Table of Contents
Install with Pip
pip install Spire.Doc
Related Links
Converting HTML files to PDF documents is a frequent requirement for various purposes, such as archiving web content, creating offline shareable web pages in a stable PDF format, or generating printable reports from HTML content. Having a reliable and efficient solution to convert HTML files to the universally accessible and stable PDF format is crucial for maximizing productivity. Fortunately, by harnessing the capabilities of Python, we can convert HTML to PDF effortlessly in Python programs, enabling the easy generation of PDF documents from HTML content.

This article focuses on leveraging Python for HTML to PDF conversion, highlighting the benefits, the main steps, and code examples of the conversion. It includes the following topics:
- Tips and Considerations for Converting HTML to PDF with Python
- Python API for HTML to PDF Conversion
- Steps and Code Example for Converting HTML to PDF in Python
- Steps and Code Example for Rendering HTML strings to PDF via Python
- Free License for the Python API to Convert HTML to PDF
- Free Online Converter for HTML to PDF Conversion
Tips and Considerations for Converting HTML to PDF with Python
With the help of Python libraries, developers and users can easily generate professional-looking PDF documents from web pages, including images, formatting, and hyperlinks. The key advantages of HTML to PDF conversion with Python are:
- Consistent Content Appearance Across Devices: Python HTML to PDF conversion enables the creation of printable reports and documents with a consistent appearance. This facilitates offline access as well as seamless sharing and printing across various devices and operating systems.
- Efficient Batch Conversion: Python code enables efficient batch conversion of HTML to PDF documents. Developers can automate the conversion process and convert multiple HTML files into PDF format simultaneously, saving time and effort.
Despite these advantages, it's crucial to acknowledge the limitations of HTML to PDF conversion. The main challenges are:
- Dynamic Content: Web pages often contain interactive elements, animations, and real-time updates, which are difficult to replicate in a static PDF document.
- Rendering Differences: Due to the complexities of web rendering and the limitations of the PDF format, there may be variations in the appearance of the PDF compared to the original web page.
To achieve the best results, developers can opt for simpler web pages when using Python for HTML to PDF conversion. Alternatively, they can preprocess the HTML file by retaining only the text content before conversion.
Python API for HTML to PDF Conversion
Spire.Doc for Python is a powerful Python library designed for efficient document processing, including tasks such as document creation, editing, and conversion. With Spire.Doc for Python, developers can leverage a comprehensive set of classes and methods to seamlessly convert HTML files to PDF in Python. Additionally, this library also provides the capability to convert HTML strings to PDF documents.
Key classes and methods for converting HTML to PDF in Python:
| Item | Description |
| Document class | Represents a Word document. |
| Document.LoadFromFile() method | Load a file in DOCX, HTML, and other formats as a Word document. |
| Document.SaveToFile() method | Save a Word document to file in DOCX, PDF, HTML, and other formats. |
| Paragraph.AppendHTML() method | Renders an HTML string within a document. |
| FileFormat Enum | Enum class representing different types of file formats. |
| XHTMLValidationType Enum | Enum class representing the options for XHTML validation, including no, strict, and transitional validation. |
Users can download Spire.Doc for Python on the official website or install it with PyPI:
- Python
Pip install Spire.Doc
Steps and Code Example for Converting HTML to PDF in Python
By loading an HTML file and saving it as an PDF file, developers can use Python to convert HTML to PDF with simple code. The main steps are as follows:
- Import the required modules.
- Create an object of Document class.
- Load an HTML file using Document.LoadFromFile() method.
- Convert the HTML file to PDF and save it using Document.SaveToFile() method.
Below is a code example for converting HTML to PDF in Python:
- Python
from spire.doc import Document
from spire.doc import FileFormat
from spire.doc import XHTMLValidationType
# Create an object of Document class
doc = Document()
# Load an HTML file
doc.LoadFromFile("Sample.html", FileFormat.Html, XHTMLValidationType.none)
# Save convert the file to PDF format and save it
doc.SaveToFile("output/HTMLToPDF.pdf", FileFormat.PDF)
doc.Close()
Conversion Effect:
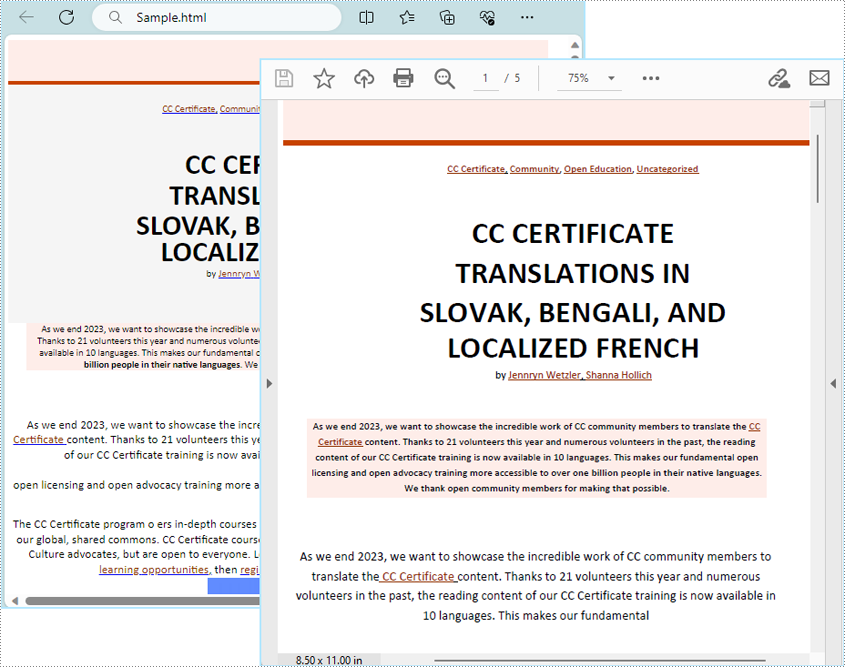
Steps and Code Example for Rendering HTML Strings to PDF via Python
HTML strings typically refer to text containing HTML tags, attributes, and content to describe the structure and presentation of a web page. By using Paragraph.AppendHTML() method, developers can effortlessly render HTML strings in documents and then save then as PDF files. The main steps are as follows:
- Import the required modules.
- Create an object of Document class.
- Add a section to the document using Document.AddSection() method and add a paragraph to the section using Section.AddParagraph() method.
- Specify the HTML string.
- Render the HTML string in the document using Paragraph.AppendHTML() method.
- Convert the document to PDF and save it using Document.SaveToFile() method.
A code example for converting HTML string to PDF in Python:
- Python
from spire.doc import Document
from spire.doc import FileFormat
# Create an object of Document class
doc = Document()
# Add a section to the document
sec = doc.AddSection()
# Add a paragraph to the section
par = sec.AddParagraph()
# Specify the HTML string
htmlString = """
<html>
<head>
<title>HTML Example</title>
</head>
<body>
<h1 style="color: blue;">Welcome to My Website</h1>
<h2>Personal Information</h2>
<ul>
<li>Name: John Doe</li>
<li>Age: 30</li>
<li>Nationality: United States</li>
</ul>
<h2>Work Experience</h2>
<table border="1">
<tr>
<th>Company</th>
<th>Position</th>
<th>Year</th>
</tr>
<tr>
<td>ABC Company</td>
<td>Software Engineer</td>
<td>2018-2020</td>
</tr>
<tr>
<td>XYZ Company</td>
<td>Project Manager</td>
<td>2020-2022</td>
</tr>
</table>
<h2>Project List</h2>
<ol>
<li>Project A</li>
<li>Project B</li>
<li>Project C</li>
</ol>
</body>
</html>
"""
# Render the HTML string in the document
par.AppendHTML(htmlString)
# Save the document as an PDF file
doc.SaveToFile("output/HTMLStringToPDF.pdf", FileFormat.PDF)
doc.Close()
Generated PDF Document:
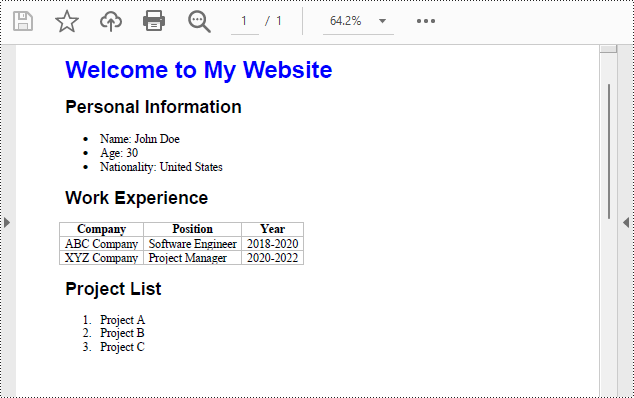
Free License for the Python API to Convert HTML to PDF
Spire.Doc for Python offers a 30-day free license that allows users to unlock any limitations in document processing and conversion, including HTML to PDF conversion with Python. By applying for a Free License, users can fully utilize the powerful file processing and conversion features provided by the API.
Free Online Converter for HTML to PDF Conversion
For users seeking to convert a small number of simple HTML files to PDF documents without any complex operations, we recommend utilizing the Free Online PDF Converter. This tool allows for easy conversion by simply uploading an HTML file and downloading the resulting PDF document. It offers a straightforward solution for quick and hassle-free conversions.

Conclusion
The above article focused on Python for HTML to PDF conversion. It explained the advantages and limitations of converting HTML to PDF with Python and gave instructions and code examples for using Spire.Doc for Python to convert HTML to PDF and HTML string to PDF. By referring to the methods above, developers can create their own Python programs to achieve automated and high-quality conversion. If any issues occurred during using Spire.Doc for Python, please go to the Spire.Doc Forum for technical support.
