
Reading PDFs in Java: Extract Text, Images, and Tables

In today’s data-driven world, handling PDFs is a critical skill for Java developers. Whether you’re dealing with scanned invoices, structured reports, or image-heavy documents, the ability to read PDF in Java can streamline workflows and unlock valuable insights.
This guide will walk you through practical implementations using Spire.PDF for Java to master PDF parsing in Java. From extracting searchable text and performing OCR on scanned pages to retrieving embedded images and reading tabular data , we’ve got you covered.
- Advanced Java Library to Read and Parse PDF Content
- Retrieve Text from Searchable PDFs
- Extract Images from PDF Documents
- Read Table Data from PDF Files
- Convert Scanned PDFs to Text with OCR
- Conclusion
- FAQs
Advanced Java Library to Read and Parse PDF Content
When it comes to reading PDF in Java, choosing the right library is half the battle. Spire.PDF stands out as a robust, feature-rich solution for developers. It supports text extraction, image retrieval, table parsing, and even OCR integration. Its intuitive API and comprehensive documentation make it ideal for both beginners and experts.
To start extracting PDF content, download Spire.PDF for Java from our website and add it as a dependency in your project. If you’re using Maven, include the following in your pom.xml:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.5.2</version>
</dependency>
</dependencies>
Below, we’ll explore how to leverage Spire.PDF for various PDF reading tasks.
Retrieve Text from Searchable PDFs
Searchable PDFs store text in a machine-readable format, enabling efficient content extraction. The PdfTextExtractor class in Spire.PDF offers direct access to page content, while PdfTextExtractOptions provides flexible extraction parameters, including strategy selection for handling special text layouts and specifying rectangular areas for extraction.
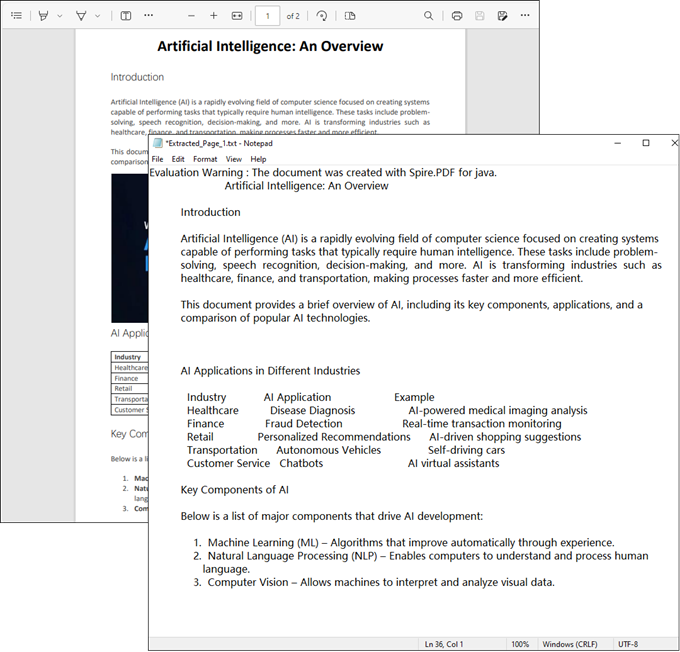
The example below shows how to retrieve text from every page of a PDF and output it to individual text files.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import com.spire.pdf.texts.PdfTextStrategy;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ExtractTextFromSearchablePdf {
public static void main(String[] args) throws IOException {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Iterate through all pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Get the current page
PdfPageBase page = doc.getPages().get(i);
// Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
// Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
// Specify extract option
extractOptions.setStrategy(PdfTextStrategy.None);
// Extract text from the page
String text = textExtractor.extract(extractOptions);
// Define the output file path
Path outputPath = Paths.get("output/Extracted_Page_" + (i + 1) + ".txt");
// Write to a txt file
Files.write(outputPath, text.getBytes());
}
// Close the document
doc.close();
}
}
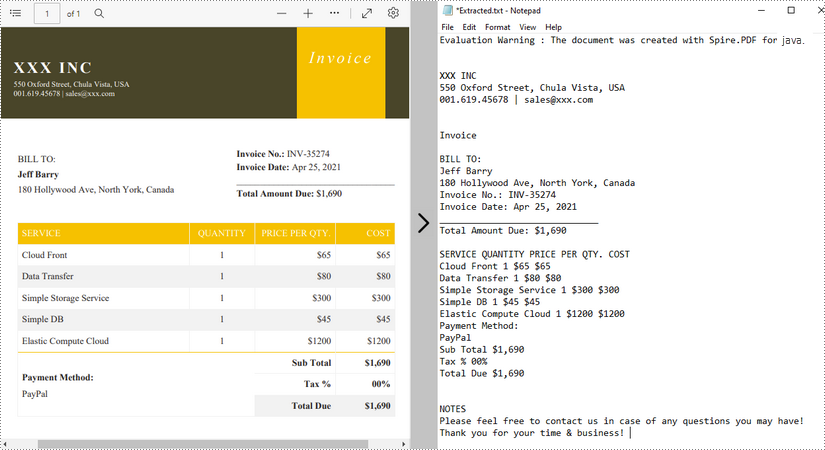
Result:
Extract Images from PDF Documents
When working with PDFs containing graphics or photos, the PdfImageHelper class provides reliable image extraction. It accurately identifies all embedded images through PdfImageInfo objects, which can then be saved as standard image files. This works particularly well for product catalogs or illustrated documents where visual content matters as much as text.
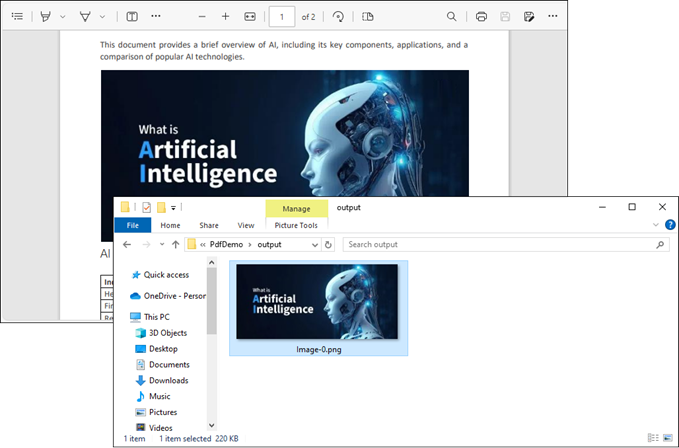
The following example extracts all embedded images from a PDF document and saves them as individual PNG files.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ExtractAllImages {
public static void main(String[] args) throws IOException {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Create a PdfImageHelper object
PdfImageHelper imageHelper = new PdfImageHelper();
// Declare an int variable
int m = 0;
// Iterate through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Get a specific page
PdfPageBase page = doc.getPages().get(i);
// Get all image information from the page
PdfImageInfo[] imageInfos = imageHelper.getImagesInfo(page);
// Iterate through the image information
for (int j = 0; j < imageInfos.length; j++)
{
// Get a specific image information
PdfImageInfo imageInfo = imageInfos[j];
// Get the image
BufferedImage image = imageInfo.getImage();
File file = new File(String.format("output/Image-%d.png",m));
m++;
// Save the image file in PNG format
ImageIO.write(image, "PNG", file);
}
}
// Clear up resources
doc.dispose();
}
}
Result:
Read Table Data from PDF Files
For PDF tables that need conversion to structured data, PdfTableExtractor intelligently recognizes cell boundaries and relationships. The resulting PdfTable objects maintain the original table organization, allowing for cell-level data export. Financial statements and research papers often benefit from this precise table preservation.
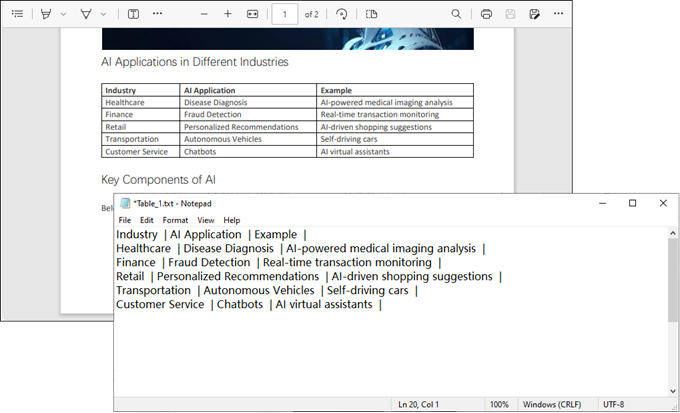
This Java code extracts table data from a PDF document and saves each table as a separate text file.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
public class ExtractTableData {
public static void main(String[] args) throws Exception {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Create a PdfTableExtractor instance
PdfTableExtractor extractor = new PdfTableExtractor(doc);
// Initialize a table counter
int tableCounter = 1;
// Loop through the pages in the PDF
for (int pageIndex = 0; pageIndex < doc.getPages().getCount(); pageIndex++) {
// Extract tables from the current page into a PdfTable array
PdfTable[] tableLists = extractor.extractTable(pageIndex);
// If any tables are found
if (tableLists != null && tableLists.length > 0) {
// Loop through the tables in the array
for (PdfTable table : tableLists) {
// Create a StringBuilder for the current table
StringBuilder builder = new StringBuilder();
// Loop through the rows in the current table
for (int i = 0; i < table.getRowCount(); i++) {
// Loop through the columns in the current table
for (int j = 0; j < table.getColumnCount(); j++) {
// Extract data from the current table cell and append to the StringBuilder
String text = table.getText(i, j);
builder.append(text).append(" | ");
}
builder.append("\r\n");
}
// Write data into a separate .txt document for each table
FileWriter fw = new FileWriter("output/Table_" + tableCounter + ".txt");
fw.write(builder.toString());
fw.flush();
fw.close();
// Increment the table counter
tableCounter++;
}
}
}
// Clear up resources
doc.dispose();
}
}
Result:
Convert Scanned PDFs to Text with OCR
Scanned PDFs require special handling through OCR engine such as Spire.OCR for Java. The solution first converts pages to images using Spire.PDF's rendering engine, then applies Spire.OCR's recognition capabilities via the **OcrScanner **class. This two-step approach effectively transforms physical document scans into editable text while supporting multiple languages.
Step 1. Install Spire.OCR and Configure the Environment
- Download Spire.OCR for Java and add the Jar file as a dependency in your project.
- Download the model that fits in with your operating system from one of the following links, and unzip the package somewhere on your disk.
- Configure the model in your code.
OcrScanner scanner = new OcrScanner();
configureOptions.setModelPath("D:\\win-x64");// model path
For detailed steps, refer to: Extract Text from Images Using the New Model of Spire.OCR for Java
Step 2. Convert a Scanned PDF to Text
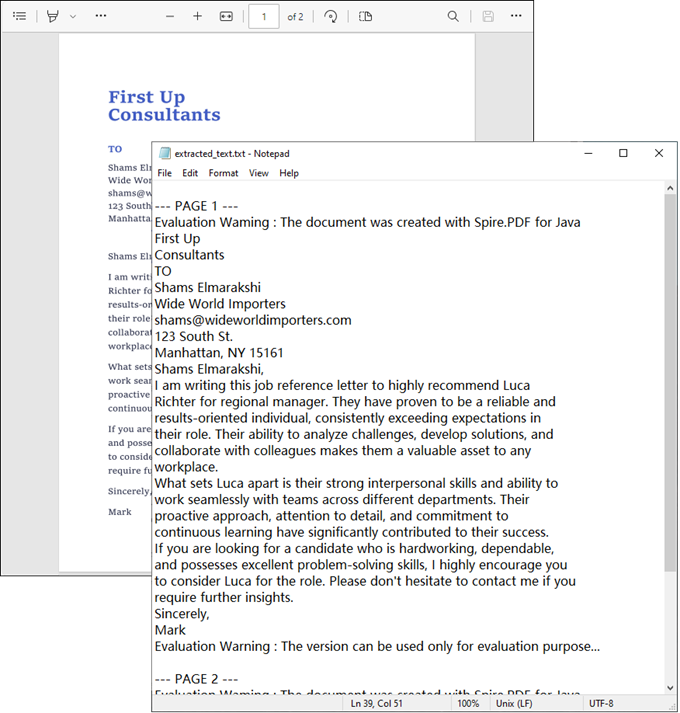
This code example converts each page of a scanned PDF into an image, applies OCR to extract text, and saves the results in a text file.
import com.spire.ocr.OcrException;
import com.spire.ocr.OcrScanner;
import com.spire.ocr.ConfigureOptions;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ExtractTextFromScannedPdf {
public static void main(String[] args) throws IOException, OcrException {
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Configure the scanner
ConfigureOptions configureOptions = new ConfigureOptions();
configureOptions.setModelPath("D:\\win-x64"); // Set model path
configureOptions.setLanguage("English"); // Set language
// Apply the configuration options
scanner.ConfigureDependencies(configureOptions);
// Load a PDF document
PdfDocument doc = new PdfDocument();
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Prepare temporary directory
String tempDirPath = "temp";
new File(tempDirPath).mkdirs(); // Create temp directory
StringBuilder allText = new StringBuilder();
// Iterate through all pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Convert page to image
BufferedImage bufferedImage = doc.saveAsImage(i, PdfImageType.Bitmap);
String imagePath = tempDirPath + File.separator + String.format("page_%d.png", i);
ImageIO.write(bufferedImage, "PNG", new File(imagePath));
// Perform OCR
scanner.scan(imagePath);
String pageText = scanner.getText().toString();
allText.append(String.format("\n--- PAGE %d ---\n%s\n", i + 1, pageText));
// Clean up temp image
new File(imagePath).delete();
}
// Save all extracted text to a file
Path outputTxtPath = Paths.get("output", "extracted_text.txt");
Files.write(outputTxtPath, allText.toString().getBytes());
// Close the document
doc.close();
System.out.println("Text extracted to " + outputTxtPath);
}
}
Result:
Conclusion
Mastering how to read PDF in Java opens up a world of possibilities for data extraction and document automation. Whether you’re dealing with searchable text, images, tables, or scanned documents, the right tools and techniques can simplify the process.
By leveraging libraries like Spire.PDF and integrating OCR for scanned files, you can build robust solutions tailored to your needs. Start experimenting with the code snippets provided and unlock the full potential of PDF processing in Java!
FAQs
Q1: Can I extract text from scanned PDFs using Java?
Yes, by combining Spire.PDF with Spire.OCR. Convert PDF pages to images and perform OCR to extract text.
Q2: What’s the best library for reading PDFs in Java?
Spire.PDF is highly recommended for its versatility and ease of use. It supports extraction of text, images, tables, and OCR integration.
Q3: Does Spire.PDF support extraction of PDF elements like metadata, attachments, and hyperlinks?
Yes, Spire.PDF provides comprehensive support for extracting:
- Metadata (title, author, keywords)
- Attachments (embedded files)
- Hyperlinks (URLs and document links)
The library offers dedicated classes like PdfDocumentInformation for metadata and methods to retrieve embedded files ( PdfAttachmentCollection ) and hyperlinks ( PdfUriAnnotation ).
Q4: How to parse tables from PDFs into CSV/Excel programmatically?
Using Spire.PDF for Java, you can extract table data from PDFs, then seamlessly export it to Excel (XLSX) or CSV format with Spire.XLS for Java. For a step-by-step guide, refer to our tutorial: Export Table Data from PDF to Excel in Java.
Get a Free License
To fully experience the capabilities of Spire.PDF for Java without any evaluation limitations, you can request a free 30-day trial license.
Java: Extract Images from PDF Documents
Extracting images from PDF documents is a highly valuable skill for anyone dealing with digital files. This capability is particularly beneficial for graphic designers who need to source visuals, content creators looking to repurpose images for blogs or social media, and data analysts who require specific graphics for reports. By efficiently retrieving images from PDFs, users can enhance their productivity and streamline their workflows, saving both time and effort.
In this article, you will learn how to extract images from an individual PDF page as well as from an entire PDF document, using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.6.2</version>
</dependency>
</dependencies>
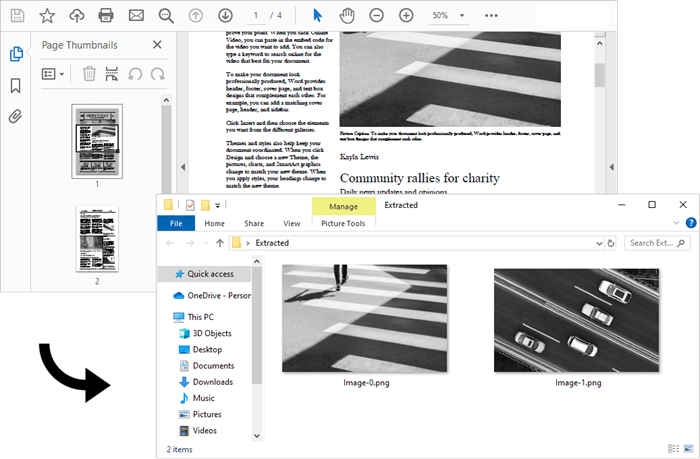
Extract Images from a Specific PDF Page in Java
The PdfImageHelper class in Spire.PDF for Java is designed to facilitate image management within PDF documents. It enables users to perform several operations, such as deleting, replacing, and retrieving images.
To get information about the images on a specific PDF page, developers can use the PdfImageHelper.getImagesInfo(PdfPageBase page) method. Once they have this information, they can export the image data in widely used formats such as PNG and JPEG.
The steps to extract images from a specific PDF page using Java are as follows:
- Create a PdfDocument object.
- Load a PDF file using the PdfDocument.loadFromFile() method.
- Get a specific page using the PdfDocument.getPages().get(index) method.
- Create a PdfImageHelper object.
- Get the image information collection from the page using the PdfImageHelper.getImagesInfo() method.
- Iterate through the image information collection.
- Get a specific piece of image information.
- Get the image data from the image information using the PdfImageInfo.getImage() method.
- Write the image data as a PNG file using the ImageIO.write() method.
The following code demonstrates how to extract images from a particular page in a PDF document and save them in a specified folder.
- Java
import com.spire.pdf.*;
import com.spire.pdf.utilities.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ExtractImagesFromPage {
public static void main(String[] args) throws IOException {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Get a specific page
PdfPageBase page = doc.getPages().get(0);
// Create a PdfImageHelper object
PdfImageHelper imageHelper = new PdfImageHelper();
// Get all image information from the page
PdfImageInfo[] imageInfos = imageHelper.getImagesInfo(page);
// Iterate through the image information
for (int i = 0; i < imageInfos.length; i++)
{
// Get a specific piece of image information
PdfImageInfo imageInfo = imageInfos[i];
// Get the image
BufferedImage image = imageInfo.getImage();
File file = new File(String.format("C:\\Users\\Administrator\\Desktop\\Extracted\\Image-%d.png",i));
// Save the image file in PNG format
ImageIO.write(image, "PNG", file);
}
// Dispose resources
doc.dispose();
}
}
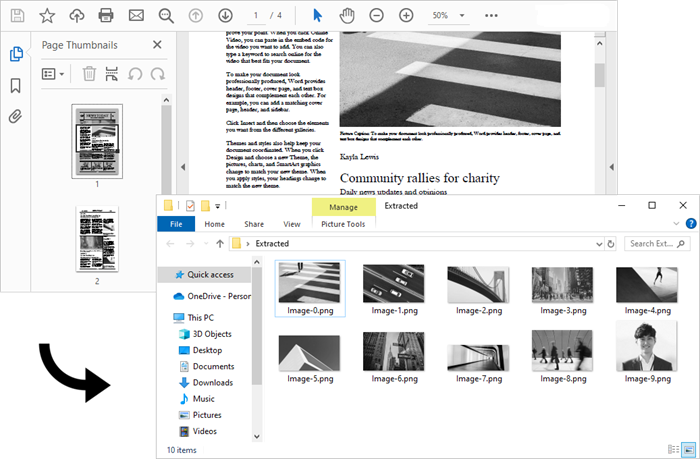
Extract Images from an Entire PDF Document in Java
From the example above, you learned how to extract images from a specific page. By iterating through each page in the document and performing image extraction on every one, you can easily gather all images from the entire document.
The steps to extract images from an entire PDF document using Java are as follows:
- Create a PdfDocument object.
- Load a PDF file using the PdfDocument.loadFromFile() method.
- Create a PdfImageHelper object.
- Iterate through the pages in the document.
- Get a specific page using the PdfDocument.getPages().get(index) method.
- Get the image information collection from the page using PdfImageHelper.getImagesInfo() method.
- Iterate through the image information collection and save each instance as a PNG file using the ImageIO.write() method.
The following code illustrates how to extract all images from a PDF document and save them in a specified folder.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ExtractAllImages {
public static void main(String[] args) throws IOException {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Create a PdfImageHelper object
PdfImageHelper imageHelper = new PdfImageHelper();
// Declare an int variable
int m = 0;
// Iterate through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Get a specific page
PdfPageBase page = doc.getPages().get(i);
// Get all image information from the page
PdfImageInfo[] imageInfos = imageHelper.getImagesInfo(page);
// Iterate through the image information
for (int j = 0; j < imageInfos.length; j++)
{
// Get a specific image information
PdfImageInfo imageInfo = imageInfos[j];
// Get the image
BufferedImage image = imageInfo.getImage();
File file = new File(String.format("C:\\Users\\Administrator\\Desktop\\Extracted\\Image-%d.png",m));
m++;
// Save the image file in PNG format
ImageIO.write(image, "PNG", file);
}
}
// Dispose resources
doc.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Extract Text from a PDF Document
Getting text out of PDFs can be a challenge, especially if you receive hundreds of PDF documents on a daily basis. Automating data extraction through programs becomes necessary because the program can process documents in bulk and ensure that the extracted content is 100% accurate. In this article, you will learn how to extract text from a searchable PDF document in Java using Spire.PDF for Java.
- Extract All Text from a Specified Page
- Extract Text from a Rectangle Area
- Extract Text Using SimpleTextExtractionStrategy
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.6.2</version>
</dependency>
</dependencies>
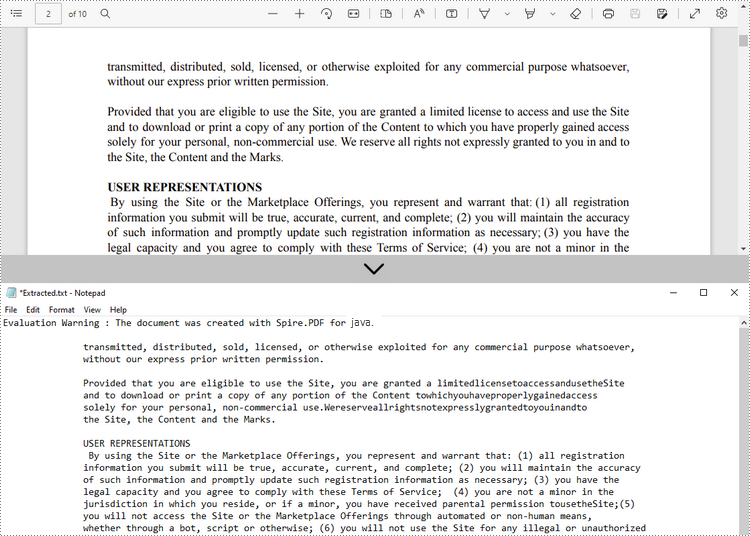
Extract All Text from a Specified Page
Spire.PDF for Java provides the PdfTextExtractor class to extract text from a searchable PDF and the PdfTextExtractOptions class to manage the extract options. By default, the PdfTextExtractor.extract() method will extract all text from a specified page without needing to specify a certain extract option. The detailed steps are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get the specific page using PdfDocument.getPages().get() method.
- Create a PdfTextExtractor object.
- Extract text from the selected page using PdfTextExtractor.extract() method.
- Write the extracted text to a TXT file.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ExtractTextFromPage {
public static void main(String[] args) throws IOException {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.getPages().get(1);
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Extract text from the page
String text = textExtractor.extract(extractOptions);
//Write to a txt file
Files.write(Paths.get("output/Extracted.txt"), text.getBytes());
}
}
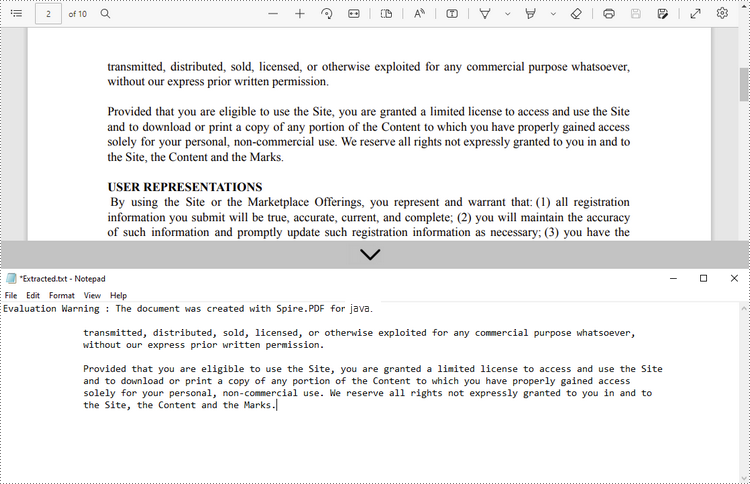
Extract Text from a Rectangle Area
To specify a rectangle area for extraction, use the setExtractArea() method under PdfTextExtractOptions class. The following steps show you how to extract text from a rectangle area of a page using Spire.PDF for Java.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get the specific page using PdfDocument.getPages().get() method.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and specify a rectangle area using setExtractArea() method of it.
- Extract text from the rectangle area using PdfTextExtractor.extract() method.
- Write the extracted text to a TXT file.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.awt.geom.Rectangle2D;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ExtractFromRectangleArea {
public static void main(String[] args) throws IOException {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.getPages().get(1);
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the option to extract text from a rectangle area
Rectangle2D rectangle2D = new Rectangle2D.Float(0, 0, 890, 170);
extractOptions.setExtractArea(rectangle2D);
//Extract text from the specified area
String text = textExtractor.extract(extractOptions);
//Write to a txt file
Files.write(Paths.get("output/Extracted.txt"), text.getBytes());
}
}
Extract Text Using SimpleTextExtractionStrategy
The above methods extract text line by line. When extracting text using SimpleTextExtractionStrategy, it keeps track of the current Y position of each string and inserts a line break into the output if the Y position has changed. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get the specific page using PdfDocument.getPages().get() method.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and set to use SimpleTextExtractionStrategy using setSimpleExtraction() method of it.
- Extract text using the strategy using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ExtractUsingSimpleTextStrategy {
public static void main(String[] args) throws IOException {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.getPages().get(0);
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the option to extract text using SimpleExtraction strategy
extractOptions.setSimpleExtraction(true);
//Extract text from the specified area
String text = textExtractor.extract(extractOptions);
//Write to a txt file
Files.write(Paths.get("output/Extracted.txt"), text.getBytes());
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.