Установлено через NuGet
PM> Install-Package Spire.PDF
Ссылки по теме
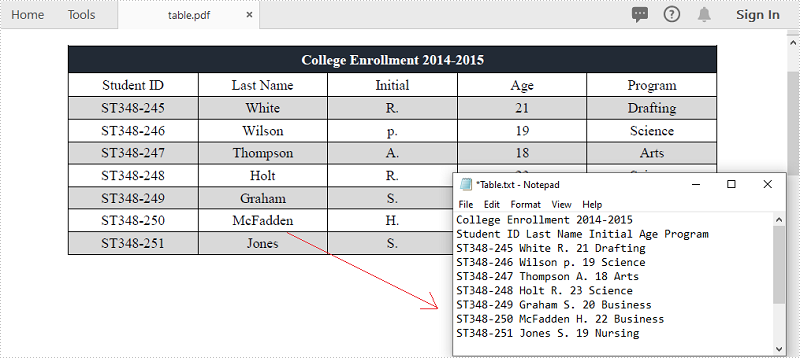
PDF — один из самых популярных форматов документов для обмена и записи данных. Вы можете столкнуться с ситуацией, когда вам необходимо извлечь данные из PDF-документов, особенно данные в таблицах. Например, в таблицах ваших счетов в формате PDF хранится полезная информация, и вы хотите извлечь данные для дальнейшего анализа или расчета. В этой статье показано, как извлекать данные из таблиц PDF и сохраните его в файле TXT с помощью Spire.PDF for .NET.
Установите Spire.PDF for .NET
Для начала вам нужно добавить файлы DLL, включенные в пакет Spire.PDF for .NET, в качестве ссылок в ваш проект .NET. Файлы DLL можно загрузить по этой ссылке или установить через NuGet.
- Package Manager
PM> Install-Package Spire.PDF
Извлечение данных из таблиц PDF
Ниже приведены основные шаги по извлечению таблиц из PDF-документа.
- Создайте экземпляр класса PdfDocument.
- Загрузите образец PDF-документа, используя метод PdfDocument.LoadFromFile().
- Извлеките таблицы с определенной страницы с помощью метода PdfTableExtractor.ExtractTable(int pageIndex).
- Получите текст определенной ячейки таблицы, используя метод PdfTable.GetText(int rowIndex, int columnsIndex).
- Сохраните извлеченные данные в файле .txt.
- C#
- VB.NET
using System.IO;
using System.Text;
using Spire.Pdf;
using Spire.Pdf.Utilities;
namespace ExtractPdfTable
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load the sample PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\table.pdf");
//Create a StringBuilder object
StringBuilder builder = new StringBuilder();
//Initialize an instance of PdfTableExtractor class
PdfTableExtractor extractor = new PdfTableExtractor(doc);
//Declare a PdfTable array
PdfTable[] tableList = null;
//Loop through the pages
for (int pageIndex = 0; pageIndex < doc.Pages.Count; pageIndex++)
{
//Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex);
//Determine if the table list is null
if (tableList != null && tableList.Length > 0)
{
//Loop through the table in the list
foreach (PdfTable table in tableList)
{
//Get row number and column number of a certain table
int row = table.GetRowCount();
int column = table.GetColumnCount();
//Loop though the row and colunm
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
//Get text from the specific cell
string text = table.GetText(i, j);
//Add text to the string builder
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
}
//Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString());
}
}
}
Imports System.IO
Imports System.Text
Imports Spire.Pdf
Imports Spire.Pdf.Utilities
Namespace ExtractPdfTable
Class Program
Shared Sub Main(ByVal args() As String)
'Create a PdfDocument object
Dim doc As PdfDocument = New PdfDocument()
'Load the sample PDF file
doc.LoadFromFile("C:\Users\Administrator\Desktop\table.pdf")
'Create a StringBuilder object
Dim builder As StringBuilder = New StringBuilder()
'Initialize an instance of PdfTableExtractor class
Dim extractor As PdfTableExtractor = New PdfTableExtractor(doc)
'Declare a PdfTable array
Dim tableList() As PdfTable = Nothing
'Loop through the pages
Dim pageIndex As Integer
For pageIndex = 0 To doc.Pages.Count- 1 Step pageIndex + 1
'Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
'Determine if the table list is null
If tableList <> Nothing And tableList.Length > 0 Then
'Loop through the table in the list
Dim table As PdfTable
For Each table In tableList
'Get row number and column number of a certain table
Dim row As Integer = table.GetRowCount()
Dim column As Integer = table.GetColumnCount()
'Loop though the row and colunm
Dim i As Integer
For i = 0 To row- 1 Step i + 1
Dim j As Integer
For j = 0 To column- 1 Step j + 1
'Get text from the specific cell
Dim text As String = table.GetText(i,j)
'Add text to the string builder
builder.Append(text + " ")
Next
builder.Append("\r\n")
Next
Next
End If
Next
'Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString())
End Sub
End Class
End Namespace
Подать заявку на временную лицензию
Если вы хотите удалить оценочное сообщение из сгенерированных документов или избавиться от функциональных ограничений, пожалуйста запросить 30-дневную пробную лицензию для себя.
