목차
핍으로 설치
pip install Spire.PDF
관련된 링크들
오늘날의 디지털 시대에 PDF 문서에서 정보를 빠르고 효율적으로 추출하는 능력은 다양한 산업과 전문가에게 매우 중요합니다. 연구자, 데이터 분석가 또는 단순히 대량의 PDF 파일을 처리하는 경우 PDF를 편집 가능한 텍스트 형식으로 변환하면 귀중한 시간과 노력을 절약할 수 있습니다. 다재다능하고 강력한 프로그래밍 언어인 Python이 변환을 위한 광범위한 기능을 통해 구출되는 곳입니다 Python에서 PDF를 텍스트로.

이번 글에서는 사용법을 알아보겠습니다 PDF를 텍스트로 변환하는 Python 변환하여 PDF 파일 처리에 Python의 강력한 기능을 활용합니다. 이 문서에는 다음 주제가 포함되어 있습니다.
- PDF를 텍스트로 변환하기 위한 Python API
- Python에서 PDF를 텍스트로 변환하기 위한 가이드
- 레이아웃을 유지하지 않고 PDF를 텍스트로 변환하는 Python
- PDF를 텍스트로 변환하고 레이아웃을 유지하는 Python
- 지정된 PDF 페이지 영역을 텍스트로 변환하는 Python
- Python에서 PDF를 텍스트로 변환하는 API에 대한 무료 라이센스 받기
- Python을 사용한 PDF 처리에 대해 자세히 알아보기
PDF를 텍스트로 변환하기 위한 Python API
PDF를 텍스트로 변환하기 위해 Python을 사용하려면 PDF 처리 API인 Spire.PDF for Python가 필요합니다. 이 Python 라이브러리는 Python 프로그램에서 PDF 문서 조작을 위해 설계되었으며, Python 프로그램에 다양한 PDF 처리 기능을 제공합니다.
우리는 할 수 있다 Spire.PDF for Python 다운로드 프로젝트에 추가하거나 다음 코드를 사용하여 PyPI를 통해 간단히 설치하세요.
pip install Spire.PDF
Python에서 PDF를 텍스트로 변환하기 위한 가이드
Python을 사용하여 PDF를 텍스트로 변환하기 전에 Python이 제공할 수 있는 주요 이점을 살펴보겠습니다.
- 편집 가능성: PDF를 텍스트로 변환하면 대부분의 장치에서 텍스트 파일을 열고 편집할 수 있으므로 문서를 더 쉽게 편집할 수 있습니다.
- 접근성: 일반적으로 텍스트 파일은 PDF보다 접근성이 더 높습니다. 데스크톱이든 휴대폰이든 텍스트 파일을 장치에서 쉽게 볼 수 있습니다.
- 다른 애플리케이션과 통합: 텍스트 파일은 다양한 애플리케이션 및 작업 흐름에 원활하게 통합될 수 있습니다.
Python에서 PDF 문서를 텍스트 파일로 변환하는 단계:
- Spire.PDF for Python를 설치합니다.
- 모듈을 가져옵니다.
- PdfDocument 클래스의 객체를 생성하고 LoadFromFile() 메서드를 사용하여 PDF 파일을 로드합니다.
- PdfTextExtractOptions 클래스의 객체를 생성하고 모든 텍스트 추출, 숨겨진 텍스트 표시, 지정된 영역의 텍스트만 추출, 단순 추출을 포함한 텍스트 추출 옵션을 설정합니다.
- PdfDocument.Pages.get_Item() 메소드를 사용하여 문서에서 페이지를 가져오고 각 페이지를 기반으로 PdfTextExtractor 객체를 생성하여 지정된 옵션과 함께 Extract() 메소드를 사용하여 페이지에서 텍스트를 추출합니다.
- 추출된 텍스트를 텍스트 파일로 저장하고 PdfDocument 개체를 닫습니다.
레이아웃 유지 없이 PDF를 텍스트로 변환하는 Python
PDF에서 텍스트를 추출하기 위해 단순 추출 방법을 사용할 때 프로그램은 빈 영역을 유지하지 않고 각 문자열의 현재 Y 위치를 추적하며 Y 위치가 변경된 경우 출력에 줄 바꿈을 삽입합니다.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
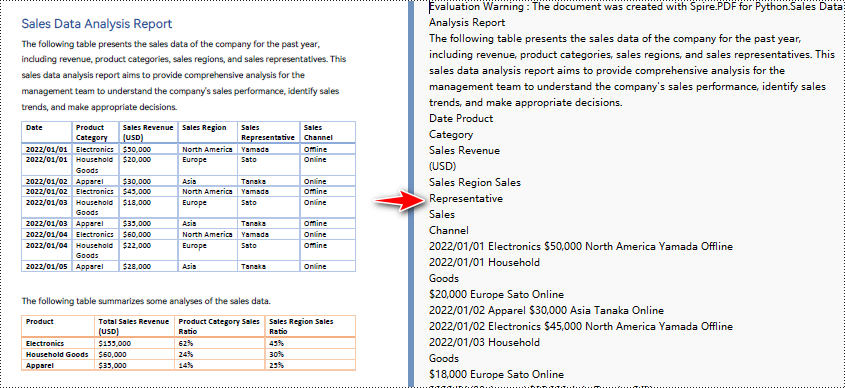
PDF를 텍스트로 변환하고 레이아웃을 유지하는 Python
기본 추출 방법을 사용하여 PDF에서 텍스트를 추출하는 경우 프로그램은 공백을 포함하여 한 줄씩 텍스트를 추출합니다.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
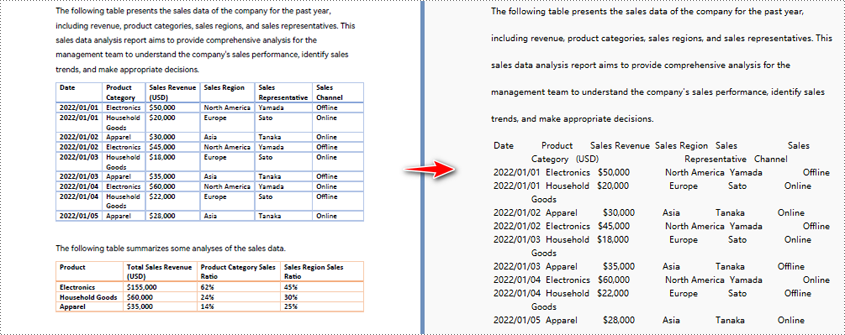
지정된 PDF 페이지 영역을 텍스트로 변환하는 Python
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
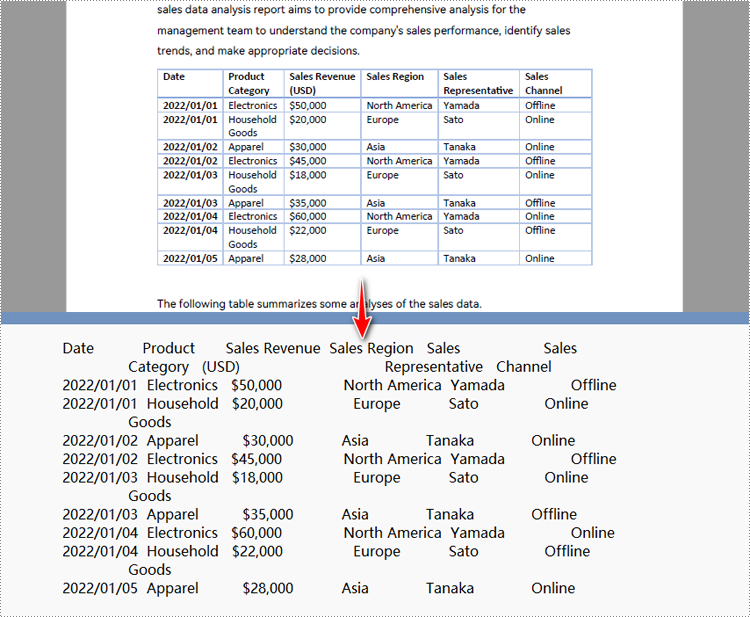
Python에서 PDF를 텍스트로 변환하는 API에 대한 무료 라이센스 받기
사용자는 다음을 수행할 수 있습니다 무료 임시 라이센스를 신청하세요 Spire.PDF for Python를 사용해 보고 Python PDF를 텍스트로 변환하는 기능을 제한 없이 평가해 보세요.
Python을 사용한 PDF 처리에 대해 자세히 알아보기
Python을 사용하여 PDF를 텍스트로 변환하는 것 외에도 다음 소스를 통해 이 API의 더 많은 PDF 처리 기능을 탐색할 수도 있습니다.
결론
이번 블로그 게시물에서 우리는 PDF의 Python을 텍스트로 변환합니다. 운영 단계를 따르고 기사의 코드 예제를 참조하면 빠르게 달성할 수 있습니다 Python에서 PDF를 텍스트로 변환 프로그램들. 또한 이 기사는 PDF 문서를 텍스트 파일로 변환할 때의 이점에 대한 통찰력을 제공합니다. 더 중요한 것은 기사의 참고 자료에서 Python을 사용하여 PDF 문서를 처리하는 방법과 OCR 도구를 통해 이미지 기반 PDF 문서를 텍스트로 변환하는 방법에 대한 추가 지식을 얻을 수 있다는 것입니다. Spire.PDF for Python를 사용하는 동안 문제가 발생하는 경우 다음을 통해 당사 팀에 문의하여 기술 지원을 받을 수 있습니다 Spire.PDF 포럼 또는 이메일.
