Table des matières
Installer avec Pip
pip install Spire.PDF
Liens connexes
À l’ère numérique d’aujourd’hui, la capacité d’extraire rapidement et efficacement des informations à partir de documents PDF est cruciale pour diverses industries et professionnels. Que vous soyez chercheur, analyste de données ou que vous traitiez simplement un grand volume de fichiers PDF, la possibilité de convertir des PDF au format texte modifiable peut vous faire gagner un temps et des efforts précieux. C'est là que Python, un langage de programmation polyvalent et puissant, vient à la rescousse avec ses fonctionnalités étendues de conversion de PDF en texte en Python.

Dans cet article, nous explorerons comment utiliser Python pour PDF en texte conversion, libérant la puissance de Python dans le traitement des fichiers PDF. Cet article comprend les sujets suivants :
- API Python pour la conversion de PDF en texte
- Guide de conversion de PDF en texte en Python
- Python pour convertir un PDF en texte sans conserver la mise en page
- Python pour convertir un PDF en texte et conserver la mise en page
- Python pour convertir une zone de page PDF spécifiée en texte
- Obtenez une licence gratuite pour l'API permettant de convertir un PDF en texte en Python
- En savoir plus sur le traitement PDF avec Python
API Python pour la conversion de PDF en texte
Pour utiliser Python pour la conversion de PDF en texte, une API de traitement PDF – Spire.PDF for Python est nécessaire. Cette bibliothèque Python est conçue pour la manipulation de documents PDF dans les programmes Python, ce qui donne aux programmes Python diverses capacités de traitement PDF.
Nous pouvons télécharger Spire.PDF for Python et ajoutez-le à notre projet, ou installez-le simplement via PyPI avec le code suivant :
pip install Spire.PDF
Guide de conversion de PDF en texte en Python
Avant de procéder à la conversion de PDF en texte à l'aide de Python, examinons les principaux avantages qu'il peut nous offrir :
- Modifiable: la conversion d'un PDF en texte vous permet de modifier le document plus facilement, car les fichiers texte peuvent être ouverts et modifiés sur la plupart des appareils.
- Accessibilité: les fichiers texte sont généralement plus accessibles que les PDF. Qu'il s'agisse d'un ordinateur de bureau ou d'un téléphone mobile, les fichiers texte peuvent être facilement visualisés sur des appareils.
- Intégration avec d'autres applications: les fichiers texte peuvent être intégrés de manière transparente dans diverses applications et flux de travail.
Étapes pour convertir des documents PDF en fichiers texte en Python :
- Installez Spire.PDF for Python.
- Importer des modules.
- Créez un objet de la classe PdfDocument et chargez un fichier PDF à l'aide de la méthode LoadFromFile().
- Créez un objet de la classe PdfTextExtractOptions et définissez les options d'extraction de texte, notamment l'extraction de tout le texte, l'affichage du texte masqué, l'extraction uniquement du texte dans une zone spécifiée et l'extraction simple.
- Obtenez une page du document à l'aide de la méthode PdfDocument.Pages.get_Item() et créez des objets PdfTextExtractor basés sur chaque page pour extraire le texte de la page à l'aide de la méthode Extract() avec les options spécifiées.
- Enregistrez le texte extrait en tant que fichier texte et fermez l'objet PdfDocument.
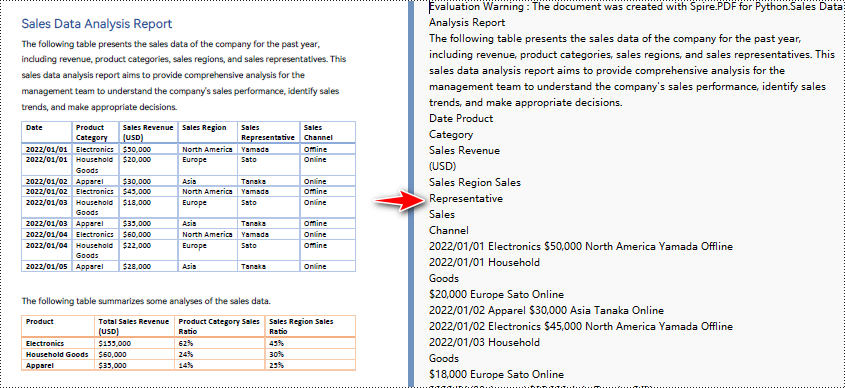
Python pour convertir un PDF en texte sans conserver la mise en page
Lorsque vous utilisez la méthode d'extraction simple pour extraire du texte à partir d'un PDF, le programme ne conservera pas les zones vides, ne gardera pas trace de la position Y actuelle de chaque chaîne et n'insérera pas un saut de ligne dans la sortie si la position Y a changé.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
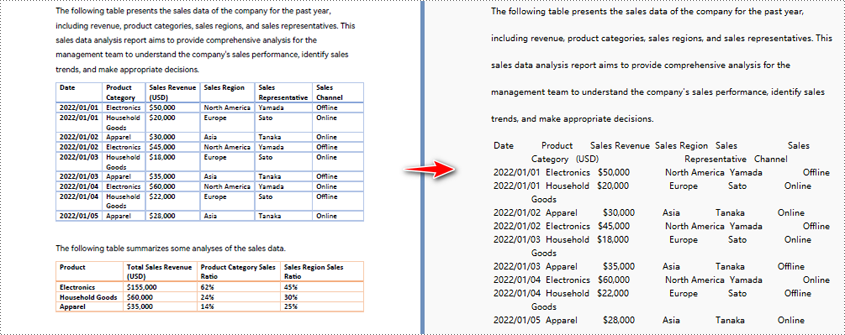
Python pour convertir un PDF en texte et conserver la mise en page
Lorsque vous utilisez la méthode d'extraction par défaut pour extraire le texte d'un PDF, le programme extraira le texte ligne par ligne, y compris les espaces.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
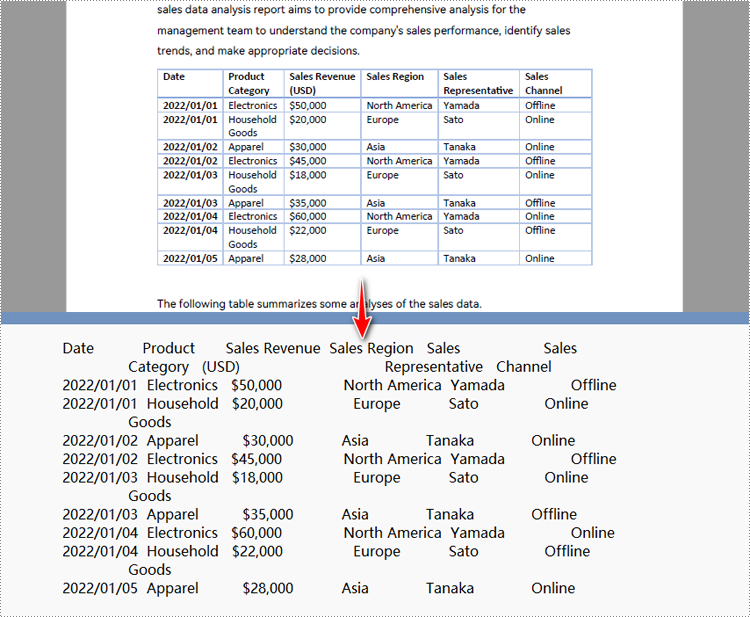
Python pour convertir une zone de page PDF spécifiée en texte
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Obtenez une licence gratuite pour l'API permettant de convertir un PDF en texte en Python
Les utilisateurs peuvent demander une licence temporaire gratuite pour essayer Spire.PDF for Python et évaluer les fonctionnalités de conversion Python PDF en texte sans aucune limitation.
En savoir plus sur le traitement PDF avec Python
Outre la conversion de PDF en texte avec Python, nous pouvons également explorer davantage de fonctionnalités de traitement PDF de cette API via les sources suivantes :
- Comment extraire du texte de documents PDF avec Python
- Tutoriels pour le traitement PDF avec Python
- Conversion de documents PDF basés sur des images en texte (OCR)
Conclusion
Dans cet article de blog, nous avons exploré Python dans la conversion PDF en texte. En suivant les étapes opérationnelles et en vous référant aux exemples de code dans l'article, nous pouvons réaliser rapidement Conversion de PDF en texte en Python programmes. De plus, l'article donne un aperçu des avantages de la conversion de documents PDF en fichiers texte. Plus important encore, nous pouvons acquérir des connaissances supplémentaires sur la gestion des documents PDF avec Python et les méthodes permettant de convertir des documents PDF basés sur des images en texte via les outils OCR à partir des références contenues dans l'article. Si des problèmes surviennent lors de l'utilisation de Spire.PDF for Python, une assistance technique peut être obtenue en contactant notre équipe via le Forum Spire.PDF ou email.
