Tabla de contenido
Instalar con Pip
pip install Spire.PDF
enlaces relacionados
En la era digital actual, la capacidad de extraer información de documentos PDF de forma rápida y eficiente es crucial para diversas industrias y profesionales. Ya sea que sea investigador, analista de datos o simplemente trabaje con un gran volumen de archivos PDF, poder convertir archivos PDF a formato de texto editable puede ahorrarle tiempo y esfuerzo valiosos. Aquí es donde Python, un lenguaje de programación potente y versátil, viene al rescate con sus amplias funciones para convertir PDF a texto en Python.

En este artículo, exploraremos cómo usar Python para PDF a texto conversión, liberando el poder de Python en el procesamiento de archivos PDF. Este artículo incluye los siguientes temas:
- API de Python para conversión de PDF a texto
- Guía para convertir PDF a texto en Python
- Python para convertir PDF a texto sin mantener el diseño
- Python para convertir PDF a texto y mantener el diseño
- Python para convertir un área de página PDF especificada en texto
- Obtenga una licencia gratuita para la API para convertir PDF a texto en Python
- Obtenga más información sobre el procesamiento de PDF con Python
API de Python para conversión de PDF a texto
Para utilizar Python para la conversión de PDF a texto, se necesita una API de procesamiento de PDF: Spire.PDF for Python. Esta biblioteca de Python está diseñada para la manipulación de documentos PDF en programas Python, lo que permite a los programas Python varias capacidades de procesamiento de PDF.
Podemos descargar Spire.PDF for Python y agregarlo a nuestro proyecto, o simplemente instalarlo a través de PyPI con el siguiente código:
pip install Spire.PDF
Guía para convertir PDF a texto en Python
Antes de continuar con la conversión de PDF a texto usando Python, veamos las principales ventajas que nos puede ofrecer:
- Editabilidad: Convertir PDF a texto le permite editar el documento más fácilmente, ya que los archivos de texto se pueden abrir y editar en la mayoría de los dispositivos.
- Accesibilidad: los archivos de texto son generalmente más accesibles que los PDF. Ya sea una computadora de escritorio o un teléfono móvil, los archivos de texto se pueden ver en los dispositivos con facilidad.
- Integración con otras aplicaciones: los archivos de texto se pueden integrar perfectamente en varias aplicaciones y flujos de trabajo.
Pasos para convertir documentos PDF a archivos de texto en Python:
- Instale Spire.PDF for Python.
- Importar módulos.
- Cree un objeto de la clase PdfDocument y cargue un archivo PDF usando el método LoadFromFile().
- Cree un objeto de la clase PdfTextExtractOptions y configure las opciones de extracción de texto, incluida la extracción de todo el texto, la visualización de texto oculto, la extracción solo de texto en un área específica y la extracción simple.
- Obtenga una página en el documento usando el método PdfDocument.Pages.get_Item() y cree objetos PdfTextExtractor basados en cada página para extraer el texto de la página usando el método Extract() con opciones específicas.
- Guarde el texto extraído como un archivo de texto y cierre el objeto PdfDocument.
Python para convertir PDF a texto sin mantener el diseño
Cuando se utiliza el método de extracción simple para extraer texto de un PDF, el programa no retendrá las áreas en blanco ni realizará un seguimiento de la posición Y actual de cada cadena ni insertará un salto de línea en la salida si la posición Y ha cambiado.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
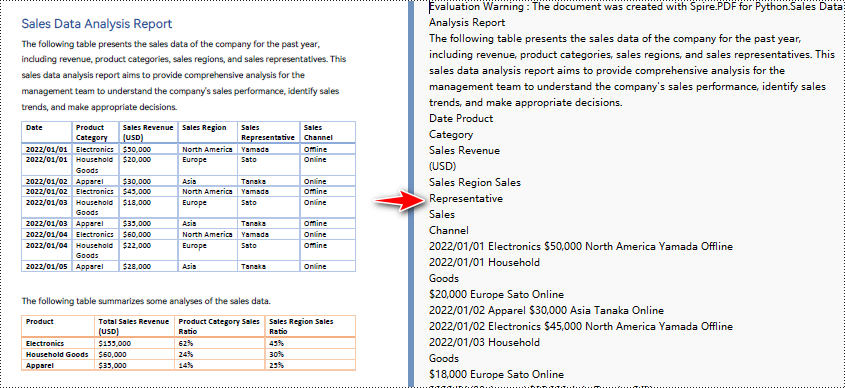
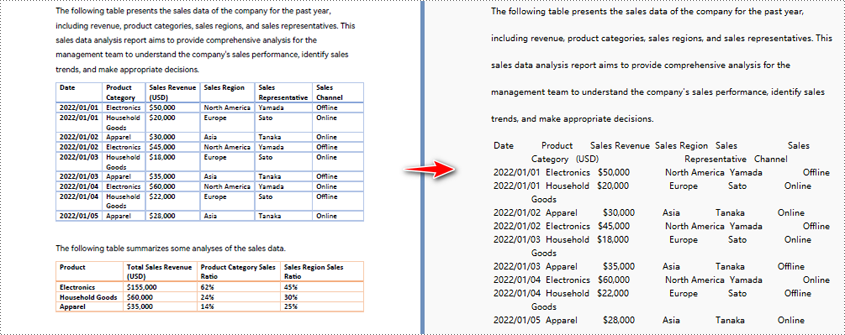
Python para convertir PDF a texto y mantener el diseño
Cuando se utiliza el método de extracción predeterminado para extraer texto de un PDF, el programa extraerá el texto línea por línea, incluidos los espacios en blanco.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
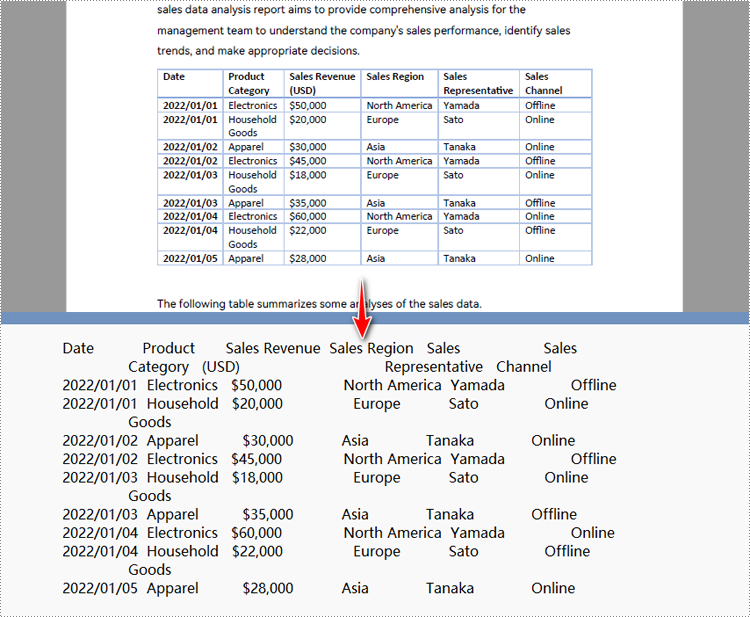
Python para convertir un área de página PDF especificada en texto
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Obtenga una licencia gratuita para la API para convertir PDF a texto en Python
Los usuarios pueden solicitar una licencia temporal gratuita Pruebe Spire.PDF for Python y evalúe las funciones de conversión de PDF a texto de Python sin ninguna limitación.
Obtenga más información sobre el procesamiento de PDF con Python
Además de convertir PDF a texto con Python, también podemos explorar más funciones de procesamiento de PDF de esta API a través de las siguientes fuentes:
- Cómo extraer texto de documentos PDF con Python
- Tutoriales para el procesamiento de PDF con Python
- Conversión de documentos PDF basados en imágenes a texto (OCR)
Conclusión
En esta publicación de blog, hemos explorado Python en conversión de PDF a texto. Siguiendo los pasos operativos y consultando los ejemplos de código del artículo, podemos lograr resultados rápidos Conversión de PDF a texto en Python programas. Además, el artículo proporciona información sobre los beneficios de convertir documentos PDF en archivos de texto. Más importante aún, podemos obtener más conocimientos sobre el manejo de documentos PDF con Python y métodos para convertir documentos PDF basados en imágenes en texto a través de herramientas OCR a partir de las referencias del artículo. Si surge algún problema durante el uso de Spire.PDF for Python, puede obtener asistencia técnica comunicándose con nuestro equipo a través del foro de Spire.PDF o por correo electrónico.
