Оглавление
Установлено через NuGet
PM> Install-Package Spire.PDF
Ссылки по теме
PDF-документы имеют фиксированный макет и не позволяют пользователям вносить в них изменения. Чтобы снова сделать содержимое PDF доступным для редактирования, вы можете конвертировать PDF в Word или извлечь текст из PDF. В этой статье вы узнаете, как извлечь текст из определенной страницы PDF, как извлечь текст из определенной области прямоугольника, и как извлекайте текст с помощью SimpleTextExtractionStrategy в C# и VB.NET используя Spire.PDF for .NET.
- Извлечь текст с указанной страницы
- Извлечь текст из прямоугольника
- Извлеките текст с помощью SimpleTextExtractionStrategy
Установите Spire.PDF for .NET
Для начала вам необходимо добавить файлы DLL, включенные в пакет Spire.PDF for.NET, в качестве ссылок в ваш проект .NET. Файлы DLL можно загрузить по этой ссылке или установить через NuGet.
PM> Install-Package Spire.PDF
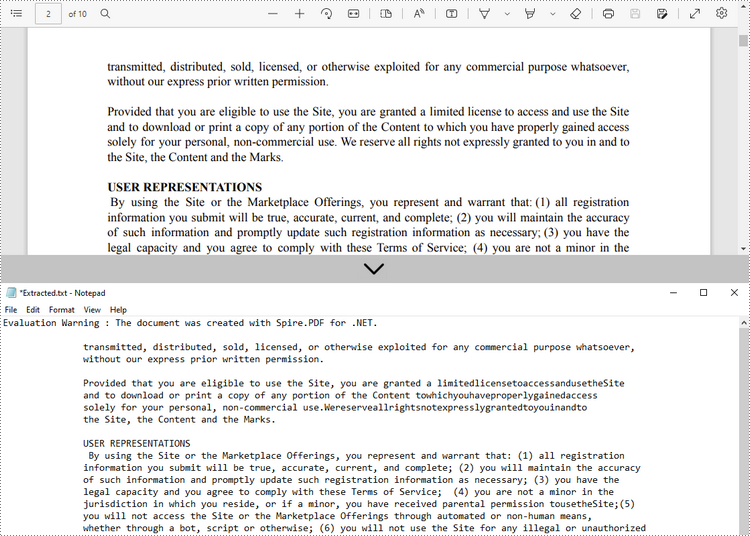
Извлечь текст с указанной страницы
Ниже приведены шаги по извлечению текста из определенной страницы PDF-документа с помощью Spire.PDF for .NET.
- Создайте объект PDFDocument.
- Загрузите PDF-файл с помощью метода PdfDocument.LoadFromFile().
- Получите конкретную страницу через свойство PdfDocument.Pages[index].
- Создайте объект PdfTextExtractor.
- Создайте объект PdfTextExtractOptions и задайте для свойства IsExtractAllText значение true.
- Извлеките текст с выбранной страницы с помощью метода PdfTextExtractor.ExtractText().
- Запишите извлеченный текст в файл TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
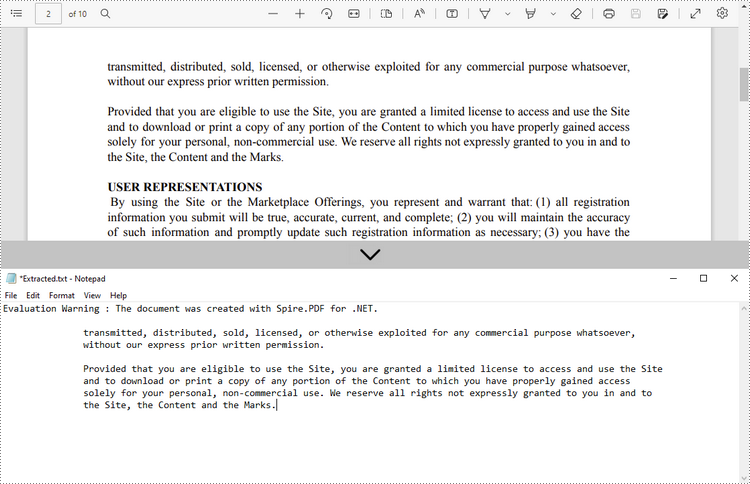
Извлечь текст из прямоугольника
Ниже приведены шаги по извлечению текста из прямоугольной области страницы с помощью Spire.PDF for .NET.
- Создайте объект PDFDocument.
- Загрузите PDF-файл с помощью метода PdfDocument.LoadFromFile().
- Получите конкретную страницу через свойство PdfDocument.Pages[index].
- Создайте объект PdfTextExtractor.
- Создайте объект PdfTextExtractOptions и укажите область прямоугольника с помощью его свойства ExtractArea.
- Извлеките текст из прямоугольника с помощью метода PdfTextExtractor.ExtractText().
- Запишите извлеченный текст в файл TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
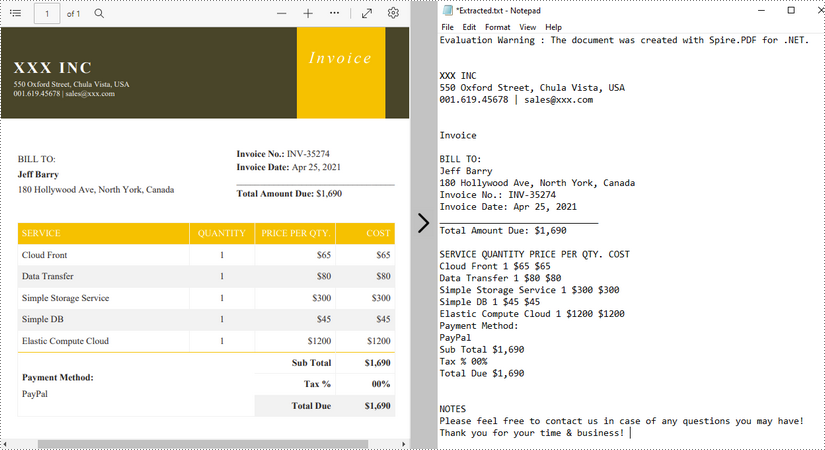
Извлеките текст с помощью SimpleTextExtractionStrategy
Вышеупомянутые методы извлекают текст построчно. При извлечении текста с помощью SimpleTextExtractionStrategy он отслеживает текущую позицию Y каждой строки и вставляет разрыв строки в выходные данные, если позиция Y изменилась. Ниже приведены подробные шаги.
- Создайте объект PDFDocument.
- Загрузите PDF-файл с помощью метода PdfDocument.LoadFromFile().
- Получите конкретную страницу через свойство PdfDocument.Pages[index].
- Создайте объект PdfTextExtractor.
- Создайте объект PdfTextExtractOptions и задайте для свойства IsSimpleExtraction значение true.
- Извлеките текст с выбранной страницы с помощью метода PdfTextExtractor.ExtractText().
- Запишите извлеченный текст в файл TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Подать заявку на временную лицензию
Если вы хотите удалить сообщение об оценке из сгенерированных документов или избавиться от ограничений функции, пожалуйста запросите 30-дневную пробную лицензию для себя.
