
Detect and Remove Blank Pages from PDF Files in Python
PDF documents may occasionally include blank pages. These pages can affect the reading experience, increase the file size and lead to paper waste during printing. To improve the professionalism and usability of a PDF document, detecting and removing blank pages is an essential step.
This article shows how to accurately detect and remove blank pages—including those that appear empty but actually contain invisible elements—using Python, Spire.PDF for Python, and Pillow.
Install Required Libraries
This tutorial requires two Python libraries:
- Spire.PDF for Python: Used for loading PDFs and detecting/removing blank pages.
- Pillow: A library for image processing that helps detect visually blank pages, which may contain invisible content.
You can easily install both libraries using pip:
pip install Spire.PDF Pillow
Need help installing Spire.PDF? Refer to this guide:
How to Install Spire.PDF for Python on Windows
How to Effectively Detect and Remove Blank Pages from PDF Files in Python
Spire.PDF provides a method called PdfPageBase.IsBlank() to check if a page is completely empty. However, some pages may appear blank but actually contain hidden content like white text, watermarks, or background images. These cannot be reliably detected using the PdfPageBase.IsBlank() method alone.
To ensure accuracy, this tutorial adopts a two-step detection strategy:
- Use the PdfPageBase.IsBlank() method to identify and remove fully blank pages.
- Convert non-blank pages to images and analyze them using Pillow to determine if they are visually blank.
⚠️ Important:
If you don’t use a valid license during the PDF-to-image conversion, an evaluation watermark will appear on the image, potentially affecting the blank page detection.
Contact the E-iceblue sales team to request a temporary license for proper functionality.
Steps to Detect and Remove Blank Pages from PDF in Python
Follow these steps to implement blank page detection and removal in Python:
1. Define a custom is_blank_image() Method
This custom function uses Pillow to check whether the converted image of a PDF page is blank (i.e., if all pixels are white).
2. Load the PDF Document
Load the PDF using the PdfDocument.LoadFromFile() method.
3. Iterate Through Pages
Loop through each page to check if it’s blank using two methods:
- If the PdfPageBase.IsBlank() method returns True, remove the page directly.
- If not, convert the page to an image using the PdfDocument.SaveAsImage() method and analyze it with the custom is_blank_image() method.
4. Save the Result PDF
Finally, save the PDF with blank pages removed using the PdfDocument.SaveToFile() method.
Code Example
- Python
import io
from spire.pdf import PdfDocument
from PIL import Image
# Apply the License Key
License.SetLicenseKey("License-Key")
# Custom function: Check if the image is blank (whether all pixels are white)
def is_blank_image(image):
# Convert to RGB mode and then get the pixels
img = image.convert("RGB")
# Get all pixel points and check if they are all white
white_pixel = (255, 255, 255)
return all(pixel == white_pixel for pixel in img.getdata())
# Load the PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample1111.pdf")
# Iterate through each page in reverse order to avoid index issues when deleting
for i in range(pdf.Pages.Count - 1, -1, -1):
page = pdf.Pages[i]
# Check if the current page is completely blank
if page.IsBlank():
# If it's completely blank, remove it directly from the document
pdf.Pages.RemoveAt(i)
else:
# Convert the current page to an image
with pdf.SaveAsImage(i) as image_data:
image_bytes = image_data.ToArray()
pil_image = Image.open(io.BytesIO(image_bytes))
# Check if the image is blank
if is_blank_image(pil_image):
# If it's a blank image, remove the corresponding page from the document
pdf.Pages.RemoveAt(i)
# Save the resulting PDF
pdf.SaveToFile("RemoveBlankPages.pdf")
pdf.Close()

Frequently Asked Questions (FAQs)
Q1: What is considered a blank page in a PDF file?
A: A blank page may be truly empty or contain hidden elements such as white text, watermarks, or transparent objects. This solution detects both types using a dual-check strategy.
Q2: Can I use this method without a Spire.PDF license?
A: Yes, you can run it without a license. However, during PDF-to-image conversion, an evaluation watermark will be added to the output images, which may affect the accuracy of blank page detection. It's best to request a free temporary license for testing.
Q3: What versions of Python are compatible with Spire.PDF?
A: Spire.PDF for Python supports Python 3.7 and above. Ensure that Pillow is also installed to perform image-based blank page detection.
Q4: Can I modify the script to only detect blank pages without deleting them?
A: Absolutely. Just remove or comment out the pdf.Pages.RemoveAt(i) line and use print() or logging to list detected blank pages for further review.
Conclusion
Removing unnecessary blank pages from PDF files is an important step in optimizing documents for readability, file size, and professional presentation. With the combined power of Spire.PDF for Python and Pillow, developers can precisely identify both completely blank pages and pages that appear empty but contain invisible content. Whether you're generating reports, cleaning scanned files, or preparing documents for print, this Python-based solution ensures clean and efficient PDFs.
Get a Free License
To fully experience the capabilities of Spire.PDF for Python without any evaluation limitations, you can request a free 30-day trial license.
Lock Cells, Rows, and Columns in Excel with JavaScript in React
When working with Excel, you may sometimes need to protect critical data while allowing users to edit other parts of the worksheet. This is especially important for scenarios where certain formulas, headers, or reference values must remain unchanged to ensure data integrity. By locking specific areas, you can prevent accidental modifications, maintain consistency, and control access to key information within the spreadsheet. In this article, you will learn how to lock cells, rows, and columns in Excel in React using JavaScript and the Spire.XLS for JavaScript library.
Install Spire.XLS for JavaScript
To get started with locking cells, rows, and columns in Excel files within a React application, you can either download Spire.XLS for JavaScript from our website or install it via npm with the following command:
npm i spire.xls
After that, copy the "Spire.Xls.Base.js" and "Spire.Xls.Base.wasm" files to the public folder of your project. Additionally, include the required font files to ensure accurate and consistent text rendering.
For more details, refer to the documentation: How to Integrate Spire.XLS for JavaScript in a React Project
Lock Cells in Excel
Spire.XLS for JavaScript offers the Worksheet.Range.get().Style.Locked property, allowing you to protect critical data cells while enabling edits to the rest of the worksheet. The detailed steps are as follows.
- Create a Workbook object using the wasmModule.Workbook.Create() method.
- Load a sample Excel file using the Workbook.LoadFromFile() method.
- Get the first worksheet using the Workbook.Worksheets.get() method.
- Unlock all cells in the used range of the worksheet by setting the Worksheet.Range.Style.Locked property to "false".
- Set text for specific cells using the Worksheet.Range.get().Text property and then lock them by setting the Worksheet.Range.get().Style.Locked property to "true".
- Protect the worksheet with a password using the Worksheet.Protect() method.
- Save the result file using the Workbook.SaveToFile() method.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
// State to hold the loaded WASM module
const [wasmModule, setWasmModule] = useState(null);
// useEffect hook to load the WASM module when the component mounts
useEffect(() => {
const loadWasm = async () => {
try {
// Access the Module and spirexls from the global window object
const { Module, spirexls } = window;
// Set the wasmModule state when the runtime is initialized
Module.onRuntimeInitialized = () => {
setWasmModule(spirexls);
};
} catch (err) {
// Log any errors that occur during loading
console.error('Failed to load WASM module:', err);
}
};
// Create a script element to load the WASM JavaScript file
const script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Xls.Base.js`;
script.onload = loadWasm;
// Append the script to the document body
document.body.appendChild(script);
// Cleanup function to remove the script when the component unmounts
return () => {
document.body.removeChild(script);
};
}, []);
// Function to lock specific cells in Excel
const LockExcelCells = async () => {
if (wasmModule) {
// Load the ARIALUNI.TTF font file into the virtual file system (VFS)
await wasmModule.FetchFileToVFS('ARIALUNI.TTF', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
// Load the input Excel file into the virtual file system (VFS)
const inputFileName = 'Sample.xlsx';
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// Create a new workbook
const workbook = wasmModule.Workbook.Create();
// Load the Excel file from the virtual file system
workbook.LoadFromFile({fileName: inputFileName});
// Get the first worksheet
let sheet = workbook.Worksheets.get(0);
// Unlock all cells in the used range of the worksheet
sheet.Range.Style.Locked = false;
// Lock a specific cell in the worksheet
sheet.Range.get("A1").Text = "Locked";
sheet.Range.get("A1").Style.Locked = true;
// Lock a specific cell range in the worksheet
sheet.Range.get("C1:E3").Text = "Locked";
sheet.Range.get("C1:E3").Style.Locked = true;
// Protect the worksheet with a password
sheet.Protect({password: "123", options: wasmModule.SheetProtectionType.All});
let outputFileName = "LockCells.xlsx";
// Save the resulting file
workbook.SaveToFile({ fileName: outputFileName, version: wasmModule.ExcelVersion.Version2013 });
// Read the saved file and convert it to a Blob object
const modifiedFileArray = wasmModule.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet' });
// Create a URL for the Blob and initiate the download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbooks
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Lock Specific Cells in Excel Using JavaScript in React</h1>
<button onClick={LockExcelCells} disabled={!wasmModule}>
Lock
</button>
</div>
);
}
export default App;
Run the code to launch the React app at localhost:3000. Once it's running, click on the "Lock" button to lock specific cells in the Excel file:
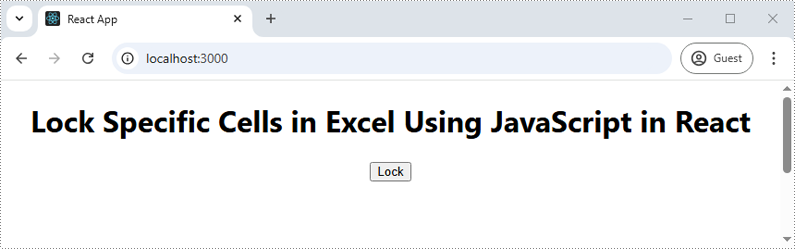
Upon opening the output Excel sheet and attempting to edit the protected cells, a dialog box will appear, notifying you that the cell you're trying to change is on a protected sheet:
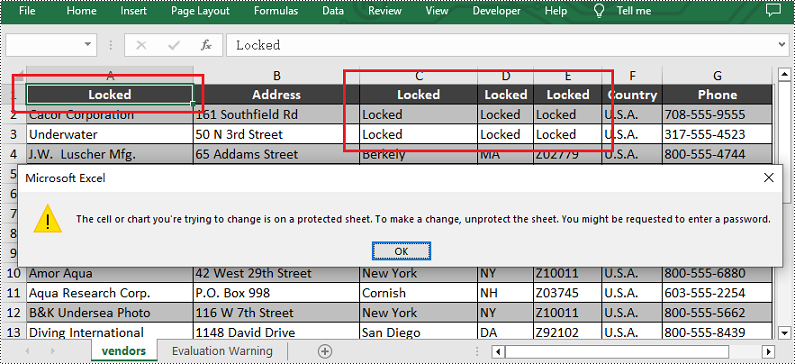
Lock Rows in Excel
If you need to preserve row-based data, such as headers or summaries, you can lock entire rows using the Worksheet.Rows.get().Style.Locked property in Spire.XLS for JavaScript. The detailed steps are as follows.
- Create a Workbook object using the wasmModule.Workbook.Create() method.
- Load a sample Excel file using the Workbook.LoadFromFile() method.
- Get the first worksheet using the Workbook.Worksheets.get() method.
- Unlock all cells in the used range of the worksheet by setting the Worksheet.Range.Style.Locked property to "false".
- Set text for a specific row using the Worksheet.Rows.get().Text property and then lock it by setting the Worksheet.Rows.get().Style.Locked property to "true".
- Protect the worksheet with a password using the Worksheet.Protect() method.
- Save the result file using the Workbook.SaveToFile() method.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
// State to hold the loaded WASM module
const [wasmModule, setWasmModule] = useState(null);
// useEffect hook to load the WASM module when the component mounts
useEffect(() => {
const loadWasm = async () => {
try {
// Access the Module and spirexls from the global window object
const { Module, spirexls } = window;
// Set the wasmModule state when the runtime is initialized
Module.onRuntimeInitialized = () => {
setWasmModule(spirexls);
};
} catch (err) {
// Log any errors that occur during loading
console.error('Failed to load WASM module:', err);
}
};
// Create a script element to load the WASM JavaScript file
const script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Xls.Base.js`;
script.onload = loadWasm;
// Append the script to the document body
document.body.appendChild(script);
// Cleanup function to remove the script when the component unmounts
return () => {
document.body.removeChild(script);
};
}, []);
// Function to lock specific rows in Excel
const LockExcelRows = async () => {
if (wasmModule) {
// Load the ARIALUNI.TTF font file into the virtual file system (VFS)
await wasmModule.FetchFileToVFS('ARIALUNI.TTF', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
// Load the input Excel file into the virtual file system (VFS)
const inputFileName = 'Sample.xlsx';
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// Create a new workbook
const workbook = wasmModule.Workbook.Create();
// Load the Excel file from the virtual file system
workbook.LoadFromFile({fileName: inputFileName});
// Get the first worksheet
let sheet = workbook.Worksheets.get(0);
// Unlock all cells in the used range of the worksheet
sheet.Range.Style.Locked = false;
// Lock the third row in the worksheet
sheet.Rows.get(2).Text = "Locked";
sheet.Rows.get(2).Style.Locked = true;
// Protect the worksheet with a password
sheet.Protect({password: "123", options: wasmModule.SheetProtectionType.All});
let outputFileName = "LockRows.xlsx";
// Save the resulting file
workbook.SaveToFile({ fileName: outputFileName, version: wasmModule.ExcelVersion.Version2013 });
// Read the saved file and convert it to a Blob object
const modifiedFileArray = wasmModule.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet' });
// Create a URL for the Blob and initiate the download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbooks
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Lock Specific Rows in Excel Using JavaScript in React</h1>
<button onClick={LockExcelRows} disabled={!wasmModule}>
Lock
</button>
</div>
);
}
export default App;
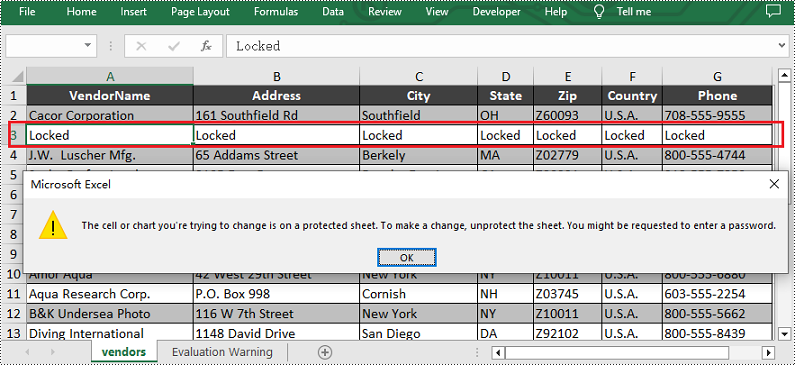
Lock Columns in Excel
To maintain the integrity of key vertical data, such as fixed identifiers or category labels, you can lock entire columns using the Worksheet.Columns.get().Style.Locked property in Spire.XLS for JavaScript. The detailed steps are as follows.
- Create a Workbook object using the wasmModule.Workbook.Create() method.
- Load a sample Excel file using the Workbook.LoadFromFile() method.
- Get the first worksheet using the Workbook.Worksheets.get() method.
- Unlock all cells in the used range of the worksheet by setting the Worksheet.Range.Style.Locked property to "false".
- Set text for a specific column using the Worksheet.Columns.get().Text property and then lock it by setting the Worksheet.Columns.get().Style.Locked property to "true".
- Protect the worksheet with a password using the Worksheet.Protect() method.
- Save the result file using the Workbook.SaveToFile() method.
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
// State to hold the loaded WASM module
const [wasmModule, setWasmModule] = useState(null);
// useEffect hook to load the WASM module when the component mounts
useEffect(() => {
const loadWasm = async () => {
try {
// Access the Module and spirexls from the global window object
const { Module, spirexls } = window;
// Set the wasmModule state when the runtime is initialized
Module.onRuntimeInitialized = () => {
setWasmModule(spirexls);
};
} catch (err) {
// Log any errors that occur during loading
console.error('Failed to load WASM module:', err);
}
};
// Create a script element to load the WASM JavaScript file
const script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Xls.Base.js`;
script.onload = loadWasm;
// Append the script to the document body
document.body.appendChild(script);
// Cleanup function to remove the script when the component unmounts
return () => {
document.body.removeChild(script);
};
}, []);
// Function to lock specific columns in Excel
const LockExcelColumns = async () => {
if (wasmModule) {
// Load the ARIALUNI.TTF font file into the virtual file system (VFS)
await wasmModule.FetchFileToVFS('ARIALUNI.TTF', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
// Load the input Excel file into the virtual file system (VFS)
const inputFileName = 'Sample.xlsx';
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// Create a new workbook
const workbook = wasmModule.Workbook.Create();
// Load the Excel file from the virtual file system
workbook.LoadFromFile({fileName: inputFileName});
// Get the first worksheet
let sheet = workbook.Worksheets.get(0);
// Unlock all cells in the used range of the worksheet
sheet.Range.Style.Locked = false;
// Lock the fourth column in the worksheet
sheet.Columns.get(3).Text = "Locked";
sheet.Columns.get(3).Style.Locked = true;
// Protect the worksheet with a password
sheet.Protect({password: "123", options: wasmModule.SheetProtectionType.All});
let outputFileName = "LockColumns.xlsx";
// Save the resulting file
workbook.SaveToFile({ fileName: outputFileName, version: wasmModule.ExcelVersion.Version2013 });
// Read the saved file and convert it to a Blob object
const modifiedFileArray = wasmModule.FS.readFile(outputFileName);
const modifiedFile = new Blob([modifiedFileArray], { type: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet' });
// Create a URL for the Blob and initiate the download
const url = URL.createObjectURL(modifiedFile);
const a = document.createElement('a');
a.href = url;
a.download = outputFileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
// Clean up resources used by the workbooks
workbook.Dispose();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Lock Specific Columns in Excel Using JavaScript in React</h1>
<button onClick={LockExcelColumns} disabled={!wasmModule}>
Lock
</button>
</div>
);
}
export default App;
Get a Free License
To fully experience the capabilities of Spire.XLS for JavaScript without any evaluation limitations, you can request a free 30-day trial license.
Spire.Presentation for Java 10.2.2 enhances the conversion from PowerPoint to images
We are delighted to announce the release of Spire.Presentation for Java 10.2.2. This version enhances the conversion from PowerPoint documents to images. Moreover, some known issues are fixed successfully in this version, such as the issue that it threw "Value cannot be null" when saving a PowerPoint document. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREPPT-2669 | Fixes the issue that the shadow effect of text was lost when converting PowerPoint to images. |
| Bug | SPIREPPT-2717 | Optimizes the function of adding annotations for specific text. |
| Bug | SPIREPPT-2718 | Fixes the issue that it threw "StringIndexOutOfBoundsException" when adding annotations for specific text. |
| Bug | SPIREPPT-2719 | Fixes the issue that the effect of converting PowerPoint to images was incorrect. |
| Bug | SPIREPPT-2722 | Fixes the issue that it threw "Value cannot be null" when saving a PowerPoint document. |
Spire.Doc 13.2.3 optimizes the time and resource consumption when converting Word to PDF
We're pleased to announce the release of Spire.Doc 13.2.3. This version optimizes the time and resource consumption when converting Word to PDF, and also adds new interfaces for reading and writing chart titles, data labels, axis, legends, data tables and other chart attributes. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Adds new interfaces for reading and writing chart titles, chart data labels, chart axis, chart legends, chart data tables and other attributes.
|
| New feature | - | Namespace changes:
Spire.Doc.Formatting.RowFormat.TablePositioning->Spire.Doc.Formatting.TablePositioning Spire.Doc.Printing.PagesPreSheet->Spire.Doc.Printing.PagesPerSheet |
| New feature | - | Optimizes the time and resource consumption when converting Word to PDF, especially when working with large files or complex layouts. |
Spire.XLS for Java 15.2.1 enhances conversions from Excel to images and PDF
We are excited to announce the release of the Spire.XLS for Java 15.2.1. The latest version enhances conversions from Excel to images and PDF. Besides, this update fixes the issue that the program threw a "NullPointerException" when loading an XLSX document. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREXLS-5575 | Fixes the issue that the program threw a "NullPointerException" when loading an XLSX document. |
| Bug | SPIREXLS-5668 | Fixes the issue that incorrect colors existed when converting Excel to images. |
| Bug | SPIREXLS-5685 | Fixes the issue that incomplete content displayed when converting Excel to PDF. |
Marker Designer
Data
| Name | Capital | Continent | Area | Population |
| Argentina | Buenos Aires | South America | 2777815 | 32300003 |
| Bolivia | La Paz | South America | 1098575 | 7300000 |
| Brazil | Brasilia | South America | 8511196 | 150400000 |
| Canada | Ottawa | North America | 9976147 | 26500000 |
| Chile | Santiago | South America | 756943 | 13200000 |
| Colombia | Bagota | South America | 1138907 | 33000000 |
| Cuba | Havana | North America | 114524 | 10600000 |
| Ecuador | Quito | South America | 455502 | 10600000 |
| El Salvador | San Salvador | North America | 20865 | 5300000 |
| Guyana | Georgetown | South America | 214969 | 800000 |
Option
| Excel Version: |
- Demo
- Java
- C# source
import com.spire.data.table.DataTable;
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class MarkerDesignerDemo {
public void markerDesignerDemo(String filePath, String dataFilePath, String resultFilePath){
Workbook data_book = new Workbook();
data_book.loadFromFile(dataFilePath);
DataTable table = data_book.getWorksheets().get(0).exportDataTable();
Workbook workbook = new Workbook();
workbook.loadFromFile(filePath);
Worksheet sheet = workbook.getWorksheets().get(0);
Worksheet sheet2 = workbook.getWorksheets().get(1);
sheet.setName( "Result");
sheet2.setName("DataSource");
sheet2.insertDataTable(table,true,1,1);
workbook.getMarkerDesigner().addParameter("Variable1", 1234.5678);
workbook.getMarkerDesigner().addDataTable("Country", table);
workbook.getMarkerDesigner().apply();
sheet.getAllocatedRange().autoFitRows();
sheet.getAllocatedRange().autoFitColumns();
workbook.saveToFile(resultFilePath, FileFormat.Version2013);
}
}
Calculate Formulas
Mathematic Functions:
| Calculate symbol : | Calculate Data: |
Logic Function:
| Calculate symbol : | Calculate Data: |
Simple Expression:
| Calculate symbol : | Calculate Data: |
MID Functions:
| Text : | Start Number: |
| Number Charts: |
Option:
| Excel Version: |
- Demo
- Java
- C# source
import com.spire.xls.*;
public class CalculateFormulaDemo {
public void CalculateFormulas(String resultFile){
Workbook workbook = new Workbook();
Worksheet sheet = workbook.getWorksheets().get(0);
Calculate(workbook, sheet);
workbook.saveToFile(resultFile, ExcelVersion.Version2010);
}
public void Calculate(Workbook workbook, Worksheet worksheet){
int currentRow = 1;
String currentFormula = null;
Object formulaResult = null;
String value = null;
// Set width respectively of Column A ,Column B,Column C
worksheet.setColumnWidth(1,32);
worksheet.setColumnWidth(2,16);
worksheet.setColumnWidth(3,16);
//Set the value of Cell A1
worksheet.getRange().get(currentRow++, 1).setValue("Examples of formulas :");
// Set the value of Cell A2
worksheet.getRange().get(++currentRow, 1).setValue("Test data:");
// Set the style of Cell A1
CellRange range = worksheet.getRange().get("A1");
range.getStyle().getFont().isBold(true);
range.getStyle().setFillPattern(ExcelPatternType.Solid);
range.getStyle().setKnownColor(ExcelColors.LightGreen1);
range.getStyle().getBorders().getByBordersLineType(BordersLineType.EdgeBottom).setLineStyle(LineStyleType.Medium);
// Additive operation of mutiple cells
worksheet.getRange().get(currentRow, 2).setNumberValue(7.3);
worksheet.getRange().get(currentRow, 3).setNumberValue(5);
worksheet.getRange().get(currentRow, 4).setNumberValue(8.2);
worksheet.getRange().get(currentRow, 5).setNumberValue(4);
worksheet.getRange().get(currentRow, 6).setNumberValue(3);
worksheet.getRange().get(currentRow, 7).setNumberValue(11.3);
// Create arithmetic expression string about cells
currentFormula = "=Sheet1!$B$3 + Sheet1!$C$3+Sheet1!$D$3+Sheet1!$E$3+Sheet1!$F$3+Sheet1!$G$3";
//Caculate arithmetic expression about cells
formulaResult = workbook.calculateFormulaValue(currentFormula);
value = formulaResult.toString();
worksheet.getRange().get(currentRow,2).setValue(value);
// Set the value and format of two head cell
worksheet.getRange().get(currentRow,1).setValue("Formulas");
worksheet.getRange().get(currentRow,2).setValue("Results");
worksheet.getRange().get(currentRow,2).setHorizontalAlignment(HorizontalAlignType.Right);
range = worksheet.getRange().get(currentRow,1,currentRow,2);
range.getStyle().getFont().isBold(true);
range.getStyle().setKnownColor(ExcelColors.LightGreen1);
range.getStyle().setFillPattern(ExcelPatternType.Solid);
range.getStyle().getBorders().getByBordersLineType(BordersLineType.EdgeBottom).setLineStyle(LineStyleType.Medium);
// Expression caculation
// Create arithmetic tables enclosed type string
currentFormula = "=33*3/4-2+10";
worksheet.getRange().get(++currentRow,1).setText(currentFormula);
// Caculate arithmetic expression
formulaResult = workbook.calculateFormulaValue(currentFormula);
value = formulaResult.toString();
worksheet.getRange().get(currentRow,2).setValue(value);
//Absolute value function
// Create abosolute value function string
currentFormula = "=ABS(-1.21)";
worksheet.getRange().get(++currentRow,1).setText(currentFormula);
// Caculate abosulte value function
formulaResult = workbook.calculateFormulaValue(currentFormula);
value = formulaResult.toString();
worksheet.getRange().get(currentRow,2).setValue(value);
// Sum function
// Create sum function string
currentFormula = "=SUM(18,29)";
worksheet.getRange().get(++currentRow,1).setText(currentFormula);
// Caculate sum function
formulaResult = workbook.calculateFormulaValue(currentFormula);
value = formulaResult.toString();
worksheet.getRange().get(currentRow,2).setValue(value);
//NOT function
// Create NOT function string
currentFormula = "=NOT(true)";
worksheet.getRange().get(++currentRow,1).setText(currentFormula);
//Caculate NOT function
formulaResult = workbook.calculateFormulaValue(currentFormula);
value = formulaResult.toString();
worksheet.getRange().get(currentRow,2).setValue(value);
worksheet.getRange().get(currentRow,2).setHorizontalAlignment(HorizontalAlignType.Right);
//String Manipulation function
//Get the substring
// Build substring function
currentFormula = "=MID(\"world\",4,2)";
worksheet.getRange().get(++currentRow,1).setText(currentFormula);
//Caculate substring function
formulaResult = workbook.calculateFormulaValue(currentFormula);
value = formulaResult.toString();
worksheet.getRange().get(currentRow,2).setValue(value);
worksheet.getRange().get(currentRow,2).setHorizontalAlignment(HorizontalAlignType.Right);
// Random function
// Create random function string.
currentFormula = "=RAND()";
worksheet.getRange().get(++currentRow,1).setText(currentFormula);
//Caculate random function
formulaResult = workbook.calculateFormulaValue(currentFormula);
value = formulaResult.toString();
worksheet.getRange().get(currentRow,2).setValue(value);
}
}
Charts
- Demo
- Java
- C# source
import com.spire.xls.*;
public class ChartDemo {
public void chartDemo(String excelFile, ExcelChartType chartType, String resultFileName){
Workbook workbook = new Workbook();
workbook.loadFromFile(excelFile);
Worksheet worksheet = workbook.getWorksheets().get(0);
setChart(worksheet,chartType);
sheetStyle(workbook,worksheet);
workbook.saveToFile(resultFileName+".xlsx",FileFormat.Version2013);
}
private void setChart(Worksheet sheet, ExcelChartType chartType){
sheet.setName("Chart data");
sheet.setGridLinesVisible(false);
//Add a new chart worsheet to workbook
Chart chart = sheet.getCharts().add();
chart.setChartType(chartType);
//Set region of chart data
chart.setDataRange(sheet.getCellRange("A1:C7"));
chart.setSeriesDataFromRange(false);
//Set position of chart
chart.setLeftColumn(4);
chart.setTopRow(2);
chart.setRightColumn(12);
chart.setBottomRow(22);
//Chart title
chart.setChartTitle("Sales market by country");
chart.getChartTitleArea().isBold(true);
chart.getChartTitleArea().setSize(12);
chart.getPrimarySerieAxis().setTitle("Country");
chart.getPrimarySerieAxis().getFont().isBold(true);
chart.getPrimarySerieAxis().getTitleArea().isBold(true);
chart.getPrimarySerieAxis().setTitle("Sales(in Dollars)");
chart.getPrimarySerieAxis().hasMajorGridLines(false);
chart.getPrimarySerieAxis().getTitleArea().setTextRotationAngle(90);
chart.getPrimarySerieAxis().setMinValue(1000);
chart.getPrimarySerieAxis().getTitleArea().isBold(true);
chart.getPlotArea().getFill().setFillType(ShapeFillType.SolidColor);
chart.getPlotArea().getFill().setForeKnownColor(ExcelColors.White);
for (int i = 0; i < chart.getSeries().getCount(); i++){
chart.getSeries().get(i).getFormat().getOptions().isVaryColor(true);
chart.getSeries().get(i).getDataPoints().getDefaultDataPoint().getDataLabels().hasValue(true);
}
chart.getLegend().setPosition(LegendPositionType.Top);
}
public static void sheetStyle(Workbook workbook, Worksheet sheet){
CellStyle oddStyle = workbook.getStyles().addStyle("oddStyle");
oddStyle.getBorders().getByBordersLineType(BordersLineType.EdgeLeft).setLineStyle(LineStyleType.Thin);
oddStyle.getBorders().getByBordersLineType(BordersLineType.EdgeTop).setLineStyle(LineStyleType.Thin);
oddStyle.getBorders().getByBordersLineType(BordersLineType.EdgeBottom).setLineStyle(LineStyleType.Thin);
oddStyle.setKnownColor(ExcelColors.LightGreen1);
CellStyle evenStyle = workbook.getStyles().addStyle("evenStyle");
evenStyle.getBorders().getByBordersLineType(BordersLineType.EdgeLeft).setLineStyle(LineStyleType.Thin);
evenStyle.getBorders().getByBordersLineType(BordersLineType.EdgeRight).setLineStyle(LineStyleType.Thin);
evenStyle.getBorders().getByBordersLineType(BordersLineType.EdgeTop).setLineStyle(LineStyleType.Thin);
evenStyle.getBorders().getByBordersLineType(BordersLineType.EdgeBottom).setLineStyle(LineStyleType.Thin);
evenStyle.setKnownColor(ExcelColors.LightTurquoise);
for (int i = 0; i < sheet.getAllocatedRange().getRows().length; i++) {
CellRange[] ranges = sheet.getAllocatedRange().getRows();
if (ranges[i].getRow() != 0){
if (ranges[i].getRow() % 2 == 0)
{
ranges[i].setCellStyleName(evenStyle.getName());
}
else
{
ranges[i].setCellStyleName(oddStyle.getName());
}
}
}
//Sets header style
CellStyle styleHeader = workbook.getStyles().addStyle("headerStyle");
styleHeader.getBorders().getByBordersLineType(BordersLineType.EdgeLeft).setLineStyle(LineStyleType.Thin);
styleHeader.getBorders().getByBordersLineType(BordersLineType.EdgeRight).setLineStyle(LineStyleType.Thin);
styleHeader.getBorders().getByBordersLineType(BordersLineType.EdgeTop).setLineStyle(LineStyleType.Thin);
styleHeader.getBorders().getByBordersLineType(BordersLineType.EdgeBottom).setLineStyle(LineStyleType.Thin);
styleHeader.setVerticalAlignment(VerticalAlignType.Center);
styleHeader.setKnownColor(ExcelColors.Green);
styleHeader.getFont().setKnownColor(ExcelColors.White);
styleHeader.getFont().isBold(true);
styleHeader.setHorizontalAlignment(HorizontalAlignType.Center);
for (int i = 0; i < sheet.getRows()[0].getCount(); i++) {
CellRange range = sheet.getRows()[0];
range.setCellStyleName(styleHeader.getName());
}
sheet.getColumns()[sheet.getAllocatedRange().getLastColumn() -1].getStyle().setNumberFormat("\"$\"#,##0");
sheet.getColumns()[sheet.getAllocatedRange().getLastColumn() -2].getStyle().setNumberFormat("\"$\"#,##0");
sheet.getRows()[0].getStyle().setNumberFormat("General");
sheet.getAllocatedRange().autoFitColumns();
sheet.getAllocatedRange().autoFitRows();
sheet.getRows()[0].setRowHeight(20);
}
}
Conversion
Upload
 Click here to browse files.
Click here to browse files.Convert to
- Demo
- Java
- C# source
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
import com.spire.xls.core.spreadsheet.HTMLOptions;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertDemo {
public void convertDemo(String filePath, String convertTo, String resultFileName) throws IOException {
Workbook workbook = new Workbook();
workbook.loadFromFile(filePath);
ConvertFormat(workbook,convertTo,resultFileName);
}
private void ConvertFormat(Workbook workbook, String convertTo, String resultFileName) throws IOException {
switch (convertTo){
case "PDF":
workbook.getConverterSetting().setSheetFitToPage(true);
workbook.saveToFile(resultFileName + ".pdf", FileFormat.PDF);
break;
case "IMAGE":
BufferedImage[] images = (BufferedImage[]) new Image[workbook.getWorksheets().size()];
for (int i = 0; i < workbook.getWorksheets().size();i++){
images[i] = workbook.saveAsImage(i,300,300);
}
if (images != null && images.length > 0){
if (images.length == 1){
ImageIO.write(images[0],".PNG", new File(resultFileName+".png"));
}
}else {
for (int j = 0; j < images.length;j++){
String fileName = String.format("image-{0}.png",j);
ImageIO.write(images[j],".PNG",new File(fileName));
}
}
break;
case "HTML":
for (int i = 0; i < workbook.getWorksheets().size(); i++) {
HTMLOptions options = new HTMLOptions();
options.setImageEmbedded(true);
String htmlPath = String.format(resultFileName+"-{0}.html",i++);
workbook.getWorksheets().get(i).saveToHtml(htmlPath,options);
}
break;
case "TIFF":
workbook.saveToTiff(resultFileName+".tiff");
break;
case "XPS":
workbook.saveToFile(resultFileName+".xps",FileFormat.XPS);
break;
}
}
}