Spire.Office for Java 9.1.10 is released
We are excited to announce the release of Spire.Office for Java 9.1.10. In this version, Spire.PDF for Java adds two new methods for decrypting PDF; Spire.Doc for Java optimizes the exception catching for loading non-existent documents; Spire.Barcode for Java supports adding pictures to the center of QR code. Moreover, a lot of known issues are fixed in this version. More details are listed below.
Here is a list of changes made in this release
Spire.PDF for Java
| Category | ID | Description |
| New feature | SPIREPDF-6479 | Adds two new methods for decrypting PDFs.
PdfDocument pdf1 =new PdfDocument();
pdf1.loadFromFile("input.pdf");
pdf1.decrypt();
pdf1.saveToFile("output.pdf");
PdfDocument pdf2 =new PdfDocument();
pdf2.loadFromFile("input.pdf");
pdf2.decrypt(ownerPassword);
pdf2.saveToFile("output.pdf");
|
| Bug | SPIREPDF-6429 | Fixes the issue that the program threw "java.lang.NullPointerException" when converting OFD to PDF. |
| Bug | SPIREPDF-6482 | Fixes the issue that the program hung when converting PDF to images. |
| Bug | SPIREPDF-6485 | Fixes the issue that the content was lost after converting OFD to PDF. |
| Bug | SPIREPDF-6486 | Fixes the issue that the program threw "java.lang.NullPointerException" when converting PDF to XLSX. |
| Bug | SPIREPDF-6502 | Fixes the issue that the content was garbled after replacing text. |
Spire.Doc for Java
| Category | ID | Description |
| New feature | SPIREDOC-10090 | Addes the Bookmark.getFirstColumn() method and the Bookmark.getLastColumn() method. |
| New feature | SPIREDOC-10163 | Optimizes the exception catching mechanism when loading non-existent document paths. |
| Bug | SPIREDOC-8257 | Fixed the issue that the paging was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8568 SPIREDOC-9172 |
Fixed the issue that the content was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8586 | Fixed the issue that the header moved down when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8797 | Fixed the issue that combined graphics were drawn incorrectly when converting Docx documents to HTML documents. |
| Bug | SPIREDOC-9069 | Fixed the issue that checkbox checkmarks were missing and an extra page occurred when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9577 | Fixed the issue that the program threw java.lang.ArrayIndexOutOfBoundsException when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9611 | Fixed the issue that some contents were lost and the formatting was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9709 | Fixed the issue that the program threw "No have this value 63" error when loading Doc documents. |
| Bug | SPIREDOC-9713 | Fixed the issue that the position of pictures was wrong when converting Doc documents to PDF documents. |
| Bug | SPIREDOC-9763 | Fixed the issue that the effect of accepting revisions was incorrect. |
| Bug | SPIREDOC-9783 | Fixed the issue that images and text overlapped when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9799 | Fixed the issue that fonts and paragraph styles were changed after replacing the contents of bookmarks. |
| Bug | SPIREDOC-10011 | Fixed the issue that header contents were displayed incorrectly after converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10015 | Fixed the issue that table styles were incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10040 | Fix the issue that the program threw an "Argument path cannot be empty" error when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10054 | Fixed the issue that images are displayed incorrectly when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10074 | Fixed the issue that tables were lost and table height was increased when converting Doc documents to PDF documents. |
| Bug | SPIREDOC-10143 | Fixed the issue that the program threw "java.lang.IllegalStateException: Wrong Word version" error when loading Docx documents encrypted with WPS. |
| Bug | SPIREDOC-10148 | Fixed the issue that directory jumps were incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10157 | Fixed an issue that the markup adding to a document using the BuiltinDocumentProperties.setKeyWord() method failed. |
| Bug | SPIREDOC-10179 | Fixed the issue that page number formatting changed after converting a Docx document to a PDF document. |
Spire.Barcode for Java
| Category | ID | Description |
| New feature | - | The method for applying a license has been changed to com.spire.barcode.license.LicenseProvider.setLicenseKey(key). |
| New feature | SPIREBARCODE-244 | Supports adding pictures to the center of QR code.
BarcodeSettings barCodeSetting = new BarcodeSettings();
BufferedImage image = ImageIO.read(new File("Image/1.png"));
barCodeSetting.setQRCodeLogoImage(image);
|
| Bug | SPIREBARCODE-243 | Fixes the issue that barcode recognition failed in vertical orientation. |
Spire.Presentation 9.1.5 supports embedding fonts in PPTX
We are pleased to announce the release of Spire.Presentation 9.1.5. This version supports embedding fonts in PPTX and provides the IsHidden property to determine whether the Ole object is hidden. In addition, some known issues have been fixed, such as the issue that the program threw "Microsoft PowerPoint 2007 file is corrpt." when loading a PPTX file when the system language was set to Turkish. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Support embedding fonts in PPTX: only supports embedding fonts into PPTX format, and does not support embedding into PDF and PowerPoint 2003 formats; when embedding Chinese name fonts, the font names are not displayed in Chinese.
ppt.AddEmbeddedFont(string fontpath); |
| New feature | SPIREPPT-2424 | Provides the IsHidden property to determine whether the Ole object is hidden.
OleObjectCollection oles = ppt.Slides[0].OleObjects; OleObject ole= oles[0]; bool result=ole.IsHidden; |
| Bug | SPIREPPT-2418 | Fixes the issue that the program threw "Microsoft PowerPoint 2007 file is corrpt." exception when loading a PPTX file when the system regional language was set to Turkish. |
| Bug | SPIREPPT-2396 | Fixes the issue that the effect was incorrect after changing the chart label position. |
Spire.Doc for Java 12.1.16 optimizes the exception catching for loading non-existent documents
We are excited to announce the release of Spire.Doc for Java 12.1.16. This version add the Bookmark.getFirstColumn() method and the Bookmark.getLastColumn() method, and optimizes the exception catching mechanism when loading a non-existent document path. It also enhances the conversion from Word to PDF and HTML. Besides, some known issues are fixed successfully in this version, such as the issue that the effect of accepting revisions was incorrect. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREDOC-10090 | Addes the Bookmark.getFirstColumn() method and the Bookmark.getLastColumn() method. |
| New feature | SPIREDOC-10163 | Optimizes the exception catching mechanism when loading non-existent document paths. |
| Bug | SPIREDOC-8257 | Fixed the issue that the paging was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8568 SPIREDOC-9172 |
Fixed the issue that the content was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8586 | Fixed the issue that the header moved down when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8797 | Fixed the issue that combined graphics were drawn incorrectly when converting Docx documents to HTML documents. |
| Bug | SPIREDOC-9069 | Fixed the issue that checkbox checkmarks were missing and an extra page occurred when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9577 | Fixed the issue that the program threw java.lang.ArrayIndexOutOfBoundsException when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9611 | Fixed the issue that some contents were lost and the formatting was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9709 | Fixed the issue that the program threw "No have this value 63" error when loading Doc documents. |
| Bug | SPIREDOC-9713 | Fixed the issue that the position of pictures was wrong when converting Doc documents to PDF documents. |
| Bug | SPIREDOC-9763 | Fixed the issue that the effect of accepting revisions was incorrect. |
| Bug | SPIREDOC-9783 | Fixed the issue that images and text overlapped when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9799 | Fixed the issue that fonts and paragraph styles were changed after replacing the contents of bookmarks. |
| Bug | SPIREDOC-10011 | Fixed the issue that header contents were displayed incorrectly after converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10015 | Fixed the issue that table styles were incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10040 | Fix the issue that the program threw an "Argument path cannot be empty" error when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10054 | Fixed the issue that images are displayed incorrectly when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10074 | Fixed the issue that tables were lost and table height was increased when converting Doc documents to PDF documents. |
| Bug | SPIREDOC-10143 | Fixed the issue that the program threw "java.lang.IllegalStateException: Wrong Word version" error when loading Docx documents encrypted with WPS. |
| Bug | SPIREDOC-10148 | Fixed the issue that directory jumps were incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10157 | Fixed an issue that the markup adding to a document using the BuiltinDocumentProperties.setKeyWord() method failed. |
| Bug | SPIREDOC-10179 | Fixed the issue that page number formatting changed after converting a Docx document to a PDF document. |
Spire.PDF 10.1.17 enhances the conversion from PDF to images and OFD
We are happy to announce the release of Spire.PDF 10.1.17. This version enhances the conversion from PDF to images and OFD as well as OFD and HTML to PDF. Moreover, some known issues are fixed in this version, such as the issue that content overlapped after replacing text. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREPDF-6278 | Fixes the issue that the result of drawing HTML text using PdfHTMLTextElement interface was incorrect. |
| Bug | SPIREPDF-6400 | Fixes the issue that the program threw System.OutOfMemoryException when saving a document after adding a bookmark. |
| Bug | SPIREPDF-6426 | Fixes the issue that content overlapped after replacing text. |
| Bug | SPIREPDF-6430 | Fixes the issue that the program threw System.IndexOutOfRangeException when converting OFD documents to PDF documents. |
| Bug | SPIREPDF-6445 | Fixes the issue that the program threw System.Collections.Generic.KeyNotFoundException when extracting tables. |
| Bug | SPIREPDF-6471 | Fixes the issue that the program threw System.ArgumentException when saving a page as an image after rotating it. |
| Bug | SPIREPDF-6473 | Fixes the issue that colored emoticons became black and white when converting HTML to PDF. |
| Bug | SPIREPDF-6477 | Fixes the issue that the content was incorrect after converting a PDF document to an image. |
| Bug | SPIREPDF-6480 | Fixes the issue that the program threw a System.NullReferenceException when printing PDF documents. |
| Bug | SPIREPDF-6483 | Fixes the issue that some text lost its bold style after converting a PDF document to an OFD document. |
Convert Excel to PDF in C#
Table of Contents
Installed via NuGet
PM> Install-Package Spire.XLS
Related Links
PDF is a widely accepted and platform-independent file format. Converting Excel to PDF ensures that the document can be accessed and viewed by anyone with a PDF reader, thereby eliminating compatibility issues and guaranteeing consistent presentation of the data.
Furthermore, PDF files are usually read-only. In regulated industries, such as finance, healthcare, or legal sectors, compliance requirements may dictate that documents should be in non-editable formats. Converting Excel to PDF helps fulfill these regulatory obligations, ensuring data integrity and authenticity.
This article will give three examples to demonstrate how to use C# to convert Excel to PDF.
- Convert Excel XLS XLSX to PDF in C#
- Convert a Specific Worksheet to PDF in C#
- Convert Each Worksheet to a Separate PDF File in C#
C# Excel to PDF Converter Library
To use C# for Excel to PDF conversion, Spire.XLS for .NET library is required. It is a powerful library that provides full support for working with Excel files in .NET platforms. It gives developers the flexibility to convert Excel to a variety of file formats such as Excel to PDF, Excel to HTML, Excel to image, Excel to CSV, etc., enabling seamless integration with different applications and systems.
Installation:
Before getting started, download the C# Excel to PDF converter to manually add the DLL files as references in your .NET project. Or install it directly via NuGet.
PM> Install-Package Spire.XLS
Classes and Properties:
Once installed, you can use the following classes, properties and methods provided by the Spire.XLS for .NET library to programmatically convert Excel to PDF in C#.
| Item | Description |
| Workbook class | Represents an Excel workbook. |
| Worksheet class | Represents a worksheet in a workbook. |
| ConverterSetting class | Represents the Excel to PDF conversion options |
| PageSetup Class | Represents the page setup of a worksheet. |
| Workbook.LoadFromFile() method | Loads an Excel workbook. |
| Workbook.Worksheets[] property | Gets a specific worksheet by index. |
| ConverterSetting.SheetFitToPage property | Renders the worksheet on a single PDF page. |
| Worksheet.PageSetup property | Returns a PageSetup object that contains all the page setup attributes such as margins, paper size, etc. |
| Workbook.SaveToFile(string fileName, FileFormat.PDF) method | Save the Excel workbook as a PDF file. |
| Worksheet.SaveToPdf() method | Save the Excel worksheet as a PDF file. |
Convert Excel XLS XLSX to PDF in C#
To save Excel as PDF in C#, simply load a .xls or .xlsx file, and then call the SaveToFile method to save it in PDF format. During the process, you can control the conversion settings through the ConverterSetting class.
The following code example shows how to convert an Excel (XLS/XLSX) file to PDF.
- Python
using Spire.Xls;
namespace ConvertExcelToPDF
{
class Program
{
static void Main(string[] args)
{
//Create a Workbook instance
Workbook workbook = new Workbook();
//Load a sample Excel file
workbook.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Planner.xlsx");
//Set worksheets to fit to page when converting
workbook.ConverterSetting.SheetFitToPage = true;
//Save Excel XLSX as PDF
workbook.SaveToFile("XlsxToPdf.pdf", FileFormat.PDF);
}
}
}
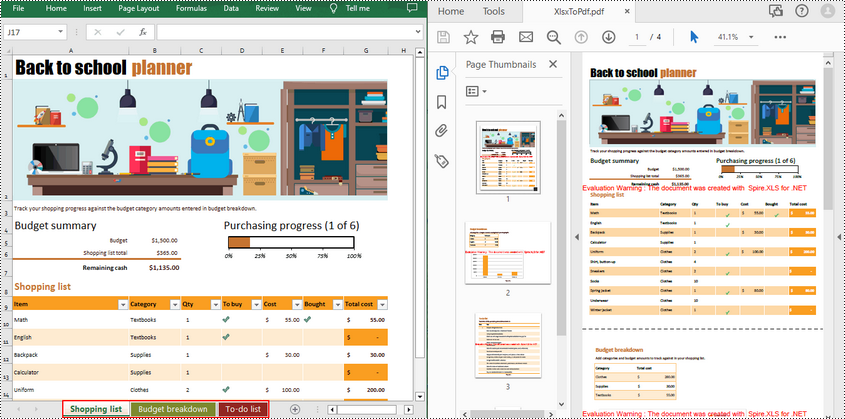
Convert a Specific Worksheet to PDF in C#
The Worksheet.SaveToPdf() method is used to save a specific worksheet as PDF. If you want to set the page margins, sizes, or other attributes of the worksheet to achieve a desired rendering effect, you can use the corresponding properties of the PageSetup Class.
The following code example shows how to convert a specific worksheet to PDF.
- Python
using Spire.Xls;
namespace ConvertWorksheetToPdf
{
class Program
{
static void Main(string[] args)
{
//Create a Workbook instance
Workbook workbook = new Workbook();
//Load a sample Excel file
workbook.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Planner.xlsx");
//Get the third worksheet
Worksheet sheet = workbook.Worksheets[2];
//Set page margins
sheet.PageSetup.TopMargin = 0.6;
sheet.PageSetup.BottomMargin = 0.6;
sheet.PageSetup.LeftMargin = 0.6;
sheet.PageSetup.RightMargin = 0.6;
//Set worksheet to fit to page when converting
workbook.ConverterSetting.SheetFitToPage = true;
//Convert the worksheet to PDF
sheet.SaveToPdf("WorksheetToPdf.pdf");
}
}
}
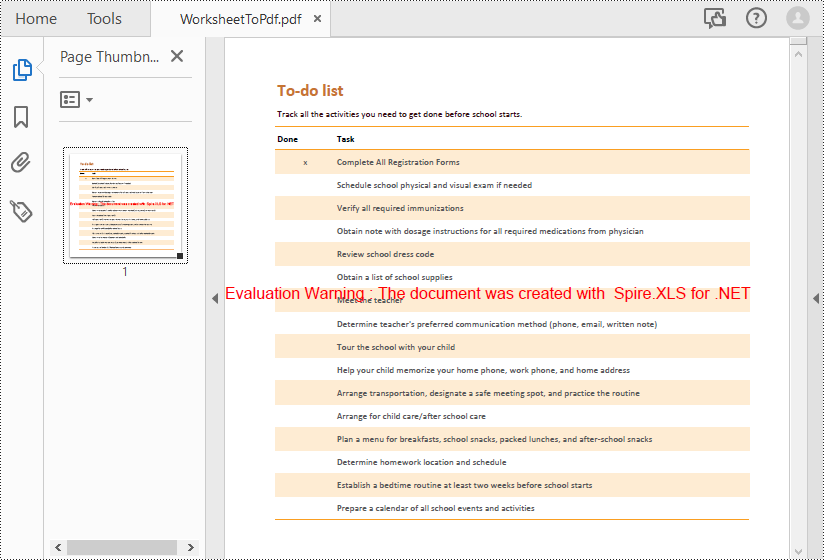
Convert Each Worksheet to a Separate PDF File in C#
The first code example converts each worksheet into a single page in a PDF file. With Spire.XLS for .NET library, it is also allowed to iterate through the worksheets and save each as a separate PDF file.
The following code example shows how to convert each worksheet in an Excel file to a separate PDF file.
- Python
using Spire.Xls;
namespace WorksheetToPdf
{
class Program
{
static void Main(string[] args)
{
//Create a Workbook instance
Workbook workbook = new Workbook();
//Load a sample Excel file
workbook.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Planner.xlsx");
//Set worksheets to fit to page when converting
workbook.ConverterSetting.SheetFitToPage = true;
//Iterate through the worksheets in the Excel file
foreach (Worksheet sheet in workbook.Worksheets)
{
//Convert each worksheet to a different PDF file
string FileName = sheet.Name + ".pdf";
sheet.SaveToPdf("Sheets\\" + FileName);
}
}
}
}
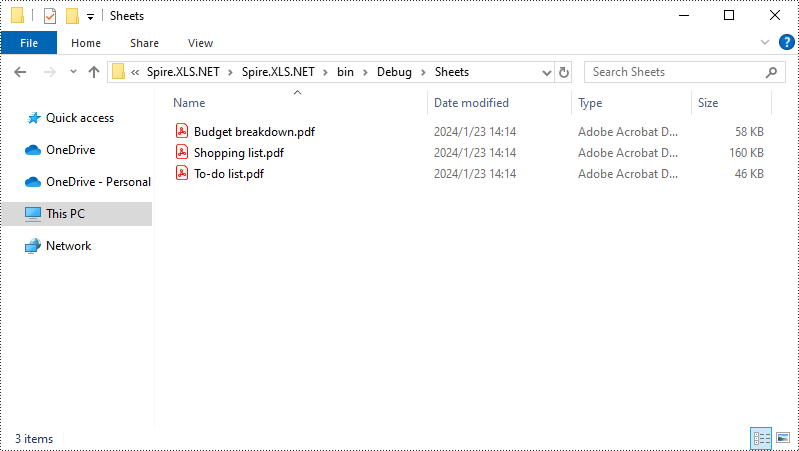
Free Excel to PDF Online Converter
Try this online converter to convert your Excel XLS or XLSX files to PDF format for free. But please be aware that the free converter only supports simple conversion without additional settings. You can upload an Excel file and wait a few seconds to get the Excel to PDF conversion done.
Conclusion
In this post, you have gained knowledge on how to use C# to convert Excel to PDF programmatically. The main classes, properties, and methods involved in the Excel to PDF conversion process have been thoroughly explained, and complete sample code for converting an Excel workbook or worksheet to PDF have also been provided.
To explore more about the Spire.XLS for .NET library, refer to the documentation, where you can find other Excel generation, processing, and conversion features along with the code examples.
Python: Remove Attachments from a PDF Document
The inclusion of attachments in a PDF can be useful for sharing related files or providing additional context and resources alongside the main document. However, there may be instances when you need to remove attachments from a PDF for reasons like reducing file size, protecting sensitive information, or simply decluttering the document. In this article, you will learn how to remove attachments from a PDF document in Python using Spire.PDF for Python.
- Remove Document-Level Attachments from PDF in Python
- Remove Annotation Attachments from PDF in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Prerequisite Knowledge
There are typically two types of attachments in PDF, document-level attachments and annotation attachments. The following table lists the differences between them and their representations in Spire.PDF.
| Attachment type | Represented by | Definition |
| Document level attachment | PdfAttachment class | A file attached to a PDF at the document level won't appear on a page, but can be viewed in the "Attachments" panel of a PDF reader. |
| Annotation attachment | PdfAnnotationAttachment class | A file attached as an annotation can be found on a page or in the "Attachment" panel. An annotation attachment is shown as a paper clip icon on the page; reviewers can double-click the icon to open the file. |
Remove Document-Level Attachments from PDF in Python
To obtain all document-level attachments of a PDF document, use the PdfDocument.Attachments property. Then, you can remove all of them using the Clear() method or selectively remove a specific attachment using the RemoveAt() method. The following are the steps to remove document-level attachments from PDF in Python.
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the attachment collection from the document using PdfDocument.Attachments property.
- Remove all attachments using PdfAttachmentCollection.Clear() method. To remove a specific attachment, use PdfAttachmentCollection.RemoveAt() method.
- Save the changes to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Attachments.pdf")
# Get the attachment collection from the document
attachments = doc.Attachments
# Remove all attachments
attachments.Clear()
# Remove a specific attachment
# attachments.RemoveAt(0)
# Save the changes to file
doc.SaveToFile("output/DeleteAttachments.pdf")
# Close the document
doc.Close()
Remove Annotation Attachments from PDF in Python
Annotations are page-based elements, and to retrieve all annotations from a document, you need to iterate through the pages and obtain the annotations from each page. Next, identify if a particular annotation is an attachment annotation, and finally remove it from the annotation collection using the RemoveAt() method.
The following are the steps to remove annotation attachments from PDF in Python.
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Iterate through the pages in the document
- Get the annotation collection from a specific page through PdfPageBase.AnnotationsWidget property.
- Iterate through the annotations in the collection.
- Determine if a specific annotation is an instance of PdfAttachmentAnnotationWidget.
- Remove the attachment annotation using PdfAnnotationCollection.RemoveAt() method.
- Save the changes to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\AnnotationAttachment.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get annotation collection from a certain page
annotationCollection = doc.Pages.get_Item(i).AnnotationsWidget
if annotationCollection.Count > 0:
# Iterate through the annotation in the collection
for j in range(annotationCollection.Count):
# Get a specific annotation
annotation = annotationCollection.get_Item(j)
# Determine if it is an attachment annotation
if isinstance(annotation, PdfAttachmentAnnotationWidget):
# Remove the annotation
annotationCollection.RemoveAt(j)
# Save the changes to file
doc.SaveToFile("output/DeleteAnnotationAttachment.pdf")
# Close the document
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.PDF for Java 10.1.9 adds two new methods for decrypting PDF
We are pleased to announce the release of Spire.PDF for Java 10.1.9. This version adds two new methods for decrypting PDFs. The conversion from PDF to images, XLSX and OFD to PDF has also been enhanced. Besides, some known issues are fixed successfully in this version, such as the issue that the content was garbled after replacing text. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-6479 | Adds two new methods for decrypting PDFs.
PdfDocument pdf1 =new PdfDocument();
pdf1.loadFromFile("input.pdf");
pdf1.decrypt();
pdf1.saveToFile("output.pdf");
PdfDocument pdf2 =new PdfDocument();
pdf2.loadFromFile("input.pdf");
pdf2.decrypt(ownerPassword);
pdf2.saveToFile("output.pdf");
|
| Bug | SPIREPDF-6429 | Fixes the issue that the program threw "java.lang.NullPointerException" when converting OFD to PDF. |
| Bug | SPIREPDF-6482 | Fixes the issue that the program hung when converting PDF to images. |
| Bug | SPIREPDF-6485 | Fixes the issue that the content was lost after converting OFD to PDF. |
| Bug | SPIREPDF-6486 | Fixes the issue that the program threw "java.lang.NullPointerException" when converting PDF to XLSX. |
| Bug | SPIREPDF-6502 | Fixes the issue that the content was garbled after replacing text. |
How to Convert PDF to Word in Python
Table of Contents
Install with Pip
pip install Spire.PDF
Related Links
The main advantage of PDF files is their ability to always maintain the format and layout of the original document, which makes them ideal for sharing and printing. However, they are often difficult to edit or modify without specialized software. In this case, converting PDF to Word provides you with greater flexibility. With this conversion, you can easily make various changes to the document content, such as modifying the text, adding or deleting text, and adjusting formatting and styles to make it meet your needs. In this article, I will show you a simple but effective way to convert PDF to Word via Python.
- Python Library for PDF Conversion
- Convert PDF to DOC
- Convert PDF to DOCX
- Set Document Properties at Conversion
- Get a Free License for the Library
Python Library for PDF Conversion
Spire.PDF for Python is a powerful PDF manipulation API that allows you to create, modify or convert PDF files on Python platforms. With it, you are able to use Python code to convert PDF to Word effortlessly and set document properties during the conversion. Before that, please install Spire.PDF for Python and plum-dispatch v1.7.4 using the following pip commands.
pip install Spire.PDF
This article covers more details of the installation: How to Install Spire.PDF for Python in VS Code
Convert PDF to DOC in Python
If you want to edit the content of PDF, converting it to Word format first is a good choice. Take PDF to DOC conversion as an example. You only need to load the PDF and save it in DOC format to the desired location.
Steps
- Import the necessary library modules.
- Create a PdfDocument object.
- Use the PdfDocument.LoadFromFile() method to load a PDF file from the specified path.
- Call the PdfDocument.SaveToFile() method to save the PDF in Word format, specifying FileFormat as DOC.
- Close the PdfDocument object.
Sample Code
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from the specified path
pdf.LoadFromFile("C:/Users/Administrator/Desktop/Sample.pdf")
# Save the PDF in DOC format
pdf.SaveToFile("C:/Users/Administrator/Desktop/ToDoc.doc", FileFormat.DOC)
# Close the PdfDocument object
pdf.Close()
Convert PDF to DOCX in Python
This method is the same as the one above. You only need to specify the format as DOCX when saving the generated file at the end.
Steps
- Import the necessary library modules.
- Create a PdfDocument object.
- Use the PdfDocument.LoadFromFile() method to load a PDF file from the specified path.
- Call the PdfDocument.SaveToFile() method to save the PDF in Word format, specifying FileFormat as DOCX.
- Close the PdfDocument object.
Sample Code
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from the specified path
pdf.LoadFromFile("C:/Users/Administrator/Desktop/Sample.pdf")
# Save the PDF in DOCX format
pdf.SaveToFile("C:/Users/Administrator/Desktop/ToDocx.docx", FileFormat.DOCX)
# Close the PdfDocument object
pdf.Close()
Set Document Properties at Conversion in Python
In addition to regular conversions, you can also customize document properties during PDF to Word conversion. This can help you better categorize and manage your documents.
Steps
- Import the required library modules.
- Create a PdfToDocConverter object and pass in the path of the PDF file to be converted as a parameter.
- Customize the properties of the converted Word document through the properties of PdfToDocConverter class.
- Call the PdfToDocConverter.SaveToDocx() method to save the PDF in Word format.
Sample Code
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfToDocConverter object
converter = PdfToDocConverter("C:/Users/Administrator/Desktop/Sample.pdf")
# Customize the properties for the file
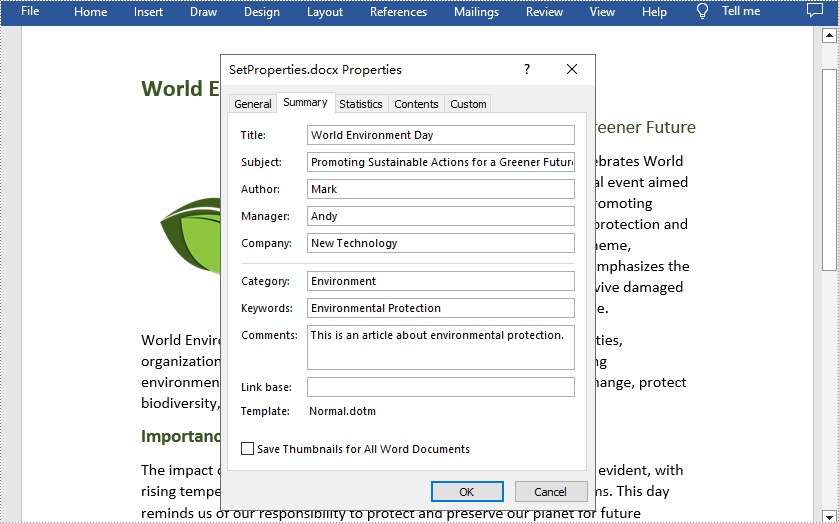
converter.DocxOptions.Title = "World Environment Day"
converter.DocxOptions.Subject = "Promoting Sustainable Actions for a Greener Future."
converter.DocxOptions.Tags = "Environmental Protection"
converter.DocxOptions.Categories = "Environment"
converter.DocxOptions.Commments = "This is an article about environmental protection."
converter.DocxOptions.Authors = "Mark"
converter.DocxOptions.LastSavedBy = "Johnny"
converter.DocxOptions.Revision = 5
converter.DocxOptions.Version = "V4.0"
converter.DocxOptions.ProgramName = "Green Development"
converter.DocxOptions.Company = "New Technology"
converter.DocxOptions.Manager = "Andy"
# Save the PDF in DOCX format
converter.SaveToDocx("C:/Users/Administrator/Desktop/SetProperties.docx")
Get a Free License for the Library to Convert PDF Files
You can get a free 30-day temporary license of Spire.PDF for Python to use Python script to convert PDF to Word without any evaluation limitation.
Conclusion
In this article, you have learned how to convert PDF to Word with Python easily. With Spire.PDF for Python library, you can also create PDF from scratch or edit it as needed. In short, this library simplifies the process and allows developers to focus on creating powerful applications that perform PDF manipulation tasks.
Spire.XLS for C++ 14.1.3 adds a custom exception class called SpireException
We are excited to announce the release of Spire.XLS for C++ 14.1.3. This version adds a custom exception class called SpireException. In addition, it also enhances the conversion from Excel to PDF. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Adds a custom exception class called SpireException. |
| Bug | SPIREXLS-5040 | Fixes the issue that the header height was increased after converting Excel to a PDF when the system language environment was set to Spanish. |
Read Excel Files in Java(Free Solution)
Table of Contents
Install with Maven
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls.free</artifactId>
<version>5.1.0</version>
</dependency>
Related Links
The ability to read data from Excel files can be useful in various industries and scenarios where structured data needs to be accessed and utilized. By reading data from Excel, you can extract information, perform calculations, and analyze the data using programming languages or specialized tools. This process enables efficient data manipulation and facilitates tasks such as generating reports, performing statistical analysis, and automating workflows.
In this article, we're going to introduce how to read Excel files in Java by using E-iceblue's Free Java Excel library. The following sub-topics are included.
- Read Value of a Cell in Java
- Read Data of a Cell Range in Java
- Read Data of an Entire Worksheet in Java
- Read Formula in a Cell in Java
- Read Formula Result in a Cell in Java
Free Java Library for Reading Excel
Free Spire.XLS for Java, provided by E-iceblue Inc., is a small but powerful Java library that empowers developers to effortlessly create, read and modify Excel XLS and XLSX files. Although it is a community edition of the commercial library Spire.XLS for Java, it offers nearly all the Excel handling capabilities, excluding file format conversion. Users can use it to easily create an Excel document from scratch, or perform operations on existing documents, such as retrieving data from a worksheet.
To install the library from the Maven repository, simply add the following configuration to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls.free</artifactId>
<version>5.1.0</version>
</dependency>
</dependencies>
Alternatively, you can download Free Spire.XLS for Java and manually import the jar file as dependency in your Java application.
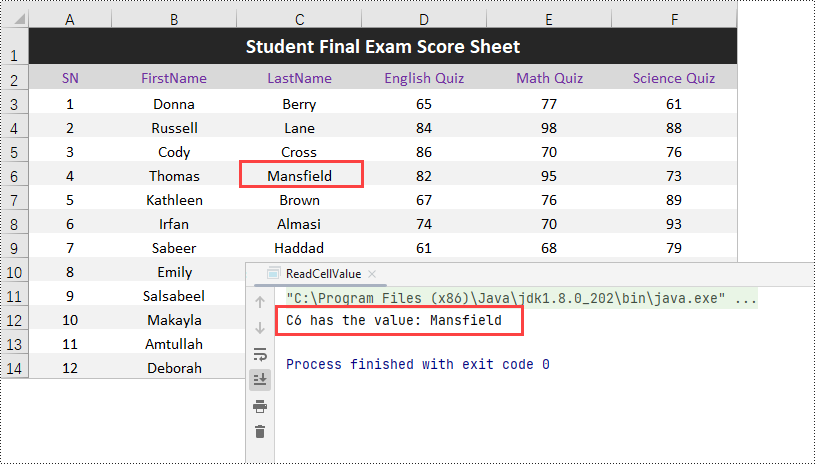
Read Value of a Cell in Java
In Free Spire.XLS, the CellRange class represents a cell or a range, and the getValue() method under the class retrieves the value of a specific cell, which can be text, a number, or a formula. Follow the following steps to read the value of a cell in Java.
- Create a Workbook object.
- Load an Excel file into the Workbook object.
- Get a specific worksheet from the Workbook object.
- Get a specific cell range (in this case, cell C6) from the worksheet.
- Retrieve the value of the cell using the getValue() method.
- Java
import com.spire.xls.CellRange;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ReadCellValue {
public static void main(String[] args) {
// Create a Workbook object
Workbook wb = new Workbook();
// Load an Excel file
wb.loadFromFile("C:\\Users\\Administrator\\Desktop\\Score Sheet.xlsx");
//Get a specific worksheet
Worksheet sheet = wb.getWorksheets().get(0);
// Get a specific cell
CellRange certainCell = sheet.getCellRange("C6");
// Get the value of the cell
String cellValue = certainCell.getValue();
// Print out result
System.out.println("C6 has the value: " + cellValue);
}
}
Read Data of a Cell Range in Java
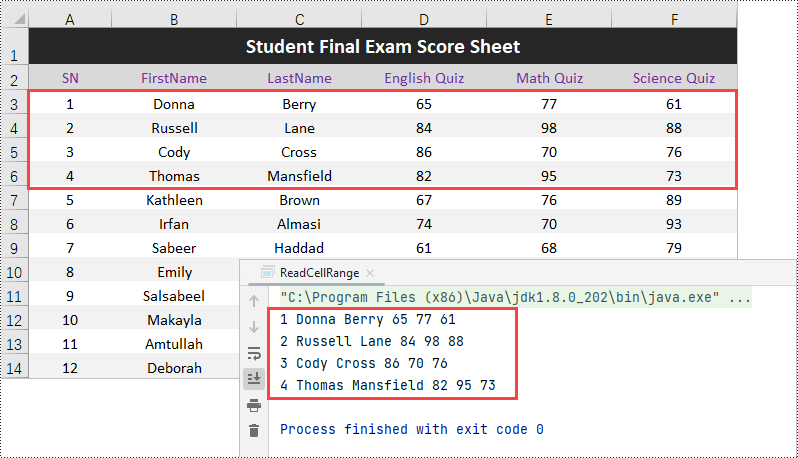
Now that we've learned how to get the value of a particular cell, it's easy to extract data from a cell region by looping through the cells one by one. The steps to read data of a specific cell range are as follows.
- Create a Workbook object.
- Load an Excel file into the Workbook object.
- Get a specific worksheet from the Workbook object.
- Get a cell range (in this case, A3:F6) from the worksheet.
- Iterate through the cells in the range using nested loops.
- Within each iteration, get a specific cell within the range.
- Retrieve the value of the cell using the getValue() method.
- Repeat the process for all cells in the range.
- Java
import com.spire.xls.CellRange;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ReadCellRange {
public static void main(String[] args) {
// Create a Workbook object
Workbook wb = new Workbook();
// Load an Excel file
wb.loadFromFile("C:\\Users\\Administrator\\Desktop\\Score Sheet.xlsx");
//Get a specific worksheet
Worksheet sheet = wb.getWorksheets().get(0);
// Get a cell range
CellRange cellRange = sheet.getCellRange("A3:F6");
// Iterate through the cells in the range
for (int i = 0; i < cellRange.getRowCount(); i++) {
for (int j = 0; j < cellRange.getColumnCount(); j++) {
// Get a specific cell
CellRange certainCell = cellRange.get(3 + i, 1 + j);
// Get the value of the cell
String cellValue = certainCell.getValue();
// Print out result
System.out.print(cellValue + " ");
}
System.out.println();
}
}
}
Read Data of an Entire Worksheet in Java
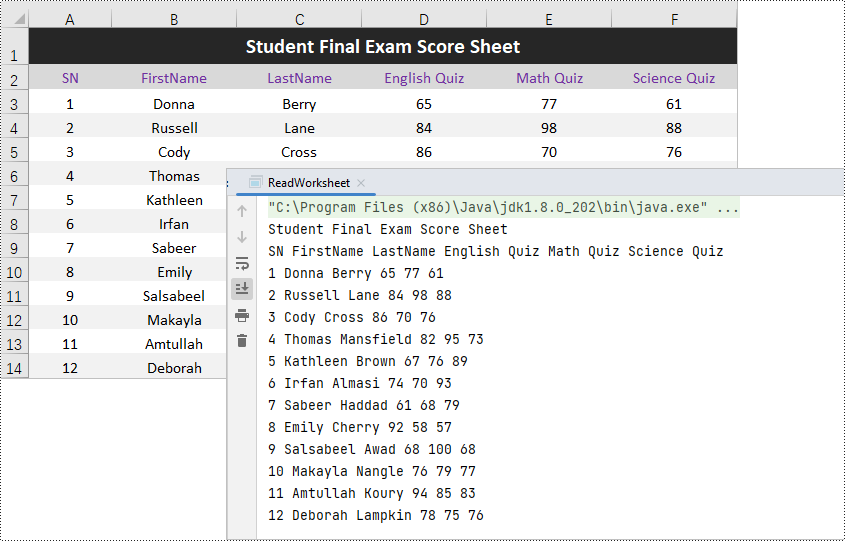
To identify the range of cells containing data, employ the Worksheet.getAllocatedRange() method, which generates a CellRange object. By iterating through the cells within the range, you can access each cell and its corresponding value. Here are the steps to read the data of an entire worksheet in Java.
- Create a Workbook object.
- Load an existing Excel file into the Workbook object.
- Get the first worksheet from the Workbook object.
- Use the getAllocatedRange() method on the worksheet to retrieve the cell range that contains data.
- Iterate through each row in the located range using a for loop.
- Within each row iteration, iterate through each column in the located range using another for loop.
- Get a specific cell within the located range using the get() method, passing the row and column indices.
- Retrieve the value of the cell using the getValue() method.
- Repeat the process for all cells in the range.
- Java
import com.spire.xls.CellRange;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ReadWorksheet {
public static void main(String[] args) {
//Create a Workbook object
Workbook wb = new Workbook();
//Load an existing Excel file
wb.loadFromFile("C:\\Users\\Administrator\\Desktop\\Score Sheet.xlsx");
//Get the first worksheet
Worksheet sheet = wb.getWorksheets().get(0);
//Get the cell range containing data
CellRange locatedRange = sheet.getAllocatedRange();
//Iterate through the rows
for (int i = 0; i < locatedRange.getRows().length; i++) {
//Iterate through the columns
for (int j = 0; j < locatedRange.getColumnCount(); j++) {
// Get a specific cell
CellRange certainCell = locatedRange.get(i + 1, j + 1);
// Get the value of the cell
String cellValue = certainCell.getValue();
// Print out result
System.out.print(cellValue + " ");
}
System.out.println();
}
}
}
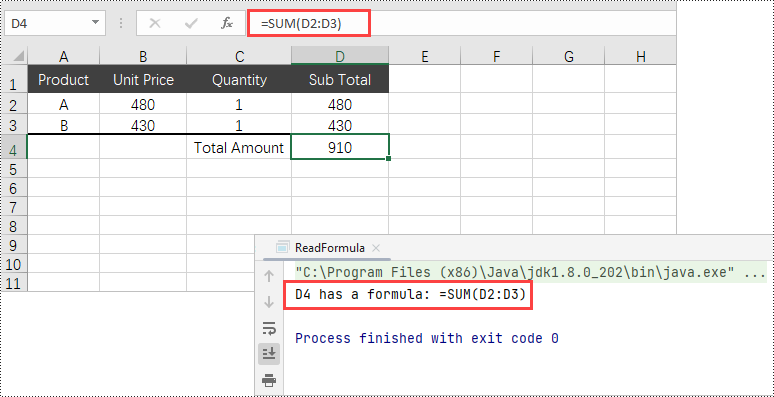
Read Formula in a Cell in Java
If a cell contains a formula, you can get the formula using either the getValue() method or the getFormula() method. Here are the steps to read formula of a cell in Java.
- Create a Workbook object.
- Load an Excel file into the Workbook object.
- Get a specific worksheet from the Workbook object.
- Get a specific cell (D4 in this case) from the worksheet.
- Check if the cell has a formula using the hasFormula() method.
- If the cell has a formula, retrieve the formula using the getFormula() method.
- Java
import com.spire.xls.CellRange;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ReadFormula {
public static void main(String[] args) {
// Create a Workbook object
Workbook wb = new Workbook();
// Load an Excel file
wb.loadFromFile("C:\\Users\\Administrator\\Desktop\\Formula.xlsx");
//Get a specific worksheet
Worksheet sheet = wb.getWorksheets().get(0);
// Get a specific cell
CellRange certainCell = sheet.getCellRange("D4");
// Determine if the cell has formula or not
if (certainCell.hasFormula()){
// Get the formula of the cell
String formula = certainCell.getFormula();
// Print out result
System.out.println("D4 has a formula: " + formula);
}
}
}
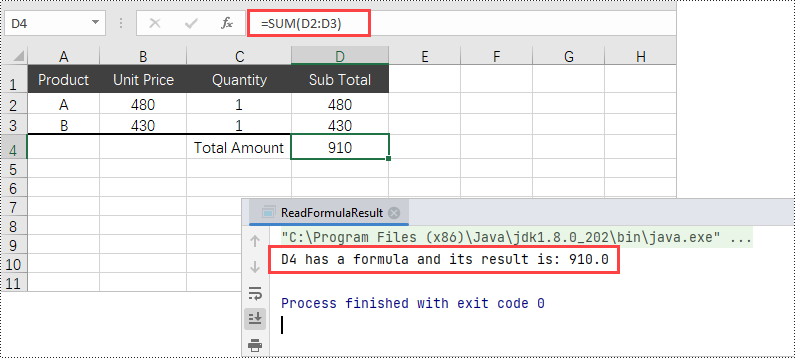
Read Formula Result in a Cell in Java
In many cases, users are primarily interested in the results produced by formulas rather than the actual formulas themselves. To obtain the result of a formula, use the getFormulaValue() method. The following are the steps to read formula result in a cell in Java.
- Create a Workbook object.
- Load an Excel file into the Workbook object.
- Get a specific worksheet from the Workbook object.
- Get a specific cell (D4 in this case) from the worksheet.
- Check if the cell has a formula using the hasFormula() method.
- If the cell has a formula, retrieve the result of the formula using the getFormulaValue() method and convert the result to a string representation using the toString() method.
- Java
import com.spire.xls.CellRange;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ReadFormulaResult {
public static void main(String[] args) {
// Create a Workbook object
Workbook wb = new Workbook();
// Load an Excel file
wb.loadFromFile("C:\\Users\\Administrator\\Desktop\\Formula.xlsx");
//Get a specific worksheet
Worksheet sheet = wb.getWorksheets().get(0);
// Get a specific cell
CellRange certainCell = sheet.getCellRange("D4");
// Determine if the cell has formula or not
if (certainCell.hasFormula()){
// Get the result of formula
String formulaResult = certainCell.getFormulaValue().toString();
// Print out result
System.out.println("D4 has a formula and its result is: " + formulaResult);
}
}
}
Conclusion
In this blog post, we have explained the process of retrieving data (text and numbers) from a specific cell, a designated cell range, or an entire Excel worksheet using Free Spire.XLS for Java. Also, we’ve discussed how to determine if a cell contains a formula, and explored methods to extract both the formula itself and its resulting value. As a professional Excel library, Free Spire.XLS for Java supports the extraction of images and OLE objects from Excel documents as well.
For more tutorials, please check out our Excel programming guide. If you have any questions, feel free to contact us via the Spire.XLS forum.