
Retrieving the coordinates of text or images within a PDF document can quickly locate specific elements, which is valuable for extracting content from PDFs. This capability also enables adding annotations, marks, or stamps to the desired locations in a PDF, allowing for more advanced document processing and manipulation.
In this article, you will learn how to get coordinates of the specified text or image in a PDF document using Spire.PDF for Python.
- Get Coordinates of the Specified Text in PDF in Python
- Get Coordinates of the Specified Image in PDF in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Coordinate System in Spire.PDF
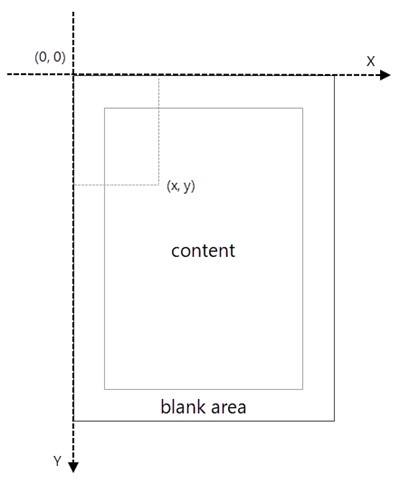
When using Spire.PDF to process an existing PDF document, the origin of the coordinate system is located at the top left corner of the page. The X-axis extends horizontally from the origin to the right, and the Y-axis extends vertically downward from the origin (shown as below).
Get Coordinates of the Specified Text in PDF in Python
To find the coordinates of a specific piece of text within a PDF document, you must first use the PdfTextFinder.Find() method to locate all instances of the target text on a particular page. Once you have found these instances, you can then access the PdfTextFragment.Positions property to retrieve the precise (X, Y) coordinates for each instance of the text.
The steps to get coordinates of the specified text in PDF are as follows.
- Create a PdfDocument object.
- Load a PDF document from a specified path.
- Get a specific page from the document.
- Create a PdfTextFinder object.
- Specify find options through PdfTextFinder.Options property.
- Search for a string within the page using PdfTextFinder.Find() method.
- Get a specific instance of the search results.
- Get X and Y coordinates of the text through PdfTextFragment.Positions[0].X and PdfTextFragment.Positions[0].Y properties.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextFinder object
textFinder = PdfTextFinder(page)
# Specify find options
findOptions = PdfTextFindOptions()
findOptions.Parameter = TextFindParameter.IgnoreCase
findOptions.Parameter = TextFindParameter.WholeWord
textFinder.Options = findOptions
# Search for the string "PRIVACY POLICY" within the page
findResults = textFinder.Find("PRIVACY POLICY")
# Get the first instance of the results
result = findResults[0]
# Get X/Y coordinates of the found text
x = int(result.Positions[0].X)
y = int(result.Positions[0].Y)
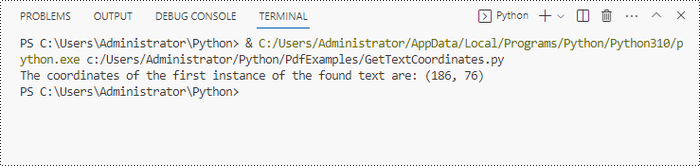
print("The coordinates of the first instance of the found text are:", (x, y))
# Dispose resources
doc.Dispose()
Get Coordinates of the Specified Image in PDF in Python
Spire.PDF for Python provides the PdfImageHelper class, which allows users to extract image details from a specific page within a PDF file. By doing so, you can leverage the PdfImageInfo.Bounds property to retrieve the (X, Y) coordinates of an individual image.
The steps to get coordinates of the specified image in PDF are as follows.
- Create a PdfDocument object.
- Load a PDF document from a specified path.
- Get a specific page from the document.
- Create a PdfImageHelper object.
- Get the image information from the page using PdfImageHelper.GetImagesInfo() method.
- Get X and Y coordinates of a specific image through PdfImageInfo.Bounds property.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Get a specific page
page = doc.Pages[0]
# Create a PdfImageHelper object
imageHelper = PdfImageHelper()
# Get image information from the page
imageInformation = imageHelper.GetImagesInfo(page)
# Get X/Y coordinates of a specific image
x = int(imageInformation[0].Bounds.X)
y = int(imageInformation[0].Bounds.Y)
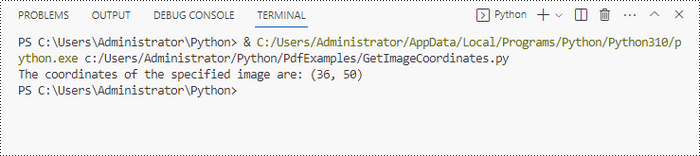
print("The coordinates of the specified image are:", (x, y))
# Dispose resources
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
