Оглавление
Ссылки по теме
В современную цифровую эпоху извлечение текста из изображений или отсканированных PDF-файлов является обычным требованием для различных приложений. Оптическое распознавание символов (OCR) — это технология, которая позволяет компьютерам распознавать и извлекать текст из таких документов. С его помощью мы можем легко конвертировать изображения и отсканированные PDF-файлы в редактируемые форматы с возможностью поиска, что упрощает обработку и анализ текстового контента. В этом блоге мы рассмотрим, как извлекать текст из изображений и отсканированных PDF-файлов с помощью OCR на C#.
- Извлечение текста из изображений в C#
- Извлечение текста из изображений с помощью координат в C#
- Извлечение текста из отсканированных PDF-файлов на C#
Библиотеки C# для извлечения текста из изображений и отсканированных PDF-файлов
Чтобы извлечь текст из изображений, мы будем использовать библиотеку Spire.OCR for .NET. Spire.OCR for .NET — это мощная библиотека, разработанная специально для извлечения текста из изображений в приложениях .NET. Он поддерживает различные форматы изображений, такие как BMP, JPG, PNG, TIFF и GIF.
Ниже приведены шаги по установке Spire.OCR for .NET:
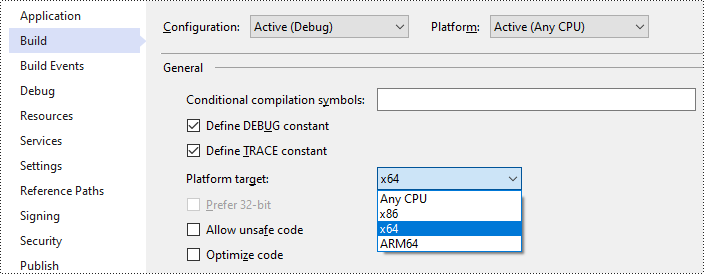
- Измените целевую платформу вашего решения на x64.
- Установите Spire.OCR из NuGet, выполнив следующую команду в консоли диспетчера пакетов NuGet:
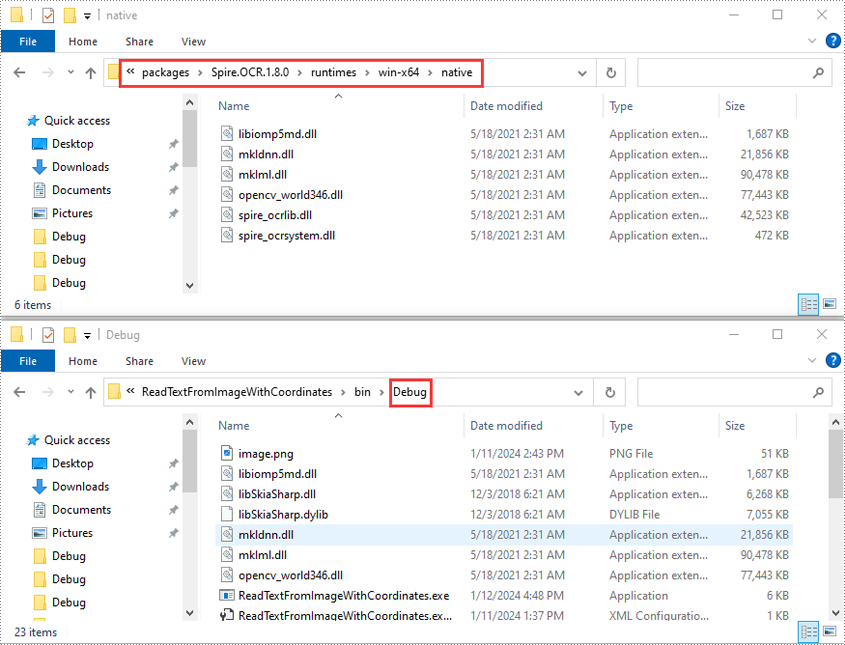
- Откройте папку решения и перейдите в каталог packages\Spire.OCR.1.8.0\runtimes\win-x64\native. Скопируйте файлы DLL из этого каталога и вставьте их в папку «Отладка» вашего решения.
Install-Package Spire.OCR
Чтобы извлечь текст из отсканированных PDF-файлов, нам сначала нужно преобразовать PDF-документ в изображения. Для этой задачи мы будем использовать Spire.PDF for .NET библиотека. После завершения преобразования мы можем использовать Spire.OCR для извлечения текста из полученных изображений.
Вы можете установить Spire.PDF for .NET из NuGet, выполнив следующую команду в консоли диспетчера пакетов NuGet:
Install-Package Spire.PDF
Извлечение текста из изображений в C#
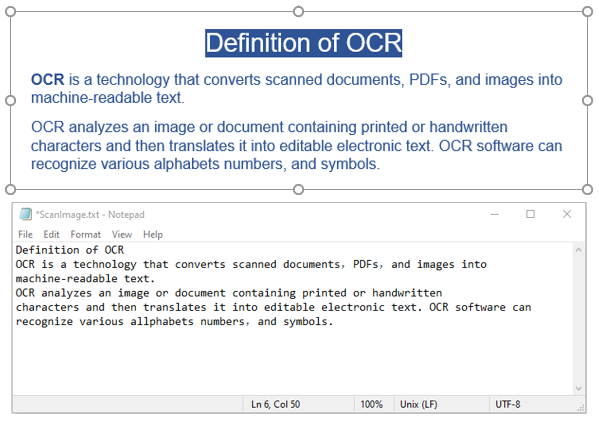
Spire.OCR предоставляет метод OcrScanner.Scan() для распознавания текста на изображении. После распознавания получить распознанный текст можно с помощью свойства OcrScanner.Text.
Вот основные шаги по распознаванию текста на изображении с помощью Spire.OCR:
- Создайте экземпляр класса OcrScanner.
- Распознайте текст на изображении с помощью метода OcrScanner.Scan().
- Получите распознанный текст из объекта OcrScanner, используя свойство OcrScanner.Text.
- Сохраните текст в текстовый файл.
Вот пример кода, показывающий, как распознать текст на изображении и сохранить результат в текстовый файл:
- C#
using Spire.OCR;
using System.IO;
namespace ReadTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imageFilePath = "Image.png";
//Specify the path of the output text file
string outputFilePath = "ScanImage.txt";
//Call the ScanTextFromImage method to scan text from an image
string scannedText = ScanTextFromImage(imageFilePath);
//Write the text to the specified file
File.WriteAllText(outputFilePath, scannedText);
}
public static string ScanTextFromImage(string imageFilePath)
{
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the recognized text from the OcrScanner object
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Извлечение текста из изображений с помощью координат в C#
Извлечение координат полезно, когда вам нужно определить точное расположение определенных текстовых элементов на изображении. С помощью Spire.OCR вы можете получить распознанный текст в виде блоков или строк. Для каждого блока вы можете получить подробную информацию о его местоположении, включая координаты x и y, а также его ширину и высоту.
Ниже приведены основные шаги по извлечению текста и информации о его местоположении из изображения с помощью Spire.OCR:
- Создайте экземпляр класса OcrScanner.
- Распознайте текст на изображении с помощью метода OcrScanner.Scan().
- Получите распознанный текст из объекта OcrScanner, используя свойство OcrScanner.Text.
- Перебирайте текстовые блоки распознанного текста.
- Для каждого блока получите его текст и информацию о местоположении, используя свойства IOCRTextBlock.Text и IOCRTextBlock.Box, а затем добавьте результат в список строк.
- Сохраните содержимое списка в текстовый файл.
Вот пример кода, который показывает, как распознать текст вместе с информацией о его местоположении на изображении и сохранить результат в текстовый файл:
- C#
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace ReadTextFromImageWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imagePath = "Image.png";
//Specify the path of the output text file
string outputFile = "ScanImageWithCoordinates.txt";
//Call the ScanTextFromImageWithCoordinates method to extract text and its area information from the image
List<string> extractedText = ScanTextFromImageWithCoordinates(imagePath);
//Write the result to the specified file
File.WriteAllLines(outputFile, extractedText);
}
//Retrieve the text blocks along with their location information (x, y, width, height) from an image
public static List<string> ScanTextFromImageWithCoordinates(string imageFilePath)
{
//Create a list
List<string> extractedText = new List<string>();
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the scanned text
IOCRText text = ocrScanner.Text;
//Iterate through each text block
foreach (IOCRTextBlock block in text.Blocks)
{
//Append the text of each block and its location information to the list
extractedText.Add($"Text: {block.Text}\nRectangular Area: {block.Box}");
}
}
return extractedText;
}
}
}
Извлечение текста из отсканированных PDF-файлов на C#
Чтобы извлечь текст из отсканированных PDF-файлов, нам нужно выполнить двухэтапный процесс. Сначала мы используем Spire.PDF для преобразования отсканированных PDF-файлов в изображения. Затем мы используем Spire.OCR для извлечения текста из этих изображений.
Вот основные шаги по распознаванию текста из отсканированного PDF-файла с помощью Spire.PDF и Spire.OCR:
- Создайте экземпляр класса PdfDocument.
- Загрузите PDF-документ с помощью метода PdfDocument.LoadFromFile().
- Перелистывайте страницы PDF-документа.
- Преобразуйте каждую страницу в объект изображения с помощью метода PdfDocument.SaveAsImage().
- Сохраните объект Image в поток, используя метод Image.Save().
- Создайте экземпляр класса OcrScanner.
- Распознайте текст из потока с помощью метода OcrScanner.Scan().
- Получите распознанный текст, используя свойство IOCRText.Text, и добавьте его в список строк.
- Сохраните содержимое списка в текстовый файл.
Вот пример кода, показывающий, как распознать текст из отсканированного PDF-файла и сохранить результат в текстовый файл:
- C#
using Spire.OCR;
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
namespace ReadTextFromScannedPDF
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the scanned PDF file
string pdfFilePath = "Sample.pdf";
//Specify the path of the output text file
string outputFilePath = "ScanPDF.txt";
//Extract text from the scanned PDF
List<string> extractedText = ExtractTextFromScannedPDF(pdfFilePath);
//Write the text to the specified file
File.WriteAllLines(outputFilePath, extractedText);
}
//Extract text from a scanned PDF
public static List<string> ExtractTextFromScannedPDF(string pdfFilePath)
{
//Create a list to store the extracted text
List<string> extractedText = new List<string>();
//Create an instance of the PdfDocument class
using (PdfDocument document = new PdfDocument())
{
//Load the PDF document
document.LoadFromFile(pdfFilePath);
//Iterate through each page of the document
for (int pageIndex = 0; pageIndex < document.Pages.Count; pageIndex++)
{
//Convert the page to an image
using (Image image = document.SaveAsImage(pageIndex, 300, 300))
{
//Create a memory stream to hold the image data
using (MemoryStream stream = new MemoryStream())
{
//Save the image to the memory stream in PNG format
image.Save(stream, ImageFormat.Png);
stream.Position = 0;
//Scan the text from the image and add it to the list
string text = ScanTextFromImageStream(stream);
extractedText.Add(text);
}
}
}
}
//Return the list
return extractedText;
}
//Scan text from an image stream
public static string ScanTextFromImageStream(Stream stream)
{
//Create an instance of the OcrScanner class
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan the text from the image stream in PNG format
ocrScanner.Scan(stream, OCRImageFormat.Png);
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Получите бесплатную лицензию
Чтобы в полной мере воспользоваться возможностями Spire.OCR for .NET или Spire.PDF for .NET без каких-либо ограничений оценки, вы можете запросить бесплатная 30-дневная пробная лицензия.
Заключение
В этом сообщении блога показано, как извлекать текст из изображений и отсканированных PDF-документов на C#. Если у вас есть какие-либо вопросы, пожалуйста, задайте их на нашем форуме или отправьте в нашу службу поддержки по электронной почте.
- Как использовать Spire.OCR в приложениях .NET Framework.
- Как использовать Spire.OCR for .NET в приложениях .NET Core
- C#/VB.NET: преобразование PDF в изображения (JPG, PNG, BMP)
- C#/VB.NET: конвертирование изображений в PDF
- C#/VB.NET: преобразование PDF в Word
- C#/VB.NET: извлечение текста из PDF-документов
