
By extracting text from Word documents, you can effortlessly obtain the written information contained within them. This allows for easier manipulation, analysis, and organization of textual content, enabling tasks such as text mining, sentiment analysis, and natural language processing. Extracting images, on the other hand, provides access to visual elements embedded within Word documents, which can be crucial for tasks like image recognition, content extraction, or creating image databases. In this article, you will learn how to extract text and images from a Word document in Python using Spire.Doc for Python.
- Extract Text from a Specific Paragraph in Python
- Extract Text from an Entire Word Document in Python
- Extract Images from an Entire Word Document in Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Extract Text from a Specific Paragraph in Python
To get a certain paragraph from a section, use Section.Paragraphs[index] property. Then, you can get the text of the paragraph through Paragraph.Text property. The detailed steps are as follows.
- Create a Document object.
- Load a Word file using Document.LoadFromFile() method.
- Get a specific section through Document.Sections[index] property.
- Get a specific paragraph through Section.Paragraphs[index] property.
- Get text from the paragraph through Paragraph.Text property.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get a specific section
section = doc.Sections[0]
# Get a specific paragraph
paragraph = section.Paragraphs[2]
# Get text from the paragraph
str = paragraph.Text
# Print result
print(str)
Extract Text from an Entire Word Document in Python
If you want to get text from a whole document, you can simply use Document.GetText() method. Below are the steps.
- Create a Document object.
- Load a Word file using Document.LoadFromFile() method.
- Get text from the document using Document.GetText() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get text from the entire document
str = doc.GetText()
# Print result
print(str)

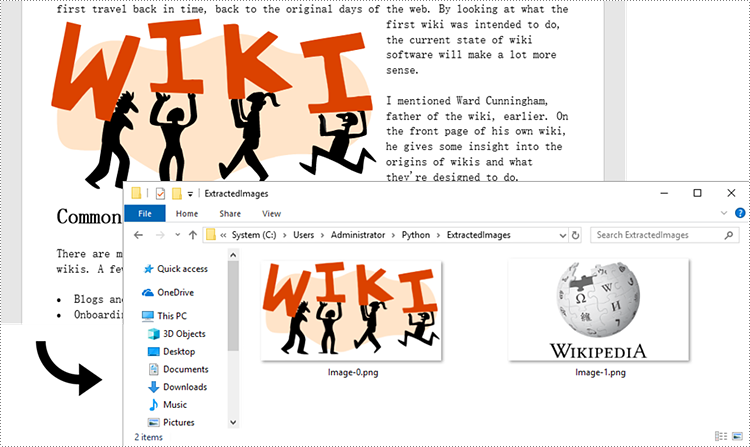
Extract Images from an Entire Word Document in Python
Spire.Doc for Python does not provide a straightforward method to get images from a Word document. You need to iterate through the child objects in the document, and determine if a certain a child object is a DocPicture. If yes, you get the image data using DocPicture.ImageBytes property and then save it as a popular image format file. The main steps are as follows.
- Create a Document object.
- Load a Word file using Document.LoadFromFile() method.
- Loop through the child objects in the document.
- Determine if a specific child object is a DocPicture. If yes, get the image data through DocPicture.ImageBytes property.
- Write the image data as a PNG file.
- Python
import queue
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Create a Queue object
nodes = queue.Queue()
nodes.put(doc)
# Create a list
images = []
while nodes.qsize() > 0:
node = nodes.get()
# Loop through the child objects in the document
for i in range(node.ChildObjects.Count):
child = node.ChildObjects.get_Item(i)
# Determine if a child object is a picture
if child.DocumentObjectType == DocumentObjectType.Picture:
picture = child if isinstance(child, DocPicture) else None
dataBytes = picture.ImageBytes
# Add the image data to the list
images.append(dataBytes)
elif isinstance(child, ICompositeObject):
nodes.put(child if isinstance(child, ICompositeObject) else None)
# Loop through the images in the list
for i, item in enumerate(images):
fileName = "Image-{}.png".format(i)
with open("ExtractedImages/"+fileName,'wb') as imageFile:
# Write the image to a specified path
imageFile.write(item)
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
