Spire.Doc 12.2.10 supports parsing GIF format content in Word documents
We are pleased to announce the release of Spire.Doc 12.2.10. This version supports parsing GIF format content in Word documents. In addition, some known issues have also been fixed, such as the issue that the incorrect bullets were retrieved. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREDOC-10052 | Supports parsing GIF format content in Word documents. |
| Bug | SPIREDOC-10154 | Fixes the issue that incorrect bullets were retrieved. |
| Bug | SPIREDOC-10160 | Fixes the issue that GIF format was converted to PNG format after mail merge. |
| Bug | SPIREDOC-10233 | Fixes the issue that private font embedding failed when converting Word to PDF. |
| Bug | SPIREDOC-10234 | Fixes the issue that characters were incorrect when converting Word to PDF. |
| Bug | SPIREDOC-10235 | Fixes the issue that reading fonts failed when converting Word to PDF on MAC systems. |
| Bug | SPIREDOC-10261 | Fixes the issue that the program threw "System.NullReferenceException" exception when loading a Docx document. |
| Bug | SPIREDOC-10295 | Fixes the issue that the table would have extra borders after loading a Docx document and saving it as a new document. |
| Bug | SPIREDOC-10305 | Fixes the issue that the program threw "System.ArgumentException" exception when comparing two Word documents. |
| Bug | SPIREDOC-10308 | Fixes the issue that the program hung when getting page count. |
| Bug | SPIREDOC-10318 | Fixes the issue that the program threw "System.InvalidCastException" when comparing two Word documents. |
C# Read Content from a Word Document
Reading content from a Word document is crucial for many work and study tasks. Reading a page from a Word document helps in quickly browsing and summarizing key information, reading a section from a Word document aids in gaining a deeper understanding of a specific topic or section, while reading the entire document from a Word document allows for a comprehensive grasp of the overall information, facilitating comprehensive analysis and understanding. This article will introduce how to use Spire.Doc for .NET to read a page, a section, and the entire content of a Word document in a C# project.
- Read a Page from a Word Document in C#
- Read a Section from a Word Document in C#
- Reading the Entire Content from a Word Document in C#
Install Spire.Doc for .NET
To begin with, you need to add the DLL files included in the Spire.Doc for .NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Doc
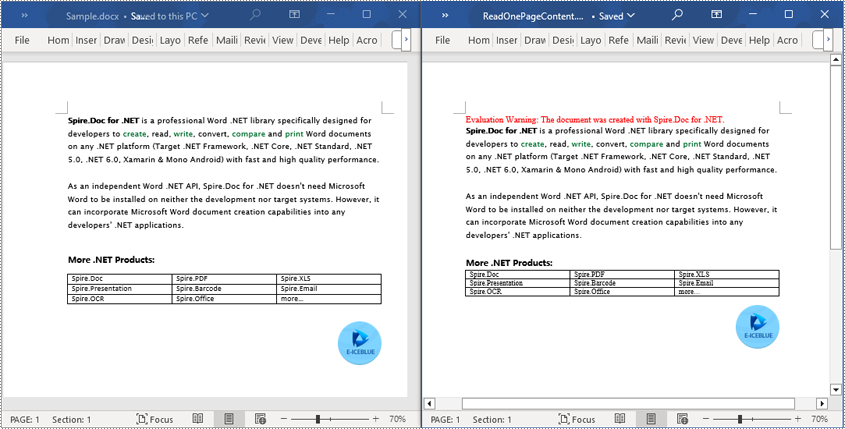
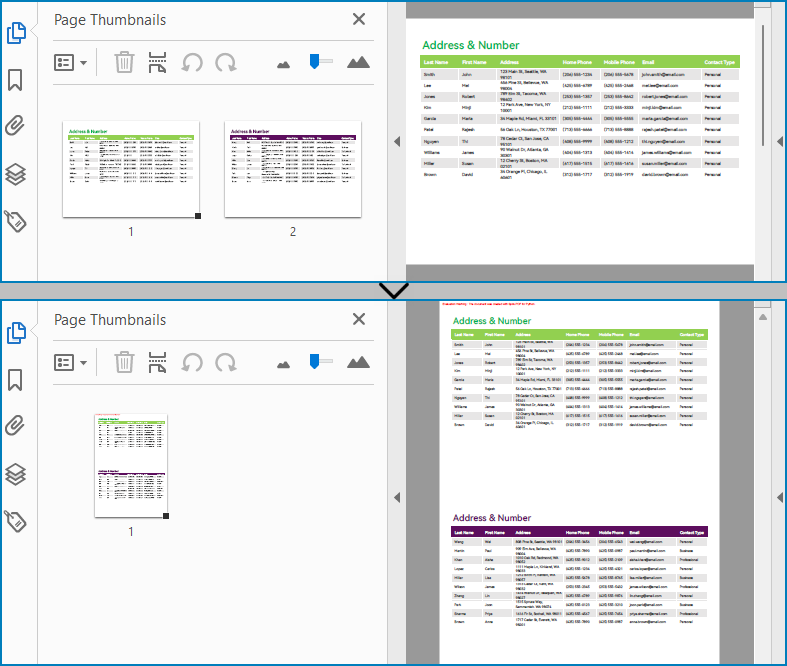
Read a Page from a Word Document in C#
By using the FixedLayoutDocument class and FixedLayoutPage class, you can easily retrieve the content of a specified page. To facilitate viewing the extracted content, this sample code will store the read content in a new Word document. The detailed steps are as follows:
- Create a Document object.
- Load a Word document using the Document.LoadFromFile() method.
- Create a FixedLayoutDocument object.
- Retrieve the FixedLayoutPage object of a page in the document.
- Access the Section where the page is located through the FixedLayoutPage.Section property.
- Get the index position of the first paragraph on the page within the section.
- Get the index position of the last paragraph on the page within the section.
- Create another Document object.
- Add a new section using Document.AddSection().
- Clone the properties of the original section to the new section using the Section.CloneSectionPropertiesTo(newSection) method.
- Copy the content of the page from the original document to the new document.
- Save the resulting document using the Document.SaveToFile() method.
- C#
using Spire.Doc;
using Spire.Doc.Pages;
using Spire.Doc.Documents;
namespace SpireDocDemo
{
internal class Program
{
static void Main(string[] args)
{
// Create a new document object
Document document = new Document();
// Load document content from the specified file
document.LoadFromFile("Sample.docx");
// Create a fixed layout document object
FixedLayoutDocument layoutDoc = new FixedLayoutDocument(document);
// Get the first page
FixedLayoutPage page = layoutDoc.Pages[0];
// Get the section where the page is located
Section section = page.Section;
// Get the first paragraph of the page
Paragraph paragraphStart = page.Columns[0].Lines[0].Paragraph;
int startIndex = 0;
if (paragraphStart != null)
{
// Get the index of the paragraph in the section
startIndex = section.Body.ChildObjects.IndexOf(paragraphStart);
}
// Get the last paragraph of the page
Paragraph paragraphEnd = page.Columns[0].Lines[page.Columns[0].Lines.Count - 1].Paragraph;
int endIndex = 0;
if (paragraphEnd != null)
{
// Get the index of the paragraph in the section
endIndex = section.Body.ChildObjects.IndexOf(paragraphEnd);
}
// Create a new document object
Document newdoc = new Document();
// Add a new section
Section newSection = newdoc.AddSection();
// Clone the properties of the original section to the new section
section.CloneSectionPropertiesTo(newSection);
// Copy the content of the page from the original document to the new document
for (int i = startIndex; i <= endIndex ; i++)
{
newSection.Body.ChildObjects.Add(section.Body.ChildObjects[i].Clone());
}
// Save the new document to a specified file
newdoc.SaveToFile("ReadOnePageContent.docx", Spire.Doc.FileFormat.Docx);
// Close and release the new document
newdoc.Close();
newdoc.Dispose();
// Close and release the original document
document.Close();
document.Dispose();
}
}
}
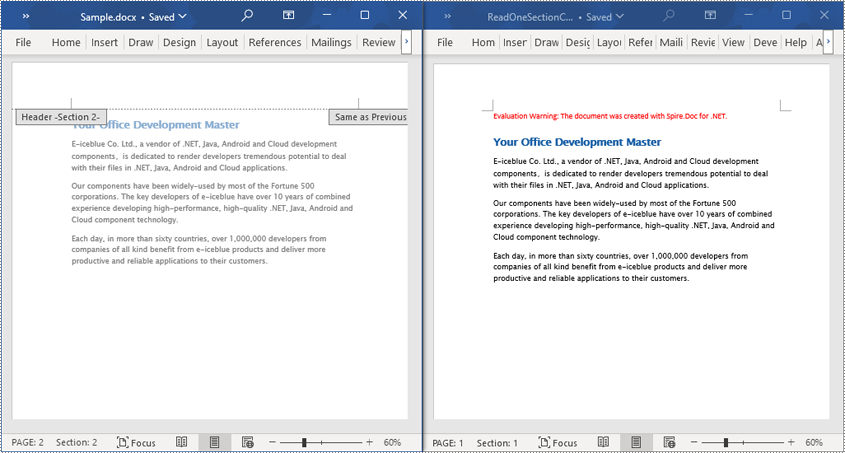
Read a Section from a Word Document in C#
By using Document.Sections[index], you can retrieve a specific Section object that contains the header, footer, and body content. This example provides a simple way to copy all content of a section to another document. The detailed steps are as follows:
- Create a Document object.
- Use the Document.LoadFromFile() method to load a Word document.
- Use Document.Sections[1] to retrieve the second section of the document.
- Create another new Document object.
- Use the Document.CloneDefaultStyleTo(newdoc) method to clone the default style of the original document to the new document.
- Use newdoc.Sections.Add(section.Clone()) to clone the content of the second section of the original document into the new document.
- Use the Document.SaveToFile() method to save the resulting document.
- C#
using Spire.Doc;
namespace SpireDocDemo
{
internal class Program
{
static void Main(string[] args)
{
// Create a new document object
Document document = new Document();
// Load a Word document from a file
document.LoadFromFile("Sample.docx");
// Get the second section of the document
Section section = document.Sections[1];
// Create a new document object
Document newdoc = new Document();
// Clone the default style to the new document
document.CloneDefaultStyleTo(newdoc);
// Clone the second section to the new document
newdoc.Sections.Add(section.Clone());
// Save the new document to a file
newdoc.SaveToFile("ReadOneSectionContent.docx", Spire.Doc.FileFormat.Docx);
// Close and release the new document object
newdoc.Close();
newdoc.Dispose();
// Close and release the original document object
document.Close();
document.Dispose();
}
}
}
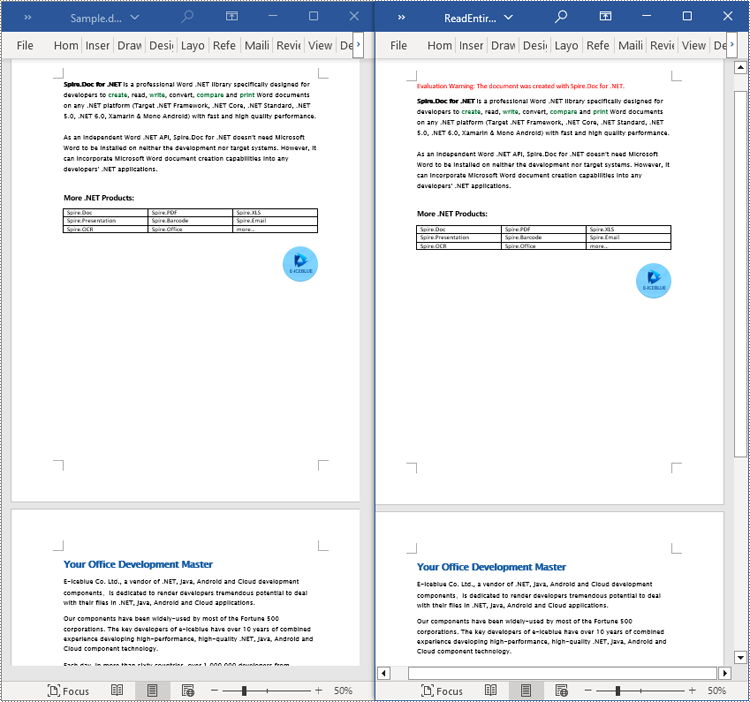
Read the Entire Content from a Word Document in C#
This example demonstrates reading the entire content of a document by iterating through each section of the original document and cloning each section into a new document. The detailed steps are as follows:
- Create a Document object.
- Use the Document.LoadFromFile() method to load a Word document.
- Create another new Document object.
- Use the Document.CloneDefaultStyleTo(newdoc) method to clone the default style of the original document to the new document.
- Iterate through each section of the original document using a foreach loop and clone each section into the new document.
- Use the Document.SaveToFile() method to save the resulting document.
- C#
using Spire.Doc;
namespace SpireDocDemo
{
internal class Program
{
static void Main(string[] args)
{
// Create a new document object
Document document = new Document();
// Load a Word document from a file
document.LoadFromFile("Sample.docx");
// Create a new document object
Document newdoc = new Document();
// Clone the default style to the new document
document.CloneDefaultStyleTo(newdoc);
// Iterate through each section in the original document and clone it to the new document
foreach (Section sourceSection in document.Sections)
{
newdoc.Sections.Add(sourceSection.Clone());
}
// Save the new document to a file
newdoc.SaveToFile("ReadEntireDocumentContent.docx", Spire.Doc.FileFormat.Docx);
// Close and release the new document object
newdoc.Close();
newdoc.Dispose();
// Close and release the original document object
document.Close();
document.Dispose();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
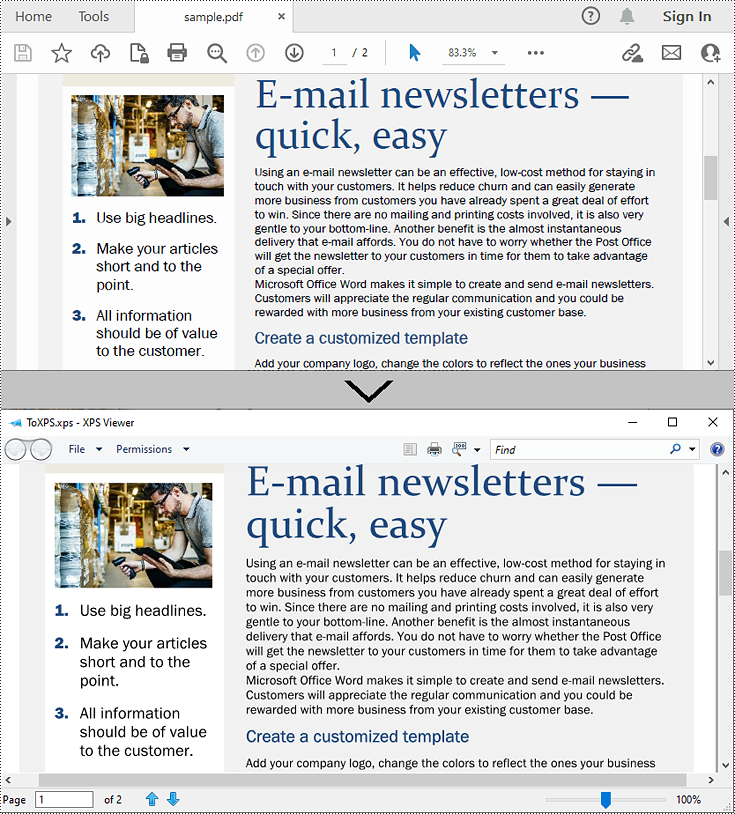
Python: Convert PDF to XPS
XPS, or XML Paper Specification, is a file format developed by Microsoft as an alternative to PDF (Portable Document Format). Similar to PDF, XPS is specifically designed to preserve the visual appearance and layout of documents across different platforms and devices, ensuring consistent viewing regardless of the software or hardware being used.
Converting PDF files to XPS format offers several notable benefits. Firstly, XPS files are fully supported within the Windows ecosystem. If you work in a Microsoft-centric environment that heavily relies on Windows operating systems and Microsoft applications, converting PDF files to XPS guarantees smooth compatibility and an optimized viewing experience tailored to the Windows platform.
Secondly, XPS files are optimized for printing, ensuring precise reproduction of the document on paper. This makes XPS the preferred format when high-quality printed copies of the document are required.
Lastly, XPS files are based on XML, a widely adopted standard for structured data representation. This XML foundation enables easy extraction and manipulation of content within the files, as well as seamless integration of file content with other XML-based workflows or systems.
In this article, we will demonstrate how to convert PDF files to XPS format in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to XPS in Python
Converting a PDF file to the XPS file format is very easy with Spire.PDF for Python. Simply load the PDF file using the PdfDocument.LoadFromFile() method, and then save the PDF file to the XPS file format using the PdfDocument.SaveToFile(filename:str, fileFormat:FileFormat) method. The detailed steps are as follows:
- Create an object of the PdfDocument class.
- Load the sample PDF file using the PdfDocument.LoadFromFile() method.
- Save the PDF file to the XPS file format using the PdfDocument.SaveToFile (filename:str, fileFormat:FileFormat) method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output file paths inputFile = "sample.pdf" outputFile = "ToXPS.xps" # Create an object of the PdfDocument class pdf = PdfDocument() # Load the sample PDF file pdf.LoadFromFile(inputFile) # Save the PDF file to the XPS file format pdf.SaveToFile(outputFile, FileFormat.XPS) # Close the PdfDocument object pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Chat With Excel using AI
As data complexity continues to rise, the need for efficient and intelligent interaction with Excel becomes increasingly pressing. To meet this challenge, we have integrated AI technology that allows users to engage in profound interactions with Excel through natural language conversations. This transformative technology is set to dramatically enhance work efficiency, lower the learning curve, and redefine the way people interact with data. In this article, we will introduce how to chat with Excel using Spire.XLS AI.
Install Spire.XLS for .NET
The Excel AI integrated into Spire.XLS for .NET package, hence to begin with, you need to add the DLL files included in the Spire.XLS for .NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.XLS
Request a License Key of AI Product
A license key is required to run Spire.XLS AI, please contact our sales department (sales@e-iceblue.com) to request one.
Use AI to Chat With Excel
Spire.XLS AI provides the ExcelAI class, enabling users to engage in dynamic conversations with Excel document data. Spire.XLS AI extends its reach to accommodate diverse file formats including txt, csv, pdf, and md, thus facilitating seamless cross-format intelligence extraction and interpretation. The following are the key methods necessary to achieve this functionality:
- UploadWorkbook(Workbook wb): This method is used to upload a Workbook object processed by Spire.XLS to the AI server, facilitating the integration of Excel content with the AI system's data.
- UploadFile(string fileName, Stream stream): This method is used to upload txt files or files in other formats to the AI server.
- DocumentSearch(string question, string file_server_path, bool enableHistory = false): This method allows posing specific questions to the AI system against a designated Excel document, generating intelligent responses based on its contents. The optional parameter enableHistory is set to false by default, if set to true, it enables the search history feature, allowing subsequent operations to track or leverage previous query results.
- Ask(string question, bool enableHistory = false): This method allows interacting with the AI system by asking a specific question, generating intelligent responses.
- ResetChatHistory(string sessionid): This method resets or clears the chat history associated with the sessionid. By invoking this method, all prior conversations and context associated with the specified session will be erased, ensuring a fresh start for the next interaction.
The following code demonstrates how to chat with Excel document using Spire.XLS AI:
- C#
using Spire.Xls;
using Spire.Xls.AI;
using System.IO;
using System.Text;
// Define the file path of the Excel document
string inputfile = "Input.xlsx";
// Create a new instance of the Workbook
Workbook wb = new Workbook();
// Load the Excel file
wb.LoadFromFile(inputfile);
// Create a new instance of the ExcelAI
ExcelAI excelAI = new ExcelAI();
// Upload the workbook and obtain the file path where it's stored in the AI system
string fpath = excelAI.UploadWorkbook(wb);
// Set the question1 to be asked to the AI system
string question1 = "The document discusses what topic? And please generate 3 topics for the upcoming conversation";
// Execute a smart search task based on the provided question for the Excel file
string answer1 =excelAI.DocumentSearch(question1, fpath, true);
// Set the question2 to be asked to the AI system
string question2 = "Please expand the first generated topic";
// Execute an ask task to ask question for AI system
string answer2 = excelAI.Ask(question2, true);
// Set the question3 to be asked to the AI system
string question3 = "How to use IF function in Excel to achieve multi condition judgment?";
// Reset the chat history for the current session
excelAI.ResetChatHistory(excelAI.SessionID);
// Execute an ask task to ask question for AI system
string answer3 = excelAI.Ask(question3, true);
// Create a StringBuilder object to append the answers
StringBuilder builder = new StringBuilder();
builder.AppendLine("Answer1: "+answer1);
builder.AppendLine("-------------------------------------------------------------------");
builder.AppendLine("Answer2: " + answer2);
builder.AppendLine("-------------------------------------------------------------------");
builder.AppendLine("Answer3: " + answer3);
// Write the answer to the txt file
File.WriteAllText("ChatWithExcel.txt", builder.ToString());
Input Excel Content:
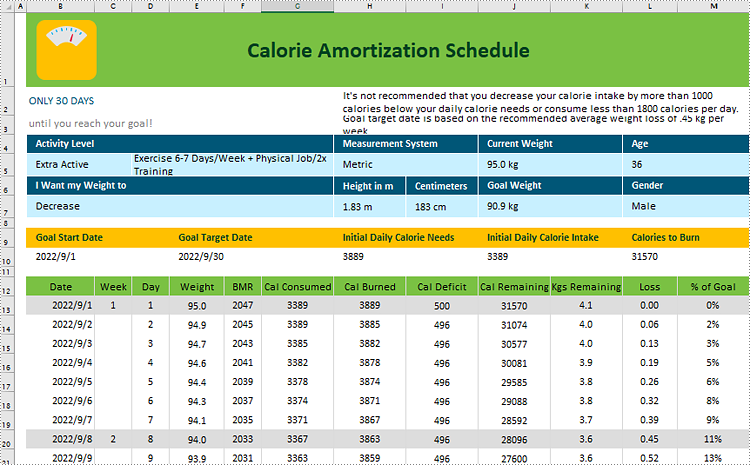
Generated Txt Content:
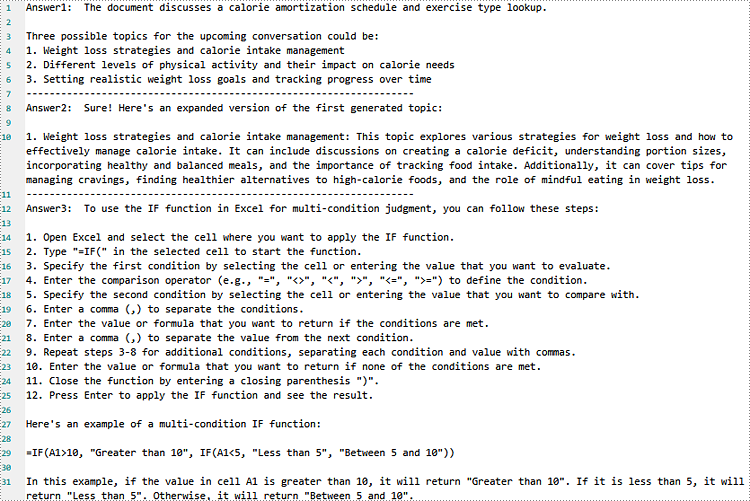
C#: Add, Insert, or Delete Pgaes in Word Documents
Adding, inserting, and deleting pages in a Word document is crucial for managing and presenting content. By adding or inserting a new page in Word, you can expand the document to accommodate more content, making it more structured and readable. Deleting pages can help streamline the document by removing unnecessary information or erroneous content. This article will explain how to use Spire.Doc for .NET to add, insert, or delete a page in a Word document within a C# project.
- Add a Page in a Word Document using C#
- Insert a Page in a Word Document using C#
- Delete a Page from a Word Document using C#
Install Spire.Doc for .NET
To begin with, you need to add the DLL files included in the Spire.Doc for .NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Doc
Add a Page in a Word Document using C#
The steps to add a new page at the end of a Word document involve first obtaining the last section, then inserting a page break at the end of the last paragraph of that section to ensure that subsequently added content appears on a new page. Here are the detailed steps:
- Create a Document object.
- Load a Word document using the Document.LoadFromFile() method.
- Get the body of the last section of the document using Document.LastSection.Body.
- Add a page break by calling Paragraph.AppendBreak(BreakType.PageBreak) method.
- Create a new ParagraphStyle object.
- Add the new paragraph style to the document's style collection using Document.Styles.Add() method.
- Create a new Paragraph object and set the text content.
- Apply the previously created paragraph style to the new paragraph using Paragraph.ApplyStyle(ParagraphStyle.Name) method.
- Add the new paragraph to the document using Body.ChildObjects.Add(Paragraph) method.
- Save the resulting document using the Document.SaveToFile() method.
- C#
// Create a new document object
Document document = new Document();
// Load a document
document.LoadFromFile("Sample.docx");
// Get the body of the last section of the document
Body body = document.LastSection.Body;
// Insert a page break after the last paragraph in the body
body.LastParagraph.AppendBreak(BreakType.PageBreak);
// Create a new paragraph style
ParagraphStyle paragraphStyle = new ParagraphStyle(document);
paragraphStyle.Name = "CustomParagraphStyle1";
paragraphStyle.ParagraphFormat.LineSpacing = 12;
paragraphStyle.ParagraphFormat.AfterSpacing = 8;
paragraphStyle.CharacterFormat.FontName = "Microsoft YaHei";
paragraphStyle.CharacterFormat.FontSize = 12;
// Add the paragraph style to the document's style collection
document.Styles.Add(paragraphStyle);
// Create a new paragraph and set the text content
Paragraph paragraph = new Paragraph(document);
paragraph.AppendText("Thank you for using our Spire.Doc for .NET product. The trial version will add a red watermark to the generated document and only supports converting the first 10 pages to other formats. Upon purchasing and applying a license, these watermarks will be removed, and the functionality restrictions will be lifted.");
// Apply the paragraph style
paragraph.ApplyStyle(paragraphStyle.Name);
// Add the paragraph to the body's content collection
body.ChildObjects.Add(paragraph);
// Create another new paragraph and set the text content
paragraph = new Paragraph(document);
paragraph.AppendText("To experience our product more fully, we provide a one-month temporary license free of charge to each of our customers. Please send an email to sales@e-iceblue.com, and we will send the license to you within one working day.");
// Apply the paragraph style
paragraph.ApplyStyle(paragraphStyle.Name);
// Add the paragraph to the body's content collection
body.ChildObjects.Add(paragraph);
// Save the document to the specified path
document.SaveToFile("Add a Page.docx", FileFormat.Docx);
// Close the document
document.Close();
// Release the resources of the document object
document.Dispose();
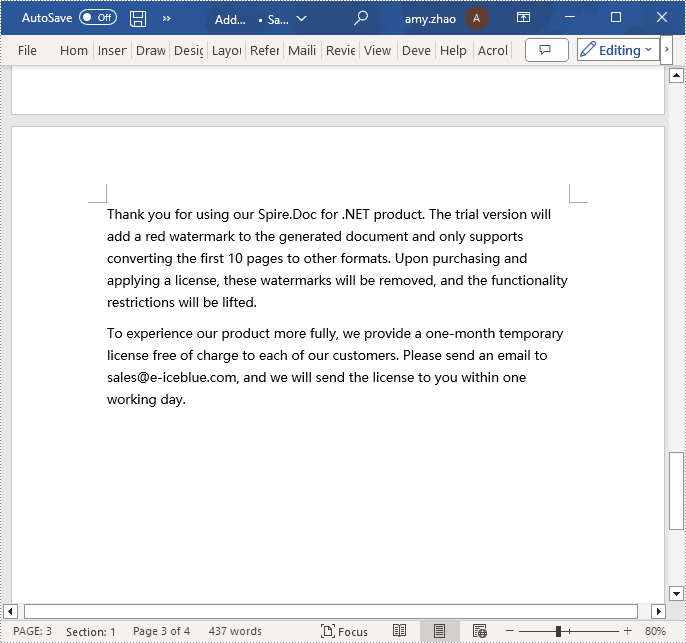
Insert a Page in a Word Document using C#
Before inserting a new page, it is necessary to determine the ending position index of the specified page content within the section. Subsequently, add the content of the new page to the document one by one after this position. Finally, to separate the content from the following pages, adding a page break is essential. The detailed steps are as follows:
- Create a Document object.
- Load a Word document using the Document.LoadFromFile() method.
- Create a FixedLayoutDocument object.
- Obtain the FixedLayoutPage object of a page in the document.
- Determine the index position of the last paragraph on the page within the section.
- Create a new ParagraphStyle object.
- Add the new paragraph style to the document's style collection using Document.Styles.Add() method.
- Create a new Paragraph object and set the text content.
- Apply the previously created paragraph style to the new paragraph using the Paragraph.ApplyStyle(ParagraphStyle.Name) method.
- Insert the new paragraph at the specified using the Body.ChildObjects.Insert(index, Paragraph) method.
- Create another new paragraph object, set its text content, add a page break by calling the Paragraph.AppendBreak(BreakType.PageBreak) method, apply the previously created paragraph style, and then insert this paragraph into the document.
- Save the resulting document using the Document.SaveToFile() method.
- C#
using Spire.Doc;
using Spire.Doc.Pages;
using Spire.Doc.Documents;
namespace SpireDocDemo
{
internal class Program
{
static void Main(string[] args)
{
// Create a new document object
Document document = new Document();
// Load the sample document from a file
document.LoadFromFile("Sample.docx");
// Create a fixed layout document object
FixedLayoutDocument layoutDoc = new FixedLayoutDocument(document);
// Get the first page
FixedLayoutPage page = layoutDoc.Pages[0];
// Get the body of the document
Body body = page.Section.Body;
// Get the last paragraph of the current page
Paragraph paragraphEnd = page.Columns[0].Lines[page.Columns[0].Lines.Count - 1].Paragraph;
// Initialize the end index
int endIndex = 0;
if (paragraphEnd != null)
{
// Get the index of the last paragraph
endIndex = body.ChildObjects.IndexOf(paragraphEnd);
}
// Create a new paragraph style
ParagraphStyle paragraphStyle = new ParagraphStyle(document);
paragraphStyle.Name = "CustomParagraphStyle1";
paragraphStyle.ParagraphFormat.LineSpacing = 12;
paragraphStyle.ParagraphFormat.AfterSpacing = 8;
paragraphStyle.CharacterFormat.FontName = "Microsoft YaHei";
paragraphStyle.CharacterFormat.FontSize = 12;
// Add the paragraph style to the document's style collection
document.Styles.Add(paragraphStyle);
// Create a new paragraph and set the text content
Paragraph paragraph = new Paragraph(document);
paragraph.AppendText("Thank you for using our Spire.Doc for .NET product. The trial version will add a red watermark to the generated document and only supports converting the first 10 pages to other formats. Upon purchasing and applying a license, these watermarks will be removed, and the functionality restrictions will be lifted.");
// Apply the paragraph style
paragraph.ApplyStyle(paragraphStyle.Name);
// Insert the paragraph at the specified position
body.ChildObjects.Insert(endIndex + 1, paragraph);
// Create another new paragraph
paragraph = new Paragraph(document);
paragraph.AppendText("To experience our product more fully, we provide a one-month temporary license free of charge to each of our customers. Please send an email to sales@e-iceblue.com, and we will send the license to you within one working day.");
// Apply the paragraph style
paragraph.ApplyStyle(paragraphStyle.Name);
// Add a page break
paragraph.AppendBreak(BreakType.PageBreak);
// Insert the paragraph at the specified position
body.ChildObjects.Insert(endIndex + 2, paragraph);
// Save the document to the specified path
document.SaveToFile("Insert a Page.docx", Spire.Doc.FileFormat.Docx);
// Close and release the original document
document.Close();
document.Dispose();
}
}
}

Delete a Page from a Word Document using C#
To delete the content of a page, first determine the index positions of the starting and ending elements of that page in the document. Then, you can utilize a loop to systematically remove these elements one by one. The detailed steps are as follows:
- Create a Document object.
- Load a Word document using the Document.LoadFromFile() method.
- Create a FixedLayoutDocument object.
- Obtain the FixedLayoutPage object of the first page in the document.
- Use the FixedLayoutPage.Section property to get the section where the page is located.
- Determine the index position of the first paragraph on the page within the section.
- Determine the index position of the last paragraph on the page within the section.
- Use a for loop to remove the content of the page one by one.
- Save the resulting document using the Document.SaveToFile() method.
- C#
using Spire.Doc;
using Spire.Doc.Pages;
using Spire.Doc.Documents;
namespace SpireDocDemo
{
internal class Program
{
static void Main(string[] args)
{
// Create a new document object
Document document = new Document();
// Load the sample document from a file
document.LoadFromFile("Sample.docx");
// Create a fixed layout document object
FixedLayoutDocument layoutDoc = new FixedLayoutDocument(document);
// Get the second page
FixedLayoutPage page = layoutDoc.Pages[1];
// Get the section of the page
Section section = page.Section;
// Get the first paragraph on the first page
Paragraph paragraphStart = page.Columns[0].Lines[0].Paragraph;
int startIndex = 0;
if (paragraphStart != null)
{
// Get the index of the starting paragraph
startIndex = section.Body.ChildObjects.IndexOf(paragraphStart);
}
// Get the last paragraph on the last page
Paragraph paragraphEnd = page.Columns[0].Lines[page.Columns[0].Lines.Count - 1].Paragraph;
int endIndex = 0;
if (paragraphEnd != null)
{
// Get the index of the ending paragraph
endIndex = section.Body.ChildObjects.IndexOf(paragraphEnd);
}
// Delete all content within the specified range
for (int i = 0; i <= (endIndex - startIndex); i++)
{
section.Body.ChildObjects.RemoveAt(startIndex);
}
// Save the document to the specified path
document.SaveToFile("Delete a Page.docx", Spire.Doc.FileFormat.Docx);
// Close and release the original document
document.Close();
document.Dispose();
}
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.PDF for Java 10.2.6 fixes the issue that the result of signature verification was incorrect
We are delighted to announce the release of Spire.PDF for Java 10.2.6. This version fixes many known issues, such as the issue that the result of signature verification was incorrect. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREPDF-6523 | Fixes the issue that the program threw java.lang.NullPointerException exception when creating a template for the first page. |
| Bug | SPIREPDF-6527 | Fixes the issue that compression of PDF documents did not work. |
| Bug | SPIREPDF-6534 | Fixes the issue that the program threw java.lang.NullPointerException when comparing documents. |
| Bug | SPIREPDF-6535 | Fixes the issue that the content was garbled after adding a digital signature. |
| Bug | SPIREPDF-6542 | Fixes the issue that the MIME type of the added attachment was incorrect. |
| Bug | SPIREPDF-6543 | Fixes the issue that the result of verifying the signature was incorrect. |
Spire.Doc for C++ 12.2.1 supports obtaining page content through fixed layout
We are excited to announce the release of Spire.Doc for C++ 12.2.1. This version supports obtaining page content through fixed layout. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Supports obtaining page content through fixed layout.
// Specify the file path
wstring input_path = DATAPATH;
wstring inputFile = input_path + L"in.docx";
wstring output_path = OUTPUTPATH;
wstring outputFile = output_path + L"out.txt";
// Create a new instance of Document
intrusive_ptr<Document> document = new Document();
//Load the document from the specified file
document->LoadFromFile(inputFile.c_str(), FileFormat::Docx);
intrusive_ptr<FixedLayoutDocument> layoutDoc = new FixedLayoutDocument(document);
wstring result;
// Create a FixedLayoutDocument object using the loaded document
intrusive_ptr<FixedLayoutLine> line = layoutDoc->GetPages()->GetItem(0)->GetColumns()->GetItem(0)->GetLines()->GetItem(0);
result.append(L"Line: ");
result.append(line->GetText());
result.append(L"\n");
// Retrieve the original paragraph associated with the line
intrusive_ptr<Paragraph> para = line->GetParagraph();
result.append(L"Paragraph text: ");
result.append(para->GetText());
result.append(L"\n");
// Retrieve all the text that appears on the first page in plain text format (including headers and footers).
wstring pageText = layoutDoc->GetPages()->GetItem(0)->GetText();
result.append(pageText);
result.append(L"\n");
// Loop through each page in the document and print how many lines appear on each page.
for (int i = 0; i < layoutDoc->GetPages()->GetCount(); i++)
{
intrusive_ptr<FixedLayoutPage> page = layoutDoc->GetPages()->GetItem(i);
intrusive_ptr<LayoutCollection> lines = page->GetChildEntities(LayoutElementType::Line, true);
result.append(L"Page ");
result.append(std::to_wstring(page->GetPageIndex()));
result.append(L" has ");
result.append(std::to_wstring(lines->GetCount()));
result.append(L" lines.");
result.append(L"\n");
}
// Perform a reverse lookup of layout entities for the first paragraph
result.append(L"\n");
result.append(L"The lines of the first paragraph:");
result.append(L"\n");
intrusive_ptr<Paragraph> para2 = (Object::Dynamic_cast<Section>(document->GetFirstChild()))->GetBody()->GetParagraphs()->GetItemInParagraphCollection(0);
intrusive_ptr<LayoutCollection> paragraphLines = layoutDoc->GetLayoutEntitiesOfNode(para2);
for (int i = 0; i < paragraphLines->GetCount(); i++)
{
intrusive_ptr<FixedLayoutLine> paragraphLine = Object::Dynamic_cast<FixedLayoutLine>(paragraphLines->GetItem(i));
result.append(paragraphLine->GetText());
result.append(L"\n");
result.append(paragraphLine->GetRectangle()->ToString());
result.append(L"\n");
result.append(L"\n");
}
// Write the extracted text to a file
std::wofstream write(outputFile);
auto LocUtf8 = locale(locale(""), new std::codecvt_utf8<wchar_t>);
write.imbue(LocUtf8);
write << result;
write.close();
// Dispose of the document resources
document->Dispose();
|
Spire.Doc for Python 12.2.1 supports obtaining page content through fixed layout
We are happy to announce the release of Spire.Doc for Python 12.2.1. This version supports obtaining page content through fixed layout. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Supports obtaining page content through fixed layout.
def WriteAllText(fpath:str,content:str):
with open(fpath,'w',encoding="utf-8") as fp:
fp.write(content)
# Specify the file path
inputFile = "./Data/Sample.docx"
outputFile = "output.txt"
# Create a new instance of Document
doc = Document()
# Load the document from the specified file
doc.LoadFromFile(inputFile, FileFormat.Docx)
# Create a FixedLayoutDocument object using the loaded document
layoutDoc = FixedLayoutDocument(doc)
result = ''
# Get the first line on the first page
line = layoutDoc.Pages[0].Columns[0].Lines[0]
result += "Line: "
result += line.Text
result += "\n"
# Retrieve the original paragraph associated with the line
para = line.Paragraph
result += "Paragraph text: "
result += para.Text
result += "\n"
# Retrieve all the text that appears on the first page in plain text format (including headers and footers).
pageText = layoutDoc.Pages[0].Text
result += pageText
result += "\n"
# Loop through each page in the document and print how many lines appear on each page.
pages = layoutDoc.Pages
for i in range(pages.Count):
page = pages[i]
lines = page.GetChildEntities(LayoutElementType.Line, True)
result += "Page "
result += str(page.PageIndex)
result += " has "
result += str(lines.Count)
result += " lines."
result += "\n"
# Perform a reverse lookup of layout entities for the first paragraph
result += "\n"
result += "The lines of the first paragraph:"
result += "\n"
tempChild = doc.FirstChild
section = Section(tempChild)
para = section.Body.Paragraphs[0]
paragraphLines = layoutDoc.GetLayoutEntitiesOfNode(para)
for i in range(paragraphLines.Count):
tempLine = paragraphLines[i]
paragraphLine = FixedLayoutLine(tempLine)
result += (paragraphLine.Text).strip()
result += "\n"
result += paragraphLine.Rectangle.ToString()
result += "\n"
result += "\n"
# Write the extracted text to a file
WriteAllText(outputFile, result)
# Dispose of the document resources
doc.Dispose()
|
Python: Split or Merge PDF Pages
Modifying PDF documents to suit various usage scenarios is a common task for PDF document creators and managers. Among these operations, splitting and merging PDF pages can assist in reorganizing PDF content for printing, typesetting, etc. By using Python programs, developers can easily split one page from a PDF document to several pages or merge multiple PDF pages into a single page. This article will demonstrate how to use Spire.PDF for Python for splitting and merging PDF pages in Python programs.
- Split One PDF Page into Several PDF Pages with Python
- Merge Multiple PDF Pages into a Single Page with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Split One PDF Page into Several PDF Pages with Python
With Spire.PDF for Python, developers draw a PDF page on a new PDF page using the PdfPageBase.CreateTemplate().Draw(newPage PdfPageBase, PointF) method. When drawing, if the current new page cannot fully accommodate the content of the original page, a new page is automatically created, and the remaining content is drawn on it. Therefore, we can create a new PDF document and control the drawing result by specifying the page size to achieve specified division of PDF pages horizontally or vertically.
Here are the steps to vertically split a PDF page into two separate PDF pages:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first page of the document using PdfDocument.Pages.get_Item() method.
- Create a new PDF document by creating an object of PdfDocument class.
- Set the margins of the new document to 0 through PdfDocument.PageSettings.Margins.All property.
- Get the width and height of the retrieved page through PdfPageBase.Size.Width property and PdfPageBase.Size.Height property.
- Set the width of the new PDF document to the same as the retrieved page through PdfDocument.PageSettings.Width property and its height to half of the retrieved page's height through PdfDocument.PageSettings.Height property.
- Add a new page in the new document using PdfDocument.Pages.Add() method.
- Draw the content of the retrieved page onto the new page using PdfPageBase.CreateTemplate().Draw() method.
- Save the new document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get the first page of the document
page = pdf.Pages.get_Item(0)
# Create a new PDF document
newPdf = PdfDocument()
# Set the margins of the new PDF document to 0
newPdf.PageSettings.Margins.All = 0.0
# Get the width and height of the retrieved page
width = page.Size.Width
height = page.Size.Height
# Set the width of the new PDF document to the same as the retrieved page and its height to half of the retrieved page's height
newPdf.PageSettings.Width = width
newPdf.PageSettings.Height = height / 2
# Add a new page to the new PDF document
newPage = newPdf.Pages.Add()
# Draw the content of the retrieved page onto the new page
page.CreateTemplate().Draw(newPage, PointF(0.0, 0.0))
# Save the new PDF document
newPdf.SaveToFile("output/SplitPDFPage.pdf")
pdf.Close()
newPdf.Close()
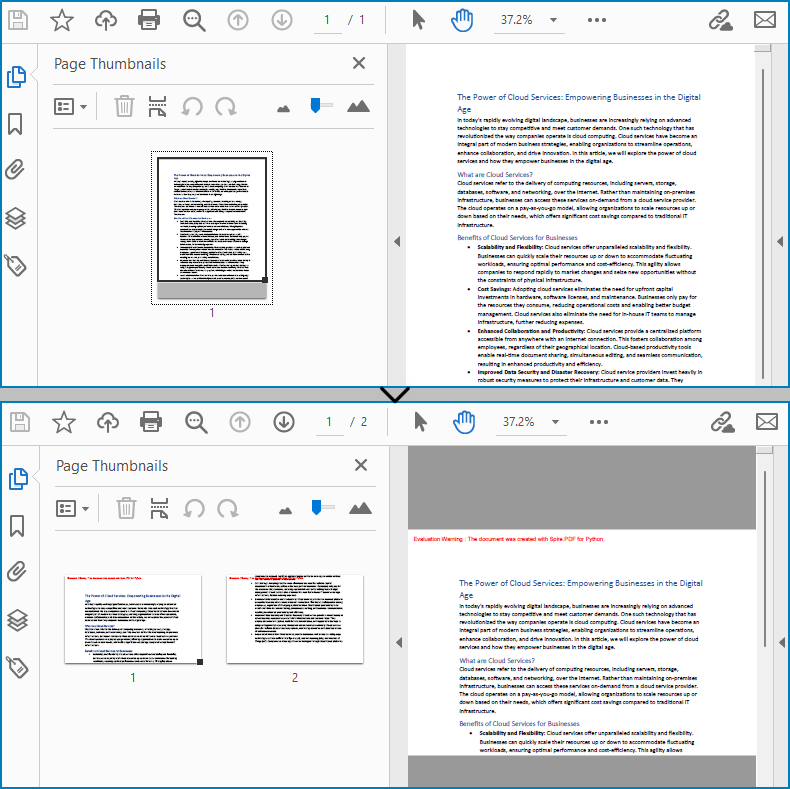
Merge Multiple PDF Pages into a Single Page with Python
Similarly, developers can merge PDF pages by drawing different pages on the same PDF page. It should be noted that the pages to be merged are preferably in the same width or height, otherwise it is necessary to take the maximum value to ensure correct drawing.
The detailed steps for merging two PDF pages into a single PDF page are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first and second pages of the document using PdfDocument.Pages.get_Item() method.
- Create a new PDF document by creating an object of PdfDocument class.
- Set the margins of the new document to 0 through PdfDocument.PageSettings.Margins.All property.
- Get the width and height of the two retrieved pages through PdfPageBase.Size.Width property and PdfPageBase.Size.Height property.
- Set the width of the new PDF document to the same as the retrieved pages through PdfDocument.PageSettings.Width property and its height to the sum of the two retrieved pages' heights through PdfDocument.PageSettings.Height property.
- Draw the content of the two retrieved pages onto the new page using PdfPageBase.CreateTemplate().Draw() method.
- Save the new document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample1.pdf")
# Get the first page and the second page of the document
page = pdf.Pages.get_Item(0)
page1 = pdf.Pages.get_Item(0)
# Create a new PDF document
newPdf = PdfDocument()
# Set the margins of the new PDF document to 0
newPdf.PageSettings.Margins.All = 0.0
# Set the page width of the new document to the same as the retrieved page
newPdf.PageSettings.Width = page.Size.Width
# Set the page height of the new document to the sum of the heights of the two retrieved pages
newPdf.PageSettings.Height = page.Size.Height + page1.Size.Height
# Add a new page to the new PDF document
newPage = newPdf.Pages.Add()
# Draw the content of the retrieved pages onto the new page
page.CreateTemplate().Draw(newPage, PointF(0.0, 0.0))
page1.CreateTemplate().Draw(newPage, PointF(0.0, page.Size.Height))
# Save the new document
newPdf.SaveToFile("output/MergePDFPages.pdf")
pdf.Close()
newPdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.XLS for Java 14.2.4 supports saving Kingdraw drawn OLE objects as images
We are pleased to announce the release of Spire.XLS for Java 14.2.4. This version supports saving Kingdraw drawn OLE objects as images. What's more, some known issues are fixed successfully, such as the issue that the content was incorrect when converting Excel to PDF. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREXLS-5046 | Supports saving Kingdraw drawn OLE objects as images.
com.spire.xls.Workbook workbook = new com.spire.xls.Workbook();
workbook.loadFromFile("data.xlsx");
Worksheet sheet = workbook.getWorksheets().get(0);
Object o = sheet.getCellRange("C2").getFormulaValue();
if (sheet.hasOleObjects()) {
for (int i = 0; i < sheet.getOleObjects().size(); i++) {
IOleObject oleObject = sheet.getOleObjects().get(i);
OleObjectType oleObjectType = sheet.getOleObjects().get(i).getObjectType();
byte[] picUrl = null;
switch (oleObjectType) {
case Emf:
picUrl = oleObject.getOleData();;
break;
}
if (picUrl != null) {
byteArrayToFile(picUrl, "out.png");
break;
}
}
}
}
public static void byteArrayToFile(byte[] datas, String destPath) {
File dest = new File(destPath);
try (InputStream is = new ByteArrayInputStream(datas);
OutputStream os = new BufferedOutputStream(new FileOutputStream(dest, false));) {
byte[] flush = new byte[1024];
int len = -1;
while ((len = is.read(flush)) != -1) {
os.write(flush, 0, len);
}
os.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
|
| Bug | SPIREXLS-5072 SPIREXLS-5099 |
Fixes the issue that the content was incorrect when converting Excel to PDF. |
| Bug | SPIREXLS-5076 | Fixes the issue that the images were incorrect after copying content. |
| Bug | SPIREXLS-5088 | Fixes the issue that the program threw "A workbook must contain at least a visible worksheet" when converting XML to Excel. |
| Bug | SPIREXLS-5089 | Optimizes the setting of Locale in the setValue method. |
| Bug | SPIREXLS-5095 | Fixes the issue that the program threw "NullPointerException" when copying tables. |
| Bug | SPIREXLS-5098 | Fixes the issue that the text content styles changed when converting Excel to HTML. |