
PDF documents are fixed in layout and do not allow users to perform modifications in them. To make the PDF content editable again, you can convert PDF to Word or extract text from PDF. In this article, you will learn how to extract text from a specific PDF page, how to extract text from a particular rectangle area, and how to extract text by SimpleTextExtractionStrategy in C# and VB.NET using Spire.PDF for .NET.
- Extract Text from a Specified Page
- Extract Text from a Rectangle
- Extract Text using SimpleTextExtractionStrategy
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
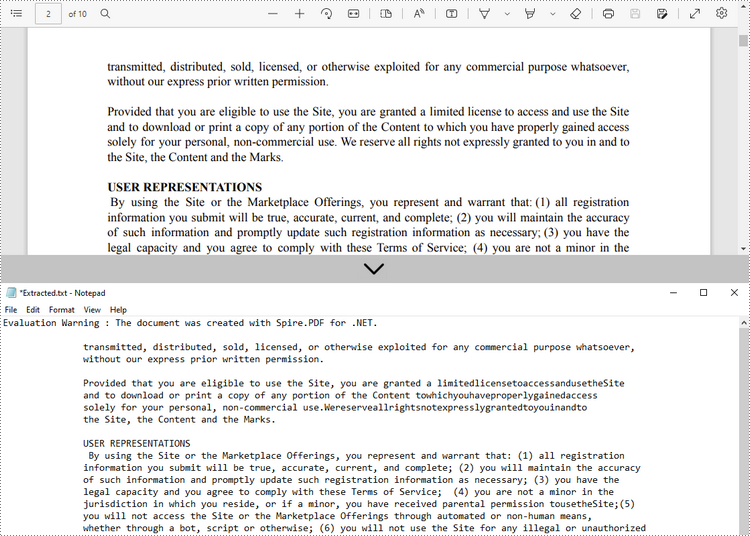
Extract Text from a Specified Page
The following are the steps to extract text from a certain page of a PDF document using Spire.PDF for .NET.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and set the IsExtractAllText property to true.
- Extract text from the selected page using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
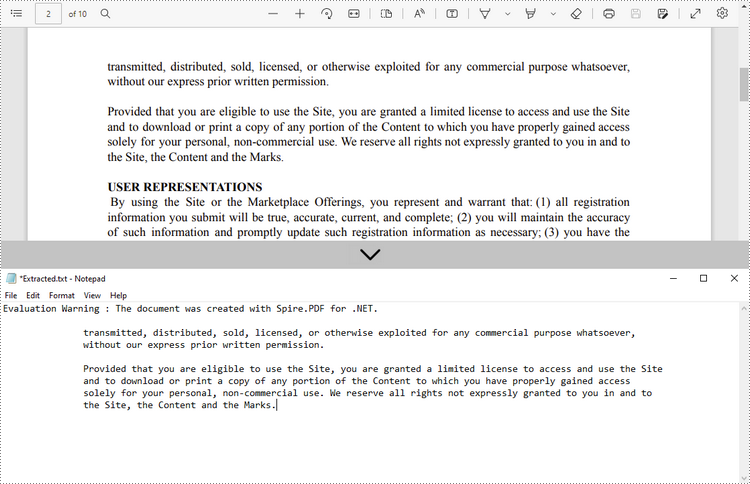
Extract Text from a Rectangle
The following are the steps to extract text from a rectangle area of a page using Spire.PDF for .NET.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and specify the rectangle area through the ExtractArea property of it.
- Extract text from the rectangle using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
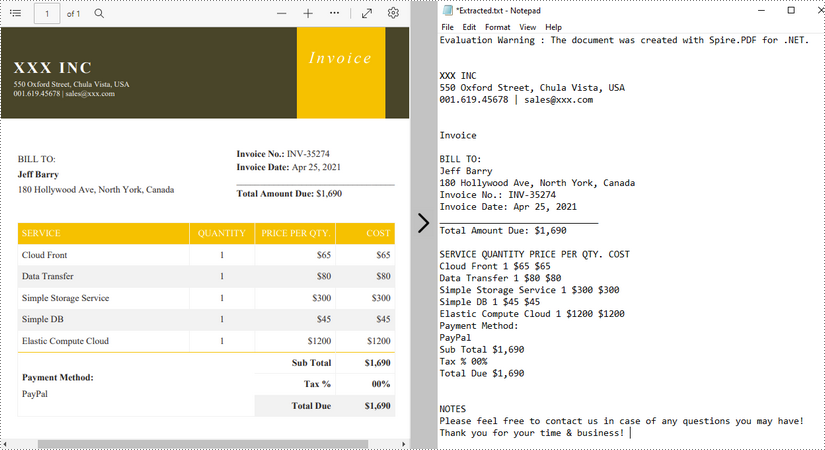
Extract Text using SimpleTextExtractionStrategy
The above methods extract text line by line. When extracting text using SimpleTextExtractionStrategy, it keeps track of the current Y position of each string and inserts a line break into the output if the Y position has changed. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object and set the IsSimpleExtraction property to true.
- Extract text from the selected page using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
