойство Workbook.Worksheets[index].
- Получите конкретную ячейку, используя свойство Worksheet.Range.
- Получите значение ячейки, используя свойство CellRange.Value.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D9"]
# Get the value of the cell
print("D9 has the value: " + certainCell.Value)
Чтение данных из диапазона ячеек в Python
Мы уже знаем, как получить значение ячейки, чтобы получить значения диапазона ячеек, например определенных строк или столбцов, нам просто нужно использовать операторы цикла для перебора ячеек, а затем извлекать их одну за другой. Шаги для чтения данных из диапазона ячеек Excel в Python следующие.
- Создание экземпляра класса рабочей книги.
- Загрузите документ Excel с помощью метода LoadFromFile.
- Получите конкретный лист, используя свойство Workbook.Worksheets[index].
- Получите определенный диапазон ячеек, используя свойство Worksheet.Range.
- Используйте операторы цикла for для получения каждой ячейки в диапазоне и получения значения определенной ячейки с помощью свойства CellRange.Value.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a cell range
cellRange = sheet.Range["A2:H5"]
# Iterate through the rows
for i in range(len(cellRange.Rows)):
# Iterate through the columns
for j in range(len(cellRange.Rows[i].Columns)):
# Get data of a specific cell
print(cellRange[i + 2, j + 1].Value + " ", end='')
print("")
Чтение данных из листа Excel в Python
Spire.XLS for Python предлагает свойство Worksheet.AllocatedRange для автоматического получения диапазона ячеек, содержащего данные из рабочего листа. Затем мы просматриваем ячейки внутри диапазона ячеек, а не по всему листу, и извлекаем значения ячеек одно за другим. Ниже приведены шаги для чтения данных из листа Excel в Python.
- Создание экземпляра класса рабочей книги.
- Загрузите документ Excel с помощью метода LoadFromFile.
- Получите конкретный лист, используя свойство Workbook.Worksheets[index].
- Получите диапазон ячеек, содержащий данные, из листа, используя свойство Worksheet.AllocatedRange.
- Используйте операторы цикла for для получения каждой ячейки в диапазоне и получения значения определенной ячейки с помощью свойства CellRange.Value.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get the first worksheet
sheet = wb.Worksheets[0]
# Get the cell range containing data
locatedRange = sheet.AllocatedRange
# Iterate through the rows
for i in range(len(sheet.Rows)):
# Iterate through the columns
for j in range(len(locatedRange.Rows[i].Columns)):
# Get data of a specific cell
print(locatedRange[i + 1, j + 1].Value + " ", end='')
print("")
Чтение значения вместо формулы в ячейке в Python
Как упоминалось ранее, когда ячейка содержит формулу, свойство CellRange.Value возвращает саму формулу, а не ее значение. Если мы хотим получить значение, нам нужно использовать метод str(CellRange.FormulaValue). Ниже приведены шаги для чтения значения, а не формулы в ячейке Excel в Python.
- Создание экземпляра класса рабочей книги.
- Загрузите документ Excel с помощью метода LoadFromFile.
- Получите конкретный лист, используя свойство Workbook.Worksheets[index].
- Получите конкретную ячейку, используя свойство Worksheet.Range.
- Определите, содержит ли ячейка формулу, используя свойство CellRange.HasFormula.
- Получите значение формулы ячейки, используя метод str(CellRange.FormulaValue).
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Formula.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D4"]
# Determine if the cell has formula
if(certainCell.HasFormula):
# Get the formula value of the cell
print(str(certainCell.FormulaValue))
Заключение
В этой записи блога мы узнали, как считывать данные из ячеек, областей ячеек и листов в Python с помощью API Spire.XLS для Python. Мы также обсудили, как определить, содержит ли ячейка формулу, и как получить значение формулы. Эта библиотека поддерживает извлечение многих других элементов Excel, таких как изображения, гиперссылки и объекты OEL. Ознакомьтесь с нашей онлайн-документацией для получения дополнительных руководств. Если у вас есть какие-либо вопросы, пожалуйста, свяжитесь с нами по электронной почте или на форуме.
Leer archivos de Excel con Python
Tabla de contenido
Instalar con Pip
pip install Spire.XLS
enlaces relacionados
Los archivos de Excel (hojas de cálculo) son utilizados por personas de todo el mundo para organizar, analizar y almacenar datos tabulares. Debido a su popularidad, los desarrolladores frecuentemente se encuentran con situaciones en las que necesitan extraer datos de Excel o crear informes en formato Excel. Siendo capaz de leer archivos de Excel con Python abre un amplio conjunto de posibilidades para el procesamiento y la automatización de datos. En este artículo, aprenderá cómo leer datos (texto o valores numéricos) de una celda, un rango de celdas o una hoja de trabajo completa utilizando la biblioteca Spire.XLS for Python.
- Leer datos de una celda particular en Python
- Leer datos de un rango de celdas en Python
- Leer datos de una hoja de cálculo de Excel en Python
- Leer valor en lugar de fórmula en una celda en Python
Biblioteca Python para leer Excel
Spire.XLS for Python es una biblioteca Python confiable de nivel empresarial para crear, escribir, leer y editando excel documentos (XLS, XLSX, XLSB, XLSM, ODS) en una aplicación Python. Proporciona un conjunto completo de interfaces, clases y propiedades que permiten a los programadores leer y escribir sobresalir archivos con facilidad. Específicamente, se puede acceder a una celda de un libro mediante la propiedad Worksheet.Range y se puede obtener el valor de la celda mediante la propiedad CellRange.Value.
La biblioteca es fácil de instalar ejecutando el siguiente comando pip. Si desea importar manualmente las dependencias necesarias, consulte Cómo instalar Spire.XLS for Python en VS Code
pip install Spire.XLS
Clases y propiedades en Spire.XLS para la API de Python
- Clase de libro de trabajo: representa un modelo de libro de trabajo de Excel, que puede usar para crear un libro de trabajo desde cero o cargar un documento de Excel existente y realizar modificaciones en él.
- Clase de hoja de trabajo: representa una hoja de trabajo en un libro de trabajo.
- Clase CellRange: representa una celda específica o un rango de celdas en un libro.
- Propiedad Worksheet.Range: obtiene una celda o un rango y devuelve un objeto de la clase CellRange.
- Propiedad Worksheet.AllocatedRange: obtiene el rango de celdas que contiene datos y devuelve un objeto de la clase CellRange.
- Propiedad CellRange.Value: obtiene el valor numérico o el valor de texto de una celda. Pero si una celda tiene una fórmula, esta propiedad devuelve la fórmula en lugar del resultado de la fórmula.
Leer datos de una celda particular en Python
Con Spire.XLS for Python, puede obtener fácilmente el valor de una determinada celda utilizando la propiedad CellRange.Value. Los pasos para leer datos de una celda particular de Excel en Python son los siguientes.
- Crear instancias de la clase de libro de trabajo
- Cargue un documento de Excel utilizando el método LoadFromFile.
- Obtenga una hoja de trabajo específica usando la propiedad Workbook.Worksheets[index].
- Obtenga una celda específica usando la propiedad Worksheet.Range.
- Obtenga el valor de la celda usando la propiedad CellRange.Value
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D9"]
# Get the value of the cell
print("D9 has the value: " + certainCell.Value)
Leer datos de un rango de celdas en Python
Ya sabemos cómo obtener el valor de una celda, para obtener los valores de un rango de celdas, como ciertas filas o columnas, solo necesitamos usar declaraciones de bucle para recorrer las celdas y luego extraerlas una por una. Los pasos para leer datos de un rango de celdas de Excel en Python son los siguientes.
- Crear instancias de la clase de libro de trabajo
- Cargue un documento de Excel utilizando el método LoadFromFile.
- Obtenga una hoja de trabajo específica usando la propiedad Workbook.Worksheets[index].
- Obtenga un rango de celdas específico usando la propiedad Worksheet.Range.
- Utilice declaraciones de bucle for para recuperar cada celda del rango y obtener el valor de una celda específica utilizando la propiedad CellRange.Value
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a cell range
cellRange = sheet.Range["A2:H5"]
# Iterate through the rows
for i in range(len(cellRange.Rows)):
# Iterate through the columns
for j in range(len(cellRange.Rows[i].Columns)):
# Get data of a specific cell
print(cellRange[i + 2, j + 1].Value + " ", end='')
print("")
Leer datos de una hoja de cálculo de Excel en Python
Spire.XLS for Python ofrece la propiedad Worksheet.AllocatedRange para obtener automáticamente el rango de celdas que contiene datos de una hoja de trabajo. Luego, recorremos las celdas dentro del rango de celdas en lugar de toda la hoja de trabajo y recuperamos los valores de las celdas uno por uno. Los siguientes son los pasos para leer datos de una hoja de cálculo de Excel en Python.
- Crear instancias de la clase de libro de trabajo.
- Cargue un documento de Excel utilizando el método LoadFromFile.
- Obtenga una hoja de trabajo específica usando la propiedad Workbook.Worksheets[index].
- Obtenga el rango de celdas que contiene datos de la hoja de trabajo usando la propiedad Worksheet.AllocatedRange.
- Utilice declaraciones de bucle for para recuperar cada celda del rango y obtener el valor de una celda específica utilizando la propiedad CellRange.Value.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get the first worksheet
sheet = wb.Worksheets[0]
# Get the cell range containing data
locatedRange = sheet.AllocatedRange
# Iterate through the rows
for i in range(len(sheet.Rows)):
# Iterate through the columns
for j in range(len(locatedRange.Rows[i].Columns)):
# Get data of a specific cell
print(locatedRange[i + 1, j + 1].Value + " ", end='')
print("")
Leer valor en lugar de fórmula en una celda en Python
Como se mencionó anteriormente, cuando una celda contiene una fórmula, la propiedad CellRange.Value devuelve la fórmula en sí, no el valor de la fórmula. Si queremos obtener el valor, debemos usar el método str(CellRange.FormulaValue). Los siguientes son los pasos para leer un valor en lugar de una fórmula en una celda de Excel en Python.
- Crear instancias de la clase de libro de trabajo.
- Cargue un documento de Excel utilizando el método LoadFromFile.
- Obtenga una hoja de trabajo específica usando la propiedad Workbook.Worksheets[index].
- Obtenga una celda específica usando la propiedad Worksheet.Range.
- Determine si la celda tiene fórmula usando la propiedad CellRange.HasFormula.
- Obtenga el valor de la fórmula de la celda usando el método str(CellRange.FormulaValue).
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Formula.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D4"]
# Determine if the cell has formula
if(certainCell.HasFormula):
# Get the formula value of the cell
print(str(certainCell.FormulaValue))
Conclusión
En esta publicación de blog, aprendimos cómo leer datos de celdas, regiones de celdas y hojas de trabajo en Python con la ayuda de Spire.XLS para la API de Python. También discutimos cómo determinar si una celda tiene una fórmula y cómo obtener el valor de la fórmula. Esta biblioteca admite la extracción de muchos otros elementos en Excel, como imágenes, hipervínculos y objetos OEL. Consulte nuestra documentación en línea para obtener más tutoriales. Si tiene alguna pregunta, comuníquese con nosotros por correo electrónico o en el foro.
Python으로 Excel 파일 읽기
목차
핍으로 설치
pip install Spire.XLS
관련된 링크들
Excel 파일(스프레드시트)은 전 세계 사람들이 표 형식의 데이터를 구성, 분석 및 저장하는 데 사용됩니다. 인기가 높기 때문에 개발자는 Excel에서 데이터를 추출하거나 Excel 형식으로 보고서를 작성해야 하는 상황에 자주 직면합니다. 를 할 수있는 Python으로 Excel 파일 읽기 데이터 처리 및 자동화를 위한 포괄적인 가능성을 열어줍니다. 이 기사에서는 다음 방법을 배웁니다. 셀, 셀 범위 또는 전체 워크시트에서 데이터(텍스트 또는 숫자 값)를 읽습니다 을 사용하여 Spire.XLS for Python 도서관.
Excel 읽기를 위한 Python 라이브러리
Spire.XLS for Python는 생성, 쓰기, 읽기 및 작업을 위한 신뢰할 수 있는 엔터프라이즈급 Python 라이브러리입니다 엑셀 편집 Python 응용 프로그램의 문서(XLS, XLSX, XLSB, XLSM, ODS). 이는 프로그래머가 읽고 사용할 수 있는 포괄적인 인터페이스, 클래스 및 속성 세트를 제공합니다 엑셀을 쓰다 파일을 쉽게. 특히 통합 문서의 셀은 Worksheet.Range 속성을 사용하여 액세스할 수 있으며 셀 값은 CellRange.Value 속성을 사용하여 얻을 수 있습니다.
라이브러리는 다음 pip 명령을 실행하여 쉽게 설치할 수 있습니다. 필요한 종속성을 수동으로 가져오려면 다음을 참조하세요 VS Code에서 Python용 Spire.XLS를 설치하는 방법
pip install Spire.XLS
Python API용 Spire.XLS의 클래스 및 속성
- 통합 문서 클래스: 처음부터 통합 문서를 만들거나 기존 Excel 문서를 로드하고 수정하는 데 사용할 수 있는 Excel 통합 문서 모델을 나타냅니다.
- Worksheet 클래스: 통합 문서의 워크시트를 나타냅니다.
- CellRange 클래스: 통합 문서의 특정 셀 또는 셀 범위를 나타냅니다.
- Worksheet.Range 속성: 셀 또는 범위를 가져오고 CellRange 클래스의 개체를 반환합니다.
- Worksheet.AllocatedRange 속성: 데이터가 포함된 셀 범위를 가져오고 CellRange 클래스의 개체를 반환합니다.
- CellRange.Value 속성: 셀의 숫자 값이나 텍스트 값을 가져옵니다. 그러나 셀에 수식이 있는 경우 이 속성은 수식 결과 대신 수식을 반환합니다.
Python에서 특정 셀의 데이터 읽기
Spire.XLS for Python를 사용하면 CellRange.Value 속성을 사용하여 특정 셀의 값을 쉽게 얻을 수 있습니다. Python에서 특정 Excel 셀의 데이터를 읽는 단계는 다음과 같습니다.
- 통합 문서 클래스 인스턴스화
- LoadFromFile 메서드를 사용하여 Excel 문서를 로드합니다.
- Workbook.Worksheets[index] 속성을 사용하여 특정 워크시트를 가져옵니다.
- Worksheet.Range 속성을 사용하여 특정 셀을 가져옵니다.
- CellRange.Value 속성을 사용하여 셀 값을 가져옵니다.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D9"]
# Get the value of the cell
print("D9 has the value: " + certainCell.Value)
Python의 셀 범위에서 데이터 읽기
우리는 셀의 값을 얻는 방법, 즉 특정 행이나 열과 같은 셀 범위의 값을 얻는 방법을 이미 알고 있습니다. 루프 문을 사용하여 셀을 반복한 다음 하나씩 추출하면 됩니다. Python에서 Excel 셀 범위의 데이터를 읽는 단계는 다음과 같습니다.
- 통합 문서 클래스 인스턴스화.
- LoadFromFile 메서드를 사용하여 Excel 문서를 로드합니다.
- Workbook.Worksheets[index] 속성을 사용하여 특정 워크시트를 가져옵니다.
- Worksheet.Range 속성을 사용하여 특정 셀 범위를 가져옵니다.
- for 루프 문을 사용하여 범위의 각 셀을 검색하고 CellRange.Value 속성을 사용하여 특정 셀의 값을 가져옵니다.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a cell range
cellRange = sheet.Range["A2:H5"]
# Iterate through the rows
for i in range(len(cellRange.Rows)):
# Iterate through the columns
for j in range(len(cellRange.Rows[i].Columns)):
# Get data of a specific cell
print(cellRange[i + 2, j + 1].Value + " ", end='')
print("")
Python에서 Excel 워크시트의 데이터 읽기
Spire.XLS for Python는 워크시트의 데이터가 포함된 셀 범위를 자동으로 얻기 위해 Worksheet.AllocationRange 속성을 제공합니다. 그런 다음 전체 워크시트가 아닌 셀 범위 내의 셀을 순회하여 셀 값을 하나씩 검색합니다. 다음은 Python에서 Excel 워크시트의 데이터를 읽는 단계입니다.
- 통합 문서 클래스 인스턴스화.
- LoadFromFile 메서드를 사용하여 Excel 문서를 로드합니다.
- Workbook.Worksheets[index] 속성을 사용하여 특정 워크시트를 가져옵니다.
- Worksheet.AllocationRange 속성을 사용하여 워크시트의 데이터가 포함된 셀 범위를 가져옵니다.
- for 루프 문을 사용하여 범위의 각 셀을 검색하고 CellRange.Value 속성을 사용하여 특정 셀의 값을 가져옵니다.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get the first worksheet
sheet = wb.Worksheets[0]
# Get the cell range containing data
locatedRange = sheet.AllocatedRange
# Iterate through the rows
for i in range(len(sheet.Rows)):
# Iterate through the columns
for j in range(len(locatedRange.Rows[i].Columns)):
# Get data of a specific cell
print(locatedRange[i + 1, j + 1].Value + " ", end='')
print("")
Python의 셀에서 수식 대신 값 읽기
앞에서 언급한 것처럼 셀에 수식이 포함된 경우 CellRange.Value 속성은 수식 값이 아닌 수식 자체를 반환합니다. 값을 얻으려면 str(CellRange.FormulaValue) 메서드를 사용해야 합니다. 다음은 Python에서 Excel 셀의 수식이 아닌 값을 읽는 단계입니다.
- 통합 문서 클래스 인스턴스화.
- LoadFromFile 메서드를 사용하여 Excel 문서를 로드합니다.
- Workbook.Worksheets[index] 속성을 사용하여 특정 워크시트를 가져옵니다.
- Worksheet.Range 속성을 사용하여 특정 셀을 가져옵니다.
- CellRange.HasFormula 속성을 사용하여 셀에 수식이 있는지 확인합니다.
- str(CellRange.FormulaValue) 메서드를 사용하여 셀의 수식 값을 가져옵니다.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Formula.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D4"]
# Determine if the cell has formula
if(certainCell.HasFormula):
# Get the formula value of the cell
print(str(certainCell.FormulaValue))
결론
이 블로그 게시물에서는 Python API용 Spire.XLS를 사용하여 Python에서 셀, 셀 영역 및 워크시트의 데이터를 읽는 방법을 배웠습니다. 또한 셀에 수식이 있는지 확인하는 방법과 수식의 값을 얻는 방법도 논의했습니다. 이 라이브러리는 이미지와 같은 Excel의 다른 많은 요소 추출을 지원합니다. 하이퍼링크 및 OEL 객체. 우리를 확인해보세요 온라인 문서 더 많은 튜토리얼을 보려면. 질문이 있으시면 다음으로 문의해 주세요 이메일 이나 포럼에서.
Leggere file Excel con Python
Sommario
Installa con Pip
pip install Spire.XLS
Link correlati
I file Excel (fogli di calcolo) vengono utilizzati da persone in tutto il mondo per organizzare, analizzare e archiviare dati tabulari. A causa della loro popolarità, gli sviluppatori incontrano spesso situazioni in cui devono estrarre dati da Excel o creare report in formato Excel. Essere capace di leggere file Excel con Python apre una serie completa di possibilità per l'elaborazione e l'automazione dei dati. In questo articolo imparerai come farlo leggere dati (valori di testo o numerici) da una cella, un intervallo di celle o un intero foglio di lavoro utilizzando la libreria Spire.XLS for Python library.
- Leggi i dati di una cella particolare in Python
- Leggi i dati da un intervallo di celle in Python
- Leggere i dati da un foglio di lavoro Excel in Python
- Leggi il valore anziché la formula in una cella in Python
Libreria Python per leggere Excel
Spire.XLS for Python è una libreria Python affidabile di livello aziendale per creare, scrivere, leggere e modifica Excel documenti (XLS, XLSX, XLSB, XLSM, ODS) in un'applicazione Python. Fornisce un set completo di interfacce, classi e proprietà che consentono ai programmatori di leggere e scrivere Excel file con facilità. Nello specifico, è possibile accedere a una cella in una cartella di lavoro utilizzando la proprietà Worksheet.Range e il valore della cella può essere ottenuto utilizzando la proprietà CellRange.Value.
La libreria è facile da installare eseguendo il seguente comando pip. Se desideri importare manualmente le dipendenze necessarie, fai riferimento a Come installare Spire.XLS for Python in VS Code
pip install Spire.XLS
Classi e proprietà in Spire.XLS per l'API Python
- Classe cartella di lavoro: rappresenta un modello di cartella di lavoro Excel, che è possibile utilizzare per creare una cartella di lavoro da zero o caricare un documento Excel esistente e apportarvi modifiche.
- Classe del foglio di lavoro: rappresenta un foglio di lavoro in una cartella di lavoro.
- Classe CellRange: rappresenta una cella specifica o un intervallo di celle in una cartella di lavoro.
- Proprietà Worksheet.Rangeottiene una cella o un intervallo e restituisce un oggetto della classe CellRange.
- ProprietàWorksheet.AllocatedRange: ottiene l'intervallo di celle contenente dati e restituisce un oggetto della classe CellRange.
- ProprietàCellRange.Value: ottiene il valore numerico o il valore testo di una cella. Ma se una cella contiene una formula, questa proprietà restituisce la formula anziché il risultato della formula.
Leggi i dati di una cella particolare in Python
Con Spire.XLS for Python, puoi ottenere facilmente il valore di una determinata cella utilizzando la proprietà CellRange.Value. I passaggi per leggere i dati di una particolare cella Excel in Python sono i seguenti.
- Crea un'istanza della classe Workbook
- Carica un documento Excel utilizzando il metodo LoadFromFile.
- Ottieni un foglio di lavoro specifico utilizzando la proprietà Workbook.Worksheets[index].
- Ottieni una cella specifica utilizzando la proprietà Worksheet.Range.
- Ottieni il valore della cella utilizzando la proprietà CellRange.Value
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D9"]
# Get the value of the cell
print("D9 has the value: " + certainCell.Value)
Leggi i dati da un intervallo di celle in Python
Sappiamo già come ottenere il valore di una cella, per ottenere i valori di un intervallo di celle, come determinate righe o colonne, dobbiamo solo utilizzare le istruzioni di loop per scorrere le celle e quindi estrarle una per una. I passaggi per leggere i dati da un intervallo di celle Excel in Python sono i seguenti.
- Crea un'istanza della classe Workbook
- Carica un documento Excel utilizzando il metodo LoadFromFile.
- Ottieni un foglio di lavoro specifico utilizzando la proprietà Workbook.Worksheets[index].
- Ottieni un intervallo di celle specifico utilizzando la proprietà Worksheet.Range.
- Utilizzare le istruzioni del ciclo for per recuperare ogni cella nell'intervallo e ottenere il valore di una cella specifica utilizzando la proprietà CellRange.Value
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a cell range
cellRange = sheet.Range["A2:H5"]
# Iterate through the rows
for i in range(len(cellRange.Rows)):
# Iterate through the columns
for j in range(len(cellRange.Rows[i].Columns)):
# Get data of a specific cell
print(cellRange[i + 2, j + 1].Value + " ", end='')
print("")
Leggere i dati da un foglio di lavoro Excel in Python
Spire.XLS for Python offre la proprietà Worksheet.AllocatedRange per ottenere automaticamente l'intervallo di celle che contiene i dati da un foglio di lavoro. Quindi, attraversiamo le celle all'interno dell'intervallo di celle anziché l'intero foglio di lavoro e recuperiamo i valori delle celle uno per uno. Di seguito sono riportati i passaggi per leggere i dati da un foglio di lavoro Excel in Python.
- Crea un'istanza della classe Workbook.
- Carica un documento Excel utilizzando il metodo LoadFromFile.
- Ottieni un foglio di lavoro specifico utilizzando la proprietà Workbook.Worksheets[index].
- Ottieni l'intervallo di celle contenente i dati dal foglio di lavoro utilizzando la proprietà Worksheet.AllocatedRange.
- Utilizzare le istruzioni del ciclo for per recuperare ogni cella nell'intervallo e ottenere il valore di una cella specifica utilizzando la proprietà CellRange.Value.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an existing Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Data.xlsx");
# Get the first worksheet
sheet = wb.Worksheets[0]
# Get the cell range containing data
locatedRange = sheet.AllocatedRange
# Iterate through the rows
for i in range(len(sheet.Rows)):
# Iterate through the columns
for j in range(len(locatedRange.Rows[i].Columns)):
# Get data of a specific cell
print(locatedRange[i + 1, j + 1].Value + " ", end='')
print("")
Leggi il valore anziché la formula in una cella in Python
Come accennato in precedenza, quando una cella contiene una formula, la proprietà CellRange.Value restituisce la formula stessa, non il valore della formula. Se vogliamo ottenere il valore, dobbiamo utilizzare il metodo str(CellRange.FormulaValue). Di seguito sono riportati i passaggi per leggere il valore anziché la formula in una cella di Excel in Python.
- Crea un'istanza della classe Workbook.
- Carica un documento Excel utilizzando il metodo LoadFromFile.
- Ottieni un foglio di lavoro specifico utilizzando la proprietà Workbook.Worksheets[index].
- Ottieni una cella specifica utilizzando la proprietà Worksheet.Range.
- Determina se la cella ha una formula utilizzando la proprietà CellRange.HasFormula.
- Ottieni il valore della formula della cella utilizzando il metodo str(CellRange.FormulaValue).
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
wb = Workbook()
# Load an Excel file
wb.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Formula.xlsx");
# Get a specific worksheet
sheet = wb.Worksheets[0]
# Get a specific cell
certainCell = sheet.Range["D4"]
# Determine if the cell has formula
if(certainCell.HasFormula):
# Get the formula value of the cell
print(str(certainCell.FormulaValue))
Conclusione
In questo post del blog, abbiamo imparato come leggere i dati da celle, regioni di celle e fogli di lavoro in Python con l'aiuto dell'API Spire.XLS for Python. Abbiamo anche discusso come determinare se una cella ha una formula e come ottenere il valore della formula. Questa libreria supporta l'estrazione di molti altri elementi in Excel come immagini, collegamenti ipertestuali e oggetti OEL. Consulta la nostra documentazione online per ulteriori tutorial. Se avete domande, contattateci via e-mail o sul forum.