Sommario
Installa con Pip
pip install Spire.PDF
Link correlati
Nell'era digitale di oggi, la capacità di estrarre informazioni dai documenti PDF in modo rapido ed efficiente è fondamentale per vari settori e professionisti. Che tu sia un ricercatore, un analista di dati o semplicemente hai a che fare con un grande volume di file PDF, la possibilità di convertire i PDF in un formato di testo modificabile può farti risparmiare tempo e fatica preziosi. È qui che Python, un linguaggio di programmazione versatile e potente, viene in soccorso con le sue estese funzionalità per convertire PDF in testo in Python.

In questo articolo esploreremo come utilizzarlo Python per PDF in testo conversione, liberando la potenza di Python nell'elaborazione dei file PDF. Questo articolo include i seguenti argomenti:
- API Python per la conversione da PDF a testo
- Guida per convertire PDF in testo in Python
- Python per convertire PDF in testo senza mantenere il layout
- Python per convertire PDF in testo e mantenere il layout
- Python per convertire un'area della pagina PDF specificata in testo
- Ottieni una licenza gratuita per l'API per convertire PDF in testo in Python
- Ulteriori informazioni sull'elaborazione dei PDF con Python
API Python per la conversione da PDF a testo
Per utilizzare Python per la conversione da PDF a testo, è necessaria un'API di elaborazione PDF: Spire.PDF for Python. Questa libreria Python è progettata per la manipolazione di documenti PDF nei programmi Python, che fornisce ai programmi Python varie capacità di elaborazione PDF.
Possiamo scaricare Spire.PDF for Python e aggiungilo al nostro progetto o semplicemente installalo tramite PyPI con il seguente codice:
pip install Spire.PDF
Guida per convertire PDF in testo in Python
Prima di procedere con la conversione di PDF in testo utilizzando Python, diamo un'occhiata ai principali vantaggi che può offrirci:
- Modificabilità: la conversione di PDF in testo consente di modificare il documento più facilmente, poiché i file di testo possono essere aperti e modificati sulla maggior parte dei dispositivi.
- Accessibilità: i file di testo sono generalmente più accessibili dei PDF. Che si tratti di un desktop o di un telefono cellulare, i file di testo possono essere visualizzati facilmente sui dispositivi.
- Integrazione con altre applicazioni: i file di testo possono essere perfettamente integrati in varie applicazioni e flussi di lavoro.
Passaggi per convertire documenti PDF in file di testo in Python:
- Installa Spire.PDF for Python.
- Importa moduli.
- Crea un oggetto della classe PdfDocument e carica un file PDF utilizzando il metodo LoadFromFile().
- Crea un oggetto della classe PdfTextExtractOptions e imposta le opzioni di estrazione del testo, inclusa l'estrazione di tutto il testo, la visualizzazione del testo nascosto, l'estrazione solo del testo in un'area specifica e l'estrazione semplice.
- Ottieni una pagina nel documento utilizzando il metodo PdfDocument.Pages.get_Item() e crea oggetti PdfTextExtractor basati su ciascuna pagina per estrarre il testo dalla pagina utilizzando il metodo Extract() con le opzioni specificate.
- Salva il testo estratto come file di testo e chiudi l'oggetto PdfDocument.
Python per convertire PDF in testo senza mantenere il layout
Quando si utilizza il metodo di estrazione semplice per estrarre testo da PDF, il programma non manterrà le aree vuote e terrà traccia della posizione Y corrente di ciascuna stringa e inserirà un'interruzione di riga nell'output se la posizione Y è cambiata.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
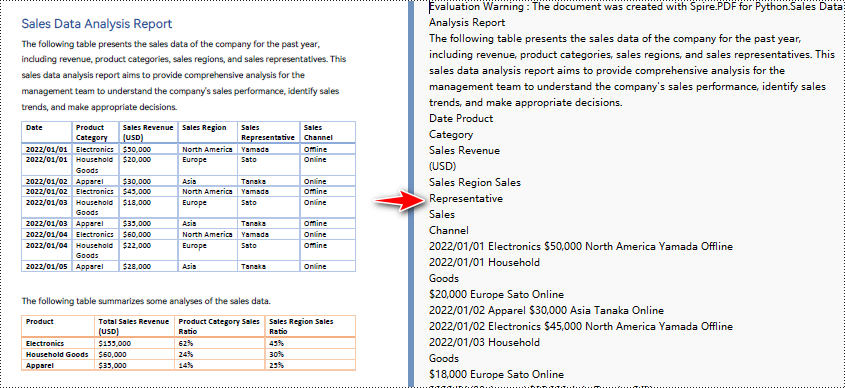
Python per convertire PDF in testo e mantenere il layout
Quando si utilizza il metodo di estrazione predefinito per estrarre testo da PDF, il programma estrarrà il testo riga per riga, compresi gli spazi vuoti.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
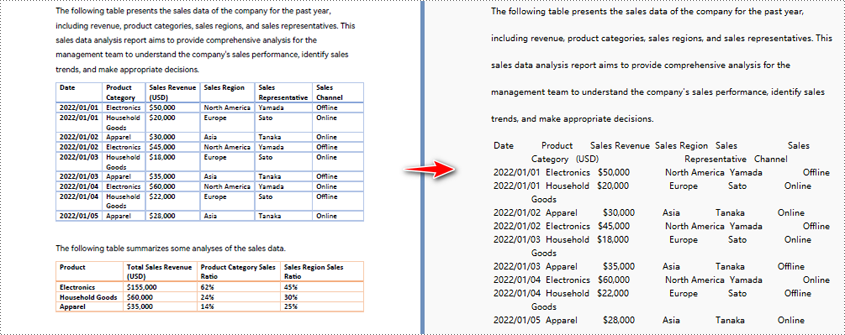
Python per convertire un'area della pagina PDF specificata in testo
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
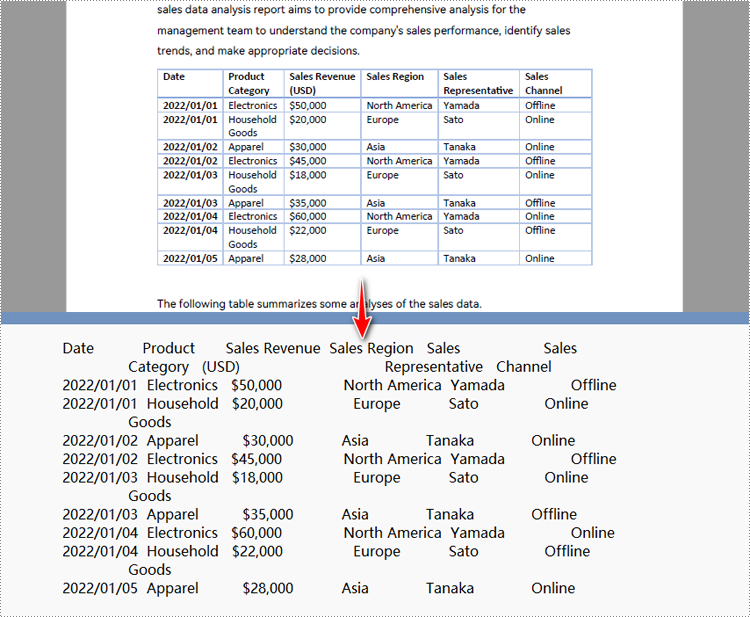
Ottieni una licenza gratuita per l'API per convertire PDF in testo in Python
Gli utenti possono richiedere una licenza temporanea gratuita per provare Spire.PDF for Python e valutare le funzionalità di conversione da PDF a testo di Python senza alcuna limitazione.
Ulteriori informazioni sull'elaborazione dei PDF con Python
Oltre a convertire PDF in testo con Python, possiamo anche esplorare altre funzionalità di elaborazione PDF di questa API attraverso le seguenti fonti:
- Come estrarre testo da documenti PDF con Python
- Tutorial per l'elaborazione di PDF con Python
- Conversione di documenti PDF basati su immagini in testo (OCR)
Conclusione
In questo post del blog, abbiamo esplorato Python nella conversione da PDF a testo. Seguendo i passaggi operativi e facendo riferimento agli esempi di codice nell'articolo, possiamo ottenere risultati rapidi Conversione da PDF a testo in Python programmi. Inoltre, l'articolo fornisce approfondimenti sui vantaggi della conversione di documenti PDF in file di testo. Ancora più importante, possiamo acquisire ulteriori conoscenze sulla gestione dei documenti PDF con Python e sui metodi per convertire documenti PDF basati su immagini in testo tramite strumenti OCR dai riferimenti nell'articolo. Se si verificano problemi durante l'utilizzo di Spire.PDF for Python, è possibile ottenere supporto tecnico contattando il nostro team tramite il forum Spire.PDF o tramite e-mail.
