Índice
Instalar com Pip
pip install Spire.PDF
Links Relacionados
Os arquivos PDF são uma escolha popular para compartilhamento e distribuição de documentos, mas pode ser bastante desafiador extrair e reaproveitar conteúdo PDF. Felizmente, convertendo arquivos PDF para HTML com Python oferece uma excelente solução para recuperação e reaproveitamento de informações em PDF, o que melhora a acessibilidade, capacidade de pesquisa e adaptabilidade. Além disso, o formato HTML permite que os mecanismos de pesquisa indexem o conteúdo, aumentando a probabilidade de ele ser descoberto na web. Além do mais, com a flexibilidade e facilidade de uso do Python, tanto iniciantes quanto desenvolvedores experientes podem usar Python para converter PDF em HTML de forma fácil e eficiente.

Este artigo se concentra em como converter PDF em HTML em programas Python. Inclui principalmente os seguintes tópicos:
- Visão geral da conversão de PDF em HTML com Python
- Converta PDF em um único arquivo HTML com código Python
- Converta PDF em HTML com imagens separadas usando Python
- Converta PDF em vários arquivos HTML com Python
- Licença Gratuita e Suporte Técnico
Visão geral da conversão de PDF em HTML com Python
As extensas APIs do Python oferecem conveniência para diversas operações de processamento de documentos PDF. Spire.PDF for Python é uma das APIs poderosas que pode realizar várias operações em documentos PDF, incluindo conversão, edição e mesclar documentos PDF. E a conversão de PDF em HTML com Python pode ser implementada sem esforço com esta API.
No Spire.PDF for Python, a classe PdfDocument representa um documento PDF. Podemos carregar um arquivo PDF usando o método LoadFromFile() nesta classe e salvar o documento em outros formatos, como HTML, para obter uma conversão simples de PDF para HTML.
Além disso, esta API também fornece o método SetConvertHtmlOptions() na propriedade PdfDocument.ConversionOptions para definir as opções de incorporação de imagem durante a conversão. Abaixo estão os parâmetros que podem ser passados para este método para definir o número máximo de páginas, opção de incorporação SVG, opção de incorporação de imagem e opção de qualidade SVG:
- useEmbeddedSvg (bool): Quando definido como True, permite incorporar SVG no arquivo HTML convertido. O arquivo HTML resultante incluirá todos os elementos do documento PDF, incluindo imagens, em um único arquivo HTML.
- useEmbeddedImg (bool): Quando definido como True, permite incorporar imagens no arquivo HTML convertido. Este parâmetro só funciona se useEmbeddedSvg estiver definido como False.
- maxPageOneFile (int): Define o número máximo de páginas a serem incluídas em um único arquivo HTML. Se o PDF tiver mais páginas do que o número especificado, vários arquivos HTML serão gerados, cada um contendo um subconjunto de páginas.
- useHighQualityEmbeddedSvg (bool): quando definido como True, garante o uso de versões de alta qualidade de imagens SVG incorporadas no processo de conversão HTML.
Fluxo de trabalho típico de conversão de PDF em HTML em Python usando Spire.PDF for Python:
- Crie um objeto da classe PdfDocument e carregue um documento PDF usando o método PdfDocument.LoadFromFile(string fileName).
- Defina as opções de conversão usando o método PdfDocument.ConversionOptions.SetConvertHtmlOptions().
- Converta o documento para o formato HTML e salve-o usando o método PdfDocument.SaveToFile(string fileName, FileFormat.HTML).
Os usuários podem baixar Spire.PDF for Python e importe-o para seus projetos ou instale-o com PyPI:
pip install Spire.PDF
Converta PDF em um único arquivo HTML com código Python
Este exemplo de código mostra como converter PDF em HTML diretamente com Python, sem definir nenhuma opção de conversão. Neste caso, só precisamos carregar um arquivo PDF com o método LoadFromFile e salvá-lo como um arquivo HTML com o método SaveToFile. O arquivo HTML convertido será um único arquivo HTML com imagens e outros elementos incorporados nele.
Exemplo de código:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("G:/Documents/ARCHITECTURE.pdf")
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTML.html", FileFormat.HTML)
doc.Close()
Resultado da conversão:
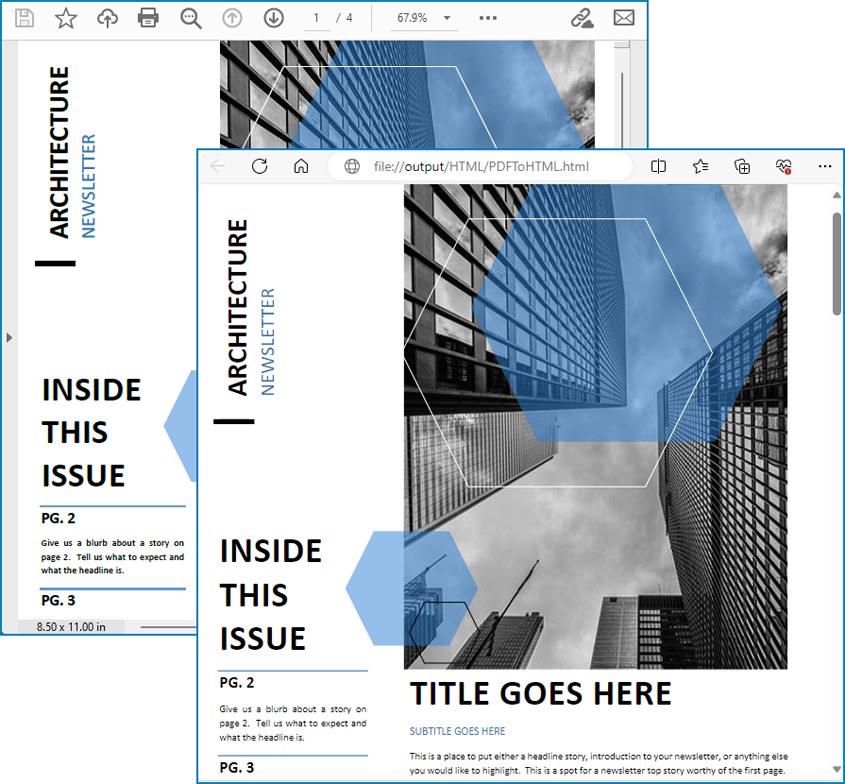
Converta PDF em HTML com imagens separadas usando Python
Ao definir o parâmetro useEmbeddedSvg como False, podemos converter o documento PDF em um arquivo HTML com imagens e arquivos CSS separados dele e armazenados em uma pasta. Isso torna conveniente editar ainda mais o arquivo HTML convertido e realizar operações adicionais nas imagens.
Exemplo de código:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLWithoutEmbeddingSVG.html", FileFormat.HTML)
doc.Close()
Resultado da conversão:
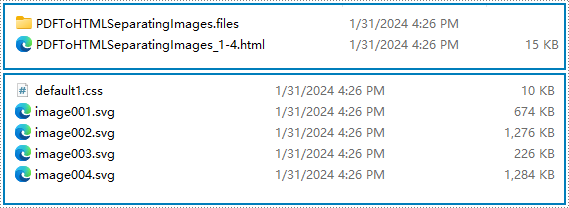
Converta PDF em vários arquivos HTML com Python
Com a pré-condição de que useEmbeddedSvg esteja definido como False, o método SetPdfToHtmlOptions permite o uso do parâmetro maxPageOneFile (int) para determinar o número máximo de páginas incluídas em cada arquivo HTML convertido. Este recurso permite Divisão de documentos PDF no processo de conversão. Por exemplo, definir o parâmetro como 1 resultará na conversão de cada página em um arquivo HTML separado.
Exemplo de código:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False, False, 1, False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLLimitingPage.html", FileFormat.HTML)
doc.Close()
Resultado da conversão:
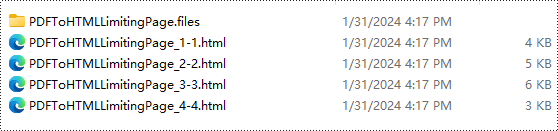
Licença Gratuita e Suporte Técnico
Spire.PDF for Python oferece aos usuários uma licença gratuita para avaliação para todos os usuários, incluindo usuários corporativos e individuais. Solicite uma licença temporária usar esta API Python para converter documentos PDF em arquivos HTML, removendo quaisquer restrições de uso ou marcas d'água.
Para quaisquer problemas encontrados durante a conversão de PDF para HTML usando esta API, os usuários podem procurar suporte técnico no fórum Spire.PDF.
Conclusão
Este artigo demonstra como converter PDF em HTML usando Python e fornece várias opções de conversão, como conversão para um único arquivo HTML, separação de arquivos HTML de imagens e divisão do documento PDF durante a conversão. Com Spire.PDF for Python, os usuários têm acesso a um método simples e eficiente para Python na conversão de PDF para HTML, suportando opções flexíveis de personalização.
