NuGet을 통해 설치됨
PM> Install-Package Spire.PDF
관련된 링크들
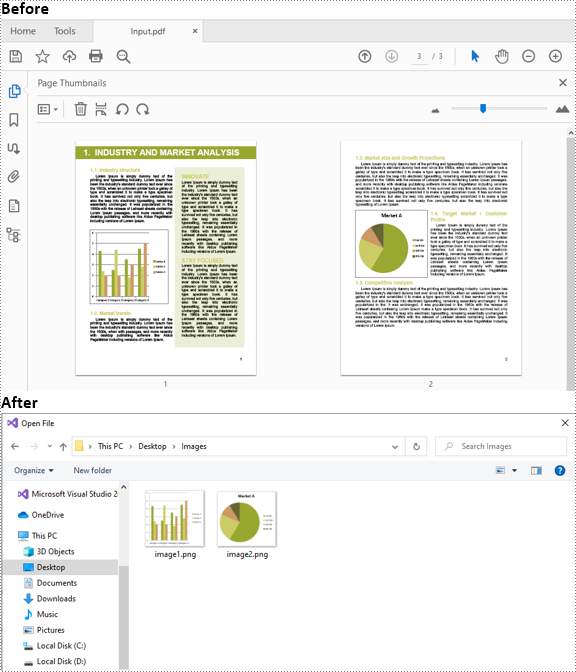
이미지는 쉽게 이해할 수 있는 방식으로 정보를 표시하기 위해 PDF 문서에서 자주 사용됩니다. 어떤 경우에는 PDF 문서에서 이미지를 추출해야 할 수도 있습니다. 예를 들어 프레젠테이션이나 다른 문서에서 PDF 보고서의 차트 이미지를 사용하려는 경우입니다. 이 문서에서는 다음 방법을 보여줍니다 C# 및 VB.NET의 PDF에서 이미지 추출 Spire.PDF for .NET사용합니다.
Spire.PDF for .NET 설치
먼저 Spire.PDF for.NET 패키지에 포함된 DLL 파일을 .NET 프로젝트의 참조로 추가해야 합니다. DLL 파일은 이 링크 에서 다운로드하거나 NuGet을 통해 설치할 수 있습니다.
PM> Install-Package Spire.PDF
C# 및 VB.NET의 PDF에서 이미지 추출
다음은 Spire.PDF for .NET를 사용하여 PDF 문서에서 이미지를 추출하는 주요 단계입니다.
- PdfDocument 개체를 만듭니다.
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 문서를 로드합니다.
- 문서의 모든 페이지를 반복합니다.
- PdfPageBase.ExtractImages() 메서드를 사용하여 각 페이지에서 이미지를 추출하고 지정된 파일 경로에 저장합니다.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
임시 라이센스 신청
생성된 문서에서 평가 메시지를 제거하고 싶거나, 기능 제한을 없애고 싶다면 30일 평가판 라이센스 요청 자신을 위해.
