Оглавление
Установить с помощью Пипа
pip install Spire.PDF
Ссылки по теме
В современную цифровую эпоху возможность быстро и эффективно извлекать информацию из PDF-документов имеет решающее значение для различных отраслей и специалистов. Независимо от того, являетесь ли вы исследователем, аналитиком данных или просто имеете дело с большим объемом PDF-файлов, возможность конвертировать PDF-файлы в редактируемый текстовый формат может сэкономить вам драгоценное время и усилия. Именно здесь на помощь приходит Python, универсальный и мощный язык программирования с его обширными возможностями преобразования PDF в текст на Python.

В этой статье мы рассмотрим, как использовать Python для преобразования PDF в текст преобразование, раскрывающее возможности Python при обработке PDF-файлов. Эта статья включает в себя следующие темы:
- API Python для преобразования PDF в текст
- Руководство по преобразованию PDF в текст в Python
- Python для преобразования PDF в текст без сохранения макета
- Python для преобразования PDF в текст и сохранения макета
- Python для преобразования указанной области страницы PDF в текст
- Получите бесплатную лицензию на API для преобразования PDF в текст на Python
- Узнайте больше об обработке PDF с помощью Python
API Python для преобразования PDF в текст
Чтобы использовать Python для преобразования PDF в текст, необходим API обработки PDF — Spire.PDF for Python Эта библиотека Python предназначена для манипулирования PDF-документами в программах Python, что расширяет возможности программ Python различными возможностями обработки PDF-файлов.
Мы можем скачать Spire.PDF for Python и добавьте его в наш проект или просто установите через PyPI с помощью следующего кода:
pip install Spire.PDF
Руководство по преобразованию PDF в текст в Python
Прежде чем мы приступим к преобразованию PDF в текст с помощью Python, давайте посмотрим на основные преимущества, которые он может нам предложить:
- Возможность редактирования: Преобразование PDF в текст упрощает редактирование документа, поскольку текстовые файлы можно открывать и редактировать на большинстве устройств.
- Доступность: Текстовые файлы обычно более доступны, чем PDF-файлы. Будь то настольный компьютер или мобильный телефон, текстовые файлы можно легко просматривать на устройствах.
- Интеграция с другими приложениями: Текстовые файлы можно легко интегрировать в различные приложения и рабочие процессы.
Шаги по преобразованию PDF-документов в текстовые файлы на Python:
- Установите Spire.PDF for Python.
- Импортируйте модули.
- Создайте объект класса PdfDocument и загрузите PDF-файл с помощью метода LoadFromFile().
- Создайте объект класса PdfTextExtractOptions и установите параметры извлечения текста, включая извлечение всего текста, отображение скрытого текста, извлечение текста только в указанной области и простое извлечение.
- Получите страницу в документе с помощью метода PdfDocument.Pages.get_Item() и создайте объекты PdfTextExtractor на основе каждой страницы для извлечения текста со страницы с помощью метода Extract() с указанными параметрами.
- Сохраните извлеченный текст как текстовый файл и закройте объект PdfDocument.
Python для преобразования PDF в текст без сохранения макета
При использовании простого метода извлечения для извлечения текста из PDF программа не сохраняет пустые области, отслеживает текущую позицию Y каждой строки и вставляет разрыв строки в выходные данные, если позиция Y изменилась.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
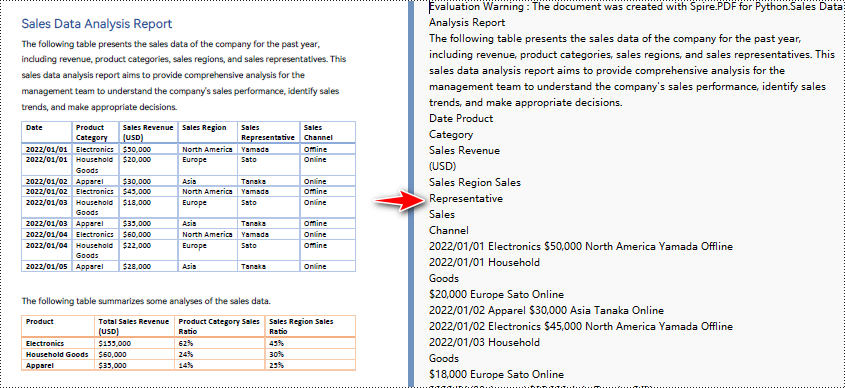
Python для преобразования PDF в текст и сохранения макета
При использовании метода извлечения по умолчанию для извлечения текста из PDF программа будет извлекать текст построчно, включая пробелы.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
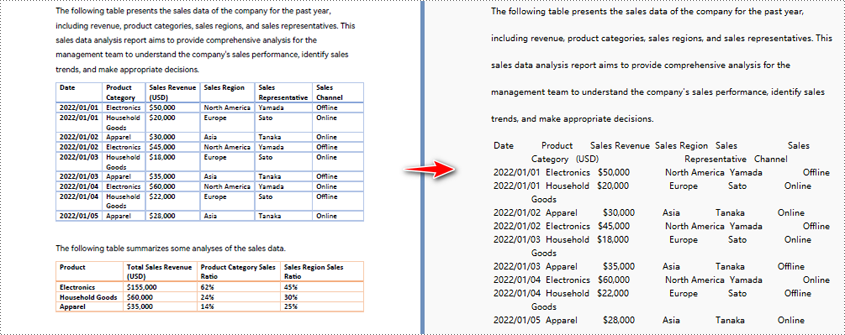
Python для преобразования указанной области страницы PDF в текст
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
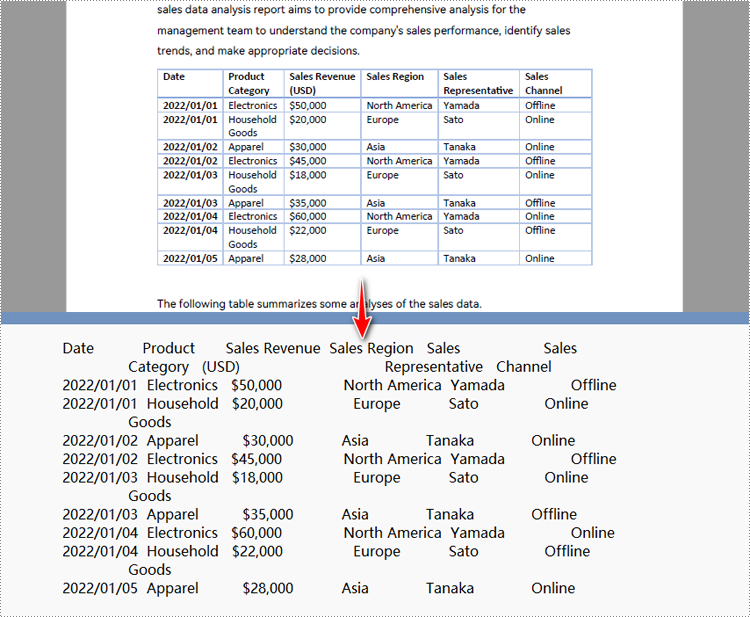
Получите бесплатную лицензию на API для преобразования PDF в текст на Python
Пользователи могут подать заявку на получение бесплатной временной лицензии попробовать Spire.PDF for Python и оценить возможности Python PDF в текст без каких-либо ограничений.
Узнайте больше об обработке PDF с помощью Python
Помимо преобразования PDF в текст с помощью Python, мы также можем изучить дополнительные функции обработки PDF с помощью этого API из следующих источников:
- Как извлечь текст из PDF-документов с помощью Python
- Учебники по обработке PDF с помощью Python
- Преобразование PDF-документов на основе изображений в текст (OCR)
Заключение
В этом сообщении блога мы изучили Python в преобразовании PDF в текст. Следуя инструкциям и обращаясь к примерам кода в статье, мы можем добиться быстрого Преобразование PDF в текст в Python программы. Кроме того, в статье представлены преимущества преобразования PDF-документов в текстовые файлы. Что еще более важно, мы можем получить дополнительные знания об обработке PDF-документов с помощью Python и методах преобразования PDF-документов на основе изображений в текст с помощью инструментов OCR из ссылок в статье. Если при использовании Spire.PDF for Python возникнут какие-либо проблемы, техническую поддержку можно получить, обратившись к нашей команде через Форум Spire.PDF или электронная почта.
