
Extract/Read (2)
If you'd like to use the images embedded in a PDF document elsewhere, you can extract and save them in a folder. This article will show you how to programmatically extract images from a PDF document using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
Extract Images from a PDF Document
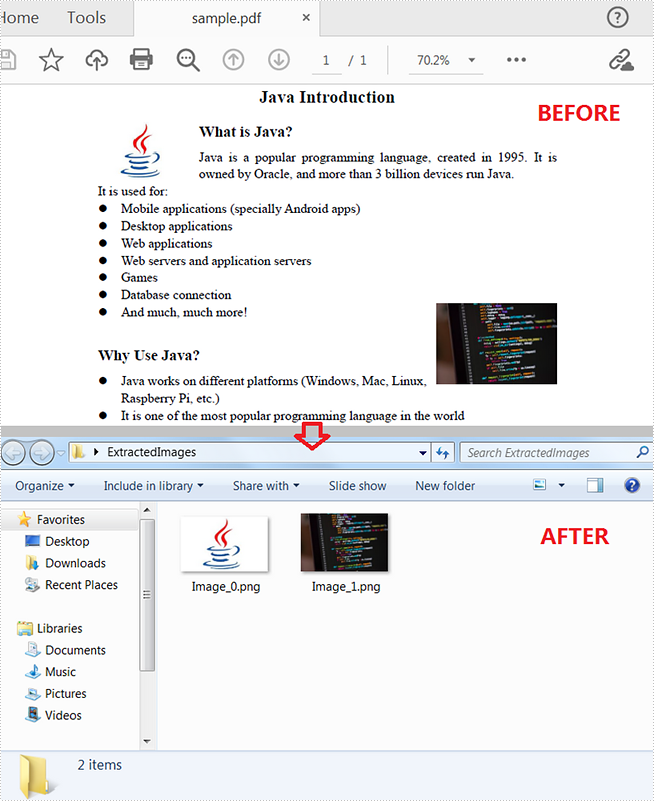
Spire.PDF for Java offers the PdfPageBase.extractImages() method to extract images from a PDF document. The detailed steps are listed below.
- Create a PdfDocument instance and load a PDF sample document using PdfDocument.loadFromFile() method.
- Loop through all pages of the document and extract images from the given page using PdfPageBase.extractImages() method.
- Specify the path and name of the output document.
- Save images as .png files.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
public class ExtractImage {
public static void main(String[] args) throws IOException {
//create a PdfDocument instance
PdfDocument doc = new PdfDocument();
//load a PDF sample file
doc.loadFromFile("sample.pdf");
//declare an int variable
int index = 0;
//loop through all pages
for (PdfPageBase page : (Iterable<PdfPageBase>) doc.getPages()) {
//extract images from the given page
for (BufferedImage image : page.extractImages()) {
//specify the file path and name
File output = new File("C:\\Users\\Administrator\\Desktop\\ExtractedImages\\" + String.format("Image_%d.png", index++));
//save images as .png files
ImageIO.write(image, "PNG", output);
}
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Getting text out of PDFs can be a challenge, especially if you receive hundreds of PDF documents on a daily basis. Automating data extraction through programs becomes necessary because the program can process documents in bulk and ensure that the extracted content is 100% accurate. In this article, you will learn how to extract text from a searchable PDF document in Java using Spire.PDF for Java.
- Extract All Text from a Specified Page
- Extract Text from a Rectangle Area
- Extract Text Using SimpleTextExtractionStrategy
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
Extract All Text from a Specified Page
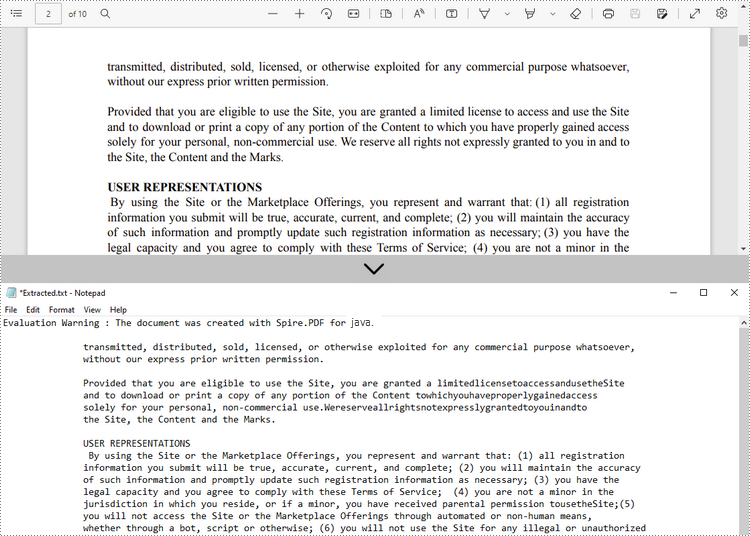
Spire.PDF for Java provides the PdfTextExtractor class to extract text from a searchable PDF and the PdfTextExtractOptions class to manage the extract options. By default, the PdfTextExtractor.extract() method will extract all text from a specified page without needing to specify a certain extract option. The detailed steps are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get the specific page using PdfDocument.getPages().get() method.
- Create a PdfTextExtractor object.
- Extract text from the selected page using PdfTextExtractor.extract() method.
- Write the extracted text to a TXT file.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ExtractTextFromPage {
public static void main(String[] args) throws IOException {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.getPages().get(1);
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Extract text from the page
String text = textExtractor.extract(extractOptions);
//Write to a txt file
Files.write(Paths.get("output/Extracted.txt"), text.getBytes());
}
}
Extract Text from a Rectangle Area
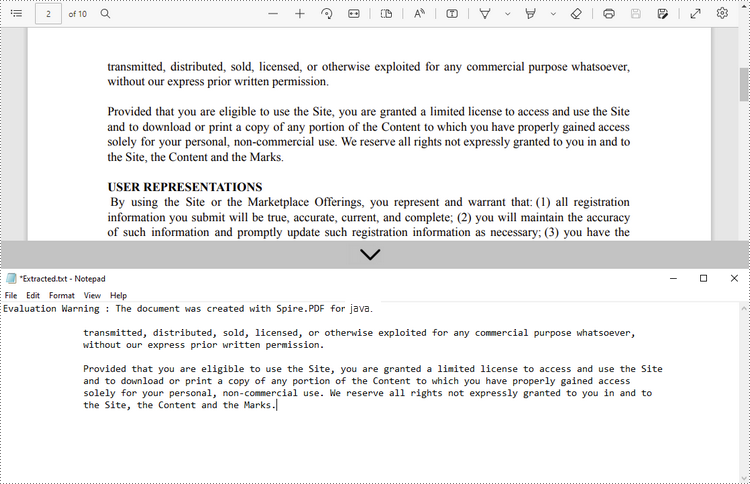
To specify a rectangle area for extraction, use the setExtractArea() method under PdfTextExtractOptions class. The following steps show you how to extract text from a rectangle area of a page using Spire.PDF for Java.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get the specific page using PdfDocument.getPages().get() method.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and specify a rectangle area using setExtractArea() method of it.
- Extract text from the rectangle area using PdfTextExtractor.extract() method.
- Write the extracted text to a TXT file.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.awt.geom.Rectangle2D;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ExtractFromRectangleArea {
public static void main(String[] args) throws IOException {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.getPages().get(1);
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the option to extract text from a rectangle area
Rectangle2D rectangle2D = new Rectangle2D.Float(0, 0, 890, 170);
extractOptions.setExtractArea(rectangle2D);
//Extract text from the specified area
String text = textExtractor.extract(extractOptions);
//Write to a txt file
Files.write(Paths.get("output/Extracted.txt"), text.getBytes());
}
}
Extract Text Using SimpleTextExtractionStrategy
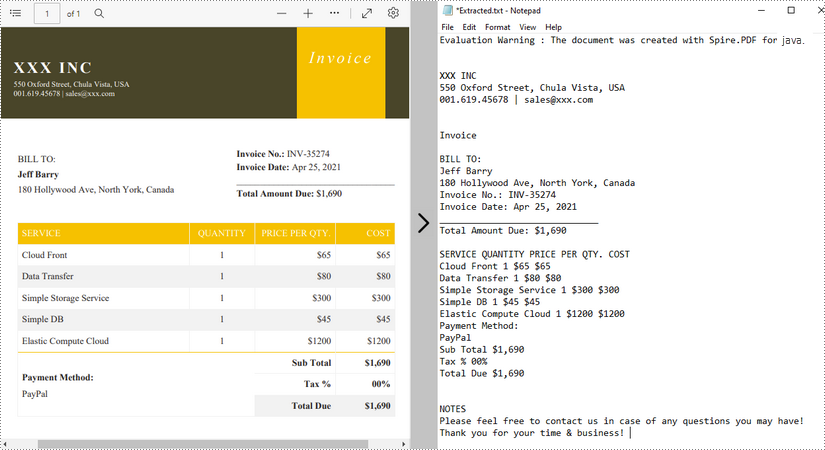
The above methods extract text line by line. When extracting text using SimpleTextExtractionStrategy, it keeps track of the current Y position of each string and inserts a line break into the output if the Y position has changed. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get the specific page using PdfDocument.getPages().get() method.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and set to use SimpleTextExtractionStrategy using setSimpleExtraction() method of it.
- Extract text using the strategy using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ExtractUsingSimpleTextStrategy {
public static void main(String[] args) throws IOException {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.getPages().get(0);
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the option to extract text using SimpleExtraction strategy
extractOptions.setSimpleExtraction(true);
//Extract text from the specified area
String text = textExtractor.extract(extractOptions);
//Write to a txt file
Files.write(Paths.get("output/Extracted.txt"), text.getBytes());
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
