
Comments in Word documents often hold valuable information, such as feedback, suggestions, and notes. Unfortunately, editors like Microsoft Word lack a built-in feature for batch-extracting comments, leaving users to rely on cumbersome methods like copying and pasting or using VBA macros. To simplify this process, this article demonstrates how to use Java to extract comments from Word documents with Spire.Doc for Java. With a streamlined approach, you can easily retrieve all comment text and images in a single operation—quickly, efficiently, and error-free. Let's explore how it’s done.
- Extract Comments Text from Word Documents in Java
- Extract Comment Images from Word Documents in Java
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.4.1</version>
</dependency>
</dependencies>
Extract Comments Text from Word Documents in Java
Using Java to extract all comment text is easy and quick. Firstly, loop through all comments in the Word file and get the current comment using the Document.getComments().get() method offered by Spire.Doc for Java. Then iterate through all paragraphs in the comment body and get the current paragraph. Finally, text from comment paragraphs will be extracted using the Paragraph.getText() method. Let's dive into the detailed steps.
Steps to extract comment text from Word files:
- Create an object of Document class.
- Load a Word document from files using Document.loadFromFile() method.
- Iterate through all comments in the Word file.
- Get the current comment with Document.getComments().get() method.
- Loop through paragraphs in the comment and access the current paragraph through Comment.getBody().getParagraphs().get() method.
- Extract the text of the paragraphs in comments by calling Paragraph.getText() method.
- Get the current comment with Document.getComments().get() method.
- Save the extracted comments.
The code example below demonstrates how to extract all comment text from a Word document:
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import java.io.*;
public class ExtractComments {
public static void main(String[] args) throws IOException {
// Create a new Document instance
Document doc = new Document();
// Load the document from the specified input file
doc.loadFromFile("/comments.docx");
// Iterate over each comment in the document
for (int i = 0; i < doc.getComments().getCount(); i++) {
// Get the comment at the current index
Comment comment = doc.getComments().get(i);
// Iterate over each paragraph in the comment's body
for (int j = 0; j < comment.getBody().getParagraphs().getCount(); j++) {
// Get the paragraph at the current index
Paragraph para = comment.getBody().getParagraphs().get(j);
// Get the text of the paragraph and append a line break
String result = para.getText() + "\r\n";
// Write the extracted comment a text file
writeStringToTxt(result, "/commenttext.txt");
}
}
// Dispose of the document resources
doc.dispose();
}
// Custom method to write a string to a text file
public static void writeStringToTxt(String content, String txtFileName) throws IOException {
FileWriter fWriter = new FileWriter(txtFileName, true);
try {
// Write the content to the text file
fWriter.write(content);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
// Flush and close the FileWriter
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
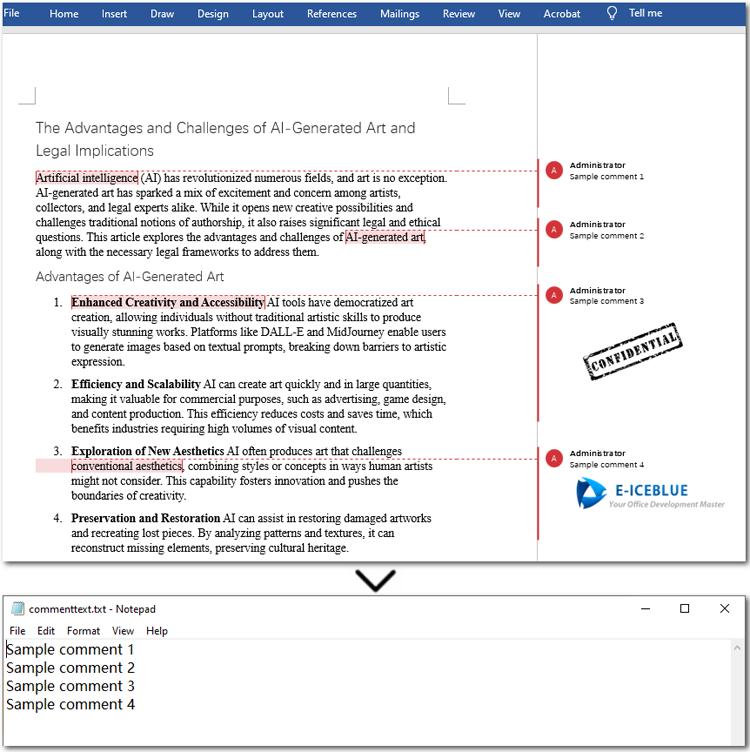
Extract Comments Images from Word Documents with Java
Sometimes, comments in a document may contain not only text but also images. With the methods provided by Spire.Doc for Java, you can easily extract all images from comments in bulk. The process is similar to extracting text: you need to iterate through each comment, the paragraphs in the comment body, and the child objects of each paragraph. Then, check if the object is a DocPicture. If it is, use the DocPicture.getImageBytes() method to extract the image.
Steps to extract comment images from Word documents:
- Create an instance of Document class.
- Specify the file path to load a source Word file through Document.loadFromFile() method.
- Create a list to store extracted data.
- Loop through comments in the Word file and get the current comment using Document.getComments().get() method.
- Loop through all paragraphs in a comment, and get the current paragraph with Comment.getBody().getParagraphs().get() method.
- Iterate through each child object of a paragraph, and access a child object through Paragraph.getChildObjects().get() method.
- Check if the child object is DocPicture, if it is, get the image data using DocPicture.getImageBytes() method.
- Loop through all paragraphs in a comment, and get the current paragraph with Comment.getBody().getParagraphs().get() method.
- Add the image data to the list and save it as image files.
Here is the code example of extracting all comment images from a Word file:
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import java.io.*;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
public class ExtractCommentImages {
public static void main(String[] args) {
// Create an object of the Document class
Document document = new Document();
// Load a Word document with comments
document.loadFromFile("/comments.docx");
// Create a list to store the extracted image data
List<byte[]> images = new ArrayList<>();
// Loop through the comments in the document
for (int i = 0; i < document.getComments().getCount(); i++) {
Comment comment = document.getComments().get(i);
// Iterate through the paragraphs in the comment body
for (int j = 0; j < comment.getBody().getParagraphs().getCount(); j++) {
Paragraph paragraph = comment.getBody().getParagraphs().get(j);
// Loop through the child objects in the paragraph
for (int k = 0; k < paragraph.getChildObjects().getCount(); k++) {
DocumentObject obj = paragraph.getChildObjects().get(k);
// Check if it is a picture
if (obj instanceof DocPicture) {
DocPicture picture = (DocPicture) obj;
// Get the image date and add it to the list
images.add(picture.getImageBytes());
}
}
}
}
// Specify the output file path
String outputDir = "/comment_images/";
new File(outputDir).mkdirs();
// Save the image data as image files
for (int i = 0; i < images.size(); i++) {
String fileName = String.format("comment-image-%d.png", i);
Path filePath = Paths.get(outputDir, fileName);
try (FileOutputStream fos = new FileOutputStream(filePath.toFile())) {
fos.write(images.get(i));
} catch (IOException e) {
e.printStackTrace();
}
}
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
