Spire.PDFViewer 7.12.6 supports obtaining the coordinates of a mouse click relative to the PDF page content
We are happy to announce the release of Spire.PDFViewer 7.12.6. This version supports obtaining the coordinates of a mouse click relative to the PDF page content. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDFVIEWER-454 | Spire.PdfDocumentViewer supports obtaining the coordinates of a mouse click relative to the PDF page content.
private void Form1_Load(object sender, EventArgs e)
{
this.pdfDocumentViewer1.LoadFromFile("1.pdf");
this.pdfDocumentViewer1.MouseDown += new MouseEventHandler(PV_Click);
}
private void PV_Click(object sender, MouseEventArgs e)
{
string outputFile = "out.Pdf";
string outputFile_TXT = "out.txt";
File.Delete(outputFile_TXT);
if (e.Button == MouseButtons.Left)
{
PointF[] controlPositions = new PointF[] { e.Location};
Spire.PdfViewer.Forms.PagePosition[] pagePositions = this.pdfDocumentViewer1.ControlToPage(controlPositions);
string fileName = this.pdfDocumentViewer1.FileName;
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(fileName,FileFormat.PDF);
PdfPageBase page = doc.Pages[pagePositions[0].PageIndex];
RectangleF bounds = new RectangleF(pagePositions[0].Position, new SizeF(100, 100));
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
PdfTextExtractOptions option = new PdfTextExtractOptions();
option.ExtractArea = bounds;
string text = textExtractor.ExtractText(option);
PdfFont font = new PdfFont(PdfFontFamily.Helvetica, 11);
PdfTextWidget pdfTextbox = new PdfTextWidget();
pdfTextbox.Font = font;
pdfTextbox.Brush = PdfBrushes.Red;
pdfTextbox.Text = "stamp";
pdfTextbox.Draw(page, bounds);
doc.Pages[pagePositions[0].PageIndex].Canvas.DrawRectangle(PdfPens.Red, bounds);
doc.SaveToFile(outputFile);
File.AppendAllText(outputFile_TXT, "Position: " + pagePositions[0].Position.ToString() + "\ntext:\r\n " + text);
MessageBox.Show("finish");
doc.Dispose();
}
}
|
Spire.OCR 1.9.1 supports Linux operating system
We are happy to announce the release of Spire.OCR 1.9.1. In this version, Spire.OCR for .NET Standard DLL supports Linux operating system. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREOCR-30 | Spire.OCR for .NET Standard DLL supports Linux operating system. |
Python: Merge or Split Table Cells in PowerPoint
Merging and splitting table cells in PowerPoint are essential features that enable users to effectively organize and present data. By merging cells, users can create larger cells to accommodate more information or establish header rows for better categorization. On the other hand, splitting cells allows users to divide a cell into smaller units to showcase specific details, such as individual data points or subcategories. These operations enhance the visual appeal and clarity of slides, helping the audience better understand and analyze the presented data. In this article, we will demonstrate how to merge and split table cells in PowerPoint in Python using Spire.Presentation for Python.
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Merge Table Cells in PowerPoint in Python
Spire.Presentation for Python offers the ITable[columnIndex, rowIndex] property to access specific table cells. Once accessed, you can use the ITable.MergeCells(startCell, endCell, allowSplitting) method to merge them into a larger cell. The detailed steps are as follows.
- Create an object of the Presentation class.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Get a specific slide using Presentation.Slides[index] property.
- Find the table on the slide by looping through all shapes.
- Get the cells you want to merge using ITable[columnIndex, rowIndex] property.
- Merge the cells using ITable.MergeCells(startCell, endCell, allowSplitting) method.
- Save the result presentation using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
ppt = Presentation()
# Load a PowerPoint presentation
ppt.LoadFromFile("Table1.pptx")
# Get the first slide
slide = ppt.Slides[0]
# Find the table on the first slide
table = None
for shape in slide.Shapes:
if isinstance(shape, ITable):
table = shape
# Get the cell at column 2, row 2
cell1 = table[1, 1]
# Get the cell at column 2, row 3
cell2 = table[1, 2]
# Check if the content of the cells is the same
if cell1.TextFrame.Text == cell2.TextFrame.Text:
# Clear the text in the second cell
cell2.TextFrame.Paragraphs.Clear()
# Merge the cells
table.MergeCells(cell1, cell2, True)
# Save the result presentation to a new file
ppt.SaveToFile("MergeCells.pptx", FileFormat.Pptx2016)
ppt.Dispose()
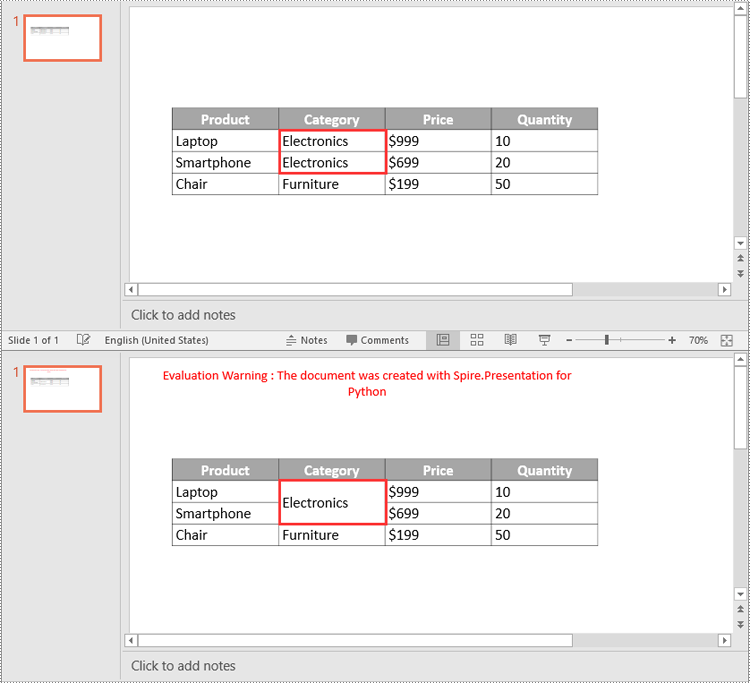
Split Table Cells in PowerPoint in Python
In addition to merging specific table cells, Spire.Presentation for Python also empowers you to split a specific table cell into smaller cells by using the Cell.Split(rowCount, colunmCount) method. The detailed steps are as follows.
- Create an object of the Presentation class.
- Load a PowerPoint presentation using Presentation.LoadFromFile() method.
- Get a specific slide using Presentation.Slides[index] property.
- Find the table on the slide by looping through all shapes.
- Get the cell you want to split using ITable[columnIndex, rowIndex] property.
- Split the cell into smaller cells using Cell.Split(rowCount, columnCount) method.
- Save the result presentation using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
ppt = Presentation()
# Load a PowerPoint presentation
ppt.LoadFromFile("Table2.pptx")
# Get the first slide
slide = ppt.Slides[0]
# Find the table on the first slide
table = None
for shape in slide.Shapes:
if isinstance(shape, ITable):
table = shape
# Get the cell at column 2, row 3
cell = table[1, 2]
# Split the cell into 3 rows and 2 columns
cell.Split(3, 2)
# Save the result presentation to a new file
ppt.SaveToFile("SplitCells.pptx", FileFormat.Pptx2016)
ppt.Dispose()
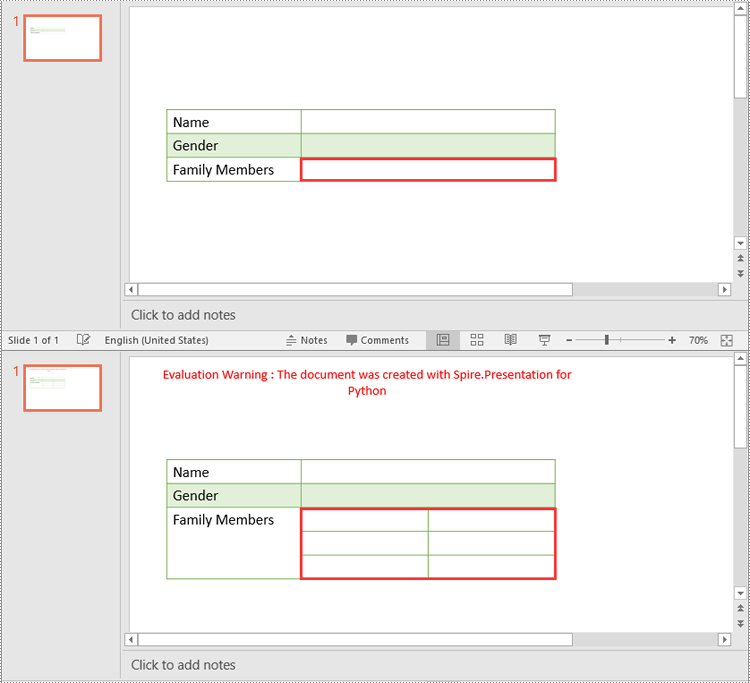
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Doc for Python 12.2.0 fixes the issue that the product package couldn't be installed with Python 3.7
We are pleased to announce the release of Spire.Doc for Python 12.2.0. This version fixes the issue that the product package couldn’t be installed with Python 3.7. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREDOC-10288 | Fixes the issue that the program failed to request resources when installing the product package with Python3.7. |
Python: Replace or Extract Images in Excel
Images in Excel can enhance data visualization and help convey information effectively. Apart from inserting/deleting images in Excel with Spire.XLS for Python, you can also use the library to replace existing images with new ones, or extract images for reuse or backup. This article will demonstrate how to replace or extract images in Excel in Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Replace Images in Excel with Python
To replace a picture in Excel, you can load a new picture and then set it as the value of the ExcelPicture.Picture property. The following are the detailed steps to replace an Excel image with another one.
- Create a Workbook instance.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specified worksheet using Workbook.Worksheets[] property.
- Get a specified picture from the worksheet using Worksheet.Pictures[] property.
- Load an image and then replace the original picture with it using ExcelPicture.Picture property.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook instance
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile ("ExcelImg.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the first picture from the worksheet
excelPicture = sheet.Pictures[0]
# Replace the picture with another one
excelPicture.Picture = Image.FromFile("logo.png")
# Save the result file
workbook.SaveToFile("ReplaceImage.xlsx", ExcelVersion.Version2016)

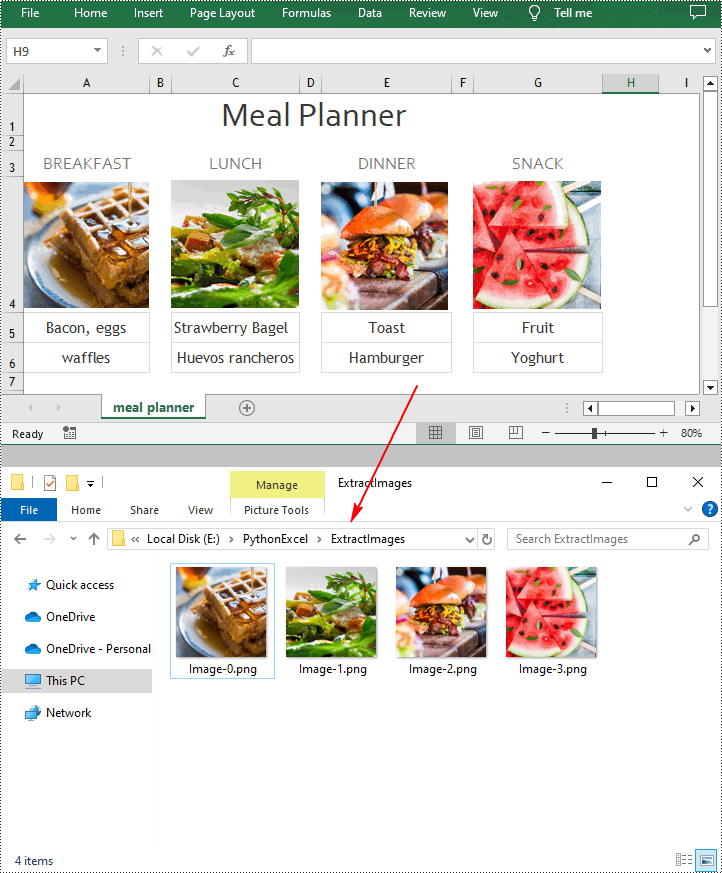
Extract Images from Excel with Python
Spire.XLS for Python provides the ExcelPicture.Picture.Save() method to save the images in Excel to a specified file path. The following are the detailed steps to extract all images in an Excel worksheet at once.
- Create a Workbook instance.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specified worksheet using Workbook.Worksheets[] property.
- Loop through to get all pictures in the worksheet using Worksheet.Pictures property.
- Extract pictures and save them to a specified file path using ExcelPicture.Picture.Save() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook instance
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("Test.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get all images in the worksheet
for i in range(sheet.Pictures.Count - 1, -1, -1):
pic = sheet.Pictures[i]
# Save each image as a PNG file
pic.Picture.Save("ExtractImages\\Image-{0:d}.png".format(i), ImageFormat.get_Png())
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Office 9.2.0 is released
We are excited to announce the release of Spire.Office 9.2.0. In this version, Spire.XLS supports setting the clipping position of header and footer images and adds XLT, XLTX, and XLTM formats to the FileFormat enumeration; Spire.Presentation supports embedding fonts in PPTX; Spire.PDF enhances the conversion from PDF to PDF/A, images, and OFD; Spire.Doc enhances the conversion from Word to PDF and HTML. Besides, a lot of known issues are fixed successfully in this version. More details are listed below.
In this version, the most recent versions of Spire.Doc, Spire.PDF, Spire.XLS, Spire.Presentation, Spire.Email, Spire.DocViewer, Spire.PDFViewer, Spire.Spreadsheet, Spire.OfficeViewer, Spire.DataExport, Spire.Barcode are included.
DLL Versions:
- Spire.Doc.dll v12.2.1
- Spire.Pdf.dll v10.2.2
- Spire.XLS.dll v14.2.1
- Spire.Presentation.dll v9.2.0
- Spire.Barcode.dll v7.2.9
- Spire.Spreadsheet.dll v7.4.6
- Spire.Email.dll v6.5.10
- Spire.DocViewer.Forms.dll v8.7.3
- Spire.PdfViewer.Forms.dll v7.12.3
- Spire.PdfViewer.Asp.dll v7.12.3
- Spire.OfficeViewer.Forms.dll v8.7.6
- Spire.DataExport.dll v4.9.0
- Spire.DataExport.ResourceMgr.dll v2.1.0
Here is a list of changes made in this release
Spire.PDF
| Category | ID | Description |
| Bug | SPIREPDF-6328 | Fixes the issue that the content was not displayed clearly when printing PDF. |
| Bug | SPIREPDF-6414 | Fixes the issue that the signature was damaged after reading a PDF containing a signature and saving it to a new document. |
| Bug | SPIREPDF-6431 | Fixes the issue that the value was rotated 90 degrees after modifying the value of a PDF form field. |
| Bug | SPIREPDF-6443 | Fixes the issue that text was not displayed clearly when converting PDF to images on the .NET Standard platform. |
| Bug | SPIREPDF-6278 | Fixes the issue that the result of drawing HTML text using PdfHTMLTextElement interface was incorrect. |
| Bug | SPIREPDF-6400 | Fixes the issue that the program threw System.OutOfMemoryException when saving a document after adding a bookmark. |
| Bug | SPIREPDF-6426 | Fixes the issue that content overlapped after replacing text. |
| Bug | SPIREPDF-6430 | Fixes the issue that the program threw System.IndexOutOfRangeException when converting OFD documents to PDF documents. |
| Bug | SPIREPDF-6445 | Fixes the issue that the program threw System.Collections.Generic.KeyNotFoundException when extracting tables. |
| Bug | SPIREPDF-6471 | Fixes the issue that the program threw System.ArgumentException when saving a page as an image after rotating it. |
| Bug | SPIREPDF-6473 | Fixes the issue that colored emoticons became black and white when converting HTML to PDF. |
| Bug | SPIREPDF-6477 | Fixes the issue that the content was incorrect after converting a PDF document to an image. |
| Bug | SPIREPDF-6480 | Fixes the issue that the program threw a System.NullReferenceException when printing PDF documents. |
| Bug | SPIREPDF-6483 | Fixes the issue that some text lost its bold style after converting a PDF document to an OFD document. |
| Bug | SPIREPDF-6427 SPIREPDF-6489 |
Fixes the issue that Find and Highlight text didn't work. |
| Bug | SPIREPDF-6456 | Fixes the issue that Arabic fonts were lost after converting a PDF document to a PDFA document. |
| Bug | SPIREPDF-6493 | Fixes the issue that the stamp position was shifted when printing PDF documents. |
| Bug | SPIREPDF-6509 | Fixes the issue that it was invalid to print a PDF document with the opposite direction of the front and back when printing on both sides of the document. |
| Bug | SPIREPDF-6510 | Fixes the issue that the program threw a System.NullReferenceException when converting a PDF document to a picture. |
| Bug | SPIREPDF-6524 | Fixes the issue that the font was over-bolded when converting a PDF document to an OFD document and then back to a PDF document. |
Spire.Doc
| Category | ID | Description |
| New feature | SPIREDOC-9979 SPIREDOC-10058 |
The left and right indentation function of the paragraph supports the option of setting the number of characters.
// Set left indentation by character count paragraph.Format.LeftIndentChars = 10; // Set right indentation by character count paragraph.Format.RightIndentChars = 10; |
| Bug | SPIREDOC-3363 | Fixes the issue that the content format was incorrect when converting Word documents to PDF documents. |
| Bug | SPIREDOC-3363 SPIREDOC-10083 |
Fixes the issue that the font changed when converting Word documents to PDF documents. |
| Bug | SPIREDOC-9136 | Fixes the issue that the document structure tags were lost when converting Word documents to PDF documents. |
| Bug | SPIREDOC-9718 | Fixes the issue that the fonts of formula content in saved Docx documents had extra italic effects. |
| Bug | SPIREDOC-9756 | Fixes the issue that the program threw System.ArgumentException when converting Word documents to HTML documents. |
| Bug | SPIREDOC-10001 | Fixes the issue that table border changed when converting Word documents to PDF documents. |
| Bug | SPIREDOC-10016 | Fixes the issue that there was an extra blank paragraph after replacing bookmark content. |
| Bug | SPIREDOC-10084 | Fixes the issue that font bold style was lost when converting Word documents to PDF documents. |
| Bug | SPIREDOC-10110 | Fixes the issue that the program threw System.ArgumentOutOfRangeException when loading Doc documents. |
| Bug | SPIREDOC-10111 | Fixes the issue that content was indented when converting Word documents to PDF documents. |
| Bug | SPIREDOC-10119 | Fixes the issue that getting codes in cross-reference fields failed. |
| Bug | SPIREDOC-10132 | Fixes the issue that the program threw System.ArgumentOutOfRangeException when getting FixedLayoutDocument objects in blank documents. |
| Bug | SPIREDOC-10195 | Fixes the issue that the program threw System.NullReferenceException when deleting bookmark content after copying documents. |
Spire.XLS
| Category | ID | Description |
| New feature | SPIREXLS-5036 | Improves the memory usage of converting worksheets to images. |
| New feature | SPIREXLS-5006 | Adds XLT, XLTX, and XLTM formats to the FileFormat enumeration. |
| New feature | SPIREXLS-5038 | Supports setting the clipping position of header and footer images.
sheet.PageSetup.LeftHeaderPictureCropTop=6.15; sheet.PageSetup.LeftHeaderPictureCropBottom=7.15; sheet.PageSetup.LeftHeaderPictureCropLeft =7.15; sheet.PageSetup.LeftHeaderPictureCropRight = 6.15; sheet.PageSetup.LeftFooterPictureCropTop=0.15; sheet.PageSetup.LeftFooterPictureCropBottom=0.15; sheet.PageSetup.LeftFooterPictureCropLeft =0.15; sheet.PageSetup.LeftFooterPictureCropRight =0.15; sheet.PageSetup.CenterHeaderPictureCropTop=0.15; sheet,PageSetup.CenterHeaderPictureCropBottom=0.15; sheet.PageSetup.CenterHeaderPictureCropLeft=0.15; sheet.PageSetup.CenterHeaderPictureCropRight =0.15; sheet.PageSetup.CenterFooterPictureCropTop=0.15; sheet.PageSetup.CenterFooterPictureCropBottom=0.15; sheet.PageSetup.CenterFooterPictureCropLeft =0.15; sheet.PageSetup.CenterFooterPictureCropRight=0.15; sheet.PageSetup.RightHeaderPictureCropTop=0.15; sheet.PageSetup.RightHeaderPictureCropBottom=0.15; sheet.PageSetup.RightHeaderPictureCropLeft=0.15; sheet.PageSetup.RightHeaderPictureCropRight=0.15; sheet.PageSetup.RightFooterPictureCropTop=0.15; sheet.PageSetup.RightFooterPictureCropBottom=0.15; sheet.PageSetup.RightFooterPictureCropLeft=0.15; |
| Bug | SPIREXLS-5016 | Fixed the issue that the program threw System.ArgumentOutOfRangeException when executing sheet.AutoFilters.Clear(). |
| Bug | SPIREXLS-5018 | Fixed the issue that opening the saved XLSX document with MS Excel tool after loading an XLSX document without modifying it and saving it directly to a new XLSX document prompted an error in some of the contents. |
| Bug | SPIREXLS-5022 | Fixed the issue that some contents of the saved XLSX document prompted errors after inserting data into the worksheet and opening the saved XLSX document with MS Excel tool. |
| Bug | SPIREXLS-5023 | Fixed the issue that retrieving cells failed. |
| Bug | SPIREXLS-5025 | Fixed the issue that paging was incorrect after converting Excel to PDF. |
| Bug | SPIREXLS-5028 | Fixed the issue that the content was misplaced after converting Excel to CSV. |
| Bug | SPIREXLS-5032 | Fixed the issue that the text of legend was messy after converting Excel to HTML with .Net Standard package in Linux system. |
| Bug | SPIREXLS-5034 | Fixed the issue that the program threw "No printers are installed" error when loading files under Linux environment. |
| Bug | SPIREXLS-5039 | Fixed the issue that the pivot chart data was incorrect after converting worksheets to pictures. |
| Bug | SPIREXLS-5061 | Fixed the issue that the program threw "Shape failing to render!" error when converting Excel to PDF. |
| Bug | SPIREXLS-5066 | Fixes the issue that the comments in the resulting document were not displayed in Office365 after calling the cellRange.ClearContents() method. |
| Bug | SPIREXLS-5073 | Fixes the issue that when the sheet name contained the special character \t, the \t was read as x0009. |
| Bug | SPIREXLS-5080 | Fixes the issue that the content was incorrect when converting XLSX documents to PDF documents. |
| Bug | SPIREXLS-5083 | Fixes the issue that the application threw "System.ArgumentException" when converting XLSX documents to PDF documents |
| Bug | SPIREXLS-5084 | Fixes the issue that the text content was overlapped when converting XLSX documents to images. |
| Bug | SPIREXLS-5090 | Fixes the issue that the "Operation is not supported on this platform" exception occurred when deploying the .netstand2.0 dlls on the .NET7.0 platform. |
Spire.Presentation
| Category | ID | Description |
| New feature | - | Support embedding fonts in PPTX: only supports embedding fonts into PPTX format, and does not support embedding into PDF and PowerPoint 2003 formats; when embedding Chinese name fonts, the font names are not displayed in Chinese.
ppt.AddEmbeddedFont(string fontpath); |
| New feature | SPIREPPT-2424 | Provides the IsHidden property to determine whether the Ole object is hidden.
OleObjectCollection oles = ppt.Slides[0].OleObjects; OleObject ole= oles[0]; bool result=ole.IsHidden; |
| Adjustment | - | Upgrades the VS2019 project framework to version 4.6.2. |
| Adjustment | - | Removes MonoAndroid and Xamarin.iOS. |
| Adjustment | - | Removes the reference of Spire.Pdf.dll from the product. |
| Adjustment | - | "Spire.Pdf.PdfConformanceLevel" has been deprecated and replaced with the new interface "Spire.Presentation.External.pdf.PdfConformanceLevel".
presentation.SaveToPdfOption.PdfConformanceLevel = Spire.Presentation.External.Pdf.PdfConformanceLevel.Pdf_A1A; |
| Adjustment | - | "Spire.Pdf.Sercurity.PdfSecurity" has been deprecated and replaced with the new interface "Spire.Presentation.External.Pdf.PdfSecurity". |
| Bug | SPIREPPT-2418 | Fixes the issue that the program threw "Microsoft PowerPoint 2007 file is corrpt." exception when loading a PPTX file when the system regional language was set to Turkish. |
| Bug | SPIREPPT-2396 | Fixes the issue that the effect was incorrect after changing the chart label position. |
Spire.Doc for C++ 12.2.0 fixes the issue that strings were lost on Linux
We are happy to announce the release of Spire.Doc for C++ 12.2.0. This version fixes the issue that strings were lost on Linux. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | - | Fixes the issue that strings were lost on Linux. |
Get Excel Summary using AI
In the era of big data, facing the challenge of processing massive amounts of information stored in Excel documents, artificial intelligence (AI) technology provides a new solution for efficiently and accurately extracting key content and generating summaries.
This article focuses on the application of AI to automatically identify and extract core data from Excel documents, enabling the automated generation of concise and highlighted document summaries. This technology not only enhances data processing efficiency but also empowers decision-makers to gain deeper insights and utilize the data effectively. In the following sections, we will gradually explore how to apply AI technology to precisely extract summaries from Excel documents.
Install Spire.XLS for .NET
The Excel AI integrated into Spire.XLS for .NET package, hence to begin with, you need to add the DLL files included in the Spire.XLS for .NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.XLS
Request a License Key of AI Product
A license key is required to run Spire.XLS AI, please contact our sales department (sales@e-iceblue.com) to request one.
Use AI to get Document Summaries
Spire.XLS AI provides the ExcelAI class, which encapsulates the ability to perform intelligent analysis and search on Excel data. In fact, ExcelAI goes beyond merely supporting intelligent analysis of Excel data, it also extends its capabilities to encompass a variety of file formats such as txt, csv, pdf, and md, thereby enabling cross-format intelligent processing and insights. Within this class, three key methods are included:
- UploadWorkbook(Workbook wb): This method is used to upload a Workbook object processed by Spire.XLS to the AI server, facilitating the integration of Excel content with the AI system's data.
- UploadFile(string fileName, Stream stream): This method is used to upload txt files or files in other formats to the AI server.
- DocumentSearch(string question, string file_server_path, bool enableHistory = false): This method allows posing specific questions to the AI system against a designated Excel document, generating intelligent responses based on its contents. The optional parameter enableHistory is set to false by default, if set to true, it enables the search history feature, allowing subsequent operations to track or leverage previous query results.
1. The following code demonstrates how to retrieve a summary of content from an Excel document:
- C#
using Spire.Xls;
using Spire.Xls.AI;
using System.IO;
using System.Text;
// Define the file path of the Excel document
string inputfile = "input.xlsx";
// Create a new instance of the Workbook
Workbook wb = new Workbook();
// Load the Excel file
wb.LoadFromFile(inputfile);
// Create a new instance of the ExcelAI
ExcelAI excelAI = new ExcelAI();
// Upload the workbook and obtain the file path where it's stored in the AI system
string fpath = excelAI.UploadWorkbook(wb);
// Set the question to be asked to the AI system. In this case, asking it to generate a concise summary from the Excel
string question = "Please generate a concise summary from the document";
// Get the answer generated by the AI based on the question
string answer = excelAI.DocumentSearch(question, fpath, true);
// Create a StringBuilder object to append the answer
StringBuilder builder = new StringBuilder();
builder.AppendLine(answer);
// Write the answer to the txt file
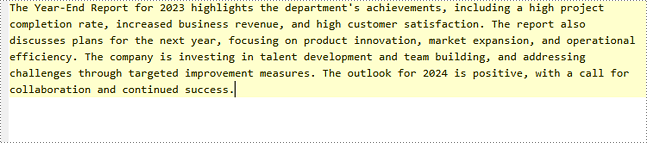
File.WriteAllText("SummaryFromExcel.txt", builder.ToString());
Input Excel Content:

Generated TXT Content:
2. The following code demonstrates how to retrieve a summary of content from a TXT:
- C#
using Spire.Xls.AI;
using System.IO;
using System.Text;
// Define the file path of the txt
string inputfile = "input.txt";
// Create a new instance of the ExcelAI
ExcelAI excelAI = new ExcelAI();
// Open and read the content of the text file as a stream
using (Stream stream = File.Open(inputfile, FileMode.Open))
{
// Upload the text file to the AI system
string fpath = excelAI.UploadFile(inputfile, stream);
// Set the question to be asked to the AI system. In this case, asking it to generate a concise summary from the txt
string question = "Please generate a concise summary from the document";
// Get the answer generated by the AI based on the question
string answer = excelAI.DocumentSearch(question, fpath, true);
// Create a StringBuilder object to append the answer
StringBuilder builder = new StringBuilder();
builder.AppendLine(answer);
// Write the answer to the txt file
File.WriteAllText("SummaryFromTxt.txt", builder.ToString());
}
Input TXT Content:

Generated TXT Content:

Spire.XLS 14.2.1 supports setting the clipping position of header and footer images
We're pleased to announce the release of Spire.XLS 14.2.1. This version supports setting the clipping position of header and footer images. In addition, some known issues that occurred when converting XLSX documents to PDF or images have been successfully fixed. More details are shown below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREXLS-5038 | Supports setting the clipping position of header and footer images.
sheet.PageSetup.LeftHeaderPictureCropTop=6.15; sheet.PageSetup.LeftHeaderPictureCropBottom=7.15; sheet.PageSetup.LeftHeaderPictureCropLeft =7.15; sheet.PageSetup.LeftHeaderPictureCropRight = 6.15; sheet.PageSetup.LeftFooterPictureCropTop=0.15; sheet.PageSetup.LeftFooterPictureCropBottom=0.15; sheet.PageSetup.LeftFooterPictureCropLeft =0.15; sheet.PageSetup.LeftFooterPictureCropRight =0.15; sheet.PageSetup.CenterHeaderPictureCropTop=0.15; sheet,PageSetup.CenterHeaderPictureCropBottom=0.15; sheet.PageSetup.CenterHeaderPictureCropLeft=0.15; sheet.PageSetup.CenterHeaderPictureCropRight =0.15; sheet.PageSetup.CenterFooterPictureCropTop=0.15; sheet.PageSetup.CenterFooterPictureCropBottom=0.15; sheet.PageSetup.CenterFooterPictureCropLeft =0.15; sheet.PageSetup.CenterFooterPictureCropRight=0.15; sheet.PageSetup.RightHeaderPictureCropTop=0.15; sheet.PageSetup.RightHeaderPictureCropBottom=0.15; sheet.PageSetup.RightHeaderPictureCropLeft=0.15; sheet.PageSetup.RightHeaderPictureCropRight=0.15; sheet.PageSetup.RightFooterPictureCropTop=0.15; sheet.PageSetup.RightFooterPictureCropBottom=0.15; sheet.PageSetup.RightFooterPictureCropLeft=0.15; |
| Bug | SPIREXLS-5066 | Fixes the issue that the comments in the resulting document were not displayed in Office365 after calling the cellRange.ClearContents() method. |
| Bug | SPIREXLS-5073 | Fixes the issue that when the sheet name contained the special character \t, the \t was read as x0009. |
| Bug | SPIREXLS-5080 | Fixes the issue that the content was incorrect when converting XLSX documents to PDF documents. |
| Bug | SPIREXLS-5083 | Fixes the issue that the application threw "System.ArgumentException" when converting XLSX documents to PDF documents |
| Bug | SPIREXLS-5084 | Fixes the issue that the text content was overlapped when converting XLSX documents to images. |
| Bug | SPIREXLS-5090 | Fixes the issue that the "Operation is not supported on this platform" exception occurred when deploying the .netstand2.0 dlls on the .NET7.0 platform. |
Spire.Presentation for Java 9.2.2 adds methods to get and set the transparency and brightness of colors
We are delighted to announce the release of Spire.Presentation for Java 9.2.2. This version adds methods to get and set the transparency and brightness of colors. It also enhances the conversion from PowerPoint to PDF. Besides, some known issues are fixed in this version, such as the issue that the obtained alignment of text was incorrect. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPPT-2419 | Adds getTransparency() and setTransparency(value) methods to get and set the transparency of the color, getBrightness() and setBrightness(value) methods to get and set the brightness of the color. |
| Bug | SPIREPPT-2392 | Fixes the issue that the charts were incorrect after converting a PowerPoint document to a PDF document. |
| Bug | SPIREPPT-2413 | Fixes the issue that the obtained alignment of text was incorrect. |
| Bug | SPIREPPT-2429 | Fixes the issue that it failed to parse color:rgb(0, 0, 0) in HTML. |
| Bug | SPIREPPT-2430 | Fixes the issue that the values of axes changed after converting a PowerPoint document to a PDF document. |