Document Operation (20)
Comparison of PDF documents is essential for effective document management. By comparing PDF documents, users can easily identify differences in document content to have a more comprehensive understanding of them, which will greatly facilitate the user to modify and integrate the document content. This article will introduce how to use Spire.PDF for Java to compare PDF documents and find the differences.
Examples of the two PDF documents that will be used for comparison:
Install Spire.PDF for Java
First of all, you need to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
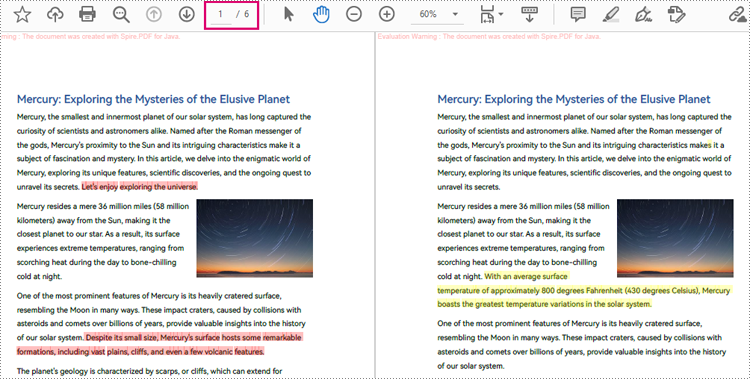
Compare Two PDF Documents
Spire.PDF for Java provides the PdfComparer class for users to create an object with two PDF documents for comparing. After creating the PdfComparer object, users can use PdfComparer.compare(String fileName) method to compare the two documents and save the result as a new PDF file.
The resulting PDF document displays the two original documents on the left and the right, with the deleted items in red and the added items in yellow.
The detailed steps for comparing two PDF documents are as follows:
- Create two objects of PdfDocument class and load two PDF documents using PdfDocument.loadFromFile() method.
- Create an object of PdfComparer class with the two documents.
- Compare the two documents and save the result as a new PDF document using PdfComparer.compare() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.comparison.PdfComparer;
public class ComparePDFPageRange {
public static void main(String[] args) {
//Create an object of PdfDocument class and load a PDF document
PdfDocument pdf1 = new PdfDocument();
pdf1.loadFromFile("Sample1.pdf");
//Create another object of PdfDocument class and load another PDF document
PdfDocument pdf2 = new PdfDocument();
pdf2.loadFromFile("Sample2.pdf");
//Create an object of PdfComparer class
PdfComparer comparer = new PdfComparer(pdf1,pdf2);
//Compare the two PDF documents and save the compare results to a new document
comparer.compare("ComparisonResult.pdf");
}
}
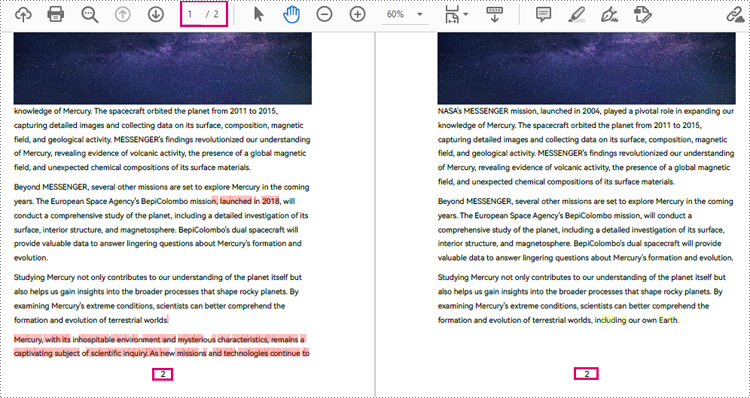
Compare a Specified Page Range of Two PDF Documents
Before comparing, users can use the PdfComparer.getOptions().setPageRanges() method to limit the page range to be compared. The detailed steps are as follows:
- Create two objects of PdfDocument class and load two PDF documents using PdfDocument.loadFromFile() method.
- Create an object of PdfComparer class with the two documents.
- Set the page range to be compared using PdfComparer.getOptions().setPageRanges() method.
- Compare the two documents and save the result as a new PDF document using PdfComparer.compare() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.comparison.PdfComparer;
public class ComparePDFPageRange {
public static void main(String[] args) {
//Create an object of PdfDocument class and load a PDF document
PdfDocument pdf1 = new PdfDocument();
pdf1.loadFromFile("G:/Documents/Sample6.pdf");
//Create another object of PdfDocument class and load another PDF document
PdfDocument pdf2 = new PdfDocument();
pdf2.loadFromFile("G:/Documents/Sample7.pdf");
//Create an object of PdfComparer class
PdfComparer comparer = new PdfComparer(pdf1,pdf2);
//Set the page range to be compared
comparer.getOptions().setPageRanges(1, 1, 1, 1);
//Compare the two PDF documents and save the compare results to a new document
comparer.compare("ComparisonResult.pdf");
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
A tagged PDF is a PDF document that contains tags that are pretty similar to HTML code. Tags provide a logical structure that governs how the content of the PDF is presented through assistive technology. Each tag identifies the associated content element, for example heading level 1 <H1>, paragraph <P>, image <Figure>, or table <Table>. In this article, you will learn how to create a tagged PDF document in Java using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
Create a Tagged PDF in Java
To add structure elements in a tagged PDF document, we must first create an object of PdfTaggedContent class. Then, add an element to the root using PdfTaggedContent.getStructureTreeRoot().appendChildElement() method. The following are the detailed steps to add a "heading" element to a tagged PDF using Spire.PDF for Java.
- Create a PdfDocument object and add a page to it using PdfDocument.getPages().add() method.
- Create an object of PdfTaggedContent class.
- Make the document compliance to PDF/UA identification using PdfTaggedContent.setPdfUA1Identification() method.
- Add a "document" element to the root of the document using PdfTaggedContent.getStructureTreeRoot().appendChildElement() method.
- Add a "heading" element under the "document" element using PdfStructureElement.appendChildElement() method.
- Add a start tag using PdfStructureElement.beginMarkedContent() method, which indicates the beginning of the heading element.
- Draw heading text on the page using PdfPageBase.getCanvas().drawString() method.
- Add an end tag using PdfStructureElement.beginMarkedContent() method, which implies the heading element ends here.
- Save the document to a PDF file using PdfDocument.saveToFile() method.
The following code snippet provides an example on how to create various elements including document, heading, paragraph, figure and table in a tagged PDF document in Java.
- Java
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import com.spire.pdf.interchange.taggedpdf.PdfStandardStructTypes;
import com.spire.pdf.interchange.taggedpdf.PdfStructureElement;
import com.spire.pdf.interchange.taggedpdf.PdfTaggedContent;
import com.spire.pdf.tables.PdfTable;
import java.awt.*;
import java.awt.geom.Point2D;
import java.awt.geom.Rectangle2D;
public class CreateTaggedPdf {
public static void main(String[] args) throws Exception {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Add a page
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(20));
//Set tab order
page.setTabOrder(TabOrder.Structure);
//Create an object of PdfTaggedContent class
PdfTaggedContent taggedContent = new PdfTaggedContent(doc);
//Set language and title for the document
taggedContent.setLanguage("en-US");
taggedContent.setTitle("Create Tagged PDF in Java");
//Set PDF/UA1 identification
taggedContent.setPdfUA1Identification();
//Create font and brush
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Times New Roman",Font.PLAIN,14), true);
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
//Add a "document" element
PdfStructureElement document = taggedContent.getStructureTreeRoot().appendChildElement(PdfStandardStructTypes.Document);
//Add a "heading" element
PdfStructureElement heading1 = document.appendChildElement(PdfStandardStructTypes.HeadingLevel1);
heading1.beginMarkedContent(page);
String headingText = "What Is a Tagged PDF?";
page.getCanvas().drawString(headingText, font, brush, new Point2D.Float(0, 0));
heading1.endMarkedContent(page);
//Add a "paragraph" element
PdfStructureElement paragraph = document.appendChildElement(PdfStandardStructTypes.Paragraph);
paragraph.beginMarkedContent(page);
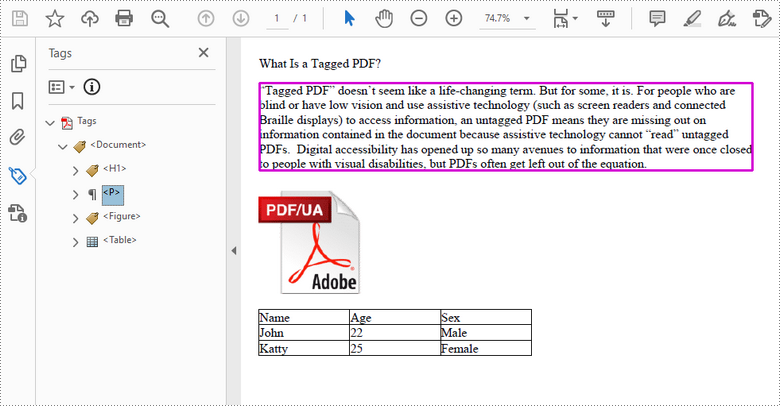
String paragraphText = "Tagged PDF doesn’t seem like a life-changing term. But for some, it is. For people who are " +
"blind or have low vision and use assistive technology (such as screen readers and connected Braille displays) to " +
"access information, an untagged PDF means they are missing out on information contained in the document because assistive " +
"technology cannot “read” untagged PDFs. Digital accessibility has opened up so many avenues to information that were once " +
"closed to people with visual disabilities, but PDFs often get left out of the equation.";
Rectangle2D.Float rect = new Rectangle2D.Float(0, 30, (float) page.getCanvas().getClientSize().getWidth(), (float) page.getCanvas().getClientSize().getHeight());
page.getCanvas().drawString(paragraphText, font, brush, rect);
paragraph.endMarkedContent(page);
//Add a "figure" element
PdfStructureElement figure = document.appendChildElement(PdfStandardStructTypes.Figure);
figure.beginMarkedContent(page);
PdfImage image = PdfImage.fromFile("C:\\Users\\Administrator\\Desktop\\pdfua.png");
page.getCanvas().drawImage(image, new Point2D.Float(0, 150));
figure.endMarkedContent(page);
//Add a "table" element
PdfStructureElement table = document.appendChildElement(PdfStandardStructTypes.Table);
table.beginMarkedContent(page);
PdfTable pdfTable = new PdfTable();
pdfTable.getStyle().getDefaultStyle().setFont(font);
String[] data = {"Name;Age;Sex",
"John;22;Male",
"Katty;25;Female"
};
String[][] dataSource = new String[data.length][];
for (int i = 0; i < data.length; i++) {
dataSource[i] = data[i].split("[;]", -1);
}
pdfTable.setDataSource(dataSource);
pdfTable.getStyle().setShowHeader(true);
pdfTable.draw(page.getCanvas(), new Point2D.Float(0, 280), 300f);
table.endMarkedContent(page);
//Save the document to file
doc.saveToFile("output/CreatePDFUA.pdf");
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Multi-column PDFs are commonly used in magazines, newspapers, research articles, etc. With Spire.PDF for Java, you can create multi-column PDFs from code easily. This article will show you how to create a two-column PDF from scratch in Java applications.
Install Spire.PDF for Java
First of all, you need to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
Create a Two-Column PDF from Scratch
The detailed steps are as follows:
- Create a PdfDocument object.
- Add a new page in the PDF using PdfDocument.getPages().add() method.
- Add a line and set its format in the PDF using PdfPageBase.getCanvas().drawLine() method.
- Add text in the PDF at two separate rectangle areas using PdfPageBase.getCanvas().drawString() method.
- Save the document to PDF using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class TwoColumnPDF {
public static void main(String[] args) throws Exception {
//Creates a pdf document
PdfDocument doc = new PdfDocument();
//Add a new page
PdfPageBase page = doc.getPages().add();
//Set location and width
float x = 0;
float y = 15;
float width = 600;
//Create pen
PdfPen pen = new PdfPen(new PdfRGBColor(Color.black), 1f);
//Draw line on the PDF page
page.getCanvas().drawLine(pen, x, y, x + width, y);
//Define paragraph text
String s1 = "Spire.PDF for Java is a PDF API that enables Java applications to read, write and "
+ "save PDF documents without using Adobe Acrobat. Using this Java PDF component, developers and "
+ "programmers can implement rich capabilities to create PDF files from scratch or process existing"
+ "PDF documents entirely on Java applications (J2SE and J2EE).";
String s2 = "Many rich features can be supported by Spire.PDF for Java, such as security settings,"
+ "extract text/image from the PDF, merge/split PDF, draw text/image/shape/barcode to the PDF, create"
+ "and fill in form fields, add and delete PDF layers, overlay PDF, insert text/image watermark to the "
+ "PDF, add/update/delete PDF bookmarks, add tables to the PDF, compress PDF document etc. Besides, "
+ "Spire.PDF for Java can be applied easily to convert PDF to XPS, XPS to PDF, PDF to SVG, PDF to Word,"
+ "PDF to HTML and PDF to PDF/A in high quality.";
//Get width and height of page
double pageWidth = page.getClientSize().getWidth();
double pageHeight = page.getClientSize().getHeight();
//Create solid brush objects
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
//Create true type font objects
PdfTrueTypeFont font= new PdfTrueTypeFont(new Font("Times New Roman",Font.PLAIN,14));
//Set the text alignment via PdfStringFormat class
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Left);
//Draw text
page.getCanvas().drawString(s1, font, brush, new Rectangle2D.Double(0, 20, pageWidth / 2 - 8f, pageHeight), format);
page.getCanvas().drawString(s2, font, brush, new Rectangle2D.Double(pageWidth / 2 + 8f, 20, pageWidth / 2 - 8f, pageHeight), format);
//Save the document
String output = "output/createTwoColumnPDF.pdf";
doc.saveToFile(output, FileFormat.PDF);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
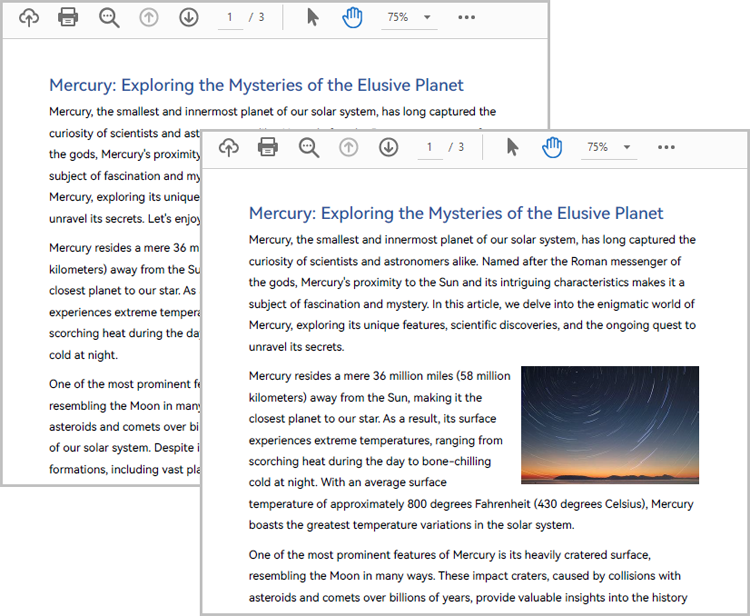
This article demonstrates how to detect if a PDF file is a portfolio in Java using Spire.PDF for Java.
The following is the screenshot of the input PDF:
import com.spire.pdf.PdfDocument;
public class DetectPortfolio {
public static void main(String []args){
//Create a PdfDocument instance
PdfDocument doc = new PdfDocument();
//Load the PDF file
doc.loadFromFile("Portfolio.pdf");
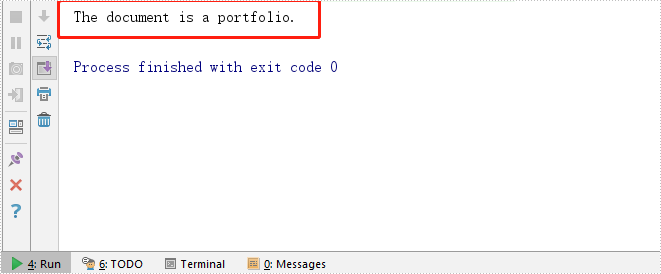
//Detect if the PDF is a portfolio
boolean value = doc.isPortfolio();
if (value)
{
System.out.println("The document is a portfolio.");
}
else
{
System.out.println("The document is not a portfolio.");
}
}
}
Output:
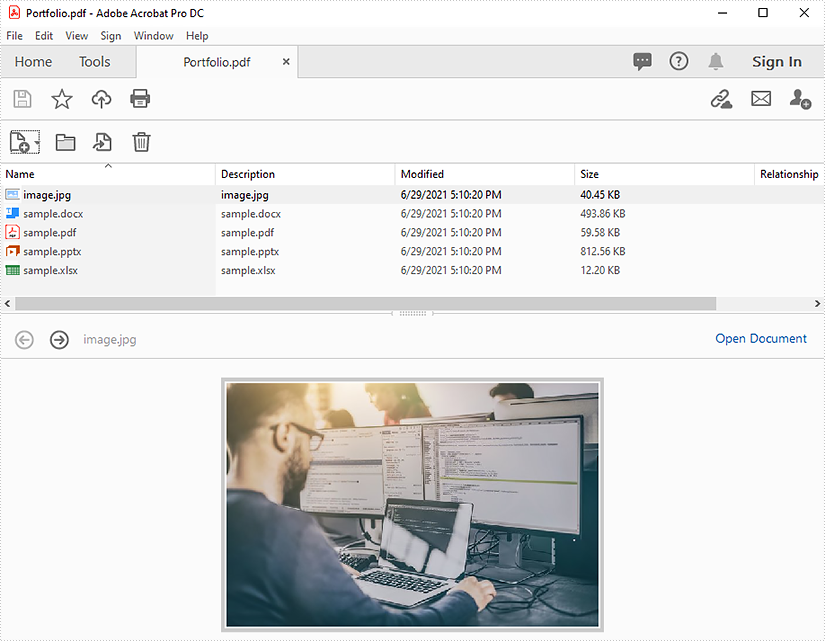
This article demonstrates how to extract files from a PDF portfolio in Java using Spire.PDF for Java.
The input PDF:
import com.spire.pdf.PdfDocument;
import com.spire.pdf.attachments.PdfAttachment;
import java.io.*;
public class ReadPortfolio {
public static void main(String []args) throws IOException {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load the PDF file
pdf.loadFromFile("Portfolio.pdf");
//Loop through the attachments in the file
for(PdfAttachment attachment : (Iterable)pdf.getAttachments()){
//Extract files
String fileName = attachment.getFileName();
OutputStream fos = new FileOutputStream("extract/" + fileName);
fos.write(attachment.getData());
}
pdf.dispose();
}
}
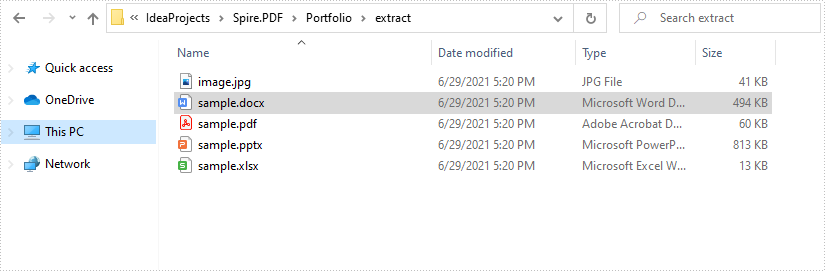
Output:
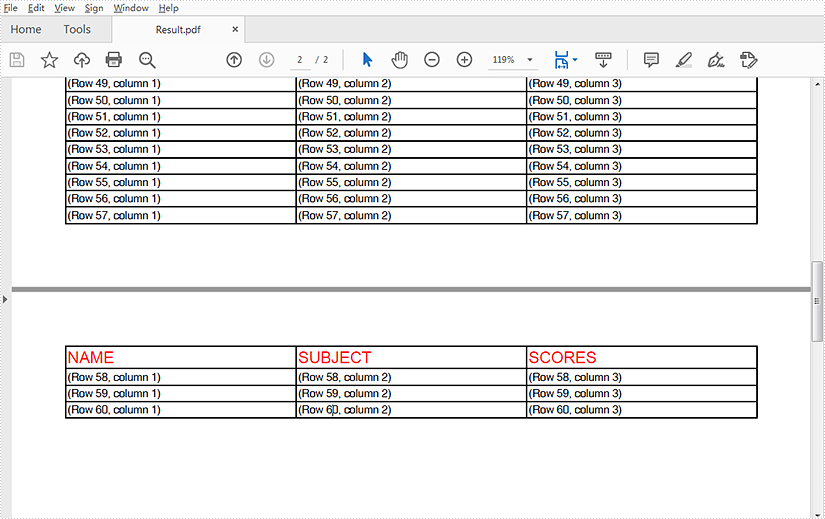
This article demonstrates how to repeat table header rows across pages in PDF using Spire.PDF for Java.
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import com.spire.pdf.grid.PdfGrid;
import com.spire.pdf.grid.PdfGridRow;
import java.awt.*;
public class RepeatTableHeaderRow {
public static void main(String[] args) {
//Create a new PDF document
PdfDocument pdf = new PdfDocument();
//Add a page
PdfPageBase page = pdf.getPages().add();
//Instantiate a PdfGrid class object
PdfGrid grid = new PdfGrid();
//Set cell padding
grid.getStyle().setCellPadding(new PdfPaddings(1,1,1,1));
//Add columns
grid.getColumns().add(3);
//Add header rows and table data
PdfGridRow[] pdfGridRows = grid.getHeaders().add(1);
for (int i = 0; i < pdfGridRows.length; i++)
{
pdfGridRows[i].getStyle().setFont(new PdfTrueTypeFont(new Font("Arial", Font.PLAIN,12), true));//Designate a font
pdfGridRows[i].getCells().get(0).setValue("NAME");
pdfGridRows[i].getCells().get(1).setValue("SUBJECT");
pdfGridRows[i].getCells().get(2).setValue("SCORES");
pdfGridRows[i].getStyle().setTextBrush(PdfBrushes.getRed());
}
//Repeat header rows (when across pages)
grid.setRepeatHeader(true);
//Add values to the table
for (int i = 0; i < 60; i++)
{
PdfGridRow row = grid.getRows().add();
for (int j = 0; j < grid.getColumns().getCount();j++)
{
row.getCells().get(j).setValue("(Row " + (i+1) + ", column " + (j+1) + ")");
}
}
// Draw a table in PDF
grid.draw(page,0,40);
//Save the document
pdf.saveToFile("Result.pdf");
pdf.dispose();
}
}
Output
A PDF portfolio allows multiple files to be assembled into a single interactive PDF container. The files in a PDF portfolio can be text documents, spreadsheets, presentations, images, videos, audio files, and more. By creating PDF portfolios, you can consolidate all of the relevant materials for a project into one unified package, making it easier to manage and distribute files. This article will demonstrate how to programmatically create a PDF portfolio and add files and folders to it using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
Create a PDF Portfolio and Add Files to It in Java
As a PDF portfolio is a collection of files, Spire.PDF for Java allows you to create it easily using the PdfDocument.getCollection() method. Then you can add files to the PDF portfolio using the PdfCollection.addFile() method. The detailed steps are as follows:
- Specify the files that need to be added to the PDF portfolio.
- Create a PdfDocument instance.
- Create a PDF portfolio and add files to it using PdfDocument.getCollection().addFile() method.
- Save the result file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class CreatePortfolioWithFiles {
public static void main(String []args){
// Specify the files
String[] files = new String[] { "Input.pdf", "Sample.docx", "Report.xlsx","Intro.pptx","Logo.jpg" };
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Create a PDF Portfolio and add files to it
for (int i = 0; i < files.length; i++)
{
pdf.getCollection().addFile(files[i]);
}
//Save the result file
pdf.saveToFile("PortfolioWithFiles.pdf", FileFormat.PDF);
pdf.dispose();
}
}
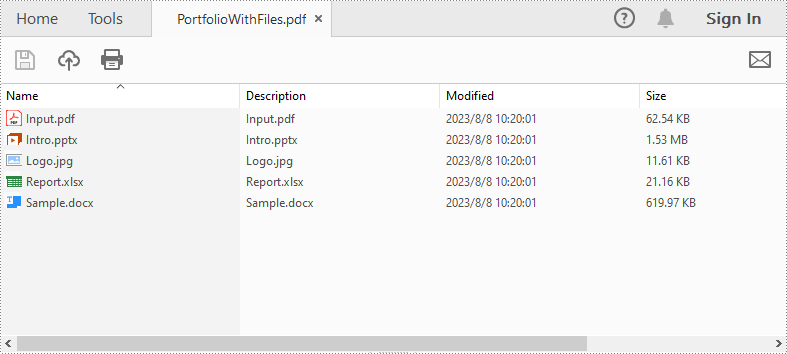
Create a PDF Portfolio and Add Folders to It in Java
After creating a PDF portfolio, Spire.PDF for Java also allows you to create folders within the PDF portfolio to further manage the files. The detailed steps are as follows:
- Specify the files that need to be added to the PDF portfolio.
- Create PdfDocument instance.
- Create a PDF portfolio using PdfDocument.getCollection() method.
- Add folders to the PDF portfolio using PdfCollection.getFolders().createSubfolder() method, and then add files to the folders using PdfFolder.addFile() method.
- Save the result file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.collections.PdfFolder;
public class CreatePortfolioWithFolders {
public static void main(String []args){
// Specify the files
String[] files = new String[] { "Input.pdf", "Sample.docx", "Report.xlsx","Intro.pptx","Logo.jpg" };
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Create a portfolio and add folders to it
for (int i = 0; i < files.length; i++)
{
PdfFolder folder = pdf.getCollection().getFolders().createSubfolder("folder" + i);
//Add files to the folders
folder.addFile(files[i]);
}
//Save the result file
pdf.saveToFile("PortfolioWithFolders.pdf", FileFormat.PDF);
pdf.dispose();
}
}
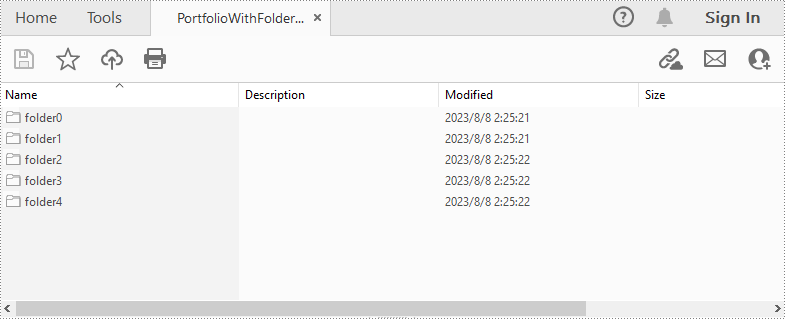
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
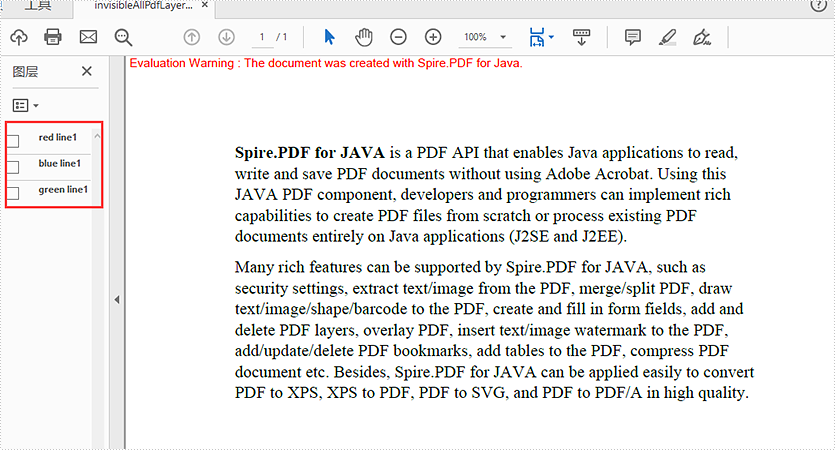
This article will demonstrate how to hide and display Layers in a PDF document using Spire.PDF for Java.
Hide all layers:
import com.spire.pdf.*;
import com.spire.pdf.graphics.layer.*;
public class invisibleAllPdfLayers {
public static void main(String[] args) {
//Load the sample document
PdfDocument doc = new PdfDocument();
doc.loadFromFile("layerSample.pdf");
for (int i = 0; i < doc.getLayers().getCount(); i++)
{
//Show all the Pdf layers
//doc.getLayers().get(i).setVisibility(PdfVisibility.On);
//Set all the Pdf layers invisible
doc.getLayers().get(i).setVisibility(PdfVisibility.Off);
}
//Save to document to file
doc.saveToFile("output/invisibleAllPdfLayers.pdf", FileFormat.PDF);
}
}
Hide some of the PDF layers:
import com.spire.pdf.*;
import com.spire.pdf.graphics.layer.*;
public class invisibleParticularPdfLayers {
public static void main(String[] args) {
//Load the sample document
PdfDocument doc = new PdfDocument();
doc.loadFromFile("layerSample.pdf");
//Hide the first layer by index
doc.getLayers().get(0).setVisibility(PdfVisibility.Off);
//Hide the layer by name with blue line1
for (int i = 0; i < doc.getLayers().getCount(); i++)
{
if("blue line1".equals(doc.getLayers().get(i).getName())){
doc.getLayers().get(i).setVisibility(PdfVisibility.Off);
}
}
//Save to document to file
doc.saveToFile("output/invisiblePaticularPdfLayers.pdf", FileFormat.PDF);
}
}
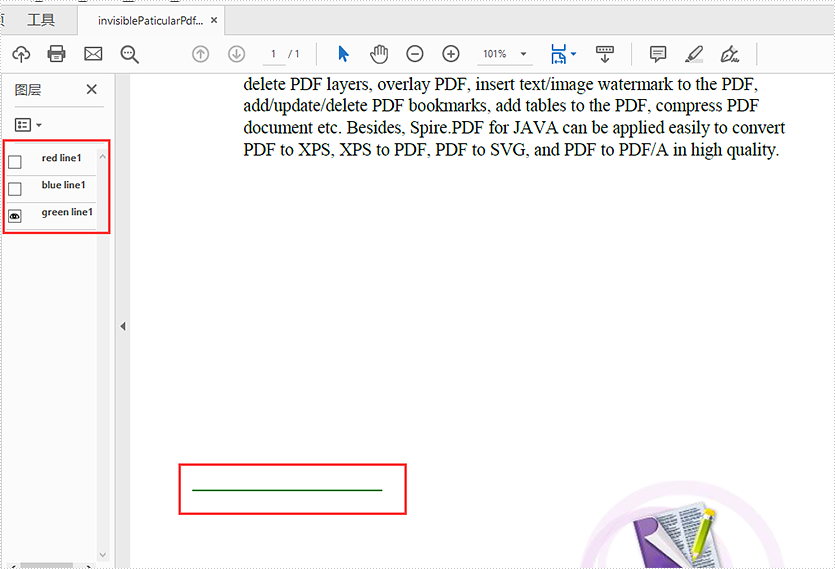
Table of contents (TOC) makes the PDF documents more accessible and easier to navigate, especially for large files. This article demonstrates how to create table of contents (TOC) for a PDF document using Spire.PDF for Java.
import com.spire.pdf.*;
import com.spire.pdf.actions.PdfGoToAction;
import com.spire.pdf.annotations.*;
import com.spire.pdf.general.PdfDestination;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.*;
public class TableOfContent {
public static void main(String[] args) throws Exception
{
//load PDF file
PdfDocument doc = new PdfDocument("sample.pdf");
int pageCount = doc.getPages().getCount();
//Insert a new page as the first page to draw table of content
PdfPageBase tocPage = doc.getPages().insert(0);
//set title
String title = "Table Of Contents";
PdfTrueTypeFont titleFont = new PdfTrueTypeFont(new Font("Arial", Font.BOLD,20));
PdfStringFormat centerAlignment = new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle);
Point2D location = new Point2D.Float((float) tocPage.getCanvas().getClientSize().getWidth() / 2, (float) titleFont.measureString(title).getHeight());
tocPage.getCanvas().drawString(title, titleFont, PdfBrushes.getCornflowerBlue(), location, centerAlignment);
//draw TOC text
PdfTrueTypeFont titlesFont = new PdfTrueTypeFont(new Font("Arial", Font.PLAIN,14));
String[] titles = new String[pageCount];
for (int i = 0; i < titles.length; i++) {
titles[i] = String.format("page%1$s", i + 1);
}
float y = (float)titleFont.measureString(title).getHeight() + 10;
float x = 0;
for (int i = 1; i <= pageCount; i++) {
String text = titles[i - 1];
Dimension2D titleSize = titlesFont.measureString(text);
PdfPageBase navigatedPage = doc.getPages().get(i);
String pageNumText = (String.valueOf(i+1));
Dimension2D pageNumTextSize = titlesFont.measureString(pageNumText);
tocPage.getCanvas().drawString(text, titlesFont, PdfBrushes.getCadetBlue(), 0, y);
float dotLocation = (float)titleSize.getWidth() + 2 + x;
float pageNumlocation = (float)(tocPage.getCanvas().getClientSize().getWidth() - pageNumTextSize.getWidth());
for (float j = dotLocation; j < pageNumlocation; j++) {
if (dotLocation >= pageNumlocation) {
break;
}
tocPage.getCanvas().drawString(".", titlesFont, PdfBrushes.getGray(), dotLocation, y);
dotLocation += 3;
}
tocPage.getCanvas().drawString(pageNumText, titlesFont, PdfBrushes.getCadetBlue(), pageNumlocation, y);
//add TOC action
Rectangle2D titleBounds = new Rectangle2D.Float(0,y,(float)tocPage.getCanvas().getClientSize().getWidth(),(float)titleSize.getHeight());
PdfDestination Dest = new PdfDestination(navigatedPage, new Point2D.Float(-doc.getPageSettings().getMargins().getTop(), -doc.getPageSettings().getMargins().getLeft()));
PdfActionAnnotation action = new PdfActionAnnotation(titleBounds, new PdfGoToAction(Dest));
action.setBorder(new PdfAnnotationBorder(0));
((PdfNewPage) ((tocPage instanceof PdfNewPage) ? tocPage : null)).getAnnotations().add(action);
y += titleSize.getHeight() + 10;
}
//save the resultant file
doc.saveToFile("addTableOfContent.pdf");
doc.close();
}
}
Output:
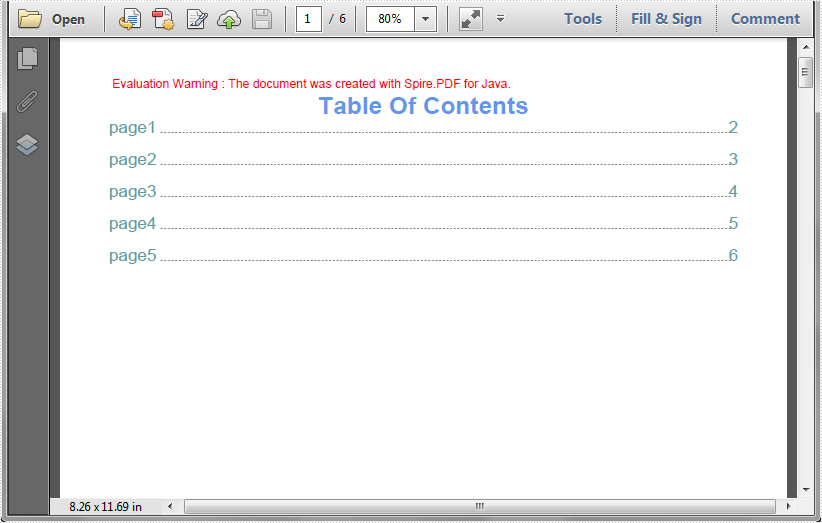
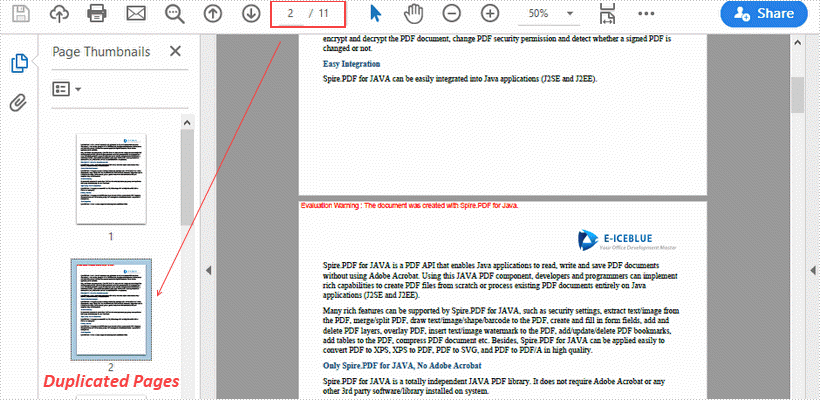
This article demonstrates how to duplicate a page within a PDF document using Spire.PDF for Java.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfMargins;
import com.spire.pdf.graphics.PdfTemplate;
import java.awt.geom.Dimension2D;
import java.awt.geom.Point2D;
public class DuplicatePage {
public static void main(String[] args) {
//Load a sample PDF document
PdfDocument pdf = new PdfDocument("C:\\Users\\Administrator\\Desktop\\original.pdf");
//Get the first page
PdfPageBase page = pdf.getPages().get(0);
//Get the page size
Dimension2D size = page.getActualSize();
//Create a template based on the page
PdfTemplate template = page.createTemplate();
for (int i = 0; i < 10; i++) {
//Add a new page to the document
page = pdf.getPages().add(size, new PdfMargins(0));
//Draw template on the new page
page.getCanvas().drawTemplate(template, new Point2D.Float(0, 0));
}
//Save the file
pdf.saveToFile("output/DuplicatePage.pdf");
}
}