
PDF documents have become a ubiquitous format for sharing and archiving data, including textual content and images. Extracting images from PDF documents can serve a multitude of purposes, from repurposing graphical content for presentations or reports to feeding these visuals into machine learning models for analysis and recognition tasks. What’s more, automating this process with Python offers users a streamlined method to efficiently retrieve images from PDF documents for further manipulation.
This article demonstrates how to leverage Spire.PDF for Python to extract images from PDF documents with step-by-step guides and code examples.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
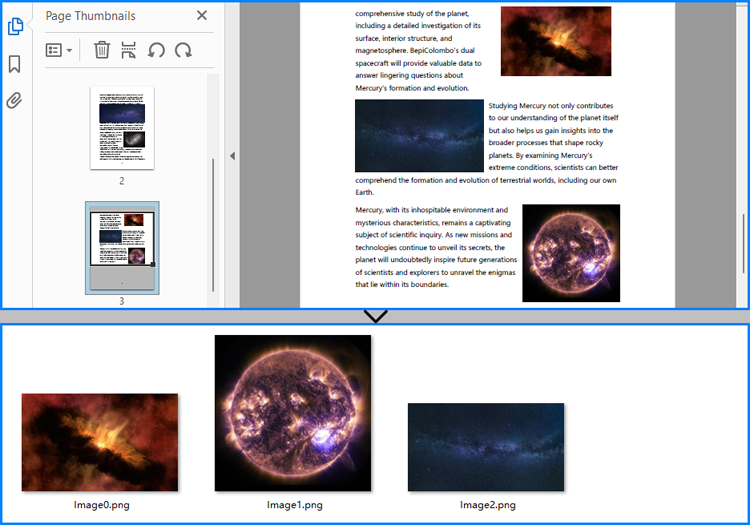
Extract All Images from a PDF Page with Python
Spire.PDF for Python provides the PdfImageHelper class to assist users in working with images in PDF documents, including operations such as deleting, replacing, and retrieving images. Developers can use the PdfImageHelper.GetImagesInfo(page: PdfPageBase) method to get the image information collection of a PDF page, and then use PdfImageInfo.Image.Save() method to save the images to files.
The detailed steps for extracting images from a PDF page are as follows:
- Create an instance of PdfDocument class and load a PDF file using PdfDocument.LoadFromFile() method.
- Create an instance of PdfImageHelper class.
- Get the page for extracting images using PdfDocument.Pages.get_Item() method.
- Get the image information of the page using PdfImageHelper.GetImagesInfo(page: PdfPageBase) method.
- Iterate through the image information items and save the images to files using PdfImageInfo.Image.Save() method.
- Python
from spire.pdf import PdfDocument, PdfImageHelper
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Create a PdfImageHelper instance
imageHelper = PdfImageHelper()
# Get the last page of the document
page = pdf.Pages.get_Item(pdf.Pages.Count - 1)
# Get the image information of the page
imageInfo = imageHelper.GetImagesInfo(page)
# Iterate through the image information
for i in range(0, len(imageInfo)):
# Save images to file
imageInfo[i].Image.Save("output/PDFImages/Image" + str(i) + ".png")
# Release resources
pdf.Dispose()
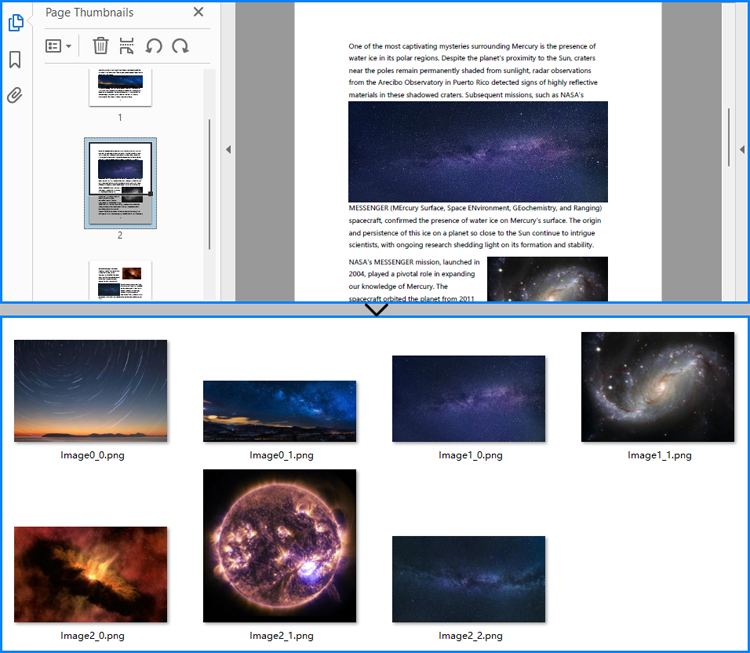
Extract All Images from a PDF Document with Python
Developers can easily extract all images from a PDF document by iterating through each page and retrieving the images contained therein.
The detailed steps for extracting all images from a PDF document are as follows:
- Create an instance of PdfDocument class and load a PDF file using PdfDocument.LoadFromFile() method.
- Create an instance of PdfImageHelper class.
- Iterate through the pages in the document:
- Get the current page using PdfDocument.Pages.get_Item() method.
- Get the image information of the page using PdfImageHelper.GetImagesInfo() method.
- Iterate through the image information items and save the images to files using PdfImageInfo.Image.Save() method.
- Python
from spire.pdf import PdfDocument, PdfImageHelper
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Create a PdfImageHelper instance
imageHelper = PdfImageHelper()
# Iterate through the pages in the document
for i in range(0, pdf.Pages.Count):
# Get the current page
page = pdf.Pages.get_Item(i)
# Get the image information of the page
imageInfo = imageHelper.GetImagesInfo(page)
# Iterate through the image information items
for j in range(0, len(imageInfo)):
# Save the current image to file
imageInfo[j].Image.Save(f"output/PDFImages/Image{i}_{j}.png")
# Release resources
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
