Instalado via NuGet
PM> Install-Package Spire.PDF
Links Relacionados
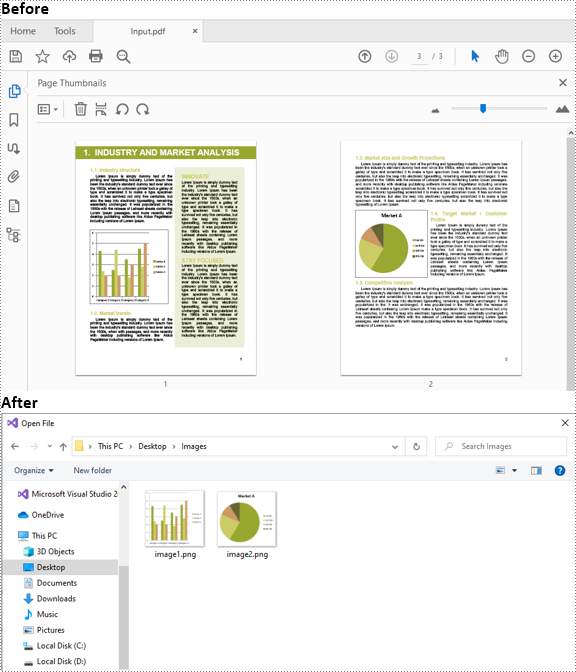
As imagens são frequentemente usadas em documentos PDF para apresentar informações de maneira facilmente compreensível. Em certos casos, pode ser necessário extrair imagens de documentos PDF. Por exemplo, quando você deseja usar uma imagem gráfica de um relatório PDF em uma apresentação ou outro documento. Este artigo demonstrará como extrair imagens de PDF em C# e VB.NET usando Spire.PDF for .NET.
Instale o Spire.PDF for .NET
Para começar, você precisa adicionar os arquivos DLL incluídos no pacote Spire.PDF for.NET como referências em seu projeto .NET. Os arquivos DLL podem ser baixados deste link ou instalados via NuGet.
PM> Install-Package Spire.PDF
Extraia imagens de PDF em C# e VB.NET
A seguir estão as etapas principais para extrair imagens de um documento PDF usando Spire.PDF for .NET:
- Crie um objeto PdfDocument.
- Carregue um documento PDF usando o método PdfDocument.LoadFromFile().
- Percorra todas as páginas do documento.
- Extraia imagens de cada página usando o método PdfPageBase.ExtractImages() e salve-as em um caminho de arquivo especificado.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Solicite uma licença temporária
Se desejar remover a mensagem de avaliação dos documentos gerados ou se livrar das limitações de função, por favor solicite uma licença de teste de 30 dias para você mesmo.
