Tabla de contenido
Instalado a través de NuGet
PM> Install-Package Spire.PDF
enlaces relacionados
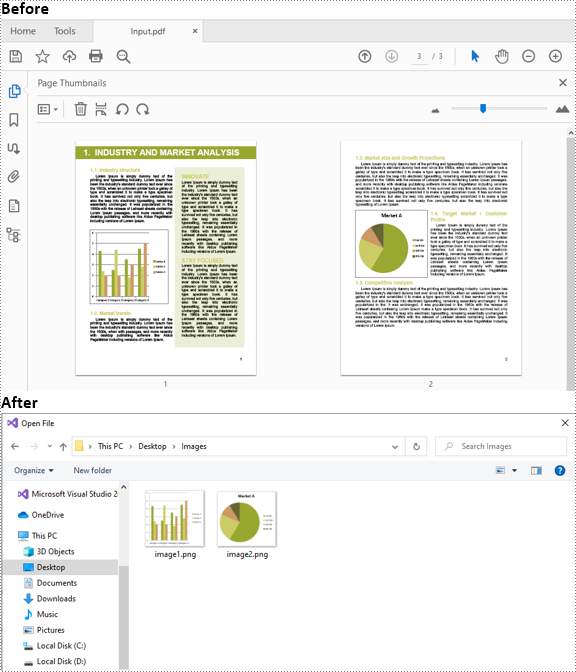
Las imágenes se utilizan a menudo en documentos PDF para presentar información de una manera fácilmente comprensible. En determinados casos, es posible que necesites extraer imágenes de documentos PDF. Por ejemplo, cuando desea utilizar una imagen de gráfico de un informe PDF en una presentación u otro documento. Este artículo demostrará cómo extraer imágenes de PDF en C# y VB.NET usando Spire.PDF for .NET.
Instalar Spire.PDF for .NET
Para empezar, debe agregar los archivos DLL incluidos en el paquete Spire.PDF for .NET como referencias en su proyecto .NET. Los archivos DLL se pueden descargar desde este enlace o instalar a través de NuGet.
PM> Install-Package Spire.PDF
Extraiga imágenes de PDF en C# y VB.NET
Los siguientes son los pasos principales para extraer imágenes de un documento PDF usando Spire.PDF for .NET:
- Cree un objeto PdfDocument.
- Cargue un documento PDF utilizando el método PdfDocument.LoadFromFile().
- Recorre todas las páginas del documento.
- Extraiga imágenes de cada página utilizando el método PdfPageBase.ExtractImages() y guárdelas en una ruta de archivo especificada.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Solicitar una licencia temporal
Si desea eliminar el mensaje de evaluación de los documentos generados o deshacerse de las limitaciones de la función, por favor solicitar una licencia de prueba de 30 días para ti.
