

Reading Word documents in Python is a common task for developers who work with document automation, data extraction, or content processing. Whether you're working with modern .docx files or legacy .doc formats, being able to open, read, and extract content like text, tables, and images from Word files can save time and streamline your workflows.
While many Python libraries support .docx, reading .doc files—the older binary format—can be more challenging. Fortunately, there are reliable methods for handling both file types in Python.
In this tutorial, you'll learn how to read Word documents (.doc and .docx) in Python using the Spire.Doc for Python library. We'll walk through practical code examples to extract text, images, tables, comments, lists, and even metadata. Whether you're building an automation script or a full document parser, this guide will help you work with Word files effectively across formats.
Table of Contents
- Why Read Word Documents Programmatically in Python?
- Install the Library for Parsing Word Documents in Python
- Read Text from Word DOC or DOCX in Python
- Read Specific Elements from a Word Document in Python
- Conclusion
- FAQs
Why Read Word Documents Programmatically in Python?
Reading Word files using Python allows for powerful automation of content processing tasks, such as:
- Extracting data from reports, resumes, or forms.
- Parsing and organizing content into databases or dashboards.
- Converting or analyzing large volumes of Word documents.
- Integrating document reading into web apps, APIs, or back-end systems.
Programmatic reading eliminates manual copy-paste workflows and ensures consistent and scalable results.
Install the Library for Parsing Word Documents in Python
To read .docx and .doc files in Python, you need a library that can handle both formats. Spire.Doc for Python is a versatile and easy-to-use library that lets you extract text, images, tables, comments, lists, and metadata from Word documents. It runs independently of Microsoft Word, so Office installation is not required.
To get started, install Spire.Doc easily with pip:
pip install Spire.Doc
Read Text from Word DOC or DOCX in Python
Extracting text from Word documents is a common requirement in many automation and data processing tasks. Depending on your needs, you might want to read the entire content or focus on specific sections or paragraphs. This section covers both approaches.
Get Text from Entire Document
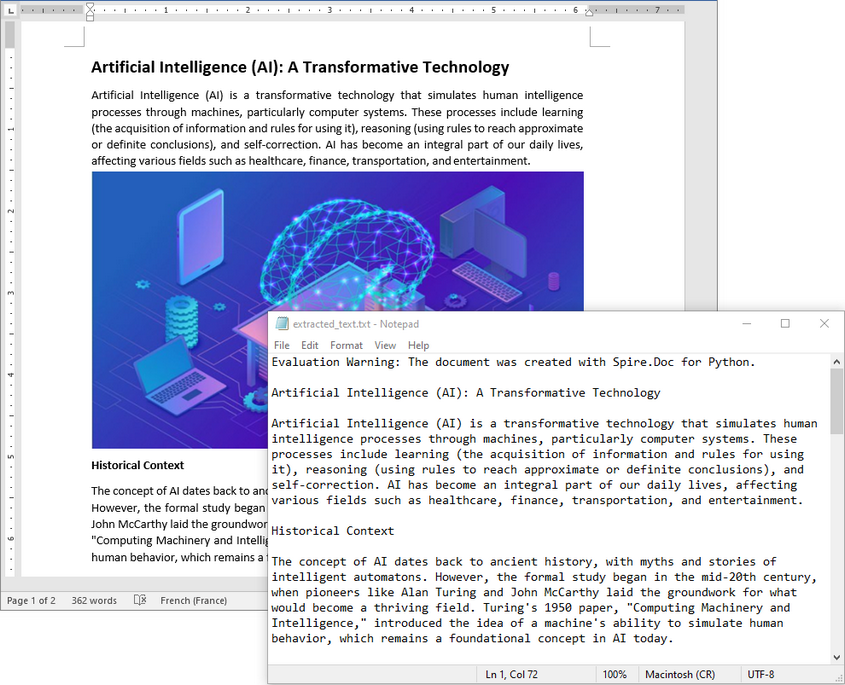
When you need to retrieve the complete textual content of a Word document — for tasks like full-text indexing or simple content export — you can use the Document.GetText() method. The following example demonstrates how to load a Word file, extract all text, and save it to a file:
from spire.doc import *
# Load the Word .docx or .doc file
document = Document()
document.LoadFromFile("sample.docx")
# Get all text
text = document.GetText()
# Save to a text file
with open("extracted_text.txt", "w", encoding="utf-8") as file:
file.write(text)
document.Close()
Get Text from Specific Section or Paragraph
Many documents, such as reports or contracts, are organized into multiple sections. Extracting text from a specific section enables targeted processing when you need content from a particular part only. By iterating through the paragraphs of the selected section, you can isolate the relevant text:
from spire.doc import *
# Load the Word .docx or .doc file
document = Document()
document.LoadFromFile("sample.docx")
# Access the desired section
section = document.Sections[0]
# Get text from the paragraphs of the section
with open("paragraphs_output.txt", "w", encoding="utf-8") as file:
for paragraph in section.Paragraphs:
file.write(paragraph.Text + "\n")
document.Close()
Read Specific Elements from a Word Document in Python
Beyond plain text, Word documents often include rich content like images, tables, comments, lists, metadata, and more. These elements can easily be programmatically accessed and extracted.
Extract Images
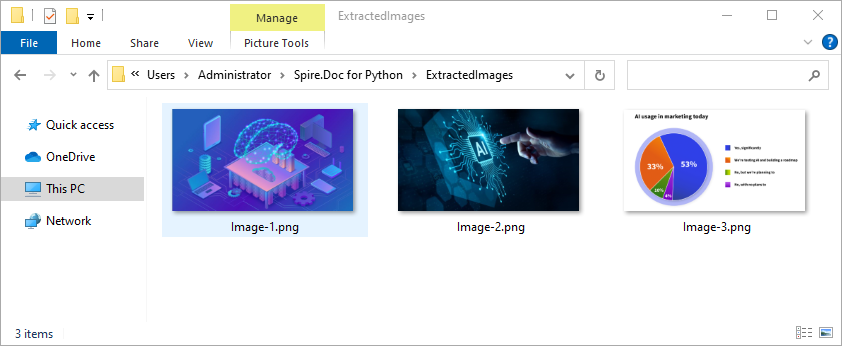
Word documents often embed images like logos, charts, or illustrations. To extract these images:
- Traverse each paragraph and its child objects.
- Identify objects of type DocPicture.
- Retrieve the image bytes and save them as separate files.
from spire.doc import *
import os
# Load the Word document
document = Document()
document.LoadFromFile("sample.docx")
# Create a list to store image byte data
images = []
# Iterate over sections
for s in range(document.Sections.Count):
section = document.Sections[s]
# Iterate over paragraphs
for p in range(section.Paragraphs.Count):
paragraph = section.Paragraphs[p]
# Iterate over child objects
for c in range(paragraph.ChildObjects.Count):
obj = paragraph.ChildObjects[c]
# Extract image data
if isinstance(obj, DocPicture):
picture = obj
# Get image bytes
dataBytes = picture.ImageBytes
# Store in the list
images.append(dataBytes)
# Create the output directory if it doesn't exist
output_folder = "ExtractedImages"
os.makedirs(output_folder, exist_ok=True)
# Save each image from byte data
for i, item in enumerate(images):
fileName = f"Image-{i+1}.png"
with open(os.path.join(output_folder, fileName), 'wb') as imageFile:
imageFile.write(item)
# Close the document
document.Close()
Get Table Data
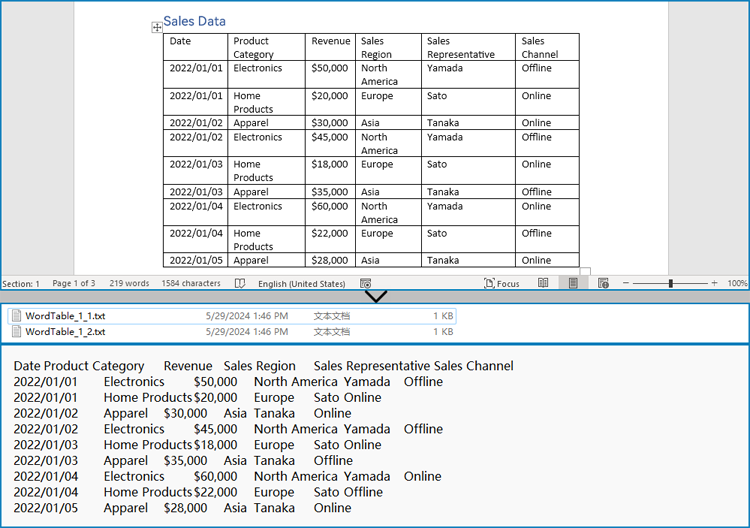
Tables organize data such as schedules, financial records, or lists. To extract all tables and their content:
- Loop through tables in each section.
- Loop through rows and cells in each table.
- Traverse over each cell’s paragraphs and combine their texts.
- Save the extracted table data in a readable text format.
from spire.doc import *
import os
# Load the Word document
document = Document()
document.LoadFromFile("tables.docx")
# Ensure output directory exists
output_dir = "output/Tables"
os.makedirs(output_dir, exist_ok=True)
# Loop through each section
for s in range(document.Sections.Count):
section = document.Sections[s]
tables = section.Tables
# Loop through each table in the section
for i in range(tables.Count):
table = tables[i]
table_data = ""
# Loop through each row
for j in range(table.Rows.Count):
row = table.Rows[j]
# Loop through each cell
for k in range(row.Cells.Count):
cell = row.Cells[k]
cell_text = ""
# Combine text from all paragraphs in the cell
for p in range(cell.Paragraphs.Count):
para_text = cell.Paragraphs[p].Text
cell_text += para_text + " "
table_data += cell_text.strip()
# Add tab between cells (except after the last cell)
if k < row.Cells.Count - 1:
table_data += "\t"
table_data += "\n"
# Save the table data to a separate text file
output_path = os.path.join(output_dir, f"WordTable_{s+1}_{i+1}.txt")
with open(output_path, "w", encoding="utf-8") as output_file:
output_file.write(table_data)
# Close the document
document.Close()
Read Lists
Lists are frequently used to structure content in Word documents. This example identifies paragraphs formatted as list items and writes the list marker together with the text to a file.
from spire.doc import *
# Load the Word document
document = Document()
document.LoadFromFile("sample.docx")
# Open a text file for writing the list items
with open("list_items.txt", "w", encoding="utf-8") as output_file:
# Iterate over sections
for s in range(document.Sections.Count):
section = document.Sections[s]
# Iterate over paragraphs
for p in range(section.Paragraphs.Count):
paragraph = section.Paragraphs[p]
# Check if the paragraph is a list
if paragraph.ListFormat.ListType != ListType.NoList:
# Write the combined list marker and paragraph text to file
output_file.write(paragraph.ListText + paragraph.Text + "\n")
# Close the document
document.Close()
Extract Comments
Comments are typically used for collaboration and feedback in Word documents. This code retrieves all comments, including the author and content, and saves them to a file with clear formatting for later review or audit.
from spire.doc import *
# Load the Word .docx or .doc document
document = Document()
document.LoadFromFile("sample.docx")
# Open a text file to save comments
with open("extracted_comments.txt", "w", encoding="utf-8") as output_file:
# Iterate over the comments
for i in range(document.Comments.Count):
comment = document.Comments[i]
# Write comment header with comment number
output_file.write(f"Comment {i + 1}:\n")
# Write comment author
output_file.write(f"Author: {comment.Format.Author}\n")
# Extract full comment text by concatenating all paragraph texts
comment_text = ""
for j in range(comment.Body.Paragraphs.Count):
paragraph = comment.Body.Paragraphs[j]
comment_text += paragraph.Text + "\n"
# Write the comment text
output_file.write(f"Content: {comment_text.strip()}\n")
# Add a blank line between comments
output_file.write("\n")
# Close the document
document.Close()
Retrieve Metadata (Document Properties)
Metadata provides information about the document such as author, title, creation date, and modification date. This code extracts common built-in properties for reporting or cataloging purposes.
from spire.doc import *
# Load the Word .docx or .doc document
document = Document()
document.LoadFromFile("sample.docx")
# Get the built-in document properties
props = document.BuiltinDocumentProperties
# Open a text file to write the properties
with open("document_properties.txt", "w", encoding="utf-8") as output_file:
output_file.write(f"Title: {props.Title}\n")
output_file.write(f"Author: {props.Author}\n")
output_file.write(f"Subject: {props.Subject}\n")
output_file.write(f"Created: {props.CreateDate}\n")
output_file.write(f"Modified: {props.LastSaveDate}\n")
# Close the document
document.Close()
Conclusion
Reading both .doc and .docx Word documents in Python is fully achievable with the right tools. With Spire.Doc, you can:
- Read text from the entire document, any section or paragraph.
- Extract tables and process structured data.
- Export images embedded in the document.
- Extract comments and lists from the document.
- Work with both modern and legacy Word formats without extra effort.
Try Spire.Doc today to simplify your Word document parsing workflows in Python!
FAQs
Q1: How do I read a Word DOC or DOCX file in Python?
A1: Use a Python library like Spire.Doc to load and extract content from Word files.
Q2: Do I need Microsoft Word installed to use Spire.Doc?
A2: No, it works without any Office installation.
Q3: Can I generate or update Word documents with Spire.Doc?
A3: Yes, Spire.Doc not only allows you to read and extract content from Word documents but also provides powerful features to create, modify, and save Word files programmatically.
Get a Free License
To fully experience the capabilities of Spire.Doc for Python without any evaluation limitations, you can request a free 30-day trial license.
