Créer des documents Word à partir de modèles avec Python
Table des matières
- Bibliothèque Python pour créer des documents Word à partir de modèles
- Créer des documents Word à partir de modèles en remplaçant le texte d'espace réservé
- Créez des documents Word à partir de modèles en remplaçant les signets
- Créez des documents Word à partir de modèles en effectuant un publipostage
- Obtenez une licence gratuite
- Conclusion
- Voir également
Installer avec Pip
pip install Spire.Doc
Liens connexes
Les modèles fournissent une structure et une mise en page prêtes à l'emploi, vous permettant d'économiser du temps et des efforts lors de la création de documents à partir de zéro. Au lieu de concevoir la mise en page du document, les styles de formatage et l'organisation des sections, vous pouvez simplement choisir un modèle qui répond à vos besoins et commencer à ajouter votre contenu. Ceci est particulièrement utile lorsque vous devez créer plusieurs documents avec une apparence cohérente. Dans ce blog, nous explorerons comment créer des documents Word à partir de modèles en utilisant Python.
Nous discuterons de trois approches différentes pour générer des documents Word à partir de modèles :
- Créez des documents Word à partir de modèles en remplaçant le texte d'espace réservé en Python
- Créez des documents Word à partir de modèles en remplaçant les signets en Python
- Créez des documents Word à partir de modèles en effectuant un publipostage en Python
Bibliothèque Python pour créer des documents Word à partir de modèles
Pour commencer, nous devons installer le module Python nécessaire qui prend en charge la génération de documents Word à partir de modèles. Dans cet article de blog, nous utiliserons la bibliothèque Spire.Doc for Python.
Spire.Doc for Python offre un ensemble complet de fonctionnalités pour créer, lire, éditer et convertir des fichiers Word dans les applications Python. Il offre une prise en charge transparente de divers formats Word, notamment Doc, Docx, Docm, Dot, Dotx, Dotm, etc. De plus, il permet une conversion de haute qualité de documents Word vers différents formats, tels que Word en PDF, Word en RTF, Word en HTML, Word en Text et Word to Image.
Pour installer Spire.Doc for Python, vous pouvez exécuter la commande pip suivante :
pip install Spire.Doc
Pour des instructions d'installation détaillées, veuillez vous référer à cette documentation : Comment installer Spire.Doc for Python dans VS Code.
Créez des documents Word à partir de modèles en remplaçant le texte d'espace réservé en Python
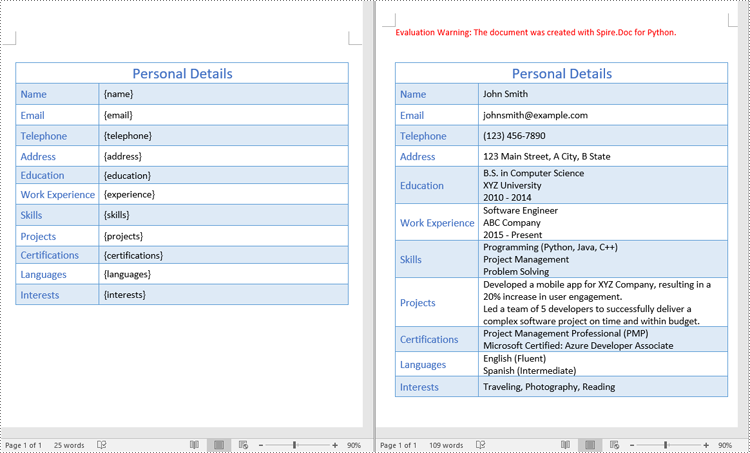
Le « texte d'espace réservé » fait référence à un texte temporaire qui peut être facilement remplacé par le contenu souhaité. Pour créer un document Word à partir d'un modèle en remplaçant le texte d'espace réservé, vous devez préparer un modèle comprenant un texte d'espace réservé prédéfini. Ce modèle peut être créé manuellement à l'aide de l'application Microsoft Word ou généré par programme avec Spire.Doc for Python.
Voici les étapes pour créer un document Word à partir d'un modèle en remplaçant le texte d'espace réservé à l'aide de Spire.Doc for Python:
- Créez une instance de document, puis chargez un modèle Word à l'aide de la méthode Document.LoadFromFile().
- Définissez un dictionnaire qui mappe le texte d'espace réservé au texte de remplacement correspondant pour effectuer des remplacements dans le document.
- Parcourez le dictionnaire.
- Remplacez le texte d'espace réservé dans le document par le texte de remplacement correspondant à l'aide de la méthode Document.Replace().
- Enregistrez le document résultant à l'aide de la méthode Document.SaveToFile().
Voici un exemple de code qui crée un document Word à partir d'un modèle en remplaçant le texte d'espace réservé à l'aide de Spire.Doc for Python:
- Python
from spire.doc import *
from spire.doc.common import *
# Specify the input and output file paths
inputFile = "Placeholder_Template.docx"
outputFile = "CreateDocumentByReplacingPlaceholderText.docx"
# Create a Document object
document = Document()
# Load a Word template with placeholder text
document.LoadFromFile(inputFile)
# Create a dictionary to store the placeholder text and its corresponding replacement text
# Each key represents a placeholder, while the corresponding value represents the replacement text
text_replacements = {
"{name}": "John Smith",
"{email}": "johnsmith@example.com",
"{telephone}": "(123) 456-7890",
"{address}": "123 Main Street, A City, B State",
"{education}": "B.S. in Computer Science \nXYZ University \n2010 - 2014",
"{experience}": "Software Engineer \nABC Company \n2015 - Present",
"{skills}": "Programming (Python, Java, C++) \nProject Management \nProblem Solving",
"{projects}": "Developed a mobile app for XYZ Company, resulting in a 20% increase in user engagement. \nLed a team of 5 developers to successfully deliver a complex software project on time and within budget.",
"{certifications}": "Project Management Professional (PMP) \nMicrosoft Certified: Azure Developer Associate",
"{languages}": "English (Fluent) \nSpanish (Intermediate)",
"{interests}": "Traveling, Photography, Reading"
}
# Loop through the dictionary
for placeholder_text, replacement_text in text_replacements.items():
# Replace the placeholder text in the document with the replacement text
document.Replace(placeholder_text, replacement_text, False, False)
# Save the resulting document
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Conseils: Cet exemple explique comment remplacer le texte d'espace réservé dans un modèle Word par un nouveau texte. Il convient de noter que Spire.Doc pour Python prend en charge le remplacement de texte dans divers scénarios, notamment le remplacement de texte par des images, le remplacement de texte par des tableaux, le remplacement de texte à l'aide d'expressions régulières, etc. Vous pouvez trouver plus de détails dans cette documentation : Python : rechercher et remplacer du texte dans Word.
Créez des documents Word à partir de modèles en remplaçant les signets en Python
Les signets dans un document Word servent de points de référence qui vous permettent d'insérer ou de remplacer avec précision du contenu à des emplacements spécifiques du document. Pour créer un document Word à partir d'un modèle en remplaçant les signets, vous devez préparer un modèle contenant des signets prédéfinis. Ce modèle peut être créé manuellement à l'aide de l'application Microsoft Word ou généré par programme avec Spire.Doc for Python.
Voici les étapes pour créer un document Word à partir d'un modèle en remplaçant les signets à l'aide de Spire.Doc for Python:
- Créez une instance de document et chargez un document Word à l'aide de la méthode Document.LoadFromFile().
- Définissez un dictionnaire qui mappe les noms de signets au texte de remplacement correspondant pour effectuer des remplacements dans le document.
- Parcourez le dictionnaire.
- Créez une instance de BookmarksNavigator et accédez au signet spécifique par son nom à l'aide de la méthode BookmarkNavigator.MoveToBookmark().
- Remplacez le contenu du signet par le texte de remplacement correspondant à l'aide de la méthode BookmarkNavigator.ReplaceBookmarkContent().
- Enregistrez le document résultant à l'aide de la méthode Document.SaveToFile().
Voici un exemple de code qui crée un document Word à partir d'un modèle en remplaçant les signets à l'aide de Spire.Doc for Python :
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word template with bookmarks
document.LoadFromFile("Template_Bookmark.docx")
# Create a dictionary to store the bookmark names and their corresponding replacement text
# Each key represents a bookmark name, while the corresponding value represents the replacement text
bookmark_replacements = {
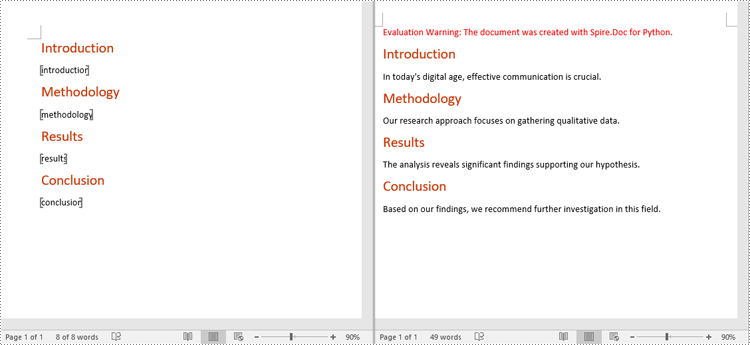
"introduction": "In today's digital age, effective communication is crucial.",
"methodology": "Our research approach focuses on gathering qualitative data.",
"results": "The analysis reveals significant findings supporting our hypothesis.",
"conclusion": "Based on our findings, we recommend further investigation in this field."
}
# Loop through the dictionary
for bookmark_name, replacement_text in bookmark_replacements.items():
# Replace the content of the bookmarks in the document with the corresponding replacement text
bookmarkNavigator = BookmarksNavigator(document)
bookmarkNavigator.MoveToBookmark(bookmark_name)
bookmarkNavigator.ReplaceBookmarkContent(replacement_text, True)
# Remove the bookmarks from the document
document.Bookmarks.Remove(bookmarkNavigator.CurrentBookmark)
# Save the resulting document
document.SaveToFile("CreateDocumentByReplacingBookmark.docx", FileFormat.Docx2016)
document.Close()
Créez des documents Word à partir de modèles en effectuant un publipostage en Python
Le publipostage est une fonctionnalité puissante de Microsoft Word qui vous permet de créer des documents personnalisés à partir d'un modèle en le fusionnant avec une source de données. Pour créer un document Word à partir d'un modèle en effectuant un publipostage, vous devez préparer un modèle comprenant des champs de fusion prédéfinis. Ce modèle peut être créé manuellement à l'aide de l'application Microsoft Word ou généré par programme avec Spire.Doc pour Python à l'aide du code suivant :
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Add a section
section = document.AddSection()
# Set page margins
section.PageSetup.Margins.All = 72.0
# Add a paragraph
paragraph = section.AddParagraph()
# Add text to the paragraph
paragraph.AppendText("Customer Name: ")
# Add a paragraph
paragraph = section.AddParagraph()
# Add a merge field to the paragraph
paragraph.AppendField("Recipient Name", FieldType.FieldMergeField)
# Save the resulting document
document.SaveToFile("Template.docx", FileFormat.Docx2013)
document.Close()
Voici les étapes pour créer un document Word à partir d'un modèle en effectuant un publipostage à l'aide de Spire.Doc for Python:
- Créez une instance de document, puis chargez un modèle Word à l'aide de la méthode Document.LoadFromFile().
- Définissez une liste de noms de champs de fusion.
- Définissez une liste de valeurs de champs de fusion.
- Effectuez un publipostage en utilisant les noms de champs et les valeurs de champs spécifiés à l'aide de la méthode Document.MailMerge.Execute().
- Enregistrez le document résultant à l'aide de la méthode Document.SaveToFile().
Voici un exemple de code qui crée un document Word à partir d'un modèle en effectuant un publipostage à l'aide de Spire.Doc for Python :
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load a Word template with merge fields
document.LoadFromFile("Template_MergeFields.docx")
# Define a list of field names
filedNames = ["Recipient Name", "Company Name", "Amount", "Due Date", "Payment Method", "Sender Name", "Title", "Phone"]
# Define a list of field values
filedValues = ["John Smith", "ABC Company", "$500", DateTime.get_Now().Date.ToString(), "PayPal", "Sarah Johnson", "Accounts Receivable Manager", "123-456-7890"]
# Perform a mail merge operation using the specified field names and field values
document.MailMerge.Execute(filedNames, filedValues)
# Save the resulting document
document.SaveToFile("CreateDocumentByMailMerge.docx", FileFormat.Docx2016)
document.Close()

Obtenez une licence gratuite
Pour profiter pleinement des capacités de Spire.Doc for Python sans aucune limitation d'évaluation, vous pouvez demander une licence d'essai gratuite de 30 jours.
Conclusion
Ce blog a montré comment créer des documents Word à partir de modèles de 3 manières différentes en utilisant Python et Spire.Doc for Python. En plus de créer des documents Word, Spire.Doc for Python fournit de nombreuses fonctionnalités pour manipuler des documents Word, vous pouvez consulter sa documentation pour plus d'informations. Si vous rencontrez des questions, n'hésitez pas à les publier sur notre forum ou envoyez-les à notre équipe d'assistance via e-mail.
Converter imagem em PDF com Python
Índice
Instalar com Pip
pip install Spire.PDF
Links Relacionados
Converter uma imagem em PDF é uma maneira conveniente e eficiente de transformar um arquivo visual em um formato portátil e de leitura universal. Esteja você trabalhando com um documento digitalizado, uma foto ou uma imagem digital, convertê-lo para PDF oferece vários benefícios. Mantém a qualidade original da imagem e garante compatibilidade entre diversos dispositivos e sistemas operacionais. Além disso, a conversão de imagens para PDF permite fácil compartilhamento, impressão e arquivamento, tornando-a uma solução versátil para diversos fins profissionais, educacionais e pessoais. Este artigo fornece vários exemplos que mostram como converta imagens em PDF usando Python.
- Converta uma imagem em um documento PDF em Python
- Converta várias imagens em um documento PDF em python
- Crie um PDF a partir de várias imagens personalizando as margens da página em Python
- Crie um PDF com várias imagens por página em Python
API de conversão de PDF para Python
Se você deseja transformar arquivos de imagem em formato PDF em um aplicativo Python, Spire.PDF for Python pode ajudar com isso. Ele permite que você crie um documento PDF com configurações de página personalizadas (tamanho e margens), adicione uma ou mais imagens a cada página e salve o documento final como um arquivo PDF. Vários formatos de imagem são suportados, incluindo imagens PNG, JPEG, BMP e GIF.
Além da conversão de imagens para PDF, esta biblioteca suporta a conversão de PDF para Word, PDF para Excel, PDF para HTML, PDF para PDF/A com alta qualidade e precisão. Como uma biblioteca Python PDF avançada, ela também fornece uma API avançada para que os desenvolvedores personalizem as opções de conversão para atender a uma variedade de requisitos de conversão.
Você pode instalá-lo executando o seguinte comando pip.
pip install Spire.PDF
Etapas para converter uma imagem em PDF em Python
- Inicialize a classe PdfDocument.
- Carregue um arquivo de imagem do caminho usando o método FromFile.
- Adicione uma página com o tamanho especificado ao documento.
- Desenhe a imagem na página no local especificado usando o método DrawImage.
- Salve o documento em um arquivo PDF usando o método SaveToFile.
Converta uma imagem em um documento PDF em Python
Este exemplo de código converte um arquivo de imagem em um documento PDF usando a biblioteca Spire.PDF for Python criando um documento em branco, adicionando uma página com as mesmas dimensões da imagem e desenhando a imagem na página.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a particular image
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Images\\img-1.jpg")
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile("output/ImageToPdf.pdf")
doc.Dispose()

Converta várias imagens em um documento PDF em python
Este exemplo ilustra como converter uma coleção de imagens em um documento PDF usando Spire.PDF for Python. O trecho de código a seguir lê imagens de uma pasta especificada, cria um documento PDF, adiciona cada imagem a uma página separada no PDF e salva o arquivo PDF resultante.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ImagesToPdf.pdf')
doc.Dispose()

Crie um PDF a partir de várias imagens personalizando as margens da página em Python
Este exemplo de código cria um documento PDF e o preenche com imagens de uma pasta especificada, ajusta as margens da página e salva o documento resultante em um arquivo.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margin
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom)
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/CustomizeMargins.pdf')
doc.Dispose()

Crie um PDF com várias imagens por página em Python
Este código demonstra como usar a biblioteca Spire.PDF em Python para criar um documento PDF com duas imagens por página. As imagens neste exemplo são do mesmo tamanho. Se o tamanho da imagem não for consistente, será necessário ajustar o código para obter o resultado desejado.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margins
doc.PageSettings.SetMargins(15.0, 15.0, 15.0, 15.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for i in range(len(files)):
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, files[i]))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height*2 + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom + 15.0)
if i % 2 == 0:
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw first image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
else :
# Draw second image on the page at (0, height + 15)
page.Canvas.DrawImage(image, 0.0, height + 15.0, width, height)
# Save to file
doc.SaveToFile('output/SeveralImagesPerPage.pdf')
doc.Dispose()
Conclusão
Nesta postagem do blog, exploramos como usar Spire.PDF for python para criar documentos PDF a partir de imagens, contendo uma ou mais imagens por página. Além disso, demonstramos como personalizar o tamanho da página PDF e as margens ao redor das imagens. Para mais tutoriais, confira nossa documentação online. Se você tiver alguma dúvida, não hesite em nos contatar por e-mail ou no fórum.
Преобразование изображения в PDF с помощью Python
Оглавление
- API конвертера PDF для Python
- Действия по преобразованию изображения в PDF
- Преобразование изображения в PDF-документ
- Преобразование нескольких изображений в документ PDF
- Создание PDF-файла из нескольких изображений. Настройка полей страницы.
- Создайте PDF-файл с несколькими изображениями на странице
- Заключение
- Смотрите также
Установить с помощью Пипа
pip install Spire.PDF
Ссылки по теме
Преобразование изображения в PDF — это удобный и эффективный способ преобразования визуального файла в портативный, универсально читаемый формат. Независимо от того, работаете ли вы с отсканированным документом, фотографией или цифровым изображением, преобразование его в PDF дает множество преимуществ. Он сохраняет исходное качество изображения и гарантирует совместимость с различными устройствами и операционными системами. Кроме того, преобразование изображений в PDF позволяет легко обмениваться ими, распечатывать и архивировать их, что делает его универсальным решением для различных профессиональных, образовательных и личных целей. В этой статье представлено несколько примеров, показывающих, как конвертировать изображения в PDF с помощью Python.
- Преобразование изображения в PDF-документ в Python
- Преобразование нескольких изображений в PDF-документ в Python
- Создание PDF-файла из нескольких изображений Настройка полей страницы в Python
- Создайте PDF-файл с несколькими изображениями на странице в Python
API конвертера PDF для Python
Если вы хотите преобразовать файлы изображений в формат PDF в приложении Python, Spire.PDF for Python может помочь в этом. Он позволяет вам создать PDF-документ с настраиваемыми настройками страницы (размер и поля), добавить одно или несколько изображений на каждую страницу и сохранить окончательный документ в виде PDF-файла. Поддерживаются различные формы изображений, включая изображения PNG, JPEG, BMP и GIF.
Помимо преобразования изображений в PDF, эта библиотека поддерживает преобразование PDF в Word, PDF в Excel, PDF в HTML, PDF в PDF/A с высоким качеством и точностью. Являясь расширенной PDF-библиотекой Python, она также предоставляет разработчикам богатый API-интерфейс, позволяющий настраивать параметры преобразования в соответствии с различными требованиями преобразования.
Вы можете установить его, выполнив следующую команду pip.
pip install Spire.PDF
Действия по преобразованию изображения в PDF в Python
- Инициализируйте класс PdfDocument.
- Загрузите файл изображения по указанному пути, используя метод FromFile.
- Добавьте в документ страницу указанного размера.
- Нарисуйте изображение на странице в указанном месте, используя метод DrawImage.
- Сохраните документ в PDF-файл, используя метод SaveToFile.
Преобразование изображения в PDF-документ в Python
В этом примере кода файл изображения преобразуется в документ PDF с помощью библиотеки Spire.PDF for Python путем создания пустого документа, добавления страницы с теми же размерами, что и изображение, и рисования изображения на странице.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a particular image
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Images\\img-1.jpg")
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile("output/ImageToPdf.pdf")
doc.Dispose()
Преобразование нескольких изображений в PDF-документ в Python
В этом примере показано, как преобразовать коллекцию изображений в документ PDF с помощью Spire.PDF for Python. Следующий фрагмент кода считывает изображения из указанной папки, создает документ PDF, добавляет каждое изображение на отдельную страницу в PDF-файле и сохраняет полученный PDF-файл.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ImagesToPdf.pdf')
doc.Dispose()
Создание PDF-файла из нескольких изображений Настройка полей страницы в Python
В этом примере кода создается документ PDF, заполняется изображениями из указанной папки, настраиваются поля страницы и сохраняется полученный документ в файл.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margin
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom)
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/CustomizeMargins.pdf')
doc.Dispose()
Создайте PDF-файл с несколькими изображениями на странице в Python
Этот код демонстрирует, как использовать библиотеку Spire.PDF в Python для создания PDF-документа с двумя изображениями на странице. Изображения в этом примере имеют одинаковый размер. Если размер вашего изображения не одинаков, вам необходимо настроить код для достижения желаемого результата.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margins
doc.PageSettings.SetMargins(15.0, 15.0, 15.0, 15.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for i in range(len(files)):
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, files[i]))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height*2 + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom + 15.0)
if i % 2 == 0:
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw first image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
else :
# Draw second image on the page at (0, height + 15)
page.Canvas.DrawImage(image, 0.0, height + 15.0, width, height)
# Save to file
doc.SaveToFile('output/SeveralImagesPerPage.pdf')
doc.Dispose()
Заключение
В этой записи блога мы рассмотрели, как использовать Spire.PDF for python для создания PDF-документов из изображений, содержащих одно или несколько изображений на странице. Кроме того, мы продемонстрировали, как настроить размер страницы PDF и поля вокруг изображений. Дополнительные руководства можно найти в нашей онлайн-документации. Если у вас есть какие-либо вопросы, не стесняйтесь обращаться к нам по электронной почте или на форуме.
Konvertieren Sie Bilder mit Python in PDF
Inhaltsverzeichnis
- PDF-Konverter-API für Python
- Schritte zum Konvertieren eines Bildes in PDF
- Konvertieren Sie ein Bild in ein PDF-Dokument
- Konvertieren Sie mehrere Bilder in ein PDF-Dokument
- Erstellen Sie ein PDF aus mehreren Bildern und passen Sie die Seitenränder an
- Erstellen Sie ein PDF mit mehreren Bildern pro Seite
- Abschluss
- Siehe auch
Mit Pip installieren
pip install Spire.PDF
verwandte Links
Das Konvertieren eines Bildes in PDF ist eine bequeme und effiziente Möglichkeit, eine visuelle Datei in ein tragbares, allgemein lesbares Format umzuwandeln. Unabhängig davon, ob Sie mit einem gescannten Dokument, einem Foto oder einem digitalen Bild arbeiten, bietet die Konvertierung in PDF zahlreiche Vorteile. Es behält die Originalqualität des Bildes bei und gewährleistet die Kompatibilität mit verschiedenen Geräten und Betriebssystemen. Darüber hinaus ermöglicht die Konvertierung von Bildern in PDF ein einfaches Teilen, Drucken und Archivieren, was es zu einer vielseitigen Lösung für verschiedene berufliche, pädagogische und persönliche Zwecke macht. Dieser Artikel enthält mehrere Beispiele, die Ihnen zeigen, wie das geht Konvertieren Sie Bilder mit Python in PDF.
- Konvertieren Sie ein Bild in ein PDF-Dokument in Python
- Konvertieren Sie mehrere Bilder in ein PDF-Dokument in Python
- Erstellen Sie eine PDF-Datei aus mehreren Bildern und passen Sie die Seitenränder in Python an
- Erstellen Sie in Python ein PDF mit mehreren Bildern pro Seite
PDF-Konverter-API für Python
Wenn Sie Bilddateien in einer Python-Anwendung in das PDF-Format umwandeln möchten, kannSpire.PDF for Python dabei helfen. Sie können damit ein PDF-Dokument mit benutzerdefinierten Seiteneinstellungen (Größe und Ränder) erstellen, jeder einzelnen Seite ein oder mehrere Bilder hinzufügen und das endgültige Dokument als PDF-Datei speichern. Es werden verschiedene Bildformate unterstützt, darunter PNG-, JPEG-, BMP- und GIF-Bilder.
Zusätzlich zur Konvertierung von Bildern in PDF unterstützt diese Bibliothek die Konvertierung von PDF in Word, PDF in Excel, PDF in HTML, und PDF in PDF/A mit hoher Qualität und Präzision. Als erweiterte Python-PDF-Bibliothek bietet sie außerdem eine umfangreiche API für Entwickler, mit der sie die Konvertierungsoptionen anpassen können, um eine Vielzahl von Konvertierungsanforderungen zu erfüllen.
Sie können es installieren, indem Sie den folgenden pip-Befehl ausführen.
pip install Spire.PDF
Schritte zum Konvertieren eines Bilds in PDF in Python
- Initialisieren Sie die PdfDocument-Klasse.
- Laden Sie eine Bilddatei aus dem Pfad mit der FromFile-Methode.
- Fügen Sie dem Dokument eine Seite mit der angegebenen Größe hinzu.
- Zeichnen Sie das Bild mit der DrawImage-Methode an der angegebenen Stelle auf die Seite.
- Speichern Sie das Dokument mit der SaveToFile-Methode in einer PDF-Datei.
Konvertieren Sie ein Bild in ein PDF-Dokument in Python
Dieses Codebeispiel konvertiert eine Bilddatei mithilfe der Bibliothek Spire.PDF for Python in ein PDF-Dokument, indem ein leeres Dokument erstellt, eine Seite mit den gleichen Abmessungen wie das Bild hinzugefügt und das Bild auf die Seite gezeichnet wird.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a particular image
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Images\\img-1.jpg")
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile("output/ImageToPdf.pdf")
doc.Dispose()
Konvertieren Sie mehrere Bilder in ein PDF-Dokument in Python
Dieses Beispiel veranschaulicht, wie Sie mit Spire.PDF for Python eine Sammlung von Bildern in ein PDF-Dokument konvertieren. Der folgende Codeausschnitt liest Bilder aus einem angegebenen Ordner, erstellt ein PDF-Dokument, fügt jedes Bild einer separaten Seite im PDF hinzu und speichert die resultierende PDF-Datei.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ImagesToPdf.pdf')
doc.Dispose()
Erstellen Sie eine PDF-Datei aus mehreren Bildern und passen Sie die Seitenränder in Python an
Dieses Codebeispiel erstellt ein PDF-Dokument und füllt es mit Bildern aus einem angegebenen Ordner, passt die Seitenränder an und speichert das resultierende Dokument in einer Datei.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margin
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom)
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/CustomizeMargins.pdf')
doc.Dispose()
Erstellen Sie in Python ein PDF mit mehreren Bildern pro Seite
Dieser Code zeigt, wie Sie mit der Spire.PDF-Bibliothek in Python ein PDF-Dokument mit zwei Bildern pro Seite erstellen. Die Bilder in diesem Beispiel haben die gleiche Größe. Wenn Ihre Bildgröße nicht konsistent ist, müssen Sie den Code anpassen, um das gewünschte Ergebnis zu erzielen.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margins
doc.PageSettings.SetMargins(15.0, 15.0, 15.0, 15.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for i in range(len(files)):
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, files[i]))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height*2 + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom + 15.0)
if i % 2 == 0:
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw first image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
else :
# Draw second image on the page at (0, height + 15)
page.Canvas.DrawImage(image, 0.0, height + 15.0, width, height)
# Save to file
doc.SaveToFile('output/SeveralImagesPerPage.pdf')
doc.Dispose()
Abschluss
In diesem Blogbeitrag haben wir untersucht, wie Sie mit Spire.PDF for python PDF-Dokumente aus Bildern erstellen können, die ein oder mehrere Bilder pro Seite enthalten. Darüber hinaus haben wir gezeigt, wie Sie die PDF-Seitengröße und die Ränder um die Bilder anpassen können. Weitere Tutorials finden Sie in unserer Online-Dokumentation. Wenn Sie Fragen haben, können Sie uns gerne per E-Mail oder im Forum kontaktieren.
Convertir imagen a PDF con Python
Tabla de contenido
- API de conversión de PDF para Python
- Pasos para convertir una imagen a PDF
- Convertir una imagen a un documento PDF
- Convertir varias imágenes a un documento PDF
- Cree un PDF a partir de varias imágenes personalizando los márgenes de la página
- Cree un PDF con varias imágenes por página
- Conclusión
- Ver también
Instalar con Pip
pip install Spire.PDF
enlaces relacionados
Convertir una imagen a PDF es una forma cómoda y eficaz de transformar un archivo visual en un formato portátil y de lectura universal. Ya sea que esté trabajando con un documento escaneado, una fotografía o una imagen digital, convertirlo a PDF ofrece numerosos beneficios. Mantiene la calidad original de la imagen y garantiza la compatibilidad entre diversos dispositivos y sistemas operativos. Además, convertir imágenes a PDF permite compartirlas, imprimirlas y archivarlas fácilmente, lo que la convierte en una solución versátil para diversos fines profesionales, educativos y personales. Este artículo proporciona varios ejemplos que le muestran cómo convertir imágenes a PDF usando Python.
- Convertir una imagen en un documento PDF en Python
- Convierta varias imágenes a un documento PDF en Python
- Cree un PDF a partir de varias imágenes personalizando los márgenes de página en Python
- Cree un PDF con varias imágenes por página en Python
API de conversión de PDF para Python
Si desea convertir archivos de imagen a formato PDF en una aplicación Python, Spire.PDF for Python puede ayudarle con esto. Le permite crear un documento PDF con configuraciones de página personalizadas (tamaño y márgenes), agregar una o más imágenes a cada página y guardar el documento final como un archivo PDF. Se admiten varios formatos de imágenes que incluyen imágenes PNG, JPEG, BMP y GIF.
Además de la conversión de imágenes a PDF, esta biblioteca admite la conversión de PDF a Word, PDF a Excel, PDF a HTML, PDF a PDF/A con alta calidad y precisión. Como biblioteca PDF de Python avanzada, también proporciona una API enriquecida para que los desarrolladores personalicen las opciones de conversión para cumplir con una variedad de requisitos de conversión.
Puede instalarlo ejecutando el siguiente comando pip.
pip install Spire.PDF
Pasos para convertir una imagen a PDF en Python
- Inicialice la clase PdfDocument.
- Cargue un archivo de imagen desde la ruta usando el método FromFile.
- Agregue una página con el tamaño especificado al documento.
- Dibuja la imagen en la página en la ubicación especificada usando el método DrawImage.
- Guarde el documento en un archivo PDF utilizando el método SaveToFile.
Convertir una imagen en un documento PDF en Python
Este ejemplo de código convierte un archivo de imagen en un documento PDF usando la biblioteca Spire.PDF for Python creando un documento en blanco, agregando una página con las mismas dimensiones que la imagen y dibujando la imagen en la página.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a particular image
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Images\\img-1.jpg")
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile("output/ImageToPdf.pdf")
doc.Dispose()
Convierta varias imágenes a un documento PDF en Python
Este ejemplo ilustra cómo convertir una colección de imágenes en un documento PDF usando Spire.PDF for Python. El siguiente fragmento de código lee imágenes de una carpeta específica, crea un documento PDF, agrega cada imagen a una página separada en el PDF y guarda el archivo PDF resultante.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ImagesToPdf.pdf')
doc.Dispose()
Cree un PDF a partir de varias imágenes personalizando los márgenes de página en Python
Este ejemplo de código crea un documento PDF y lo completa con imágenes de una carpeta específica, ajusta los márgenes de la página y guarda el documento resultante en un archivo.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margin
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom)
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/CustomizeMargins.pdf')
doc.Dispose()
Cree un PDF con varias imágenes por página en Python
Este código demuestra cómo utilizar la biblioteca Spire.PDF en Python para crear un documento PDF con dos imágenes por página. Las imágenes en este ejemplo tienen el mismo tamaño; si el tamaño de su imagen no es consistente, entonces deberá ajustar el código para lograr el resultado deseado.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margins
doc.PageSettings.SetMargins(15.0, 15.0, 15.0, 15.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for i in range(len(files)):
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, files[i]))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height*2 + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom + 15.0)
if i % 2 == 0:
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw first image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
else :
# Draw second image on the page at (0, height + 15)
page.Canvas.DrawImage(image, 0.0, height + 15.0, width, height)
# Save to file
doc.SaveToFile('output/SeveralImagesPerPage.pdf')
doc.Dispose()
Conclusión
En esta publicación de blog, exploramos cómo usar Spire.PDF for Python para crear documentos PDF a partir de imágenes, que contienen una o más imágenes por página. Además, demostramos cómo personalizar el tamaño de la página PDF y los márgenes alrededor de las imágenes. Para obtener más tutoriales, consulte nuestra documentación en línea. Si tiene alguna pregunta, no dude en contactarnos por correo electrónico o en el foro.
Python을 사용하여 이미지를 PDF로 변환
목차
핍으로 설치
pip install Spire.PDF
관련된 링크들
이미지를 PDF로 변환하는 것은 시각적 파일을 휴대 가능하고 보편적으로 읽을 수 있는 형식으로 변환하는 편리하고 효율적인 방법입니다. 스캔한 문서, 사진 또는 디지털 이미지로 작업하는 경우 PDF로 변환하면 다양한 이점을 얻을 수 있습니다. 이미지의 원본 품질을 유지하고 다양한 장치 및 운영 체제에서의 호환성을 보장합니다. 또한 이미지를 PDF로 변환하면 공유, 인쇄, 보관이 쉬워 다양한 전문적, 교육적, 개인적 목적을 위한 다용도 솔루션이 됩니다. 이 문서에서는 다음 방법을 보여주는 몇 가지 예를 제공합니다 Python을 사용하여 이미지를 PDF로 변환합니다.
- Python에서 이미지를 PDF 문서로 변환
- Python에서 여러 이미지를 PDF 문서로 변환
- Python에서 페이지 여백 사용자 정의하기 여러 이미지에서 PDF 만들기
- Python에서 페이지당 여러 이미지가 포함된 PDF 만들기
Python용 PDF 변환기 API
Python 애플리케이션에서 이미지 파일을 PDF 형식으로 변환하려는 경우 Spire.PDF for Python가 도움이 될 수 있습니다. 사용자 정의 페이지 설정(크기 및 여백)을 사용하여 PDF 문서를 만들고, 모든 단일 페이지에 하나 이상의 이미지를 추가하고, 최종 문서를 PDF 파일로 저장할 수 있습니다. PNG, JPEG, BMP, GIF 이미지를 포함한 다양한 이미지 형식이 지원됩니다.
이미지를 PDF로 변환하는 것 외에도 이 라이브러리는 높은 품질과 정밀도로 PDF를 Word로, PDF를 Excel로, PDF를 HTML로, PDF를 PDF/A로 변환하는 것을 지원합니다. 고급 Python PDF 라이브러리인 이 라이브러리는 개발자가 다양한 변환 요구 사항을 충족하도록 변환 옵션을 사용자 정의할 수 있는 풍부한 API도 제공합니다.
다음 pip 명령을 실행하여 설치할 수 있습니다.
pip install Spire.PDF
Python에서 이미지를 PDF로 변환하는 단계
- PdfDocument 클래스를 초기화합니다.
- FromFile 메서드를 사용하여 경로에서 이미지 파일을 로드합니다.
- 문서에 지정된 크기의 페이지를 추가합니다.
- DrawImage 메서드를 사용하여 페이지의 지정된 위치에 이미지를 그립니다.
- SaveToFile 메서드를 사용하여 문서를 PDF 파일로 저장합니다.
Python에서 이미지를 PDF 문서로 변환
이 코드 예제는 빈 문서를 만들고, 이미지와 동일한 크기의 페이지를 추가하고, 페이지에 이미지를 그리는 방식으로 Spire.PDF for Python 라이브러리를 사용하여 이미지 파일을 PDF 문서로 변환합니다.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a particular image
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Images\\img-1.jpg")
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile("output/ImageToPdf.pdf")
doc.Dispose()
Python에서 여러 이미지를 PDF 문서로 변환
이 예에서는 Spire.PDF for Python를 사용하여 이미지 모음을 PDF 문서로 변환하는 방법을 보여줍니다. 다음 코드 조각은 지정된 폴더에서 이미지를 읽고, PDF 문서를 만들고, 각 이미지를 PDF의 별도 페이지에 추가하고, 결과 PDF 파일을 저장합니다.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ImagesToPdf.pdf')
doc.Dispose()
Python에서 페이지 여백 사용자 정의하기 여러 이미지에서 PDF 만들기
이 코드 예제는 PDF 문서를 생성하고 이를 지정된 폴더의 이미지로 채우고 페이지 여백을 조정한 후 결과 문서를 파일에 저장합니다.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margin
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom)
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/CustomizeMargins.pdf')
doc.Dispose()
Python에서 페이지당 여러 이미지가 포함된 PDF 만들기
이 코드는 Python에서 Spire.PDF 라이브러리를 사용하여 페이지당 두 개의 이미지가 포함된 PDF 문서를 만드는 방법을 보여줍니다. 이 예의 이미지는 크기가 동일합니다. 이미지 크기가 일정하지 않은 경우 원하는 결과를 얻으려면 코드를 조정해야 합니다.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margins
doc.PageSettings.SetMargins(15.0, 15.0, 15.0, 15.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for i in range(len(files)):
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, files[i]))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height*2 + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom + 15.0)
if i % 2 == 0:
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw first image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
else :
# Draw second image on the page at (0, height + 15)
page.Canvas.DrawImage(image, 0.0, height + 15.0, width, height)
# Save to file
doc.SaveToFile('output/SeveralImagesPerPage.pdf')
doc.Dispose()
결론
이 블로그 게시물에서는 Spire.PDF for python를 사용하여 페이지당 하나 이상의 이미지가 포함된 이미지에서 PDF 문서를 만드는 방법을 살펴보았습니다. 또한 PDF 페이지 크기와 이미지 주변 여백을 사용자 정의하는 방법을 시연했습니다. 더 많은 튜토리얼을 보려면 다음을 확인하세요 온라인 문서. 질문이 있으시면 언제든지 문의해 주세요 이메일 아니면 법정.
Converti immagine in PDF con Python
Sommario
Installa con Pip
pip install Spire.PDF
Link correlati
La conversione di un'immagine in PDF è un modo comodo ed efficiente per trasformare un file visivo in un formato portatile e universalmente leggibile. Che tu stia lavorando con un documento scansionato, una foto o un'immagine digitale, convertirlo in PDF offre numerosi vantaggi. Mantiene la qualità originale dell'immagine e garantisce la compatibilità tra diversi dispositivi e sistemi operativi. Inoltre, la conversione delle immagini in PDF consente una facile condivisione, stampa e archiviazione, rendendola una soluzione versatile per vari scopi professionali, educativi e personali. Questo articolo fornisce diversi esempi che mostrano come convertire immagini in PDF utilizzando Python.
- Converti un'immagine in un documento PDF in Python
- Converti più immagini in un documento PDF in Python
- Crea un PDF da più immagini personalizzando i margini della pagina in Python
- Crea un PDF con diverse immagini per pagina in Python
API di conversione PDF per Python
Se desideri trasformare i file di immagine in formato PDF in un'applicazione Python, Spire.PDF for Python può aiutarti in questo. Ti consente di creare un documento PDF con impostazioni di pagina personalizzate (dimensioni e margini), aggiungere una o più immagini a ogni singola pagina e salvare il documento finale come file PDF. Sono supportati vari formati di immagine che includono immagini PNG, JPEG, BMP e GIF.
Oltre alla conversione da immagini a PDF, questa libreria supporta la conversione da PDF a Word, da PDF a Excel, da PDF a HTML, da PDF a PDF/Acon alta qualità e precisione. Essendo una libreria PDF Python avanzata, fornisce anche una ricca API che consente agli sviluppatori di personalizzare le opzioni di conversione per soddisfare una varietà di requisiti di conversione.
Puoi installarlo eseguendo il seguente comando pip.
pip install Spire.PDF
Passaggi per convertire un'immagine in PDF in Python
- Inizializza la classe PdfDocument.
- Carica un file immagine dal percorso utilizzando il metodo FromFile.
- Aggiungi una pagina con la dimensione specificata al documento.
- Disegna l'immagine sulla pagina nella posizione specificata utilizzando il metodo DrawImage.
- Salva il documento in un file PDF utilizzando il metodo SaveToFile.
Converti un'immagine in un documento PDF in Python
Questo esempio di codice converte un file immagine in un documento PDF utilizzando la libreria Spire.PDF for Python creando un documento vuoto, aggiungendo una pagina con le stesse dimensioni dell'immagine e disegnando l'immagine sulla pagina.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a particular image
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Images\\img-1.jpg")
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile("output/ImageToPdf.pdf")
doc.Dispose()
Converti più immagini in un documento PDF in Python
Questo esempio illustra come convertire una raccolta di immagini in un documento PDF utilizzando Spire.PDF for Python. Il seguente frammento di codice legge le immagini da una cartella specificata, crea un documento PDF, aggiunge ciascuna immagine a una pagina separata nel PDF e salva il file PDF risultante.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ImagesToPdf.pdf')
doc.Dispose()
Crea un PDF da più immagini personalizzando i margini della pagina in Python
Questo esempio di codice crea un documento PDF e lo popola con immagini da una cartella specificata, regola i margini della pagina e salva il documento risultante in un file.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margin
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom)
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/CustomizeMargins.pdf')
doc.Dispose()
Crea un PDF con diverse immagini per pagina in Python
Questo codice dimostra come utilizzare la libreria Spire.PDF in Python per creare un documento PDF con due immagini per pagina. Le immagini in questo esempio hanno le stesse dimensioni, se la dimensione dell'immagine non è coerente, è necessario modificare il codice per ottenere il risultato desiderato.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margins
doc.PageSettings.SetMargins(15.0, 15.0, 15.0, 15.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for i in range(len(files)):
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, files[i]))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height*2 + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom + 15.0)
if i % 2 == 0:
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw first image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
else :
# Draw second image on the page at (0, height + 15)
page.Canvas.DrawImage(image, 0.0, height + 15.0, width, height)
# Save to file
doc.SaveToFile('output/SeveralImagesPerPage.pdf')
doc.Dispose()
Conclusione
In questo post del blog, abbiamo esplorato come utilizzare Spire.PDF for Python per creare documenti PDF da immagini, contenenti una o più immagini per pagina. Inoltre, abbiamo dimostrato come personalizzare le dimensioni della pagina PDF e i margini attorno alle immagini. Per ulteriori tutorial, consulta la nostra documentazione online. Se avete domande, non esitate a contattarci tramite e-mail o sul Forum.
Convertir une image en PDF avec Python
Table des matières
- API de conversion PDF pour Python
- Étapes pour convertir une image en PDF
- Convertir une image en document PDF
- Convertir plusieurs images en un document PDF
- Créer un PDF à partir de plusieurs images en personnalisant les marges de page
- Créer un PDF avec plusieurs images par page
- Conclusion
- Voir également
Installer avec Pip
pip install Spire.PDF
Liens connexes
La conversion d'une image en PDF est un moyen pratique et efficace de transformer un fichier visuel en un format portable et universellement lisible. Que vous travailliez avec un document numérisé, une photo ou une image numérique, sa conversion en PDF offre de nombreux avantages. Il conserve la qualité originale de l'image et garantit la compatibilité entre divers appareils et systèmes d'exploitation. De plus, la conversion d'images au format PDF permet un partage, une impression et un archivage faciles, ce qui en fait une solution polyvalente à diverses fins professionnelles, éducatives et personnelles. Cet article fournit plusieurs exemples vous montrant comment convertir des images en PDF en utilisant Python.
- Convertir une image en document PDF en Python
- Convertir plusieurs images en un document PDF en python
- Créer un PDF à partir de plusieurs images en personnalisant les marges de page en Python
- Créer un PDF avec plusieurs images par page en Python
API de conversion PDF pour Python
Si vous souhaitez transformer des fichiers image au format PDF dans une application Python, Spire.PDF for Python peut vous aider. Il vous permet de créer un document PDF avec des paramètres de page personnalisés (taille et marges), d'ajouter une ou plusieurs images à chaque page et d'enregistrer le document final sous forme de fichier PDF. Diverses formes d'images sont prises en charge, notamment les images PNG, JPEG, BMP et GIF.
En plus de la conversion d'images en PDF, cette bibliothèque prend en charge la conversion de PDF en Word, PDF en Excel, PDF en HTML, PDF en PDF/A avec une qualité et une précision élevées. En tant que bibliothèque Python PDF avancée, elle fournit également une API riche permettant aux développeurs de personnaliser les options de conversion afin de répondre à diverses exigences de conversion.
Vous pouvez l'installer en exécutant la commande pip suivante.
pip install Spire.PDF
Étapes pour convertir une image en PDF en Python
- Initialisez la classe PdfDocument.
- Chargez un fichier image à partir du chemin à l’aide de la méthode FromFile.
- Ajoutez une page avec la taille spécifiée au document.
- Dessinez l'image sur la page à l'emplacement spécifié à l'aide de la méthode DrawImage.
- Enregistrez le document dans un fichier PDF à l'aide de la méthode SaveToFile.
Convertir une image en document PDF en Python
Cet exemple de code convertit un fichier image en document PDF à l'aide de la bibliothèque Spire.PDF for Python en créant un document vierge, en ajoutant une page avec les mêmes dimensions que l'image et en dessinant l'image sur la page.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a particular image
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Images\\img-1.jpg")
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile("output/ImageToPdf.pdf")
doc.Dispose()
Convertir plusieurs images en un document PDF en python
Cet exemple illustre comment convertir une collection d'images en un document PDF à l'aide de Spire.PDF for Python. L'extrait de code suivant lit les images d'un dossier spécifié, crée un document PDF, ajoute chaque image à une page distincte du PDF et enregistre le fichier PDF résultant.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ImagesToPdf.pdf')
doc.Dispose()
Créer un PDF à partir de plusieurs images en personnalisant les marges de page en Python
Cet exemple de code crée un document PDF et le remplit avec des images d'un dossier spécifié, ajuste les marges de la page et enregistre le document résultant dans un fichier.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margin
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom)
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/CustomizeMargins.pdf')
doc.Dispose()
Créer un PDF avec plusieurs images par page en Python
Ce code montre comment utiliser la bibliothèque Spire.PDF en Python pour créer un document PDF avec deux images par page. Les images de cet exemple ont la même taille, si la taille de votre image n'est pas cohérente, vous devez alors ajuster le code pour obtenir le résultat souhaité.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margins
doc.PageSettings.SetMargins(15.0, 15.0, 15.0, 15.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for i in range(len(files)):
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, files[i]))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height*2 + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom + 15.0)
if i % 2 == 0:
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw first image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
else :
# Draw second image on the page at (0, height + 15)
page.Canvas.DrawImage(image, 0.0, height + 15.0, width, height)
# Save to file
doc.SaveToFile('output/SeveralImagesPerPage.pdf')
doc.Dispose()
Conclusion
Dans cet article de blog, nous avons expliqué comment utiliser Spire.PDF for python pour créer des documents PDF à partir d'images, contenant une ou plusieurs images par page. De plus, nous avons montré comment personnaliser la taille de la page PDF et les marges autour des images. Pour plus de tutoriels, veuillez consulter notre documentation en ligne. Si vous avez des questions, n'hésitez pas à nous contacter par email ou sur le forum.
Conversão de PDF em texto em Python: recuperar texto de PDFs
Índice
Instalar com Pip
pip install Spire.PDF
Links Relacionados
Na era digital de hoje, a capacidade de extrair informações de documentos PDF de forma rápida e eficiente é crucial para vários setores e profissionais. Quer você seja um pesquisador, um analista de dados ou simplesmente lide com um grande volume de arquivos PDF, ser capaz de converter PDFs em formato de texto editável pode economizar tempo e esforço valiosos. É aqui que Python, uma linguagem de programação versátil e poderosa, vem ao resgate com seus extensos recursos para converter PDF em texto em Python.

Neste artigo, exploraremos como usar Python para PDF para texto conversão, liberando o poder do Python no processamento de arquivos PDF. Este artigo inclui os seguintes tópicos:
- API Python para conversão de PDF em texto
- Guia para converter PDF em texto em Python
- Python para converter PDF em texto sem manter o layout
- Python para converter PDF em texto e manter o layout
- Python para converter uma área específica da página PDF em texto
- Obtenha uma licença gratuita para a API para converter PDF em texto em Python
- Saiba mais sobre processamento de PDF com Python
API Python para conversão de PDF em texto
Para usar Python para conversão de PDF em texto, é necessária uma API de processamento de PDF – Spire.PDF for Python Esta biblioteca Python foi projetada para manipulação de documentos PDF em programas Python, o que capacita os programas Python com várias habilidades de processamento de PDF.
Pudermos baixar Spire.PDF for Python e adicione-o ao nosso projeto, ou simplesmente instale-o através do PyPI com o seguinte código:
pip install Spire.PDF
Guia para converter PDF em texto em Python
Antes de prosseguirmos com a conversão de PDF em texto usando Python, vamos dar uma olhada nas principais vantagens que ele pode nos oferecer:
- Editabilidade: A conversão de PDF em texto permite editar o documento com mais facilidade, pois os arquivos de texto podem ser abertos e editados na maioria dos dispositivos.
- Acessibilidade: Arquivos de texto geralmente são mais acessíveis que PDFs. Quer seja um desktop ou um telefone celular, os arquivos de texto podem ser visualizados em dispositivos com facilidade.
- Integração com outros aplicativos: Os arquivos de texto podem ser integrados perfeitamente em vários aplicativos e fluxos de trabalho.
Etapas para converter documentos PDF em arquivos de texto em Python:
- Instale Spire.PDF for Python.
- Importe módulos.
- Crie um objeto da classe PdfDocument e carregue um arquivo PDF usando o método LoadFromFile().
- Crie um objeto da classe PdfTextExtractOptions e defina as opções de extração de texto, incluindo extrair todo o texto, mostrar texto oculto, extrair apenas texto em uma área especificada e extração simples.
- Obtenha uma página no documento usando o método PdfDocument.Pages.get_Item() e crie objetos PdfTextExtractor com base em cada página para extrair o texto da página usando o método Extract() com opções especificadas.
- Salve o texto extraído como um arquivo de texto e feche o objeto PdfDocument.
Python para converter PDF em texto sem manter layout
Ao usar o método de extração simples para extrair texto de PDF, o programa não reterá as áreas em branco e acompanhará a posição Y atual de cada string e inserirá uma quebra de linha na saída se a posição Y tiver mudado.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python para converter PDF em texto e manter o layout
Ao usar o método de extração padrão para extrair texto de PDF, o programa extrairá o texto linha por linha, incluindo espaços em branco.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
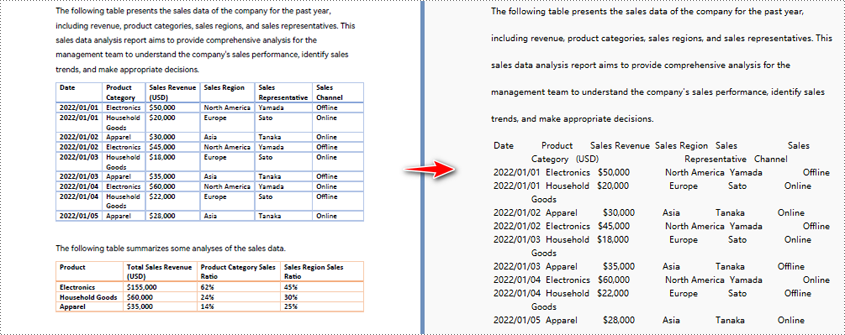
Python para converter uma área específica da página PDF em texto
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
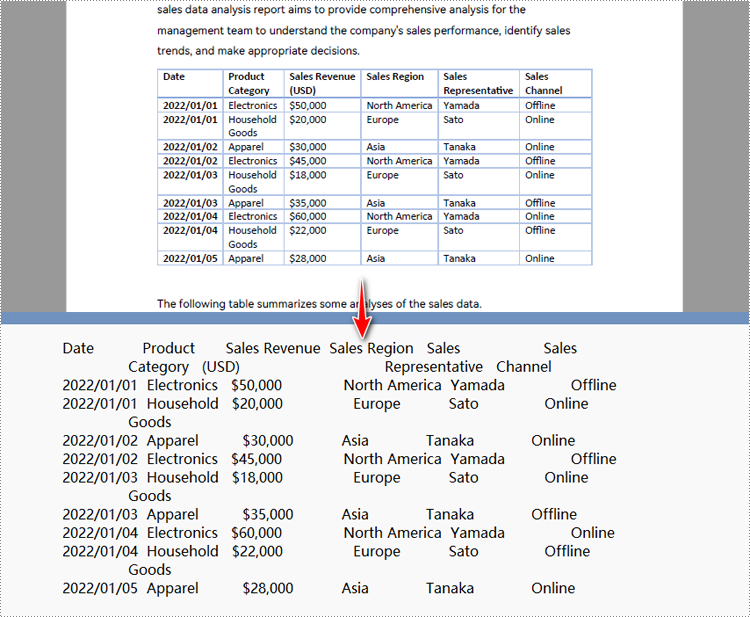
Obtenha uma licença gratuita para a API para converter PDF em texto em Python
Os usuários podem solicite uma licença temporária gratuita para experimentar o Spire.PDF for Python e avaliar os recursos de conversão de PDF em texto do Python sem quaisquer limitações.
Saiba mais sobre processamento de PDF com Python
Além de converter PDF em texto com Python, também podemos explorar mais recursos de processamento de PDF desta API através das seguintes fontes:
- Como extrair texto de documentos PDF com Python
- Tutoriais para processamento de PDF com Python
- Convertendo documentos PDF baseados em imagem em texto (OCR)
Conclusão
Nesta postagem do blog, exploramos Python em PDF para conversão de texto. Seguindo as etapas operacionais e consultando os exemplos de código do artigo, podemos obter resultados rápidos Conversão de PDF para texto em Python programas. Além disso, o artigo fornece informações sobre os benefícios da conversão de documentos PDF em arquivos de texto. Mais importante ainda, podemos obter mais conhecimento sobre como lidar com documentos PDF com Python e métodos para converter documentos PDF baseados em imagens em texto por meio de ferramentas de OCR a partir das referências do artigo. Se surgir algum problema durante o uso do Spire.PDF for Python, o suporte técnico pode ser obtido entrando em contato com nossa equipe por meio do fórum Spire.PDF ou pore-mail.
Преобразование PDF в текст Python: извлечение текста из PDF-файлов
Оглавление
Установить с помощью Пипа
pip install Spire.PDF
Ссылки по теме
В современную цифровую эпоху возможность быстро и эффективно извлекать информацию из PDF-документов имеет решающее значение для различных отраслей и специалистов. Независимо от того, являетесь ли вы исследователем, аналитиком данных или просто имеете дело с большим объемом PDF-файлов, возможность конвертировать PDF-файлы в редактируемый текстовый формат может сэкономить вам драгоценное время и усилия. Именно здесь на помощь приходит Python, универсальный и мощный язык программирования с его обширными возможностями преобразования PDF в текст на Python.
В этой статье мы рассмотрим, как использовать Python для преобразования PDF в текст преобразование, раскрывающее возможности Python при обработке PDF-файлов. Эта статья включает в себя следующие темы:
- API Python для преобразования PDF в текст
- Руководство по преобразованию PDF в текст в Python
- Python для преобразования PDF в текст без сохранения макета
- Python для преобразования PDF в текст и сохранения макета
- Python для преобразования указанной области страницы PDF в текст
- Получите бесплатную лицензию на API для преобразования PDF в текст на Python
- Узнайте больше об обработке PDF с помощью Python
API Python для преобразования PDF в текст
Чтобы использовать Python для преобразования PDF в текст, необходим API обработки PDF — Spire.PDF for Python Эта библиотека Python предназначена для манипулирования PDF-документами в программах Python, что расширяет возможности программ Python различными возможностями обработки PDF-файлов.
Мы можем скачать Spire.PDF for Python и добавьте его в наш проект или просто установите через PyPI с помощью следующего кода:
pip install Spire.PDF
Руководство по преобразованию PDF в текст в Python
Прежде чем мы приступим к преобразованию PDF в текст с помощью Python, давайте посмотрим на основные преимущества, которые он может нам предложить:
- Возможность редактирования: Преобразование PDF в текст упрощает редактирование документа, поскольку текстовые файлы можно открывать и редактировать на большинстве устройств.
- Доступность: Текстовые файлы обычно более доступны, чем PDF-файлы. Будь то настольный компьютер или мобильный телефон, текстовые файлы можно легко просматривать на устройствах.
- Интеграция с другими приложениями: Текстовые файлы можно легко интегрировать в различные приложения и рабочие процессы.
Шаги по преобразованию PDF-документов в текстовые файлы на Python:
- Установите Spire.PDF for Python.
- Импортируйте модули.
- Создайте объект класса PdfDocument и загрузите PDF-файл с помощью метода LoadFromFile().
- Создайте объект класса PdfTextExtractOptions и установите параметры извлечения текста, включая извлечение всего текста, отображение скрытого текста, извлечение текста только в указанной области и простое извлечение.
- Получите страницу в документе с помощью метода PdfDocument.Pages.get_Item() и создайте объекты PdfTextExtractor на основе каждой страницы для извлечения текста со страницы с помощью метода Extract() с указанными параметрами.
- Сохраните извлеченный текст как текстовый файл и закройте объект PdfDocument.
Python для преобразования PDF в текст без сохранения макета
При использовании простого метода извлечения для извлечения текста из PDF программа не сохраняет пустые области, отслеживает текущую позицию Y каждой строки и вставляет разрыв строки в выходные данные, если позиция Y изменилась.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python для преобразования PDF в текст и сохранения макета
При использовании метода извлечения по умолчанию для извлечения текста из PDF программа будет извлекать текст построчно, включая пробелы.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Python для преобразования указанной области страницы PDF в текст
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Получите бесплатную лицензию на API для преобразования PDF в текст на Python
Пользователи могут подать заявку на получение бесплатной временной лицензии попробовать Spire.PDF for Python и оценить возможности Python PDF в текст без каких-либо ограничений.
Узнайте больше об обработке PDF с помощью Python
Помимо преобразования PDF в текст с помощью Python, мы также можем изучить дополнительные функции обработки PDF с помощью этого API из следующих источников:
- Как извлечь текст из PDF-документов с помощью Python
- Учебники по обработке PDF с помощью Python
- Преобразование PDF-документов на основе изображений в текст (OCR)
Заключение
В этом сообщении блога мы изучили Python в преобразовании PDF в текст. Следуя инструкциям и обращаясь к примерам кода в статье, мы можем добиться быстрого Преобразование PDF в текст в Python программы. Кроме того, в статье представлены преимущества преобразования PDF-документов в текстовые файлы. Что еще более важно, мы можем получить дополнительные знания об обработке PDF-документов с помощью Python и методах преобразования PDF-документов на основе изображений в текст с помощью инструментов OCR из ссылок в статье. Если при использовании Spire.PDF for Python возникнут какие-либо проблемы, техническую поддержку можно получить, обратившись к нашей команде через Форум Spire.PDF или электронная почта.