Índice
Instalar com Pip
pip install Spire.PDF
Links Relacionados
Na era digital de hoje, a capacidade de extrair informações de documentos PDF de forma rápida e eficiente é crucial para vários setores e profissionais. Quer você seja um pesquisador, um analista de dados ou simplesmente lide com um grande volume de arquivos PDF, ser capaz de converter PDFs em formato de texto editável pode economizar tempo e esforço valiosos. É aqui que Python, uma linguagem de programação versátil e poderosa, vem ao resgate com seus extensos recursos para converter PDF em texto em Python.

Neste artigo, exploraremos como usar Python para PDF para texto conversão, liberando o poder do Python no processamento de arquivos PDF. Este artigo inclui os seguintes tópicos:
- API Python para conversão de PDF em texto
- Guia para converter PDF em texto em Python
- Python para converter PDF em texto sem manter o layout
- Python para converter PDF em texto e manter o layout
- Python para converter uma área específica da página PDF em texto
- Obtenha uma licença gratuita para a API para converter PDF em texto em Python
- Saiba mais sobre processamento de PDF com Python
API Python para conversão de PDF em texto
Para usar Python para conversão de PDF em texto, é necessária uma API de processamento de PDF – Spire.PDF for Python Esta biblioteca Python foi projetada para manipulação de documentos PDF em programas Python, o que capacita os programas Python com várias habilidades de processamento de PDF.
Pudermos baixar Spire.PDF for Python e adicione-o ao nosso projeto, ou simplesmente instale-o através do PyPI com o seguinte código:
pip install Spire.PDF
Guia para converter PDF em texto em Python
Antes de prosseguirmos com a conversão de PDF em texto usando Python, vamos dar uma olhada nas principais vantagens que ele pode nos oferecer:
- Editabilidade: A conversão de PDF em texto permite editar o documento com mais facilidade, pois os arquivos de texto podem ser abertos e editados na maioria dos dispositivos.
- Acessibilidade: Arquivos de texto geralmente são mais acessíveis que PDFs. Quer seja um desktop ou um telefone celular, os arquivos de texto podem ser visualizados em dispositivos com facilidade.
- Integração com outros aplicativos: Os arquivos de texto podem ser integrados perfeitamente em vários aplicativos e fluxos de trabalho.
Etapas para converter documentos PDF em arquivos de texto em Python:
- Instale Spire.PDF for Python.
- Importe módulos.
- Crie um objeto da classe PdfDocument e carregue um arquivo PDF usando o método LoadFromFile().
- Crie um objeto da classe PdfTextExtractOptions e defina as opções de extração de texto, incluindo extrair todo o texto, mostrar texto oculto, extrair apenas texto em uma área especificada e extração simples.
- Obtenha uma página no documento usando o método PdfDocument.Pages.get_Item() e crie objetos PdfTextExtractor com base em cada página para extrair o texto da página usando o método Extract() com opções especificadas.
- Salve o texto extraído como um arquivo de texto e feche o objeto PdfDocument.
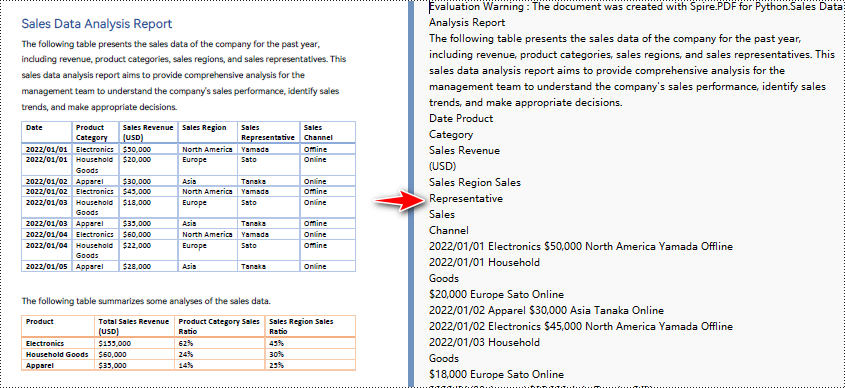
Python para converter PDF em texto sem manter layout
Ao usar o método de extração simples para extrair texto de PDF, o programa não reterá as áreas em branco e acompanhará a posição Y atual de cada string e inserirá uma quebra de linha na saída se a posição Y tiver mudado.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
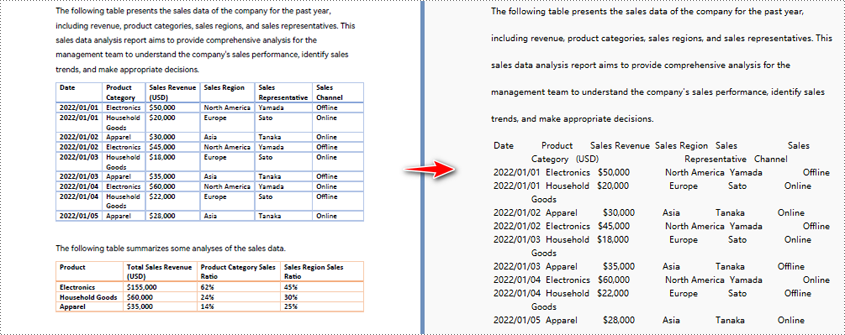
Python para converter PDF em texto e manter o layout
Ao usar o método de extração padrão para extrair texto de PDF, o programa extrairá o texto linha por linha, incluindo espaços em branco.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
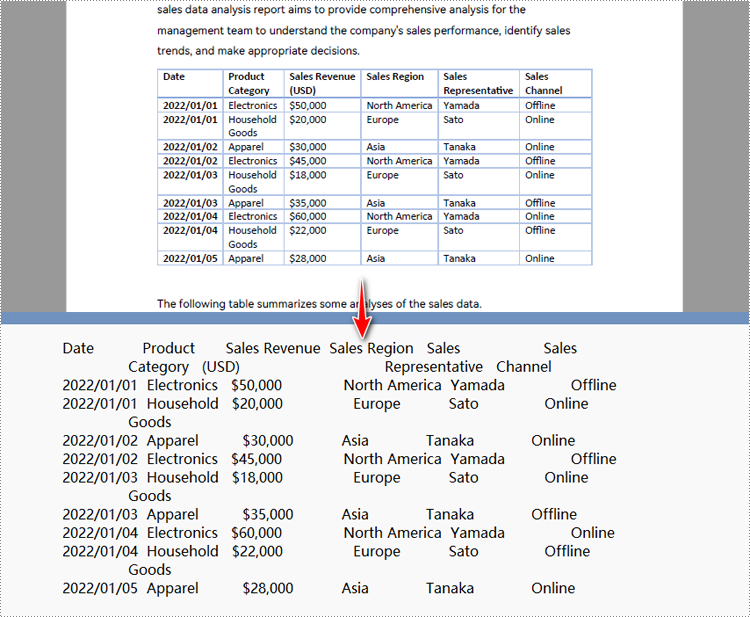
Python para converter uma área específica da página PDF em texto
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Obtenha uma licença gratuita para a API para converter PDF em texto em Python
Os usuários podem solicite uma licença temporária gratuita para experimentar o Spire.PDF for Python e avaliar os recursos de conversão de PDF em texto do Python sem quaisquer limitações.
Saiba mais sobre processamento de PDF com Python
Além de converter PDF em texto com Python, também podemos explorar mais recursos de processamento de PDF desta API através das seguintes fontes:
- Como extrair texto de documentos PDF com Python
- Tutoriais para processamento de PDF com Python
- Convertendo documentos PDF baseados em imagem em texto (OCR)
Conclusão
Nesta postagem do blog, exploramos Python em PDF para conversão de texto. Seguindo as etapas operacionais e consultando os exemplos de código do artigo, podemos obter resultados rápidos Conversão de PDF para texto em Python programas. Além disso, o artigo fornece informações sobre os benefícios da conversão de documentos PDF em arquivos de texto. Mais importante ainda, podemos obter mais conhecimento sobre como lidar com documentos PDF com Python e métodos para converter documentos PDF baseados em imagens em texto por meio de ferramentas de OCR a partir das referências do artigo. Se surgir algum problema durante o uso do Spire.PDF for Python, o suporte técnico pode ser obtido entrando em contato com nossa equipe por meio do fórum Spire.PDF ou pore-mail.
